翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
データスキャン量を削減する
まず、必要なデータのみをロードすることを検討してください。各データソースの Spark クラスターにロードされるデータの量を減らすだけで、パフォーマンスを向上させることができます。このアプローチが適切かどうかを評価するには、次のメトリクスを使用します。
Amazon S3 からの読み取りバイト数は CloudWatch メトリクスで確認できる他、「Spark UI」セクションで説明されているように Spark UI でも詳細を確認できます。
CloudWatch メトリクス
Amazon S3 からのおおよその読み取りサイズは、ETL データ移動 (バイト) で確認できます。このメトリクスは、前回のレポート以降に、すべてのエグゼキュターによって Amazon S3 から読み取られたバイト数を示します。これを使用して、Amazon S3 からの ETL データ移動をモニタリングでき、外部データソースからの取り込みレートと読み取り量を比較できます。
![書き込み S3 バイト数と読み取り S3 バイト数が表示されている、[ETL データ移動 (バイト)] のグラフメトリクスタブ。](images/etl-data-movements.png)
読み取り S3 バイト数のデータポイントが予想よりも大きい場合は、次の解決策を検討してください。
Spark UI
for Spark UI AWS Glue のステージタブで、入力サイズと出力サイズを確認できます。次の例では、ステージ 2 は 47.4 GiB の入力と 47.7 GiB の出力を読み取り、ステージ 5 は 61.2 MiB の入力と 56.6 MiB の出力を読み取ります。

AWS Glue ジョブで Spark SQL または DataFrame アプローチを使用すると、SQL / DataFrame タブにこれらのステージに関するより多くの統計が表示されます。この場合、ステージ 2 には、読み取りファイル数: 430、読み取りファイルサイズ: 47.4 GiB、出力行数: 160,796,570 が表示されます。
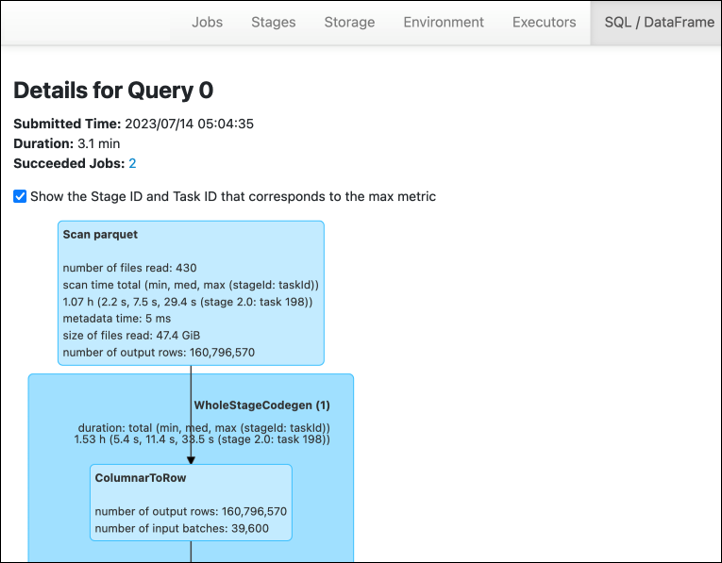
読み込んでいるデータと使用しているデータのサイズに大きな差がある場合、次の解決策を試してください。
Amazon S3
Amazon S3 から読み取るときにジョブにロードされるデータの量を減らすには、データセット のファイルサイズ、圧縮、ファイル形式、ファイルレイアウト (パーティション) を考慮してください。Spark ジョブ AWS Glue の場合、多くの場合、raw データの ETL に使用されますが、効率的な分散処理のためには、データソース形式の機能を検査する必要があります。
-
ファイルサイズ – 入力と出力のファイルサイズを中程度の範囲 (128 MB など) に維持することをお勧めします。ファイルが小さすぎても大きすぎても問題が発生する可能性があります。
小さなファイルが多数あると、次の問題が発生します。
-
多数のオブジェクトに対してリクエスト (
List、Get、Headなど) を行う際に発生するオーバーヘッドにより、Amazon S3 のネットワーク I/O に大きな負荷がかかります (同じデータの量を少数のオブジェクトに格納する場合と比較して)。 -
多数のパーティションやタスクが生成されるため、Spark ドライバーにおいて I/O および処理負荷が増大し、過剰な並列処理が発生します。
一方、ファイルタイプが分割不可 (gzip など) でファイルが大きすぎる場合、Spark アプリケーションは 1 つのタスクがファイル全体の読み取りを完了するまで待つ必要があります。
小さなファイルごとに Apache Spark タスクを作成するときに発生する過剰な並列処理を減らすには、DynamicFrames のファイルグループを使用します。このアプローチにより、Spark ドライバーから OOM 例外が発生する可能性が低くなります。ファイルグループ化を設定するには、
