翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
Apache Spark の主要なトピック
このセクションでは、Apache Spark のパフォーマンス AWS Glue を調整するための Apache Spark の基本概念と主要なトピックについて説明します。実際のチューニング戦略について話し合う前に、これらの概念とトピックを理解しておくことが重要です。
アーキテクチャ
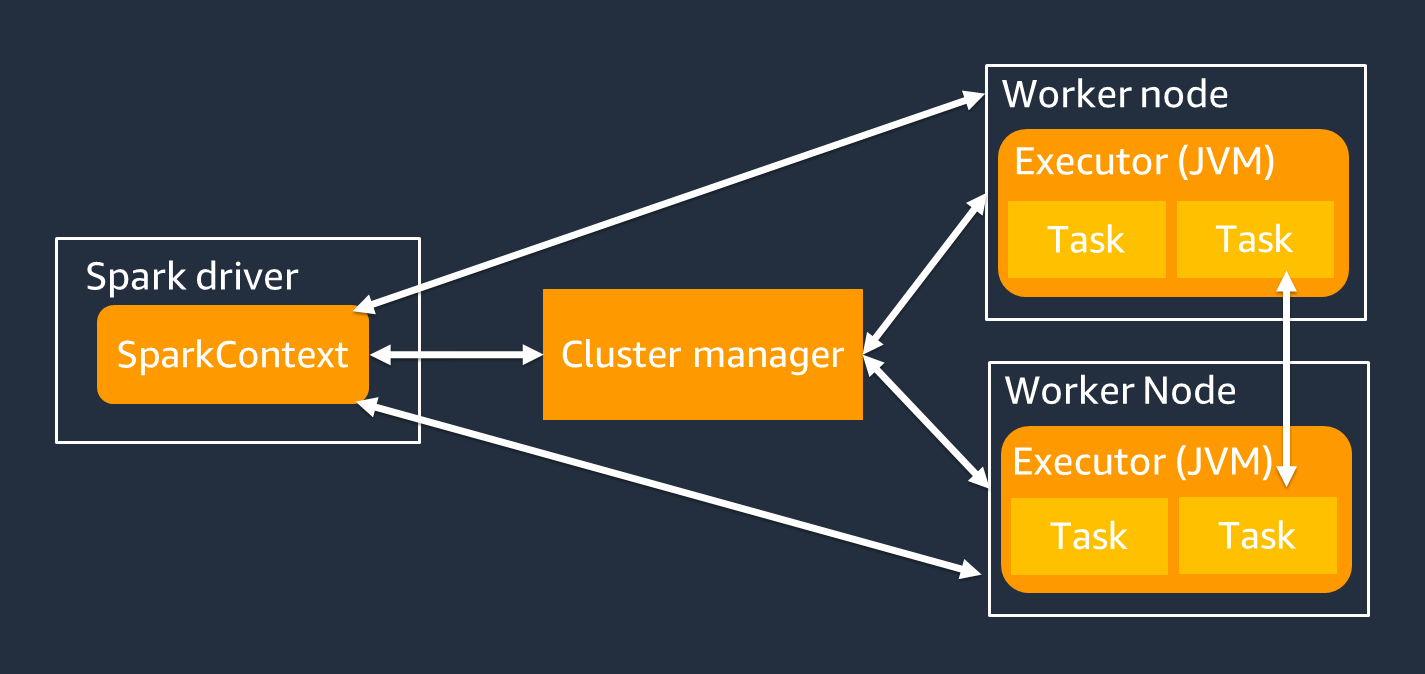
Spark ドライバーは主に、Spark アプリケーションを個々のワーカーで実行できるタスクに分割します。Spark ドライバーには次の責任があります。
-
コード内の
main()を実行する -
実行プランを生成する
-
クラスターのリソースを管理するクラスターマネージャーと連携して、Spark エグゼキュターをプロビジョニングする
-
Spark エグゼキュターに対するタスクをスケジュールし、リクエストする
-
タスクの進行状況と復旧を管理する
ジョブ実行では、SparkContext オブジェクトを使用して Spark ドライバーを操作します。
Spark エグゼキュターは、Spark ドライバーから渡されるデータを保持し、タスクを実行するワーカーです。Spark エグゼキュターの数は、クラスターのサイズに応じて増減します。
注記
Spark エグゼキュターには複数のスロットがあるため、複数のタスクを並列に処理できます。Spark は、デフォルトで仮想 CPU (vCPU) コアごとに 1 つのタスクをサポートします。例えば、エグゼキュターに 4 つの CPU コアがある場合、4 つのタスクを同時に実行できます。
耐障害性のある分散データセット
Spark は、Spark エグゼキュター全体で大規模なデータセットを保存および追跡する複雑なジョブを実行します。Spark ジョブのコードを記述するときは、ストレージの詳細について考える必要はありません。Spark は、耐障害性のある分散データセット (RDD) という抽象化を提供します。これは、並列に操作でき、クラスターの Spark エグゼキュター全体に分割できる要素のコレクションです。
