기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
Connect Customer에서 고객 세그먼트 구축
참고
SQL(베타)로 구동되는 분할을 사용하려면 데이터 스토어를 켜야 합니다. Customer Profiles 홈 페이지 화면으로 이동하여 상단 파란색 배너에서 데이터 스토어를 활성화하세요.
참고
-
Connect Customer 관리자 웹 사이트에서 세분화 빌더 환경으로 이동하려면이 기능에 대한 보안 프로필 권한이 필요합니다. 자세한 내용은 보안 프로필 권한을 할당하여 고객 세그먼트 관리 단원을 참조하십시오.
-
세그먼트를 빌드하기 전에 Customer Profiles 도메인 설정 데이터 통합을 사용하여 Customer Profiles 도메인의 프로필을 채우는 것이 좋습니다. Customer Profiles와의 데이터 통합을 구성하는 방법에 대한 자세한 내용은 외부 애플리케이션을 Connect Customer Profiles와 통합 섹션을 참조하세요.
-
세그먼트에는 계산된 속성을 사용하여 캡처한 이벤트가 포함될 수 있습니다. 사용자 지정 계산된 속성을 구성하고 계산된 기본 속성 고객 프로필 제안을 검토하는 방법에 대한 자세한 내용은 Connect Customer Profiles에서 계산된 속성 설정 섹션을 참조하세요.
Connect Customer는 고객 세그먼트를 구축하는 두 가지 방법을 제공합니다. 1/ Spark SQL을 통해 세그먼트 정의(베타, 데이터 스토어 활성화 필요), 2/ 대상 그룹 및 필터를 통해 세그먼트 정의(클래식 세분화). 둘 다 생성형 AI 기반 세그먼트 AI 어시스턴트를 통해 자연어 프롬프트를 사용할 수 있습니다. 한 가지 방법으로 세그먼트를 정의하는 경우 해당 세그먼트를 다른 세그먼트로 이동하고 다시 시작해야 합니다.
대상 그룹 및 필터를 사용한 클래식 세분화
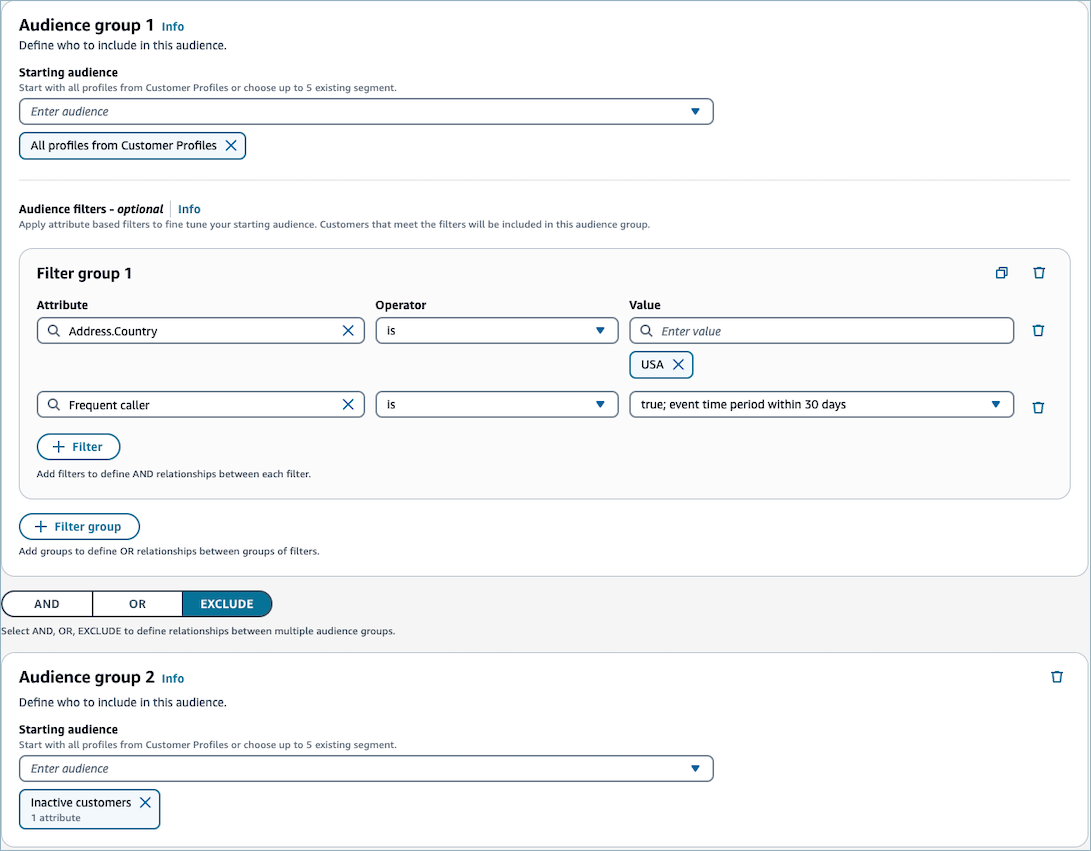
고객 세그먼트를 생성할 때 시작 잠재고객을 선택하고 세그먼트를 정의하는 필터를 선택하여 해당 잠재고객을 구체화합니다. 예를 들어 잠재고객 그룹을 생성한 다음 특정 국가에 거주하고 자주 전화하는 모든 고객의 필터를 선택할 수 있습니다. 세그먼트는 캠페인 실행, 고객 응대 흐름 실행, 세그먼트 추정 또는 내보내기 등 온디맨드로 다시 계산됩니다. 그 결과, 각 세그먼트의 크기 및 멤버십은 시간의 경과에 따라 변화합니다.
또한 두 번째 잠재고객 그룹을 생성한 다음 두 잠재고객 그룹 간에 관계(AND, OR 또는 EXCLUDE)를 생성하여 첫 번째 잠재고객 그룹에서 고객을 추가로 좁히거나 연결하거나 제외할 수 있습니다.
잠재고객 그룹
고객 세그먼트를 생성할 때 하나 이상의 잠재고객 그룹을 생성합니다. 잠재고객 그룹은 다음과 같은 구성 요소로 구성됩니다.
-
시작 잠재고객: 초기 사용자 모집단을 정의하는 고객 세그먼트입니다. 최대 5명의 시작 대상 또는 Customer Profiles 도메인의 모든 프로필을 지정할 수 있습니다.
-
필터 그룹: 시작 잠재고객 위에 적용하는 잠재고객 정보의 범주입니다. OR 관계로 연결된 여러 필터 그룹을 추가할 수 있습니다.
