翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
タスクを並列化する
パフォーマンスを最適化するには、データのロードと変換のタスクを並列化することが重要です。「Key topics in Apache Spark」で説明したように、回復力のある分散データセット (RDD) のパーティション数は並列処理の程度を決定するため重要です。Spark が作成する各タスクは、RDD パーティションと 1:1 で対応します。最適なパフォーマンスを実現するには、RDD パーティション数がどのように決定され、その数がどのように最適化されるかを理解しておく必要があります。
十分な並列処理がない場合、以下の症状が CloudWatch メトリクスと Spark UI に記録されます。
CloudWatch メトリクス
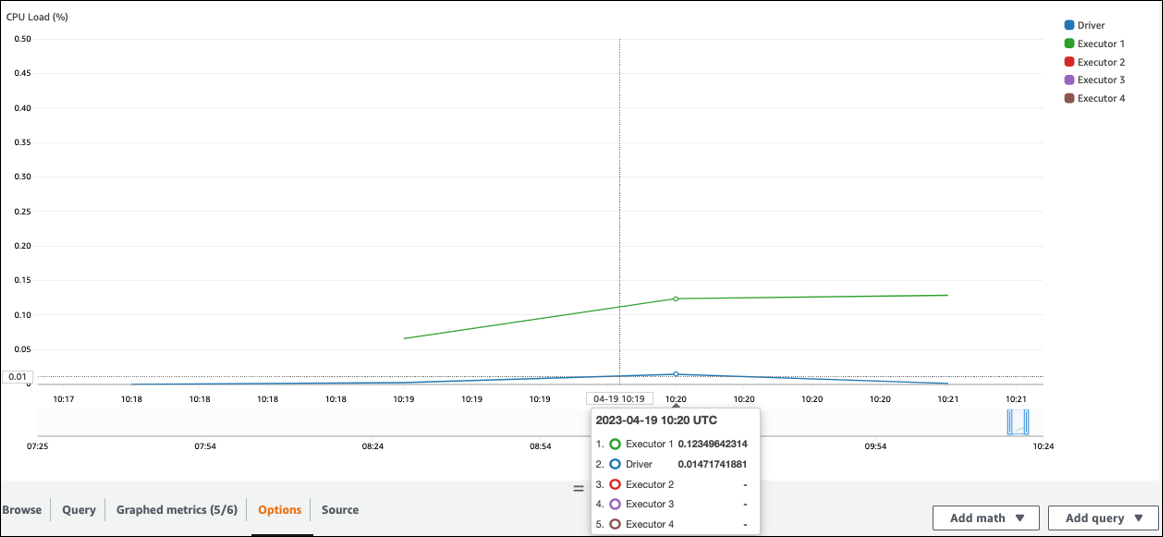
CPU 負荷とメモリ使用率を確認します。ジョブのあるフェーズで一部のエグゼキュターが処理を行っていない場合は、並列処理を改善することをお勧めします。この場合、視覚化された時間枠内ではエグゼキュター 1 がタスクを実行していましたが、残りのエグゼキュター (2、3、4) は実行していませんでした。これらのエグゼキュターには、Spark ドライバーからタスクが割り当てられていなかったと推測できます。
Spark UI
Spark UI の [ステージ] タブで、ステージ内のタスクの数を確認できます。この場合、Spark は 1 つのタスクのみを実行しています。

さらに、イベントタイムラインには、エグゼキュター 1 が 1 つのタスクを処理している様子が表示されます。つまり、このステージの処理はすべて 1 つのエグゼキュターで実行され、他のエグゼキュターはアイドル状態のままでした。

これらの症状が発生した場合は、データソースごとに次のソリューションを試してください。
Amazon S3 からのデータロードを並列化する
Amazon S3 からのデータロードを並列化するには、まずデフォルトのパーティション数を確認します。その後、ターゲットパーティション数を手動で決定できますが、パーティションが多すぎないように注意してください。
デフォルトのパーティション数を決定する
Amazon S3 の場合、Spark RDD の初期パーティション数 (各パーティションは 1 つの Spark タスクに対応) は、Amazon S3 データセットの特性 (形式、圧縮、サイズなど) によって決まります。Amazon S3 に保存されている CSV オブジェクトから AWS Glue DynamicFrame または Spark DataFrame を作成すると、RDD パーティションの初期数 (NumPartitions) を次のようにほぼ計算できます。
-
オブジェクトサイズ <= 64 MB:
NumPartitions = Number of Objects -
オブジェクトサイズ > 64 MB:
NumPartitions = Total Object Size / 64 MB -
分割不可 (gzip):
NumPartitions = Number of Objects
「Reduce the amount of data scan」セクションで説明したように、Spark は大きな S3 オブジェクトを分割して、並列処理が可能なスプリットにします。オブジェクトがスプリットサイズより大きい場合、Spark はオブジェクトを分割し、各スプリットに対して RDD パーティション (およびタスク) を作成します。Spark のスプリットサイズはデータ形式とランタイム環境に基づいていますが、おおよその開始値としては妥当です。一部のオブジェクトは gzip などの分割不可な圧縮形式で圧縮されているため、Spark では分割できません。
NumPartitions 値は、データ形式、圧縮、 AWS Glue バージョン、 AWS Glue ワーカー数、Spark 設定によって異なる場合があります。
例えば、Spark DataFrame を使用して単一の 10 GB の csv.gz オブジェクトをロードする場合、gzip は分割できないため、Spark ドライバーは RDD パーティションを 1 つだけ作成します (NumPartitions=1)。これにより、次の図に示すように、1 つの特定の Spark エグゼキュターに負荷が集中し、残りのエグゼキュターにはタスクが割り当てられません。
Spark Web UI の [ステージ] タブでステージの実際のタスク数 (NumPartitions) を確認するか、コード内で df.rdd.getNumPartitions() を実行して並列処理を確認します。
10 GB の gzip ファイルを扱う場合は、そのファイルを生成するシステムが分割可能な形式で生成できるかどうかを確認します。これが不可能な場合は、ファイルを処理するためにクラスター容量をスケールする必要がある場合があります。ロードしたデータに対して変換を効率的に実行するには、再パーティションを使用して、クラスター内のワーカー間で RDD を再分散する必要があります。
ターゲットパーティション数を手動で決定する
データのプロパティや Spark における特定機能の実装によっては、基盤となる処理を並列化できる場合でも、NumPartitions の値が低くなることがあります。NumPartitions が少なすぎる場合は、df.repartition(N) を実行してパーティション数を増やすことで、処理を複数の Spark エグゼキュターに分散できます。