次の図は、Python スクリプトを一般的な環境で実行した場合と、Spark フレームワーク (PySpark) で実行した場合で、メモリ内にデータを保存する方法の違いを示しています。
![Python val [1,2,3 N]、Apache Spark rdd = sc.parallelize[1,2,3 N]。](images/store-data-memory.png)
-
Python – Python スクリプトで
val = [1,2,3...N]のように記述すると、データはコードが実行されている単一のマシンのメモリに保持されます。 -
PySpark – Spark は、複数の Spark エグゼキュターのメモリに分散されたデータをロードして処理するための RDD データ構造を提供します。例えば、
rdd = sc.parallelize[1,2,3...N]のようなコードで RDD を生成でき、Spark はデータを複数の Spark エグゼキュターのメモリに自動的に分散して保持できます。多くの AWS Glue ジョブでは、DynamicFrames と Spark DataFrames を介して AWS Glue RDDs を使用します。これらは、RDD 内のデータのスキーマを定義し、その追加情報を使用して高レベルのタスクを実行できるようにする抽象化です。これらは内部的に RDD を使用するため、次のコードではデータが複数ノードに透過的に分散およびロードされます。
-
DynamicFrame
dyf= glueContext.create_dynamic_frame.from_options( 's3', {"paths": [ "s3://<YourBucket>/<Prefix>/"]}, format="parquet", transformation_ctx="dyf" ) -
DataFrame
df = spark.read.format("parquet") .load("s3://<YourBucket>/<Prefix>")