-
필터: 필터는 세그먼트에 속하는 잠재고객 수를 줄입니다. 필요에 맞게 세그먼트를 조정하려는 만큼 필터를 추가할 수 있습니다.
고객 세그먼트에는 하나 이상의 잠재고객 그룹이 있어야 하지만 선택적으로 두 번째 잠재고객 그룹을 생성한 다음 두 잠재고객 그룹 간에 관계(AND/OR/EXCLUDE)를 생성할 수 있습니다. 이러한 결과에 대한 자세한 내용은 5단계: 두 번째 잠재고객 그룹 추가(선택 사항) 섹션을 참조하세요.
고객 세그먼트 생성
다음 단계는 고객 세그먼트 생성 및 구성을 설명합니다.
-
1단계: 새 세그먼트 빌드
-
2단계: 이름 및 설명 구성
-
3단계: 잠재고객 그룹 1에 포함할 시작 잠재고객 선택
-
4단계: 필터 그룹 선택 및 구성(선택 사항)
-
5단계: 잠재고객 그룹 2 추가(선택 사항)
-
6단계: 정렬 활성화(선택 사항)
1단계: 새 세그먼트 빌드
-
세그먼트를 생성하려면 사전 조건으로 보안 프로필 권한을 생성해야 합니다. 자세한 내용은 보안 프로필 권한을 할당하여 고객 세그먼트 관리 단원을 참조하십시오. 또한 세그먼트의 멤버십을 가장 잘 시각화하려면 세그먼트를 생성하기 전에 데이터를 수집하는 것이 좋습니다. S3 또는 외부 애플리케이션을 통해 프로필을 수집하려면 Customer Profiles로 고객 데이터 생성 및 수집 또는외부 애플리케이션을 Connect Customer Profiles와 통합 섹션 참조하세요.
-
고객 세그먼트 테이블 보기에서 세그먼트 생성을 선택합니다.
2단계: 이름 및 설명 지정
-
이름에 나중에 쉽게 알아볼 수 있도록 고객 세그먼트의 이름을 입력합니다.
참고
Connect Customer 관리자 웹 사이트는 입력한 이름을 세그먼트
DisplayName의 로 사용하고 이를 기반으로 식별자를 생성합니다. 생성된 식별자는 Customer Profiles API를 사용하여 세그먼트에 액세스할 때SegmentDefinitionName으로 사용됩니다. -
(선택 사항) 설명에 고객 세그먼트에 대한 설명을 입력합니다.