この場合、df.repartition(100) を実行すると NumPartitions が 1 から 100 に増加し、データの 100 個のパーティションが作成され、それぞれに他のエグゼキュターへ割り当て可能なタスクが割り当てられます。
repartition(N) オペレーションは、データ全体を均等に分割し (10 GB/100 パーティション = 100 MB/パーティション)、特定のパーティションへのデータスキューを回避します。
注記
join などのシャッフルオペレーションを実行すると、spark.sql.shuffle.partitions または spark.default.parallelism の値に応じて、パーティションの数が動的に増減されます。これにより、Spark エグゼキュター間でのデータ交換をより効率的に実行できるようになります。詳細については、Spark ドキュメント
パーティションのターゲット数を決定する際の目標は、プロビジョニングされた AWS Glue ワーカーの使用を最大化することです。 AWS Glue ワーカーの数と Spark タスクの数は、vCPUs。Spark は、vCPU コアごとに 1 つのタスクをサポートします。 AWS Glue バージョン 3.0 以降では、次の式を使用してパーティションのターゲット数を計算できます。
# Calculate NumPartitions by WorkerType numExecutors = (NumberOfWorkers - 1) numSlotsPerExecutor = 4 if WorkerType is G.1X 8 if WorkerType is G.2X 16 if WorkerType is G.4X 32 if WorkerType is G.8X NumPartitions = numSlotsPerExecutor * numExecutors # Example: Glue 4.0 / G.1X / 10 Workers numExecutors = ( 10 - 1 ) = 9 # 1 Worker reserved on Spark Driver numSlotsPerExecutor = 4 # G.1X has 4 vCpu core ( Glue 3.0 or later ) NumPartitions = 9 * 4 = 36
この例では、各 G.1X ワーカーは Spark エグゼキュター (spark.executor.cores = 4) に 4 つの vCPU コアを提供します。Spark は vCPU コアごとに 1 つのタスクをサポートするため、G.1X Spark エグゼキュターは 4 つのタスクを同時に実行できます (numSlotPerExecutor)。このパーティション数は、タスクに同じ時間がかかる場合、クラスターを最大限に活用できます。ただし、一部のタスクは他のタスクより時間がかかるため、アイドルコアが発生します。このような場合は、ボトルネックとなるタスクを細分化して効率的にスケジュールするために、numPartitions を 2~3 倍に増やすことを検討してください。
パーティション数が多すぎる
パーティション数が過剰になると、タスク数も過剰になります。これにより、管理タスクや Spark エグゼキュター間のデータ交換など、分散処理に関連するオーバーヘッドによって Spark ドライバーに大きな負荷がかかります。
ジョブのパーティション数がターゲットパーティション数よりも著しく多い場合は、パーティション数を減らすことを検討してください。次のオプションを使用することで、パーティションを減らすことができます。
-
ファイルサイズが非常に小さい場合は、 AWS Glue groupFiles を使用します。これにより、各ファイルを処理するために Apache Spark タスクを起動することで発生する過剰な並列処理を抑えられます。
-
coalesce(N)を使用してパーティションをマージします。これは低コストのプロセスです。パーティション数を減らす場合は、repartition(N)よりcoalesce(N)を優先します。repartition(N)はシャッフルを発生させて各パーティション内のレコード数を均等に分散するため、コストと管理オーバーヘッドが増加します。 -
Spark 3.x のアダプティブクエリ実行を使用します。「Key topics in Apache Spark」セクションで説明したように、アダプティブクエリ実行はパーティション数を自動的に結合する機能を提供します。このアプローチは、ジョブを実行するまでパーティション数がわからない場合に使用できます。
JDBC からのデータロードを並列化する
Spark RDD のパーティション数は設定によって決まります。デフォルトでは、1 件の SELECT クエリでソースデータセット全体をスキャンするタスクが 1 つだけ実行されることに注意してください。
AWS Glue DynamicFrames と Spark DataFrames はどちらも、複数のタスクにわたる並列 JDBC データロードをサポートしています。これは、where 述語を使用して 1 件の SELECT クエリを複数のクエリに分割することによって行われます。JDBC からの読み取りを並列化するには、次のオプションを設定します。
-
For AWS Glue DynamicFrame の場合は、