-
RDD には次の機能があります。
-
RDD は、パーティションと呼ばれる複数の部分に分割されたデータで構成されます。各 Spark エグゼキュターは 1 つ以上のパーティションをメモリに保存し、データは複数のエグゼキュターに分散されます。
-
RDD はイミュータブルです。つまり、作成後に変更することはできません。DataFrame を変更するには、次のセクションで定義されている変換を使用できます。
-
RDD は使用可能なノード間でデータをレプリケートするため、ノード障害から自動的に復旧できます。
遅延評価
RDD は、2 種類のオペレーションをサポートします。一つは、既存のデータセットから新しいデータセットを作成する変換、もう一つはデータセットで計算を実行した後にドライバープログラムに値を返すアクションです。
-
変換 – RDD はイミュータブルであるため、変換を使用してのみ変更できます。
例えば、
mapは各データセット要素を関数に渡し、結果を表す新しい RDD を返す変換です。mapメソッドは出力を返さない点に注意してください。Spark は、結果を返す代わりに、抽象的な変換を将来のために保存します。Spark は、アクションが呼び出されるまで、変換を実行しません。 -
アクション – 変換を使用して、論理変換プランを構築します。計算を開始するには、
write、count、show、collectなどのアクションを実行します。Spark のすべての変換は遅延評価であり、結果はすぐには計算されません。代わりに、Spark は Amazon Simple Storage Service (Amazon S3) オブジェクトなど、一部のベースデータセットに適用された一連の変換を記憶します。これらの変換は、アクションが結果をドライバーに返す必要がある場合にのみ計算されます。この設計により、Spark はより効率的に処理を実行できます。例えば、
map変換によって作成されたデータセットが、reduceのように行数を大幅に削減する変換によってのみ使用される状況を考えてみましょう。その場合、マッピングされた大きなデータセットを渡す代わりに、両方の変換を行った小さなデータセットをドライバーに渡すことができます。
