Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Retour en arrière d’un cluster de bases de données Aurora
Avec Amazon Aurora MySQL-Compatible Edition, vous pouvez revenir en arrière sur un cluster de base de données à un moment précis, sans restaurer les données à partir d'une sauvegarde.
Important
Le retour en arrière est pris en charge dans les versions 2, 3 et 8.4 d'Aurora MySQL.
Table des matières
Considérations relatives aux mises à niveau pour les clusters compatibles avec le retour en arrière
Configuration du retour en arrière d’un cluster de bases de données Aurora MySQL
Exécution d’un retour en arrière pour un cluster de bases de données MySQL
Surveillance du retour en arrière pour un cluster de bases de données Aurora MySQL
Abonnement à un événement de retour en arrière avec la console
Désactivation du retour en arrière pour un cluster de bases de données Aurora MySQL
Présentation du retour en arrière
Le retour en arrière permet de « faire revenir en arrière » le cluster de bases de données à l’heure que vous spécifiez. Le retour en arrière ne remplace pas une sauvegarde de votre cluster de bases de données afin de pouvoir la restaurer à un instant dans le passé. Toutefois, le retour en arrière fournit les avantages suivants par rapport aux fonctions traditionnelles de sauvegarde et de restauration :
Vous pouvez facilement annuler des erreurs. Si vous effectuez par erreur une action destructrice, comme une opération DELETE sans clause WHERE, vous pouvez exécuter un retour en arrière pour faire revenir le cluster de bases de données à une heure précédant l’action destructrice sans aucune interruption minimale du service.
Vous pouvez effectuer rapidement un retour en arrière d’un cluster de bases de données. La restauration d’un cluster de bases de données à un instant dans le passé lance un nouveau cluster de bases de données et restaure celui-ci à partir des données de sauvegarde ou d’un instantané de cluster de bases de données ; cette opération peut prendre plusieurs heures. Le retour en arrière d’un cluster de bases de données ne nécessite pas de nouveau cluster de bases de données et fait revenir en arrière le cluster de bases de données en quelques minutes.
Vous pouvez explorer les précédentes modifications de données. Vous pouvez effectuer des retours en arrière d’un cluster de bases de données de manière répétée en arrière et en avant dans le temps afin de déterminer le moment où une modification particulière a eu lieu. Par exemple, vous pouvez effectuer un retour en arrière d’un cluster de bases de données de trois heures, puis effectuer un autre retour en arrière en avant d’une heure. Dans ce cas, l’heure du retour en arrière est antérieure de deux heures par rapport à l’heure d’origine.
Note
Pour plus d’informations sur la restauration d’un cluster de bases de données à un instant dans le passé, consultez Présentation de la sauvegarde et de la restauration d’un cluster de bases de données Aurora.
Fenêtre de retour en arrière
Avec le retour en arrière, il y a une fenêtre de retour en arrière cible et une fenêtre de retour en arrière réelle :
-
La fenêtre de retour en arrière cible correspond au laps de temps pendant lequel vous souhaitez pouvoir effectuer un retour en arrière de votre cluster de bases de données. Lorsque vous activez le retour en arrière, vous spécifiez une fenêtre de retour en arrière cible. Par exemple, vous pouvez spécifier une fenêtre de retour en arrière cible de 24 heures si vous souhaitez pouvoir effectuer un retour en arrière d’une journée du cluster de bases de données.
-
La fenêtre de retour en arrière réelle correspond au laps de temps réel pendant lequel vous pouvez effectuer un retour en arrière de votre cluster de bases de données ; sa valeur peut être inférieure à celle de la fenêtre de retour en arrière cible. La fenêtre de retour en arrière réelle est basée sur votre charge de travail et sur le stockage disponible pour les informations sur les modifications de la base de données, appelées enregistrements de modification.
À mesure que vous effectuez des mises à jour de votre cluster de bases de données Aurora avec le retour en arrière activé, vous générez des enregistrements de modifications. Aurora conserve les enregistrements de modifications pour la fenêtre de retour en arrière cible, et leur stockage vous est facturé sur une base horaire. La fenêtre de retour en arrière cible et la charge de travail sur votre cluster de bases de données déterminent le nombre d’enregistrements de modification que vous stockez. La charge de travail correspond au nombre de modifications que vous apportez au cluster de bases de données sur un laps de temps donné. Si votre charge de travail est lourde, vous stockez davantage d’enregistrements dans votre fenêtre de retour en arrière que si votre charge de travail est légère.