groupFilesおよびgroupSizeパラメータを設定します。次のコード例では、これらのパラメータを持つ ETL スクリプトで AWS Glue DynamicFrame API を使用しています。dyf = glueContext.create_dynamic_frame_from_options("s3", {'paths': ["s3://input-s3-path/"], 'recurse':True, 'groupFiles': 'inPartition', 'groupSize': '1048576'}, format="json") -
-
圧縮 — S3 オブジェクトのサイズが数百メガバイトある場合は、圧縮することを検討してください。圧縮形式にはさまざまな種類がありますが、大きく 2 種類に分類できます。
-
gzip などの分割不可の圧縮形式では、1 つのワーカーがファイル全体を解凍する必要があります。
-
bzip2 や LZO (インデックス付き) などの分割可能な圧縮形式では、ファイルの一部を解凍できるため、並列化が可能です。
Spark (およびその他の一般的な分散処理エンジン) では、エンジンが並列で処理できるチャンクにソースデータファイルを分割します。これらの単位はスプリットと呼ばれることがよくあります。データが分割可能な形式になると、最適化された AWS Glue リーダーは、特定のブロックのみを取得する
RangeオプションをGetObjectAPI に提供することで、S3 オブジェクトから分割を取得できます。次の図を参照して、これが実際にどのように機能するかを確認してください。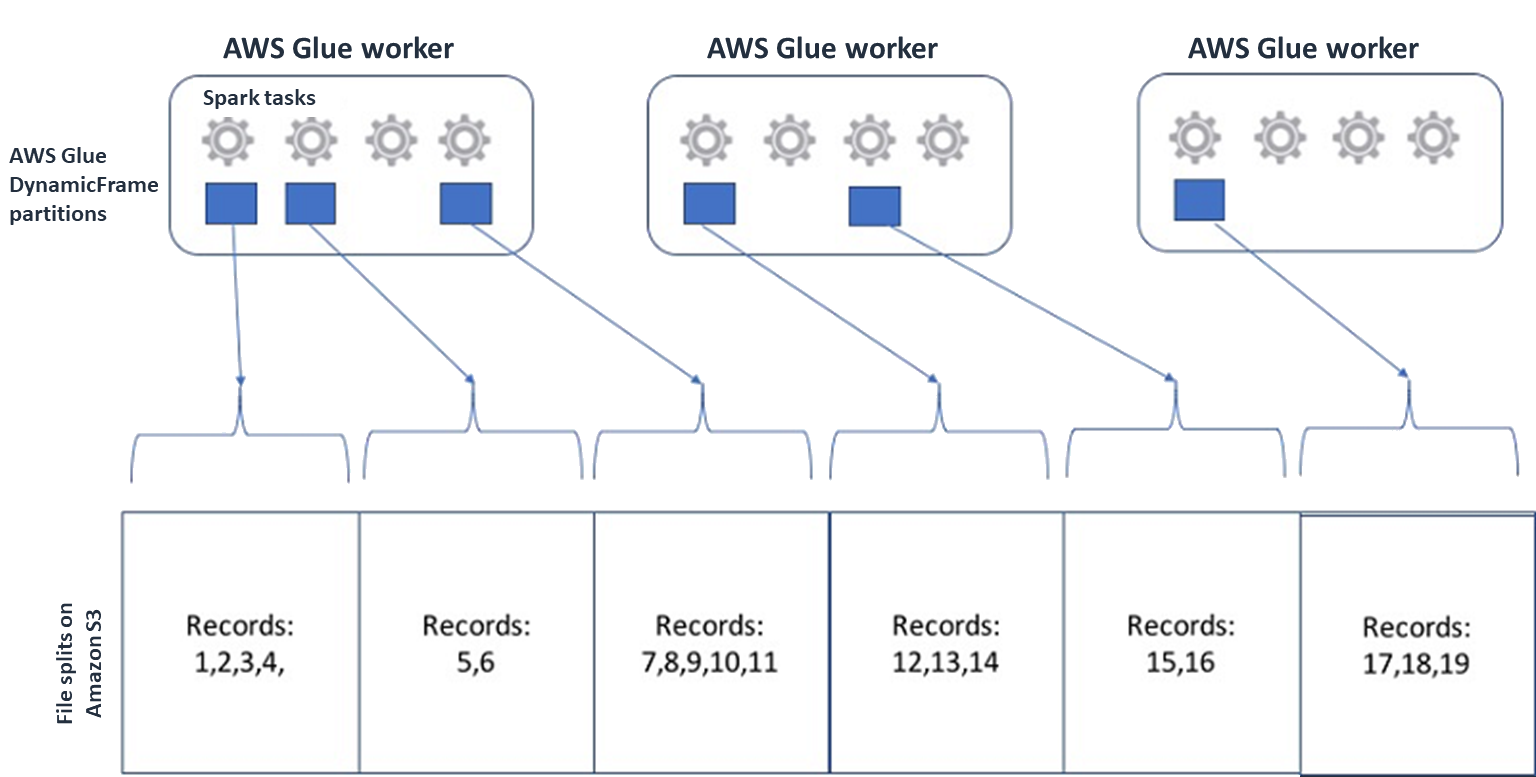
圧縮データは、ファイルが最適なサイズであるか、ファイルが分割可能である限り、アプリケーションを大幅に高速化できます。データサイズが小さいほど、Amazon S3 からスキャンされるデータや、Amazon S3 から Spark クラスターへのネットワークトラフィックが削減されます。一方で、データを圧縮および解凍するには、より多くの CPU が必要です。必要なコンピューティングの量は、圧縮アルゴリズムの圧縮率に応じてスケールされます。分割可能な圧縮形式を選択するときは、このトレードオフを考慮してください。
注記
gzip ファイルは一般に分割できませんが、個々の Parquet ブロックを gzip で圧縮することで、それらのブロックを並列化できます。
-
-
ファイル形式 – 列形式を使用します。Apache Parquet
と Apache ORC は、一般的な列指向のデータ形式です。Parquet と ORC は、列ベースの圧縮を使用し、各列をそのデータ型に基づいてエンコードおよび圧縮することで、データを効率的に保存します。Parquet エンコーディングの詳細については、「Parquet encoding definitions 」を参照してください。Parquet ファイルは分割可能でもあります。 列形式では、値を列ごとにフォーマットし、ブロックにまとめて保存します。列形式を使用すると、使用しない列に対応するデータのブロックをスキップできます。Spark アプリケーションでは、必要な列のみを取得できます。一般に、圧縮率の向上やデータのブロックスキップによって Amazon S3 から読み取るバイト数が減少し、パフォーマンスが向上します。どちらの形式も、I/O を削減するための以下のプッシュダウンアプローチをサポートしています。
-
射影プッシュダウン – 射影プッシュダウンは、アプリケーションで指定した列のみを取得する手法です。次の例に示すように、Spark アプリケーション内で列を指定します。
-
DataFrame の例:
df.select("star_rating") -