Spark アプリケーションの用語
このセクションでは、Spark アプリケーションの用語について説明します。Spark ドライバーは実行プランを作成し、いくつかの抽象化を通じてアプリケーションの動作を制御します。Spark UI を使用した開発、デバッグ、パフォーマンスチューニングにおいては、以下の用語が重要です。
-
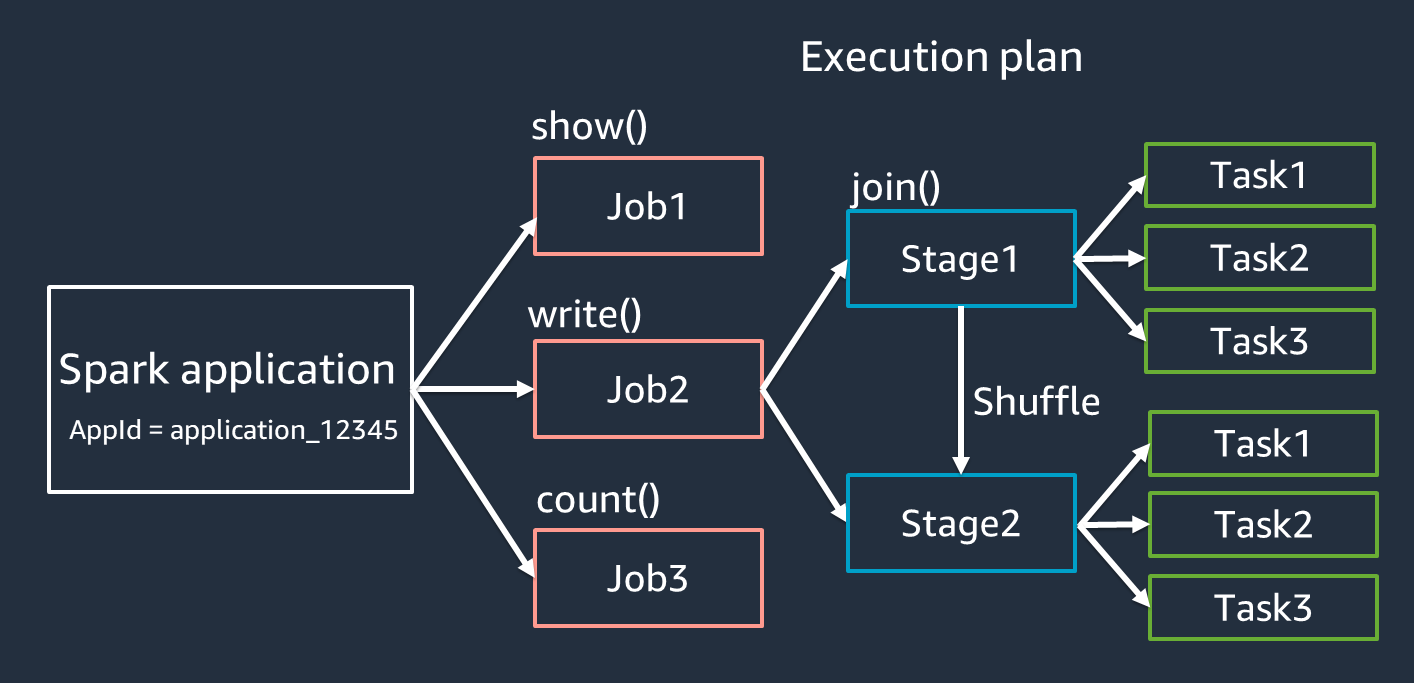
アプリケーション – Spark セッション (Spark コンテキスト) に基づきます。
<application_XXX>のような一意の ID で識別されます。 -
ジョブ – RDD に対して作成されたアクションに基づきます。ジョブは 1 つ以上のステージで構成されます。
-
ステージ – RDD に対して作成されたシャッフルに基づきます。ステージは 1 つ以上のタスクで構成されます。シャッフルは、RDD パーティション全体でデータを再分散し、異なるグループにまとめ直すための Spark のメカニズムです。
join()などの特定の変換ではシャッフルが必要です。シャッフルの詳細については、「Optimize shuffles」チューニングプラクティスを参照してください。 -
タスク – タスクは、Spark によってスケジュールされた処理の最小単位です。タスクは RDD パーティションごとに作成され、タスクの数はステージ内の同時実行の最大数です。
注記
並列処理を最適化するときに考慮すべき最も重要なものはタスクです。タスクの数は、RDD の数に応じてスケールします。
並列処理
Spark は、データをロードおよび変換するためのタスクを並列処理します。
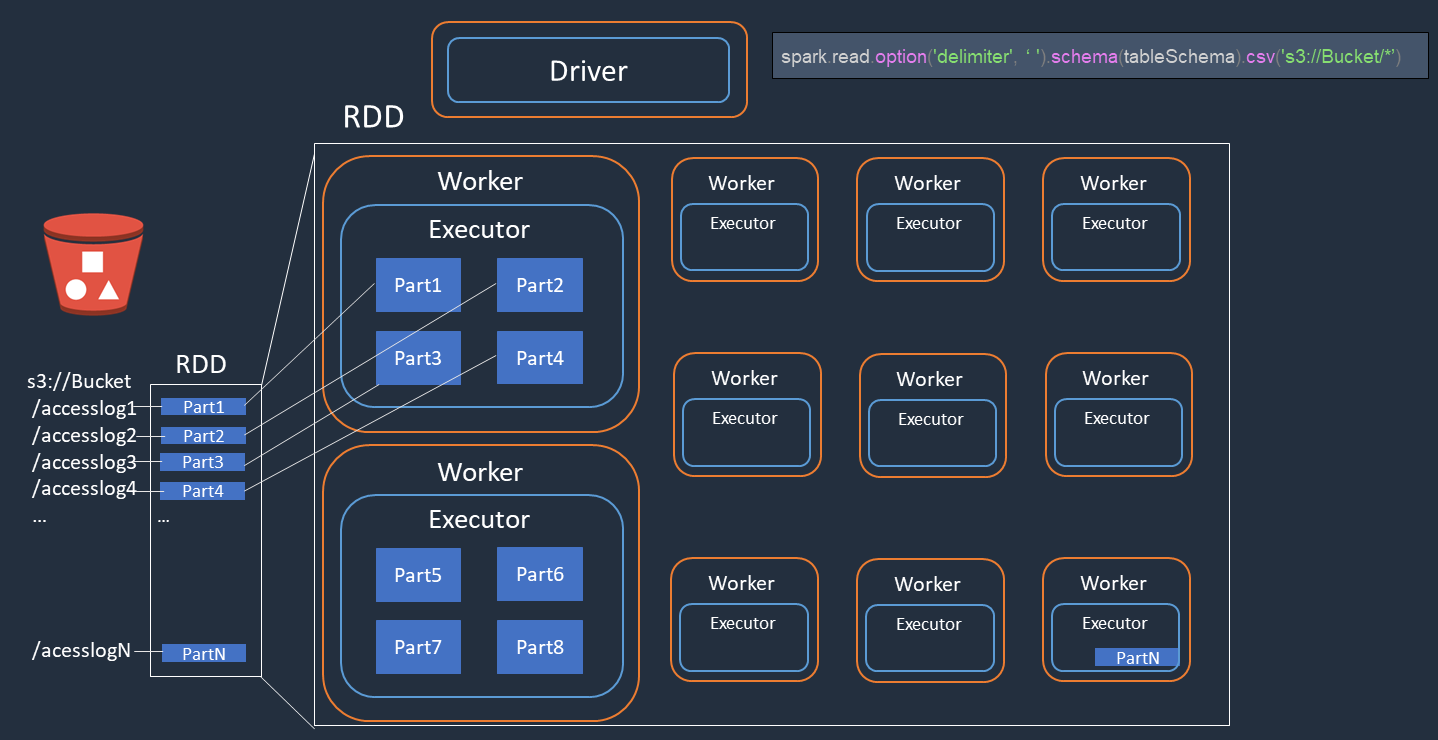
Amazon S3 でアクセスログファイル (accesslog1 ... accesslogN という名前) の分散処理を実行する例を考えてみましょう。次の図は、分散処理フローを示しています。
-
Spark ドライバーは、多くの Spark エグゼキュターにまたがる分散処理の実行計画を作成します。
