翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
計画オーバーヘッドを最小限に抑える
「Key topics in Apache Spark」で説明されているように、Spark ドライバーは実行計画を生成します。その計画に基づいて、タスクは分散処理のために Spark エグゼキュターに割り当てられます。ただし、小さなファイルが多数ある場合や、 AWS Glue Data Catalog に多数のパーティションが含まれている場合、Spark ドライバーがボトルネックになる可能性があります。計画のオーバーヘッドが大きいかどうかを特定するには、次のメトリクスを評価します。
CloudWatch メトリクス
次の状況において、[CPU 負荷] と [メモリ使用率] を確認します。
-
Spark ドライバーの [CPU 負荷] と [メモリ使用率] が高く記録されています。通常、Spark ドライバーはデータを処理しないため、CPU 負荷とメモリ使用率が急増することはありません。ただし、Amazon S3 のデータソースに小さなファイルが多数存在する場合、S3 オブジェクトの一覧表示や大量のタスクの管理によって、リソース使用率が高くなる可能性があります。
-
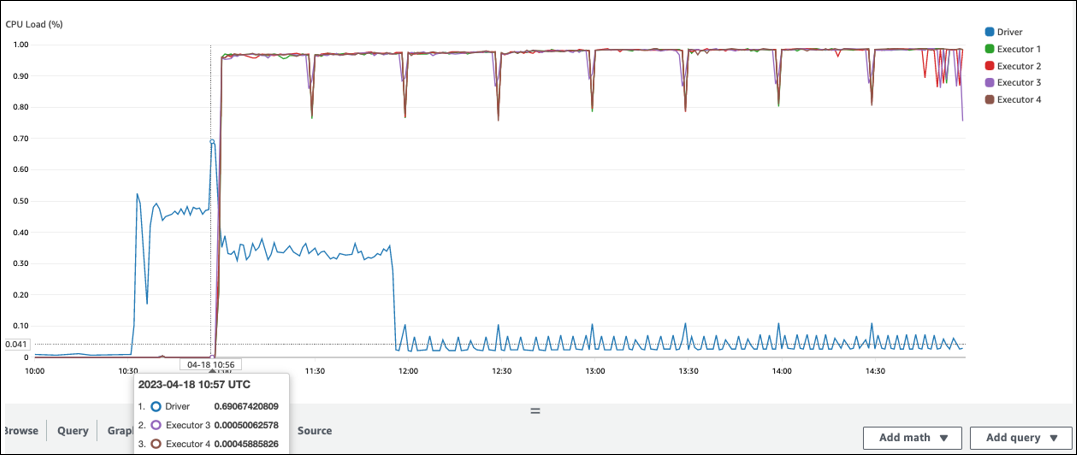
Spark エグゼキューターによる処理開始までに長い時間がかかっています。次のスクリーンショット例では、 AWS Glue ジョブが 10:00 に開始されたにもかかわらず、Spark エグゼキュターの CPU 負荷が 10:57 まで低すぎます。これは、Spark ドライバーが実行計画の生成に時間を要している可能性を示しています。この例では、Data Catalog から大量のパーティションを取得し、Spark ドライバーで多数の小さなファイルを一覧表示するのに時間がかかっています。
Spark UI
Spark UI の [ジョブ] タブで、[送信] 時刻を確認できます。次の例では、ジョブが 10:00:00 に開始されたにもかかわらず、Spark ドライバーは 10:56:46 に AWS Glue job0 を開始しました。

また、[ジョブ] タブでは、[タスク (すべてのステージ): 成功/合計] 時刻を確認することもできます。この場合、タスク数は 58100 と記録されています。「Parallelize tasks」ページの Amazon S3 セクションで説明されているように、タスク数は S3 オブジェクト数にほぼ対応します。つまり、Amazon S3 には約 58,100 個のオブジェクトが存在することになります。
このジョブとタイムラインの詳細については、[ステージ] タブを参照してください。Spark ドライバーにボトルネックが発生している場合は、次の解決策を検討してください。
-
Amazon S3 のファイルが多すぎる場合は、「Parallelize tasks」ページの「Too many partitions」セクションに記載されている、過剰な並列処理に関するガイダンスを検討してください。
-
Amazon S3 のパーティションが多すぎる場合は、「Reduce the amount of data scan」ページの「Too many Amazon S3 partitions」セクションに記載されている、過剰なパーティショニングに関するガイダンスを検討してください。パーティションが多い場合は、AWS Glue パーティションインデックスを有効にして、データカタログからパーティションメタデータを取得する際のレイテンシーを低減します。詳細については、AWS Glue 「パーティションインデックスを使用したクエリパフォーマンスの向上
」を参照してください。 -
JDBC のパーティションが多すぎる場合は、
hashpartitionの値を小さくします。 -
DynamoDB のパーティションが多すぎる場合は、
dynamodb.splitsの値を小さくします。 -
ストリーミングジョブでパーティションが多すぎる場合は、シャード数を減らします。