Vous pouvez considérer votre fenêtre de retour en arrière cible comme étant l’objectif du laps de temps maximal pendant lequel vous souhaitez pouvoir faire un retour en arrière de votre cluster de bases de données. Dans la plupart des cas, vous pouvez effectuer un retour en arrière correspondant au laps de temps maximal spécifié. Toutefois, dans certains cas, le cluster de bases de données ne peut pas stocker suffisamment d’enregistrements de modification pour effectuer un retour en arrière correspondant au laps de temps maximal, et votre fenêtre de retour en arrière réelle est plus petite que votre fenêtre de retour en arrière cible. Généralement, la fenêtre de retour en arrière réelle est plus petite que la fenêtre de retour en arrière cible lorsque la charge de travail est particulièrement lourde sur votre cluster de bases de données. Lorsque votre fenêtre de retour en arrière réelle est plus petite que votre fenêtre de retour en arrière cible, nous vous envoyons une notification.
Lorsque le retour en arrière est activé pour un cluster de bases de données, et que vous supprimez une table stockée dans ce cluster, Aurora conserve cette table dans les enregistrements de modification du retour en arrière. Ainsi, vous pouvez revenir en arrière à une heure antérieure à celle où vous avez supprimé la table. Si vous ne disposez pas de suffisamment d’espace dans votre fenêtre de retour en arrière pour stocker la table, il est possible que celle-ci soit supprimée des enregistrements de modification du retour en arrière.
Heure de retour en arrière
Aurora procède toujours au retour en arrière à une heure cohérente pour le cluster de bases de données. Cela élimine la possibilité de transactions non validées une fois le retour en arrière terminé. Lorsque vous spécifiez une heure de retour en arrière, Aurora choisit automatiquement l’heure cohérente la plus proche possible. Cette approche signifie que le retour en arrière terminé peut ne pas correspondre exactement à l'heure que vous spécifiez, mais vous pouvez déterminer l'heure exacte d'un retour en arrière à l'aide de la commande CLI AWS describe-db-cluster-backtracks. Pour de plus amples informations, veuillez consulter Extraction de retours sur trace existants.
Limites du retour en arrière
Les limites suivantes s’appliquent à un retour en arrière :
-
Le retour en arrière est disponible uniquement pour les clusters de bases de données créés avec la fonction de retour en arrière activée. Vous ne pouvez pas modifier un cluster de bases de données pour activer le retour en arrière. Vous pouvez activer la fonction de retour en arrière lorsque vous créez un nouveau cluster de bases de données, restaurez un instantané de cluster de bases de données.
-
La limite pour une fenêtre de retour en arrière est de 72 heures.
-
Le retour en arrière affecte l’ensemble du cluster de bases de données. Par exemple, vous ne pouvez pas effectuer un retour en arrière sélectif sur une seule table ou une seule mise à jour de données.
-
Vous ne pouvez pas créer de réplicas lecture entre régions à partir d’un cluster compatible avec le retour en arrière, mais vous pouvez toujours activer la réplication des journaux binaires (binlog) sur le cluster. Si vous essayez d’effectuer un retour en arrière sur un cluster de bases de données pour lequel la journalisation binaire est activée, une erreur se produit généralement, sauf si vous avez choisi de forcer le retour en arrière. Toute tentative visant à forcer un retour en arrière interrompra les répliques de lecture en aval et interférera avec d'autres opérations telles que blue/green les déploiements.
-
Vous ne pouvez pas effectuer un retour en arrière d’un clone de base de données à une heure antérieure à l’heure à laquelle le clone a été créé. Toutefois, vous pouvez utiliser la base de données d’origine pour effectuer un retour en arrière à une heure antérieure à l’heure à laquelle le clone a été créé. Pour plus d’informations sur le clonage de base de données, consultez Clonage d’un volume pour un cluster de bases de données Amazon Aurora.
-
Le retour en arrière entraîne une brève interruption de l’instance de base de données. Vous devez arrêter ou mettre en pause vos applications avant de démarrer une opération de retour en arrière, afin de vous assurer qu’il n’y a aucune nouvelle demande en lecture ou en écriture. Au cours de l’opération de retour en arrière, Aurora met en pause la base de données, ferme les connexions ouvertes et annule toutes les lectures et écritures non enregistrées. Il attend ensuite que l’opération de retour en arrière se termine.