-
Spark ドライバーは、実行計画に基づいて各エグゼキュターにタスクを割り当てます。デフォルトでは、Spark ドライバーは、S3 オブジェクト (
Part1 ... N) ごとに RDD パーティション (それぞれが 1 つの Spark タスクに対応) を作成します。次に、Spark ドライバーは各エグゼキュターにタスクを割り当てます。 -
各 Spark タスクは、割り当てられた S3 オブジェクトをダウンロードし、RDD パーティションのメモリに保存します。このようにして、複数の Spark エグゼキュターが、それぞれに割り当てられたタスクを並列にダウンロードして処理します。
パーティションの初期数と最適化の詳細については、「Parallelize tasks」セクションを参照してください。
Catalyst オプティマイザ
内部的には、Spark は Catalyst オプティマイザ
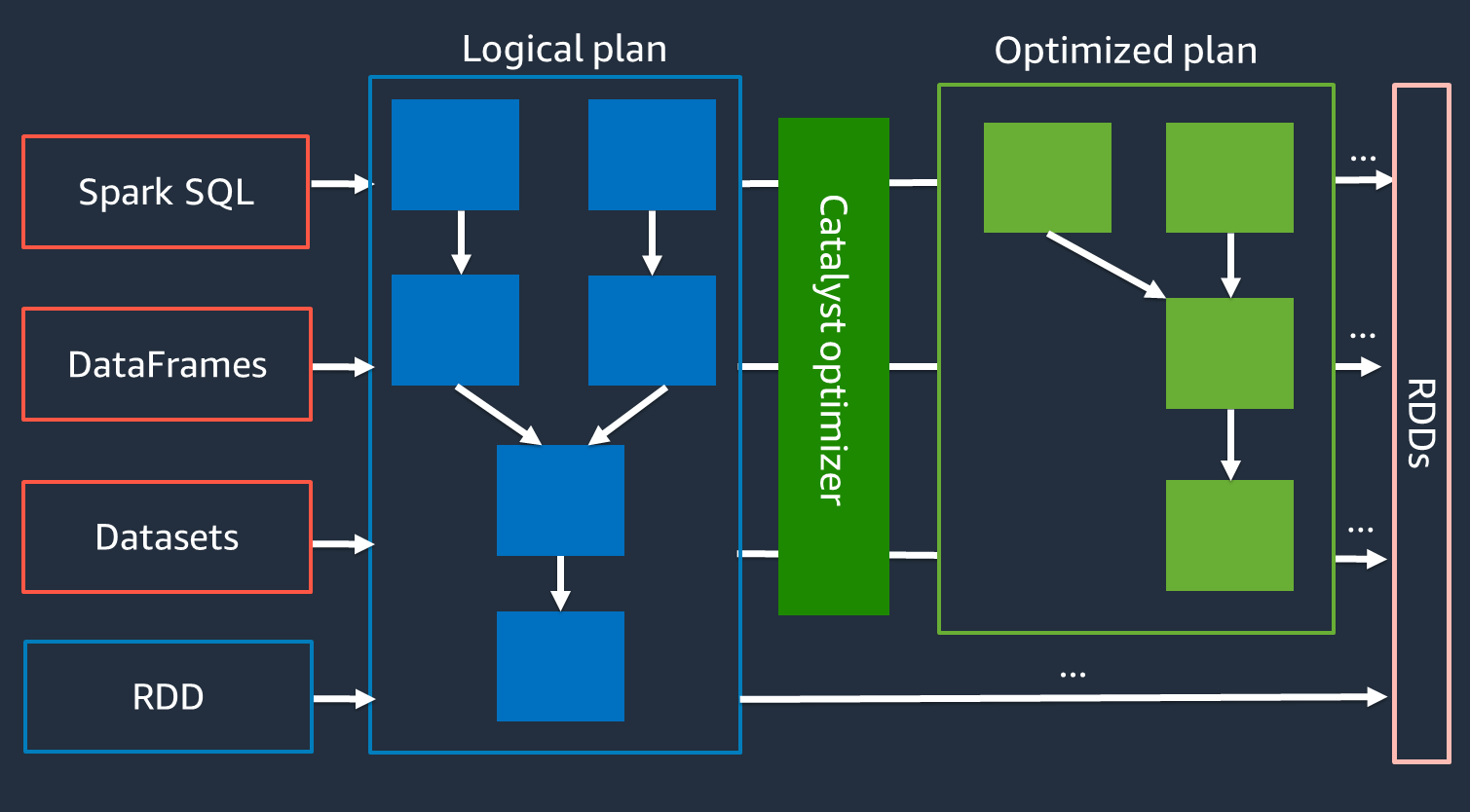
Catalyst オプティマイザは RDD API と直接やり取りしないため、高レベル API は一般に、低レベルな RDD API よりも高速です。複雑な結合の場合、Catalyst オプティマイザはジョブの実行計画を最適化することで、パフォーマンスを大幅に向上させることができます。Spark ジョブの最適化された計画は、Spark UI の [SQL] タブで確認できます。
アダプティブクエリ実行
Catalyst オプティマイザは、アダプティブクエリ実行と呼ばれるプロセスを通じてランタイム最適化を実行します。アダプティブクエリ実行は、ランタイム統計を使用して、ジョブの実行中にクエリの実行計画を再最適化します。アダプティブクエリ実行は、以下のセクションで説明するように、シャッフル後のパーティションの結合、ソートマージ結合のブロードキャスト結合への変換、スキュー結合の最適化など、パフォーマンスの課題に対するいくつかのソリューションを提供します。