Spark SQL の例:
spark.sql("select start_rating from <table>")
-
-
述語プッシュダウン – 述語プッシュダウンは、
WHERE句およびGROUP BY句を効率的に処理するための手法です。どちらの形式にも、列値を表すデータのブロックがあります。各ブロックは、最大値や最小値など、そのブロックの統計を保持します。Spark は、アプリケーションで使用されるフィルター値に応じて、そのブロックを読み取るかスキップするかを判断するために、これらの統計を使用ます。この機能を使用するには、次の例に示すように、条件にフィルターを追加します。-
DataFrame の例:
df.select("star_rating").filter("star_rating < 2") -
Spark SQL の例:
spark.sql("select * from <table> where star_rating < 2")
-
-
-
ファイルレイアウト – データの使用方法に基づいて、S3 データを異なるパスのオブジェクトに保存することで、関連するデータを効率的に取得できます。詳細については、Amazon S3 ドキュメントの「プレフィックスを使用してオブジェクトを整理する」を参照してください。 AWS Glue は、
key=valueの形式でキーと値を Amazon S3 のプレフィックスに保存し、Amazon S3 パスによってデータをパーティション化することをサポートしています。データをパーティション化することで、各下流の分析アプリケーションによってスキャンされるデータの量を制限できるようになるため、パフォーマンスが向上し、コストが削減されます。詳細については、「 での ETL 出力のパーティションの管理 AWS Glue」を参照してください。パーティション化では、テーブルをさまざまな部分に分割し、次の例に示すように、年、月、日などの列値に基づいて関連するデータをグループ化されたファイルに保持します。
# Partitioning by /YYYY/MM/DD s3://<YourBucket>/year=2023/month=03/day=31/0000.gz s3://<YourBucket>/year=2023/month=03/day=01/0000.gz s3://<YourBucket>/year=2023/month=03/day=02/0000.gz s3://<YourBucket>/year=2023/month=03/day=03/0000.gz ...データセットのパーティションは、 AWS Glue Data Catalogのテーブルでモデル化することで定義できます。その後、次のようにパーティションプルーニングを使用して、データスキャンの量を制限できます。
-
For AWS Glue DynamicFrame で、
push_down_predicate(または ) を設定しますcatalogPartitionPredicate。dyf = Glue_context.create_dynamic_frame.from_catalog( database=src_database_name, table_name=src_table_name, push_down_predicate = "year='2023' and month ='03'", ) -
Spark DataFrame の場合は、パーティションをプルーニングする固定パスを設定します。
df = spark.read.format("json").load("s3://<YourBucket>/year=2023/month=03/*/*.gz") -
Spark SQL の場合は、データカタログからパーティションをプルーニングする where 句を設定できます。
df = spark.sql("SELECT * FROM <Table> WHERE year= '2023' and month = '03'") -