-
Vous ne pouvez pas restaurer un instantané interrégional d'un cluster compatible avec le retour en arrière dans une AWS région qui ne prend pas en charge le retour en arrière.
-
Si vous effectuez une mise à niveau sur place pour un cluster compatible avec le backtrack depuis la version 2 vers la version 3 d'Aurora MySQL, ou de la version 3 vers la version 8.4, vous ne pouvez pas revenir en arrière avant que la mise à niveau n'ait eu lieu.
Disponibilité des régions et des versions
Le retour en arrière n’est pas disponible pour Aurora PostgreSQL.
Voici les moteurs pris en charge et la disponibilité des régions pour le retour en arrière avec Aurora MySQL.
| Région | Aurora MySQL version 8.4 | Aurora MySQL version 3 | Aurora MySQL version 2 |
|---|---|---|---|
| USA Est (Virginie du Nord) | Toutes les versions | Toutes les versions | Toutes les versions |
| USA Est (Ohio) | Toutes les versions | Toutes les versions | Toutes les versions |
| USA Ouest (Californie du Nord) | Toutes les versions | Toutes les versions | Toutes les versions |
| USA Ouest (Oregon) | Toutes les versions | Toutes les versions | Toutes les versions |
| Afrique (Le Cap) | – | – | – |
| Asie-Pacifique (Hong Kong) | – | – | – |
| Asie-Pacifique (Jakarta) | – | – | – |
| Asie-Pacifique (Malaisie) | – | – | – |
| Asie-Pacifique (Melbourne) | – | – | – |
| Asie-Pacifique (Mumbai) | Toutes les versions | Toutes les versions | Toutes les versions |
| Asie-Pacifique (Nouvelle Zélande) | – | – | – |
| Asie-Pacifique (Osaka) | Toutes les versions | Toutes les versions | Versions 2.07.3 et ultérieures |
| Asie-Pacifique (Séoul) | Toutes les versions | Toutes les versions | Toutes les versions |
| Asie-Pacifique (Singapour) | Toutes les versions | Toutes les versions | Toutes les versions |
| Asie-Pacifique (Sydney) | Toutes les versions | Toutes les versions | Toutes les versions |
| Asie-Pacifique (Taipei) | – | – | – |
| Asie-Pacifique (Thaïlande) | – | – | – |
| Asie-Pacifique (Tokyo) | Toutes les versions | Toutes les versions | Toutes les versions |
| Canada (Centre) | Toutes les versions | Toutes les versions | Toutes les versions |
| Canada-Ouest (Calgary) | – | – | – |
| Chine (Pékin) | – | – | – |
| China (Ningxia) | – | – | – |
| Europe (Francfort) | Toutes les versions | Toutes les versions | Toutes les versions |
| Europe (Irlande) | Toutes les versions | Toutes les versions | Toutes les versions |
| Europe (Londres) | Toutes les versions | Toutes les versions | Toutes les versions |
| Europe (Milan) | – | – | – |
| Europe (Paris) | Toutes les versions | Toutes les versions | Toutes les versions |
| Europe (Espagne) | – | – | – |
| Europe (Stockholm) | – | – | – |
| Europe (Zurich) | – | – | – |
| Israël (Tel Aviv) | – | – | – |
| Mexique (Centre) | – | – | – |
| Middle East (Bahrain) | – | – | – |
| Moyen-Orient (EAU) | – | – | – |
| Amérique du Sud (São Paulo) | – | – | – |
| AWS GovCloud (US-East) | – | – | – |
| AWS GovCloud (US-West) | – | – | – |
Considérations relatives aux mises à niveau pour les clusters compatibles avec le retour en arrière
Vous pouvez mettre à niveau un cluster de base de données compatible avec le backtrack de la version 2 vers la version 3 ou de la version 3 vers la version 8.4, car toutes les versions mineures d'Aurora MySQL versions 3 et 8.4 sont prises en charge pour Backtrack.
Abonnement à un événement de retour en arrière avec la console
La procédure suivante explique comment s’abonner à un événement de retour en arrière à l’aide de la console. L’événement vous envoie un e-mail ou une notification lorsque votre fenêtre de retour en arrière réelle est plus petite que votre fenêtre de retour en arrière cible.
Pour afficher des informations de retour en arrière à l’aide de la console
Connectez-vous à la console Amazon RDS AWS Management Console et ouvrez-la à https://console.aws.amazon.com/rds/
l'adresse. -
Choisissez Abonnements aux événements.
-
Choisissez Créer un abonnement aux événements.