3단계: 잠재고객 그룹 1에 포함할 시작 잠재고객 선택
먼저 잠재고객 그룹의 시작 잠재고객을 어떻게 정의할지 선택합니다.
-
잠재고객 그룹 1의 시작 잠재고객 드롭다운 목록에서 잠재고객 그룹에 포함할 세그먼트를 하나 이상 선택하거나 Customer Profiles에서 모든 프로필을 선택합니다.
참고
여러 세그먼트를 시작 잠재고객으로 선택하면 세그먼트가
OR관계에 의해 연결됩니다. 예를 들어 프리미엄 멤버십 고객과 기본 멤버십 고객 세그먼트를 시작 잠재고객으로 선택하면 두 세그먼트 중 하나에 있는 모든 프로필이 포함됩니다.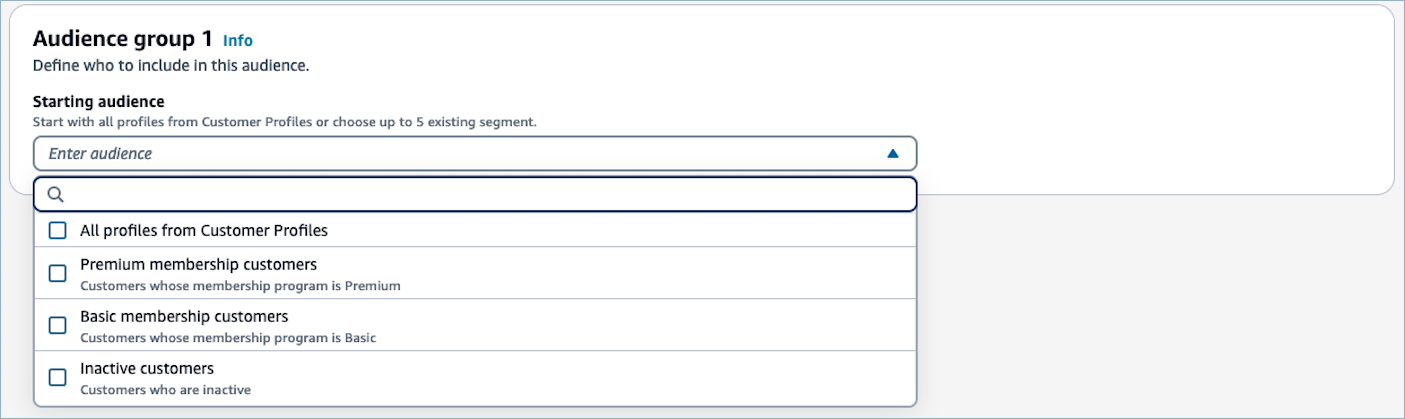
-
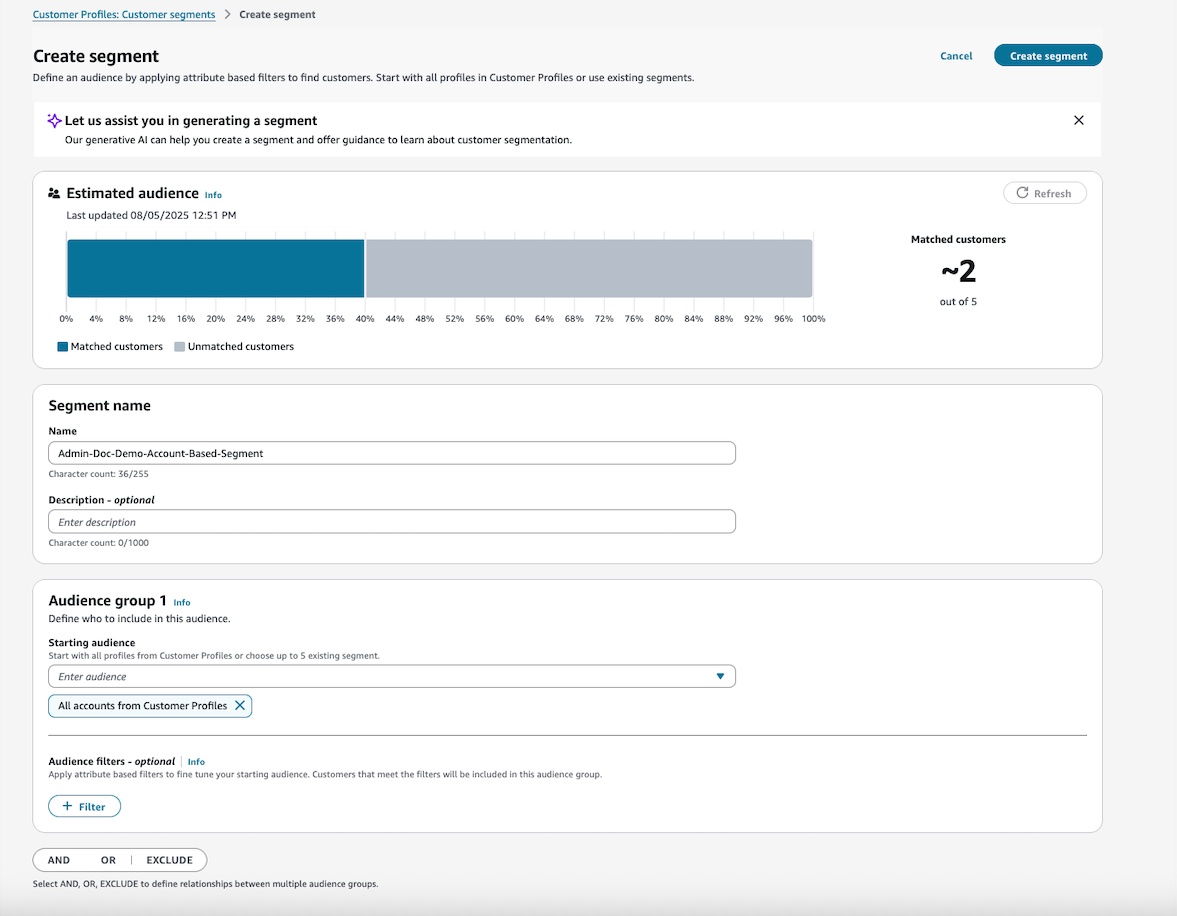
ProfileType으로 세그먼트를 생성하려면 먼저 Customer Profiles의 모든 계정을 초기 잠재고객으로 사용합니다. 이 접근 방식을 사용하면 계정 기반 프로필을 효과적으로 필터링할 수 있습니다. 달리 지정하지 않는 한 분할 프로세스는 고객 프로필 도메인 내의 모든 프로필을 자동으로 내보냅니다. 이 기본 동작은 포괄적인 적용 범위를 보장하지만 특정 대상 지정 요구 사항에 맞게 조정할 수 있습니다.
다음은 세그먼트 정의를 생성하는 방법의 예입니다(계정 또는 표준 프로필 기반).
모든 계정 기반 프로필을 필터링합니다(ProfileType=ACCOUNT_PROFILE).
참고
하위 프로필로만 세그먼트를 생성하려면 계정 기반 프로필을 제외하는 새 잠재고객을 생성합니다. 예를 들어
ProfileType이 포함된 프로필은 PROFILE이거나ProfileType가 비어 있는 경우입니다.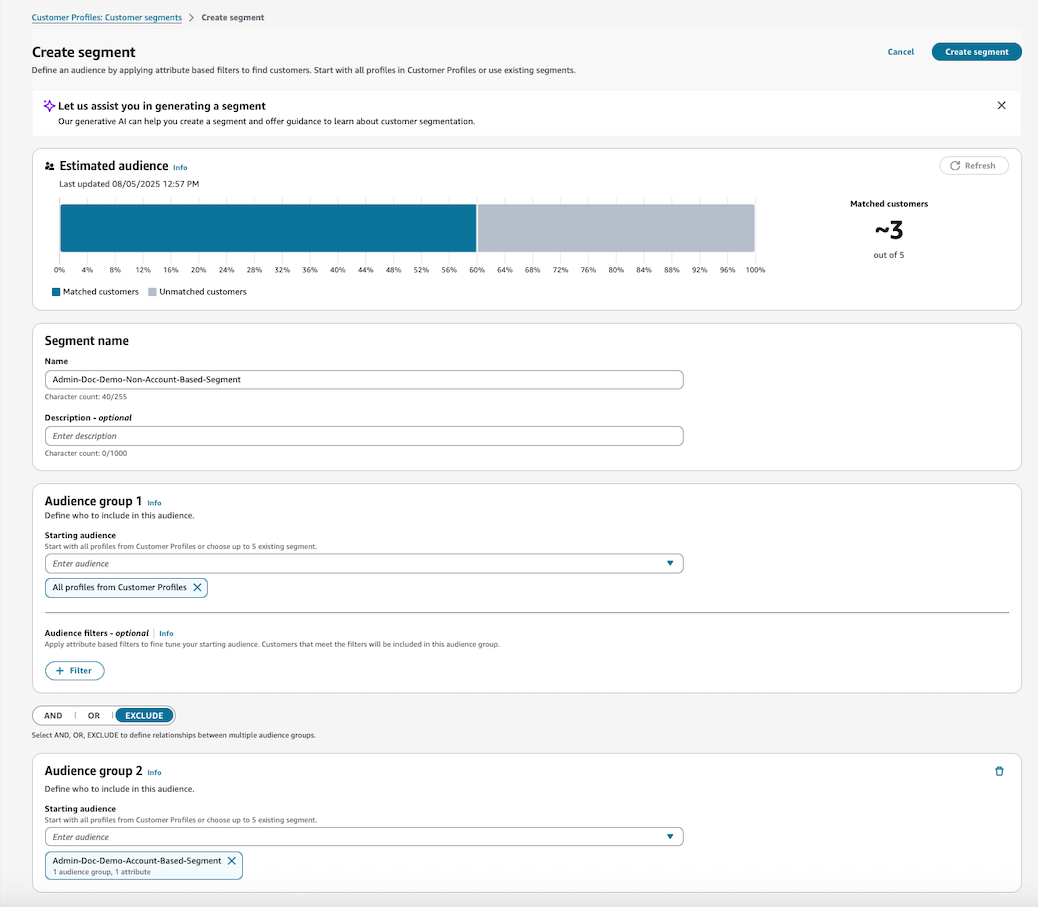
Phone을 사용하여 연결할 계정을 대상으로 하는 샘플 캠페인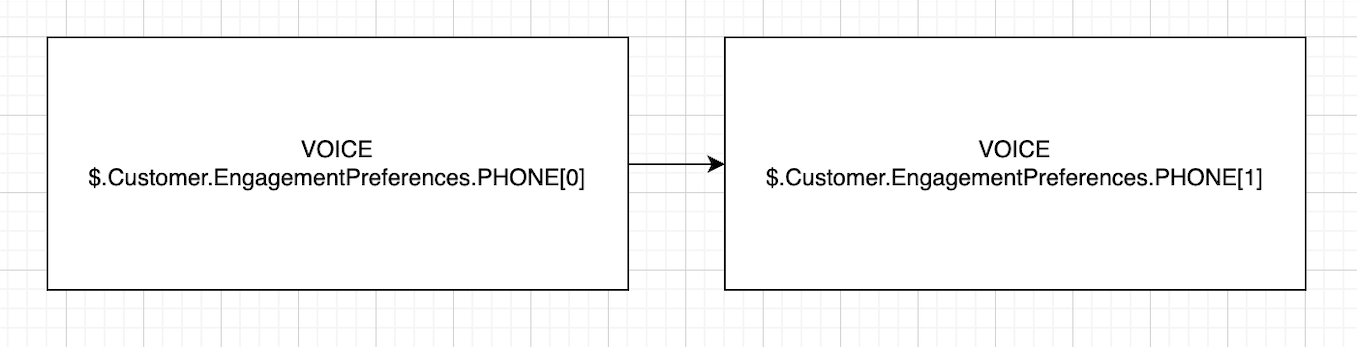
이 예제에서 캠페인은 다음 직접 호출 시퀀스를 사용하여 단일 계정을 대상으로 합니다.