アダプティブクエリ実行は AWS Glue 3.0 以降で使用でき、デフォルトでは AWS Glue 4.0 (Spark 3.3.0) 以降で有効になっています。コード内で spark.conf.set("spark.sql.adaptive.enabled",
"true") を使用することで、アダプティブクエリ実行を有効または無効にできます。
シャッフル後のパーティションの合体
この機能は、map 出力統計に基づいて、各シャッフル後に RDD パーティションを削減 (合体) します。これにより、クエリ実行時のシャッフルパーティション数のチューニングが簡素化されます。データセットに合わせてシャッフルパーティション数を設定する必要はありません。初期のシャッフルパーティション数が十分に多ければ、Spark が実行時に適切な数を自動的に選択します。
シャッフル後のパーティションの合体は、spark.sql.adaptive.enabled と spark.sql.adaptive.coalescePartitions.enabled の両方が true に設定されている場合に有効になります。詳細については、Apache Spark のドキュメント
ソートマージ結合のブロードキャスト結合への変換
この機能は、サイズが大きく異なる 2 つのデータセットを結合している場合を認識し、その情報に基づいてより効率的な結合アルゴリズムを採用します。詳細については、Apache Spark のドキュメント
スキュー結合の最適化
データスキューは、Spark ジョブの最も一般的なボトルネックの 1 つです。これは、データが特定の RDD パーティション (ひいては特定のタスク) に偏ることで、アプリケーション全体の処理時間が遅延する状況を指します。これにより、多くの場合、結合オペレーションのパフォーマンスが低下します。スキュー結合最適化機能は、スキューされたタスクをほぼ均等なサイズのタスクに分割 (および必要に応じてレプリケート) することで、ソートマージ結合のスキューを動的に処理します。
この機能は、spark.sql.adaptive.skewJoin.enabled が true に設定されている場合に有効になります。詳細については、Apache Spark のドキュメント