を使用してデータを書き込むときに日付でパーティション分割するには AWS Glue、次のようにDataFrame DynamicFrame の DynamicFrame または partitionBy()
に partitionKeys を列の日付情報とともに設定します。 -
DynamicFrame
glue_context.write_dynamic_frame_from_options( frame= dyf, connection_type='s3',format='parquet' connection_options= { 'partitionKeys': ["year", "month", "day"], 'path': 's3://<YourBucket>/<Prefix>/' } ) -
DataFrame
df.write.mode('append')\ .partitionBy('year','month','day')\ .parquet('s3://<YourBucket>/<Prefix>/')
これにより、出力データのコンシューマーのパフォーマンスを向上させることができます。
入力データセットを作成するパイプラインを変更するアクセス権限がない場合、パーティショニングは使用できません。代わりに、glob パターンを使用して不要な S3 パスを除外できます。DynamicFrame で読み取るときに除外を設定します。例えば、次のコードでは、2023 年の 01~09 月の日付を除外しています。
dyf = glueContext.create_dynamic_frame.from_catalog( database=db, table_name=table, additional_options = { "exclusions":"[\"**year=2023/month=0[1-9]/**\"]" }, transformation_ctx='dyf' )データカタログのテーブルプロパティで除外を設定することもできます。
-
キー:
exclusions -
値:
["**year=2023/month=0[1-9]/**"]
-
-
-
Amazon S3 パーティションが多すぎる場合 – 数千の値を持つ ID 列など、値の範囲が広い列で Amazon S3 データをパーティション化することは避けてください。これにより、可能なパーティションの数が、パーティション化したすべてのフィールドの積になるため、バケット内のパーティションの数が大幅に増加する可能性があります。パーティションが多すぎると、以下が発生する可能性があります。
-
データカタログからパーティションメタデータを取得する際のレイテンシーが増加する
-
小さなファイルの数が増え、Amazon S3 API へのリクエスト (
List、Get、Head) が増加する
例えば、
partitionByまたはpartitionKeysで日付タイプを設定する場合、yyyy/mm/ddのような日付レベルのパーティショニングは、多くのユースケースに適しています。ただし、yyyy/mm/dd/<ID>のような形式は、非常に多くのパーティション数を生成する可能性があり、パフォーマンス全体に悪影響を与える可能性があります。一方、リアルタイム処理アプリケーションなどの一部のユースケースでは、
yyyy/mm/dd/hhのような多くのパーティションが必要になります。ユースケースで大量のパーティションが必要な場合は、データカタログからパーティションメタデータを取得する際のレイテンシーを短縮するために、AWS Glue のパーティションインデックスを使用することを検討してください。 -
データベースと JDBC
データベースから情報を取得するときにデータスキャンを減らすには、SQL クエリで where 述語 (または句) を指定できます。SQL インターフェイスを提供しないデータベースは、クエリやフィルタリングのための独自のメカニズムを提供します。