-
John에게 첫 번째 연락 시도(ID: 2)
-
John이 응답하지 않으면 Sally(ID: 3)에게 백업 연락처로 전화를 겁니다.
-
-
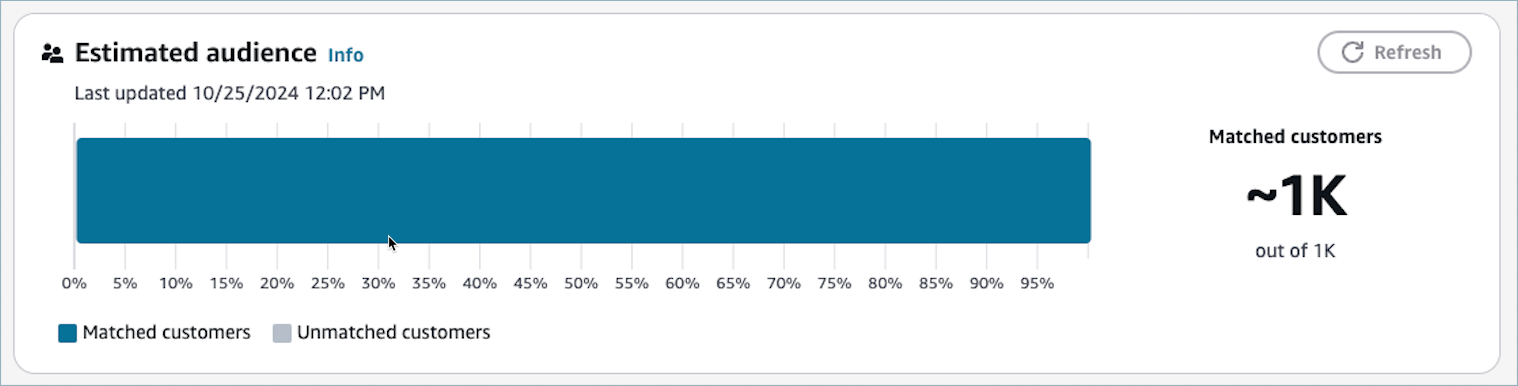
시작 대상을 선택하면 예상 잠재고객 섹션이 업데이트되어 적격 프로필이 표시됩니다. 대상 그룹을 편집한 후에는 예상 대상 섹션에서 새로 고침 버튼을 선택하여 추정치를 다시 가져올 수 있습니다.
4단계: 잠재고객 필터 선택 및 적용(선택 사항)
시작 잠재고객을 선택한 후 속성에 조건부 로직을 적용하여 잠재고객을 추가로 세분화할 수 있습니다. 세그먼트는 표준 프로필 속성, 사용자 지정 프로필 속성 및 계산된 속성을 지원합니다.
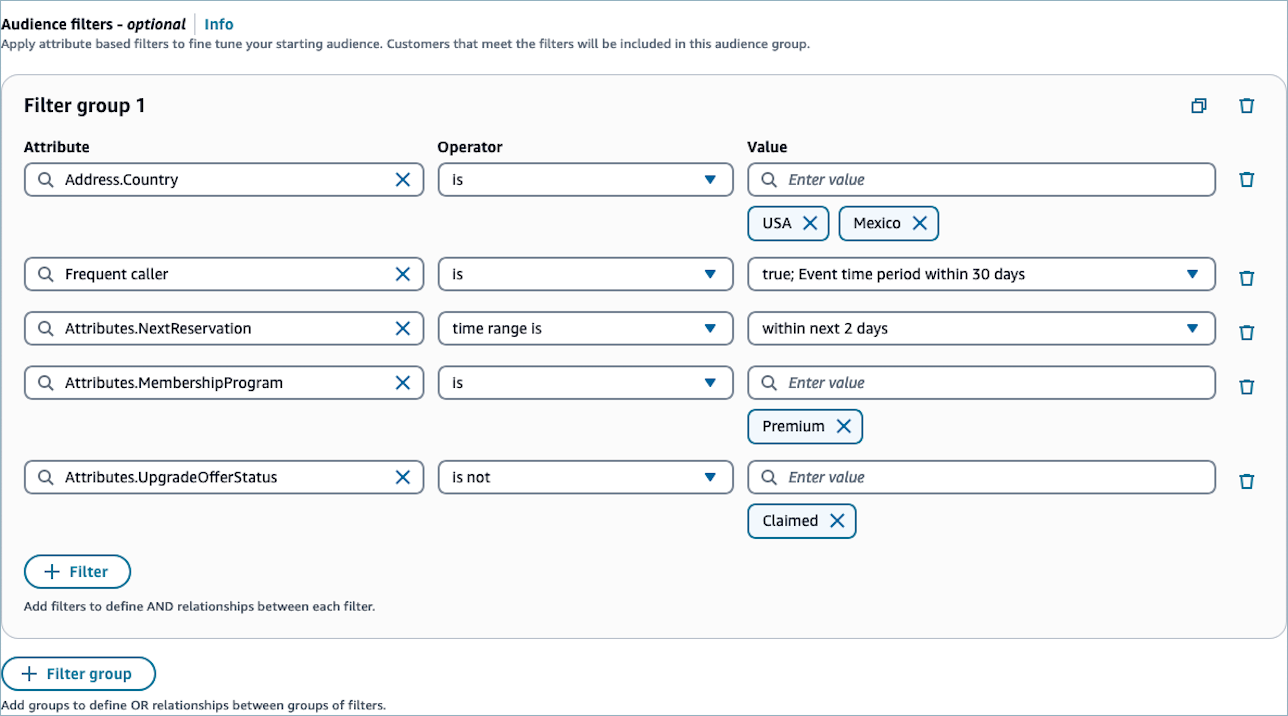
잠재고객 필터를 선택하고 구성하는 방법
-
속성에는 다음 유형 중에서 속성을 선택합니다.