-
Dans la zone Nom, attribuez un nom à l’abonnement aux événements et vérifiez que Oui est sélectionné pour Activé.
-
Dans la section Target (Cible), choisissez New email topic (Nouvelle rubrique d’e-mail).
-
Dans Nom de la rubrique, attribuez un nom à la rubrique, puis indiquez les adresses e-mail ou les numéros de téléphone qui recevront les notifications dans Avec ces destinataires.
-
Dans la section Source, choisissez Instances pour Type de source.
-
Pour Instances to include (Instances à inclure), choisissez Select specific instances (Sélectionner des instances spécifiques), puis sélectionnez votre instance de base de données.
-
Pour Event categories to include (Catégories d’événement à inclure), choisissez Select specific event categories (Sélectionner des catégories d’événement spécifiques), puis sélectionnez backtrack (retour en arrière).
Votre page doit ressembler à la page suivante.
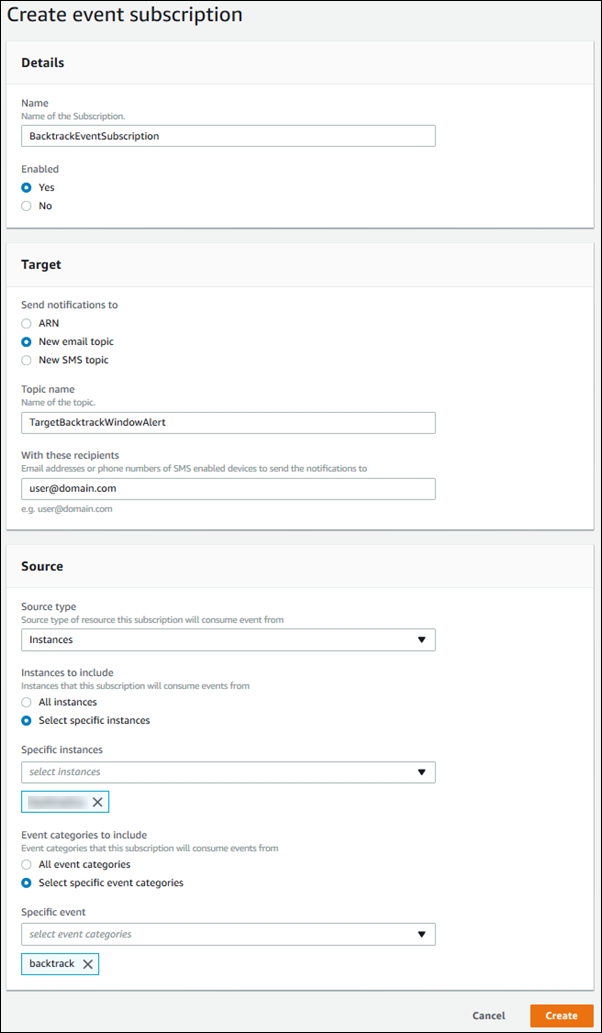
-
Choisissez Créer.
Extraction de retours sur trace existants
Vous pouvez extraire des informations sur des retours en arrière existants pour un cluster de bases de données. Ces informations incluent l’identifiant unique du retour en arrière, la date et l’heure de destination et d’origine du retour en arrière, la date et l’heure de la demande de retour en arrière et l’état actuel du retour en arrière.
Note
Actuellement, vous ne pouvez pas extraire des retours en arrière existants à l’aide de la console.
La procédure suivante explique comment extraire des retours en arrière existants pour un cluster de bases de données à l’aide de l AWS CLI.
Pour récupérer des backtracks existants à l'aide du AWS CLI
-
Appelez la commande describe-db-cluster-backtracks de l’ AWS CLI, puis fournissez les valeurs suivantes :
-
--db-cluster-identifier: nom du cluster de bases de données.
L’exemple suivant extrait les retours en arrière existants pour
sample-cluster.Pour Linux, macOS ou Unix :
aws rds describe-db-cluster-backtracks \ --db-cluster-identifier sample-clusterPour Windows :
aws rds describe-db-cluster-backtracks ^ --db-cluster-identifier sample-cluster -
Pour récupérer des informations sur les backtracks d'un cluster de bases de données à l'aide de l'API Amazon RDS, utilisez l'DescribeDBClusterBacktracksopération. Cette opération renvoie des informations sur les retours en arrière pour le cluster de bases de données spécifié dans la valeur DBClusterIdentifier.