Java Database Connectivity (JDBC) 接続を使用する場合は、次のパラメータに対して where 句を含む select クエリを指定します。
-
DynamicFrame の場合は、sampleQuery オプションを使用します。
create_dynamic_frame.from_catalogを使用する場合は、additional_options引数を次のように設定します。query = "SELECT * FROM <TableName> where id = 'XX' AND" datasource0 = glueContext.create_dynamic_frame.from_catalog( database = db, table_name = table, additional_options={ "sampleQuery": query, "hashexpression": key, "hashpartitions": 10, "enablePartitioningForSampleQuery": True }, transformation_ctx = "datasource0" )using create_dynamic_frame.from_optionsを使用する場合は、connection_options引数を次のように設定します。query = "SELECT * FROM <TableName> where id = 'XX' AND" datasource0 = glueContext.create_dynamic_frame.from_options( connection_type = connection, connection_options={ "url": url, "user": user, "password": password, "dbtable": table, "sampleQuery": query, "hashexpression": key, "hashpartitions": 10, "enablePartitioningForSampleQuery": True } ) -
DataFrame の場合は、query
オプションを使用します。 query = "SELECT * FROM <TableName> where id = 'XX'" jdbcDF = spark.read \ .format('jdbc') \ .option('url', url) \ .option('user', user) \ .option('password', pwd) \ .option('query', query) \ .load() -
Amazon Redshift の場合は、 AWS Glue 4.0 以降を使用して Amazon Redshift Spark コネクタのプッシュダウンサポートを活用します。
dyf = glueContext.create_dynamic_frame.from_catalog( database = "redshift-dc-database-name", table_name = "redshift-table-name", redshift_tmp_dir = args["temp-s3-dir"], additional_options = {"aws_iam_role": "arn:aws:iam::role-account-id:role/rs-role-name"} ) -
他のデータベースについては、そのデータベースのドキュメントを参照してください。
AWS Glue オプション
-
すべての連続ジョブ実行に対して完全なスキャンを回避し、前回のジョブ実行時に存在しなかったデータのみを処理するには、ジョブのブックマークを有効にします。
-
処理する入力データの量を制限するには、ジョブのブックマークを使用して制限付き実行を有効にします。これにより、ジョブ実行ごとにスキャンされるデータの量を減らすことができます。