-
계산된 속성 - 계산된 속성 중 하나를 기준으로 잠재고객을 필터링합니다.
기본 계산된 속성과 사용자 지정 계산된 속성을 구성하는 방법에 대한 자세한 내용은 Connect Customer Profiles에서 계산된 속성 설정 섹션을 참조하세요.
-
표준 속성 - 표준 프로필 속성 중 하나를 기준으로 잠재고객을 필터링합니다.
표준 프로필 속성 목록은 고객 프로필 연결의 표준 프로필 정의 섹션을 참조하세요.
-
사용자 지정 속성 - 사용자 지정 프로필 속성 중 하나를 기준으로 잠재고객을 필터링합니다.
참고
도메인 내에 최대 1,000개의 최신 프로필 속성을 저장합니다. 도메인에 많은 양의 속성이 포함된 경우 가장 오래된 속성이 이 목록에 표시되지 않을 수 있습니다.
-
-
연산자를 선택합니다. 연산자는 입력한 값에 대한 속성의 관계를 결정합니다. 다음은 사용 가능한 연산자에 대한 설명입니다. 사용 가능한 연산자는 선택한 속성의 값 유형에 따라 변경됩니다.
| 지원되는 속성 값 유형 | 연산자 | 설명 |
|---|---|---|
| 숫자 | 보다 큼 | 숫자 속성에만 사용됩니다. 이 연산자는 전달된 수보다 큰 결과를 필터링합니다. 예를 들어 고객의 평균 대기 시간이 10초를 초과합니다. |
| 크거나 같음 | 숫자 속성에만 사용됩니다. 이 연산자는 전달된 수보다 크거나 같은 결과를 필터링합니다. 예를 들어 고객의 평균 대기 시간은 10초 이상입니다. | |
| 같음 | 숫자 속성에만 사용됩니다. 이 연산자는 숫자 값 동등성을 기준으로 잠재고객을 필터링합니다. 예를 들어 고객의 평균 대기 시간이 10초입니다. | |
| 보다 작음 | 숫자 속성에만 사용됩니다. 이 연산자는 전달된 수보다 작은 결과를 필터링합니다. 예를 들어 고객의 평균 대기 시간이 10초 미만입니다. | |
| 작거나 같음 | 숫자 속성에만 사용됩니다. 이 연산자는 전달된 수보다 작거나 같은 결과를 필터링합니다. 예를 들어 고객의 평균 대기 시간이 10초 이하입니다. | |
| 문자열 | Is | 일치하는 잠재고객을 지정된 문자열로 필터링합니다. 예를 들어 고객의 Address.Country는 미국입니다. |
| Is not | 지정된 문자열과 일치하지 않는 잠재고객을 필터링합니다. 예를 들어 고객의 Address.Country는 미국이 아닙니다. | |
| 포함 | 문자열 내 하위 문자열을 기준으로 잠재고객을 필터링하려면 이 옵션을 사용합니다. 예를 들어 Address.Country 속성에 대한 필터가 있는 경우 미국을 전달하여 미국 또는 미국을 반환할 수 있습니다. | |
| 다음으로 시작 | 속성이 지정된 문자열로 시작하는 잠재고객을 필터링합니다. 예를 들어 고객의 Address.Country는 미국으로 시작합니다. | |
| 다음으로 끝남 | 속성이 지정된 문자열로 끝나는 잠재고객을 필터링합니다. 예를 들어 고객의 EmailAddress는 @amazon.com으로 끝납니다. | |
| Date | Before | 속성에 특정 날짜 이전의 날짜 값이 있는 잠재고객을 필터링합니다. 예를 들어 Attributes.NextReservation이 2024/10/01 이전인 고객의 입니다. |
| 켜짐 | 속성 값이 특정 날짜와 일치하는 잠재고객을 필터링합니다. 예를 들어 Attributes.NextReservation이 2024/10/01인 고객의 입니다. | |
| After | 속성에 특정 날짜 이후의 날짜 값이 있는 잠재고객을 필터링합니다. 예를 들어 Attributes.NextReservation이 2024/10/01 이후인 고객의 입니다. | |
| 시간 범위 | 속성에 특정 시간 범위 사이의 날짜 값이 있는 잠재고객을 필터링합니다. 절대 시간 모드 또는 상대 시간 모드에서 시간 범위를 지정할 수 있습니다. | |
| 절대 시간 모드: 절대 시간 범위를 지정할 수 있습니다. 예를 들어 2024/10/01 오전 12시에서 2024/10/07 오전 12시 사이입니다. | ||
| 상대 시간 모드: 사용하면 미래 또는 지난 X시간, 일, 주, 월 또는 연도의 상대 시간 범위를 지정할 수 있습니다. - 미래 시간 방향: 속성의 날짜 값이 현재 시간과 지정된 미래 시간 사이인 잠재고객을 필터링합니다. 예를 들어, 향후 2일 이내입니다. - 과거 시간 방향: 지정된 과거 시간과 현재 사이의 날짜 값을 가진 속성을 가진 잠재고객을 필터링합니다. 예를 들어 지난 2일 이내입니다. | ||
| 시간 범위가 아님 | 속성의 날짜 값이 특정 시간 범위 사이가 아닌 잠재고객을 필터링합니다. 절대 시간 모드 또는 상대 시간 모드에서 시간 범위를 지정할 수 있습니다. 자세한 내용은 이 테이블의 '시간 범위' 연산자를 참조하세요. |
참고
Connect Customer 관리자 웹 사이트의 고객 세그먼트는 모든 시간 기반 필터에 대해 UTC 시간대와 기본 시간 00:00:00 UTC를 사용합니다. 날짜를 기준으로 필터링 할 수 있지만 시간은 동일한 값으로 기록됩니다. 2024-1-1 날짜를 입력하면 콘솔은 이 시간을 2024-01-01T00:00:00Z로 전달합니다.
