翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
クラスター容量をスケールする
ジョブの処理に時間がかかっているものの、エグゼキュターが十分なリソースを消費しており、Spark が使用可能なコア数に対して多数のタスクを生成している場合は、クラスター容量のスケーリングを検討してください。これが適切かどうかを評価するには、次のメトリクスを使用します。
CloudWatch メトリクス
-
エグゼキュターが十分なリソースを消費しているかどうかを判断するには、CPU 負荷とメモリ使用率を確認します。
-
処理時間がパフォーマンス目標を満たすには長すぎるかどうかを評価するには、ジョブの実行時間を確認します。
次の例では、4 つのエグゼキュターが 97% を超える CPU 負荷で実行されていますが、約 3 時間経過しても処理は完了していません。
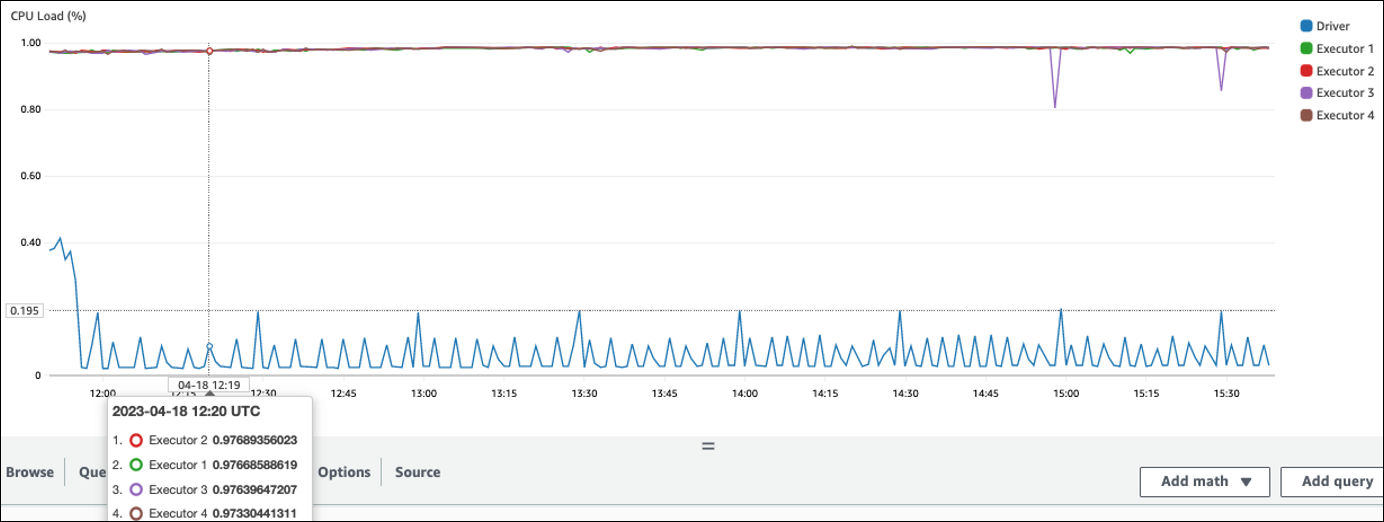
注記
CPU 負荷が低い場合、クラスター容量をスケーリングしてもおそらく効果は見込めません。
Spark UI
[ジョブ] タブまたは [ステージ] タブで、各ジョブまたはステージのタスク数を確認できます。次の例では、Spark が 58100 個のタスクを作成しています。
![1 つのステージと 58,100 個のタスクが表示されている [すべてのジョブのステージ]。](images/stages-for-all-jobs.png)
[エグゼキュター] タブには、エグゼキュターとタスクの合計数が表示されます。次のスクリーンショットでは、各 Spark エグゼキュターには 4 つのコアがあり、4 つのタスクを同時に実行できます。
![[コア] 列が表示されている [エグゼキュター] テーブル。](images/executors-tab-cores.png)
この例では、Spark タスク数 (58100)) は、エグゼキュターが同時に処理できる 16 個のタスク (4 個のエグゼキュター x 4 個のコア) を大きく上回っています。
このような状況が発生した場合は、クラスターのスケーリングを検討してください。クラスター容量は、次のオプションを使用してスケーリングできます。
-
Enable AWS Glue Auto Scaling – Auto Scaling は、 AWS Glue バージョン 3.0 以降の AWS Glue 抽出、変換、ロード (ETL) およびストリーミングジョブで使用できます。 は、各ステージのパーティション数またはジョブ実行時にマイクロバッチが生成される速度に応じて、クラスターからワーカー AWS Glue を自動的に追加および削除します。
Auto Scaling が有効になっていてもワーカー数が増加しない状況が発生した場合は、ワーカーを手動で追加することを検討してください。ただし、1 つのステージで手動スケーリングを行うと、後続のステージで多くのワーカーがアイドル状態になり、パフォーマンスの向上がないままコストが増加する可能性があることに注意してください。
Auto Scaling を有効にすると、CloudWatch エグゼキュターメトリクスにエグゼキュターの数が表示されます。Spark アプリケーションにおけるエグゼキュターの需要をモニタリングするには、次のメトリクスを使用します。
-
glue.driver.ExecutorAllocationManager.executors.numberAllExecutors -
glue.driver.ExecutorAllocationManager.executors.numberMaxNeededExecutors
メトリクスの詳細については、Amazon CloudWatch メトリクス AWS Glue を使用したモニタリング」を参照してください。
-
-
スケールアウトする: AWS Glue ワーカーの数を増やす – AWS Glue ワーカーの数を手動で増やすことができます。アイドル状態のワーカーが確認されるまでワーカーを追加します。この時点でさらにワーカーを追加しても、結果が改善されずコストが増加します。詳細については、「タスクを並列化する」を参照してください。
-
スケールアップ: より大きなワーカータイプを使用する – AWS Glue ワーカーのインスタンスタイプを手動で変更して、より多くのコア、メモリ、ストレージを持つワーカーを使用できます。より大きなワーカータイプを使用すると、メモリ集約型のデータ変換、偏りのある集約、ペタバイト規模のデータを含むエンティティ検出チェックなど、負荷の高いデータ統合ジョブを垂直スケーリングで実行できます。
スケールアップは、例えばジョブのクエリプランがかなり大きいことが原因で、Spark ドライバーにより大きな容量が必要な場合にも有効です。ワーカータイプとパフォーマンスの詳細については、 AWS Big Data Blog の記事「Scale your AWS Glue for Apache Spark jobs with new larger worker types G.4X and G.8X
」を参照してください。 より大きなワーカータイプを使用すると、必要なワーカーの合計数を減らすこともできます。これにより、結合などの高負荷な処理でシャッフルを減らし、パフォーマンスを向上させます。