hashfield(またはhashexpression)とhashpartition。詳細については、「JDBC テーブルからの並列読み取り」を参照してください。connection_mysql8_options = { "url": "jdbc:mysql://XXXXXXXXXX.XXXXXXX.us-east-1.rds.amazonaws.com:3306/test", "dbtable": "medicare_tb", "user": "test", "password": "XXXXXXXXX", "hashexpression":"id", "hashpartitions":"10" } datasource0 = glueContext.create_dynamic_frame.from_options( 'mysql', connection_options=connection_mysql8_options, transformation_ctx= "datasource0" ) -
Spark DataFrame の場合は、
numPartitions、partitionColumn、lowerBound、およびupperBoundを設定します。詳細については、「JDBC To Other Databases」を参照してください。 df = spark.read \ .format("jdbc") \ .option("url", "jdbc:mysql://XXXXXXXXXX.XXXXXXX.us-east-1.rds.amazonaws.com:3306/test") \ .option("dbtable", "medicare_tb") \ .option("user", "test") \ .option("password", "XXXXXXXXXX") \ .option("partitionColumn", "id") \ .option("numPartitions", "10") \ .option("lowerBound", "0") \ .option("upperBound", "1141455") \ .load() df.write.format("json").save("s3://bucket_name/Tests/sparkjdbc/with_parallel/")
ETL コネクタの使用時に DynamoDB からのデータロードを並列化する
Spark RDD のパーティション数は、dynamodb.splits パラメータによって決まります。Amazon DynamoDB からの読み取りを並列化するには、次のオプションを設定します。
-
dynamodb.splitsの値を増やします。 -
AWS Glue for Spark の ETL の接続タイプとオプションで説明されている式に従って、 パラメータを最適化します。
Kinesis Data Streams からのデータロードを並列化する
Spark RDD のパーティション数は、ソースの Amazon Kinesis Data Streams データストリームにおけるシャードの数によって決まります。データストリームのシャードが少ない場合、Spark タスクも少なくなるため、ダウンストリームプロセスにおける並列処理が低下する可能性があります。Kinesis Data Streams からの読み取りを並列化するには、次のオプションを設定します。
-
Kinesis Data Streams からデータをロードする際の並列処理を高めるために、シャード数を増やします。
-
マイクロバッチ内のロジックが複雑な場合は、不要な列を削除した後、バッチの開始時点でデータを再パーティション化することを検討してください。
詳細については、AWS Glue 「ストリーミング ETL ジョブのコストとパフォーマンスを最適化するためのベストプラクティス
データロード後にタスクを並列化する
データロード後にタスクを並列化するには、次のオプションを使用して RDD パーティション数を増やします。
-
特にロード処理自体を並列化できなかった場合は、初期ロード直後にデータを再パーティション化して、より多くのパーティションを生成します。
DynamicFrame または DataFrame に対して
repartition()を呼び出し、パーティション数を指定します。使用可能なコア数の 2~3 倍を目安とするのが一般的です。ただし、パーティションテーブルに書き込む際、ファイルが大量に生成される可能性があります (各パーティションが各テーブルパーティションにファイルを生成する可能性があるため)。これを回避するには、DataFrame を列単位で再パーティション化します。これは、テーブルのパーティション列を使用するため、書き込み前にデータが整理されます。この方法であれば、テーブルパーティション上に小さなファイルができるのを避けつつ、より多くのパーティション数を指定できます。ただし、一部のパーティション値にデータが集中してタスクの完了が遅れる「データスキュー」が発生しないよう注意が必要です。
-
シャッフルが発生する場合は、
spark.sql.shuffle.partitionsの値を増やします。これは、シャッフル時のメモリに関する問題の回避にも役立ちます。シャッフルパーティションが 2,001 を超えると、Spark は圧縮メモリ形式を使用します。値がこの上限に近い場合は、より効率的な表現を得るために、
spark.sql.shuffle.partitionsの値をそれ以上に設定することを検討します。