참고
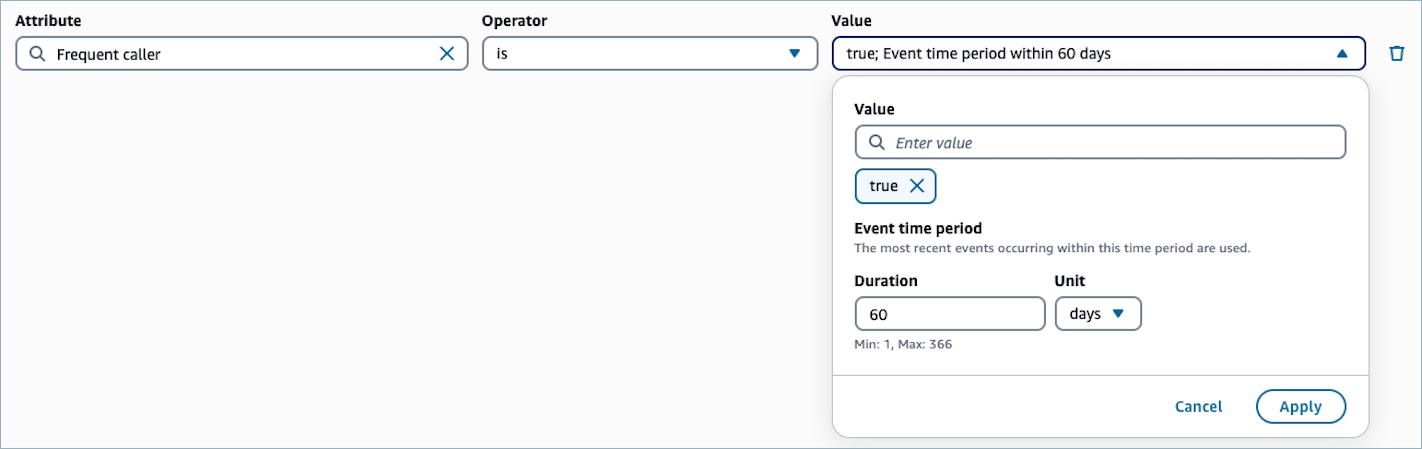
계산된 속성에 대한 필터를 지정할 때 계산된 속성 정의의 기간을 재정의할 수 있습니다. 예를 들어 필터 Frequent caller is true for the event time period of 60
days는 계산된 속성 정의에 구성된 기간 대신 지난 60일 이내에 값을 평가하도록 자주 전화하는 사람 고객 프로필 연결의 계산된 기본 속성을 재정의합니다. 이 재정의는 세그먼트에 고유하며 계산된 속성 정의 자체에는 영향을 주지 않습니다.
-
값을 지정합니다.
OR관계로 연결된 여러 값을 지정할 수 있습니다. 예:Address.Country는USA또는Mexico입니다. 값 입력은 도메인에 저장된 고객 프로필을 기반으로 문자열 연산자에 대한 제안 사항을 드롭다운에 표시합니다.참고
값은 대소문자를 구분합니다. 예를 들어 Address.Country is US는 Address.Country is us와 다른 결과를 반환합니다.
-
(선택 사항) 이 기준에 추가 속성을 적용하려면 필터 추가를 선택합니다. 다른 필터 그룹을 생성하려면 그룹 추가를 선택합니다.
참고
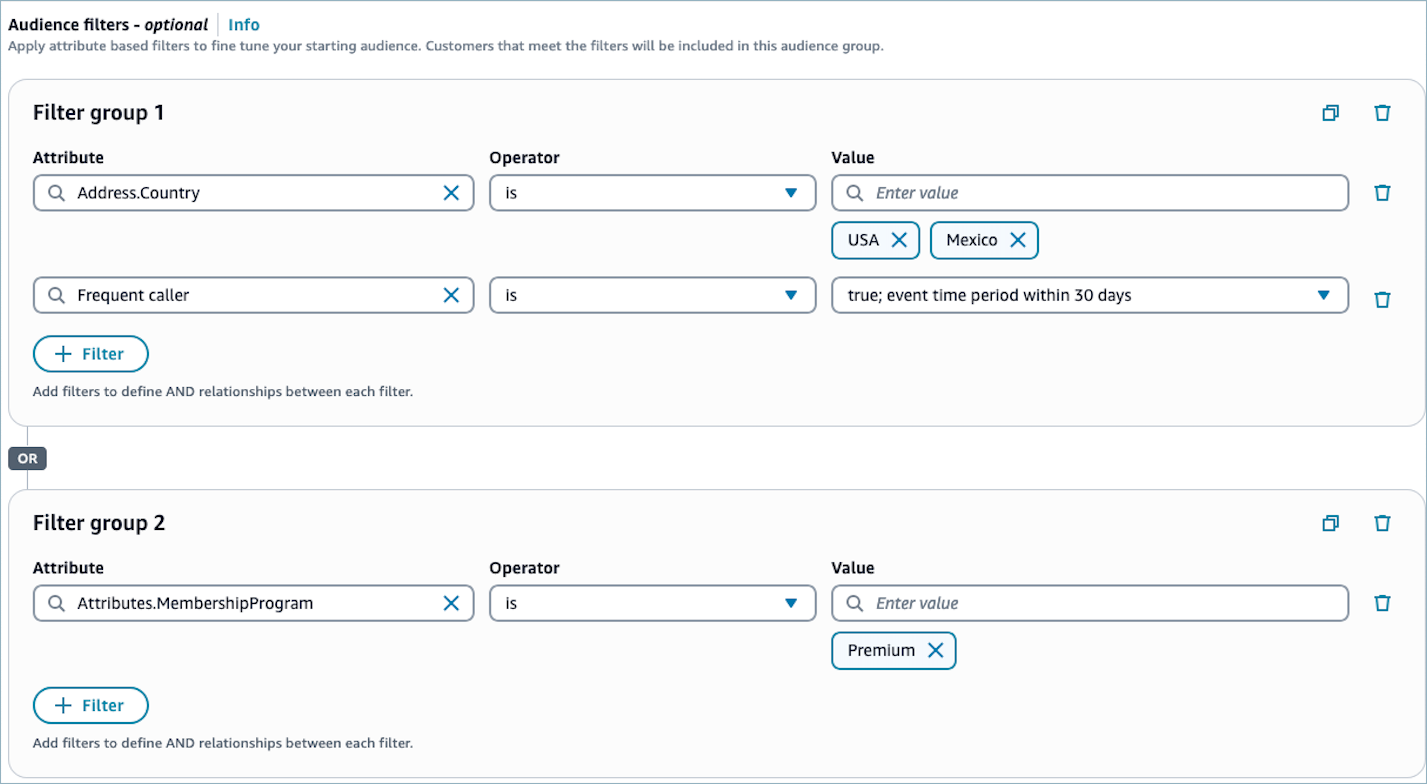
필터 그룹에 여러 필터가 있는 경우 필터는 AND 관계로 연결됩니다. 예를 들어 'Address.Country is USA' 및 'Customer'의 평균 대기 시간이 10초를 초과하는' 필터 2개가 포함된 필터 그룹은 Address.Country가 미국이고 평균 대기 시간이 10초를 초과하는 프로필이 세그먼트에 속합니다.
대상 그룹에 여러 필터 그룹이 있는 경우 Connect Customer 관리자 웹 사이트의 고객 세그먼트는 OR 관계를 사용하여 필터 그룹 간에 연결합니다.
-
잠재고객 그룹 설정이 끝나면 세그먼트 생성을 선택합니다.
5단계: 두 번째 잠재고객 그룹 추가(선택 사항)
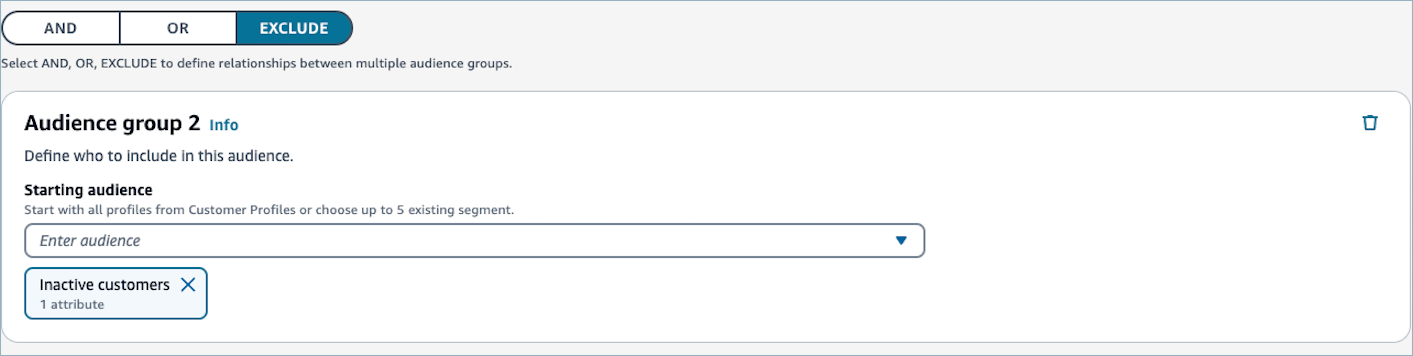
선택적으로 두 번째 잠재고객 그룹을 추가하고 잠재고객 그룹 1과의 관계를 정의합니다.Connect Customer 관리자 웹 사이트를 사용하여 고객 세그먼트를 생성할 때 세그먼트당 최대 2개의 잠재고객 그룹을 가질 수 있습니다. 세그먼트에 두 번째 잠재고객 그룹을 추가할 경우, 두 잠재고객 그룹 간의 연결 방식을 지정하는 두 가지 방법 중 하나를 선택할 수 있습니다.
-
AND 관계 - AND 관계를 사용하여 두 잠재고객을 연결하는 경우 세그먼트에는 잠재고객 그룹 1과 잠재고객 그룹 2의 필터를 모두 충족하는 모든 프로필이 포함됩니다.
-
OR 관계 - OR 관계를 사용하여 두 잠재고객을 연결하는 경우 세그먼트에는 잠재고객 그룹 1 또는 잠재고객 그룹 2의 필터를 충족하는 모든 프로필이 포함됩니다.
-
EXCLUDE 관계 - EXCLUDE 관계를 사용하여 두 잠재고객을 연결하는 경우 세그먼트에는 잠재고객 그룹 2의 프로필을 제외한 잠재고객 그룹 1의 프로필이 포함됩니다.
두 번째 잠재고객 그룹을 구성하는 방법
-
잠재고객 그룹 1을 구성한 후 SELECTAND, OR 또는 EXCLUDE 관계를 선택합니다.
-
잠재고객 그룹 2에서 시작 잠재고객을 선택합니다. 자세한 내용은 3단계: 잠재고객 그룹 1에 포함할 시작 잠재고객 선택 섹션을 참조하세요.
-
(선택 사항) 세그먼트 범위를 좁히고자 하는 필터를 선택합니다. 자세한 내용은 4단계: 잠재고객 필터 선택 및 적용(선택 사항) 섹션을 참조하세요.
-
세그먼트 설정이 끝나면 세그먼트 생성을 선택합니다. 세그먼트가 생성되었으므로 이제 아웃바운드 캠페인 또는 흐름에서 세그먼트를 사용할 수 있습니다.

6단계: 정렬 활성화(선택 사항)
선택적으로 세그먼트 결과에 대한 정렬을 구성합니다. 정렬을 사용하면 세그먼트 출력에 프로파일이 표시되는 순서를 제어할 수 있습니다. 최대 10개의 속성을 기준으로 정렬할 수 있습니다. 속성은 위에서 아래로 평가됩니다. 여러 프로필이 속성에 대해 동일한 값을 공유하는 경우 목록의 다음 속성이 타이브레이커 등으로 사용됩니다.
아웃바운드 캠페인과 여정은 실행 시이 정렬 순서를 준수합니다. 즉, 프로필이 세그먼트에서 정의한 순서대로 처리되고 다이얼링됩니다. 아웃바운드 캠페인에서 정렬된 세그먼트를 사용하는 방법에 대한 자세한 내용은 아웃바운드 캠페인 모범 사례를 참조하세요. 세그먼트 정렬은 다음을 수행할 때 유용합니다.
-
수명 값 또는 계정 티어와 같은 속성을 기준으로 정렬하여 고부가가치 고객의 우선순위를 정합니다.
-
약속 날짜를 기준으로 정렬하여 예정된 약속이 있는 고객에게 먼저 문의하세요.
-
시간에 민감한 통신을 특정 순서로 처리합니다.
참고
세그먼트 정렬 순서는 여정의 음성 캠페인 및 음성 활동에만 적용됩니다. 다른 통신 채널은 정렬되지 않은 순서로 프로필을 처리합니다.
정렬을 활성화하려면
-
정렬할 속성 이름을 입력합니다. 표준 또는 계산된 속성의 속성을 사용할 수 있습니다.
-
정렬 순서 지정: 오름차순 또는 내림차순을 선택합니다.
-
(선택 사항) 문자열, 숫자 또는 날짜를 선택하여 데이터 유형을 지정합니다. 유형을 지정하지 않으면 샘플링된 데이터를 기반으로 유형이 자동으로 추론됩니다.

Spark SQL로 구동되는 세그먼트 생성
Spark SQL로 구동되는 세그먼트를 사용하면 전체 Customer Profile 데이터와 확장된 기능을 사용하여 세그먼트를 정의할 수 있습니다. 표준 프로필 객체 속성과 사용자 지정 객체 속성을 사용할 수 있습니다. 표준 객체와 사용자 지정 객체를 함께 조인하여 다양한 객체의 데이터를 사용하고, 백분위수와 같은 통계로 세그먼트를 필터링하고, 비교를 위해 날짜 필드를 표준화하는 등의 SQL 기반 기능을 사용할 수도 있습니다.
Segment Assistant AI에 자연어 프롬프트를 입력하여 시작할 수 있습니다. 세그먼트 AI 어시스턴트는 Spark SQL로의 번역을 포함하여 세그먼트를 정의합니다. Segment Assistant AI는 세그먼트를 정의하는 데 수행한 단계를 제공하며 생성하려는 것과 일치하는지 확인할 수 있습니다. SQL, 자연어로 된 SQL 단계 및 Spark SQL의 AI 생성 요약을 보고 추가로 검증할 수도 있습니다. 변경하려면 자연어 프롬프트를 업데이트하거나 Spark SQL을 직접 편집할 수 있습니다.
Spark SQL 세그먼트를 직접 생성할 수도 있습니다.
클래식 분할과 마찬가지로 Spark SQL로 구동되는 세그먼트는 세그먼트 멤버십 호출, 흐름 블록 및 아웃바운드 캠페인에 사용할 수 있습니다.
고객 이벤트에 의해 시작된 세그먼트 멤버십 호출, 흐름 블록 또는 아웃바운드 캠페인에서 Spark SQL 세그먼트를 사용하는 경우 마지막으로 내보낸 세그먼트(세그먼트 스냅샷)를 사용합니다. 멤버십에 사용되는 세그먼트 스냅샷은 생성 후 1년이 지나면 만료됩니다. 4XX 오류가 발생하면 세그먼트(세그먼트 스냅샷)를 내보냈는지 확인합니다.
고객 세그먼트에서 시작한 아웃바운드 캠페인은 세그먼트(세그먼트 스냅샷)를 내보낼 필요가 없습니다.
참고
SQL 분할은 최대 10년의 데이터가 있는 데이터 스토어에서 실행됩니다. 클래식 세분화에서 최신 데이터 사용(지난 3년 동안 업데이트된 데이터)
1단계: 새 세그먼트 빌드
세그먼트 AI 어시스턴트에서 “세그먼트 생성 방법”을 선택하여 가치 있는 세그먼트 생성에 대한 자세한 지침을 보거나 “세그먼트 생성 방법”을 선택하여 자연어 프롬프트를 입력하여 세그먼트를 생성합니다.
또는 SQL을 사용하여 쿼리 편집기에서 새 세그먼트를 정의합니다.
2단계: 이름 및 설명 지정
이름에 나중에 쉽게 알아볼 수 있도록 고객 세그먼트의 이름을 입력합니다.
참고
Amazon Connect 관리자 웹 사이트는 입력한 이름을 세그먼트DisplayName의 로 사용하고 이를 기반으로 식별자를 생성합니다. 생성된 식별자는 Customer Profiles API를 사용하여 세그먼트에 액세스할 때 SegmentDefinitionName으로 사용됩니다.
(선택 사항) 설명에 고객 세그먼트에 대한 설명을 입력합니다.
3단계: 세그먼트 검토 및 검증
세그먼트 AI 어시스턴트가 사용한 데이터와 세그먼트를 생성하는 데 사용한 AI 모델을 검토합니다. 생성한 SQL을 검토하여 쿼리 편집기에서 세그먼트를 정의할 수도 있습니다. 세그먼트를 생성할 수 없는 경우 정확한 세그먼트를 생성하는 데 도움이 되도록 제공한 피드백을 해결합니다. 세그먼트가 생성되면 Customer Profiles는 자동으로 세그먼트 견적을 생성합니다.
편집하려면 쿼리 편집기에서 “새 대화”를 선택하거나 SQL을 생성/편집하여 새 프롬프트를 제공할 수 있습니다.
세그먼트 AI 어시스턴트를 사용하지 않는 경우 쿼리 편집기 아래의 “쿼리 검증 및 추정” 버튼을 선택하여 쿼리를 검증하고 견적을 생성할 수 있습니다.
참고
Spark SQL로 구동되는 세그먼트는 다른 쿼리 엔진과 마찬가지로 세그먼트 및 사용된 SQL에서 사용하는 프로필 데이터의 양에 따라 시간이 걸립니다(예: 객체 간 여러 조인에는 일반적으로 더 많은 시간이 소요됨).
4단계: 세그먼트 생성
세그먼트를 빌드하고 만족하면 오른쪽 상단의 “세그먼트 생성” 버튼을 선택합니다. 세그먼트를 생성한 후에는 흐름의 세그먼트를 사용하고 아웃바운드 캠페인의 세그먼트를 사용하여 작업 - .csv로 내보내기를 선택할 수 있습니다.
참고
아웃바운드 캠페인 또는 흐름 블록에서 세그먼트를 사용하는 경우 세그먼트가 마지막으로 생성된 시기에 따라 세그먼트 멤버십을 확인합니다. 흐름 또는 캠페인이 실행 중일 때 실시간 세그먼트 멤버십 검사가 필요한 경우 Classic 세분화를 사용합니다.
