Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Clonage d’un volume pour un cluster de bases de données Amazon Aurora
Le clonage Aurora vous permet de créer un nouveau cluster qui partage les mêmes pages de données que l’original, mais qui est un volume distinct et indépendant. Le processus est conçu pour être rapide et rentable. Le nouveau cluster avec son volume de données associé est appelé clone. La création d’un clone est plus rapide et plus économe en espace que la copie physique des données à l’aide d’autres techniques telles que la restauration d’instantané.
Rubriques
Présentation du clonage Aurora
Pour créer un clone, Aurora utilise un protocole de copie sur écriture. Ce mécanisme utilise un espace supplémentaire minimal pour créer un clone initial. Lors de la création du premier clone, Aurora conserve une seule copie des données qu’utilisent le cluster de bases de données Aurora source et le nouveau cluster de bases de données Aurora (cloné). Un stockage supplémentaire n’est alloué que quand des modifications sont apportées aux données (sur le volume de stockage Aurora) par le cluster de bases de données Aurora source ou le clone du cluster de bases de données Aurora. Pour en savoir plus sur le protocole de copie sur écriture, consultez Fonctionnement du clonage Aurora.
Le clonage Aurora est particulièrement utile pour configurer rapidement des environnements de test à l’aide de vos données de production, sans risque de corruption des données. Vous pouvez utiliser des clones pour de nombreux types d’applications, telles que les suivantes :
-
Expérimentez des changements potentiels (par exemple, des changements de schémas et de groupes de paramètres) pour évaluer tous les impacts.
-
Exécutez des opérations imposant une charge de travail élevée, telles que l’exportation de données ou l’exécution de requêtes analytiques sur le clone.
-
Créez une copie de votre cluster de bases de données de production à des fins de développement, de test ou autres.
Vous pouvez créer plusieurs clones à partir du même cluster de bases de données Aurora. Vous pouvez également créer plusieurs clones à partir d’un autre clone.
Après avoir créé un clone Aurora, vous pouvez configurer les instances de base de données Aurora différemment du cluster de bases de données Aurora source. Par exemple, il se peut que vous n’ayez pas besoin d’un clone à des fins de développement pour répondre aux mêmes exigences de haute disponibilité que le cluster de bases de données Aurora de production source. Dans ce cas, vous pouvez configurer le clone avec une seule instance de base de données Aurora plutôt que les multiples instances de base de données qu’utilise le cluster de bases de données Aurora.
Lorsque vous créez un clone à l’aide d’une configuration de déploiement différente de la source, le clone est créé à l’aide de la dernière version mineure du moteur de base de données Aurora de la source.
Lorsque vous créez des clones à partir de vos clusters de base de données Aurora, les clones sont créés dans votre compte, AWS le même compte qui possède le cluster de base de données Aurora source. Toutefois, vous pouvez également partager Aurora serverless et provisionner des clusters et des clones de base de données Aurora avec d'autres AWS comptes. Pour de plus amples informations, veuillez consulter Cross-account clonage avec AWS RAM et Amazon Aurora.
Lorsque vous avez fini d’utiliser le clone à des fins de test, de développement ou autres, vous pouvez le supprimer.
Limites du clonage Aurora
Le clonage Aurora présente actuellement les limitations suivantes :
-
Vous pouvez créer autant de clones que vous le souhaitez, jusqu’au nombre maximal de clusters de bases de données autorisés dans la Région AWS.
-
Vous pouvez créer jusqu’à 15 clones avec le protocole de copie sur écriture. Lorsque vous avez créé 15 clones, le prochain clone créé est une copie intégrale. Le protocole de copie intégrale agit comme une reprise ponctuelle.
-
Vous ne pouvez pas créer de clone dans une AWS région différente de celle du cluster de base de données Aurora source.
-
Vous ne pouvez pas créer un clone à partir d’un cluster de bases de données Aurora dépourvu de la fonction de requête parallèle vers un cluster utilisant la fonction de requête parallèle. Pour introduire des données dans un cluster utilisant la fonction de requête parallèle, créez un instantané du cluster d’origine et restaurez-le dans un cluster utilisant la fonction de requête parallèle.
-
Vous ne pouvez pas créer de clone à partir d’un cluster de bases de données Aurora dépourvu d’instances de base de données. Vous ne pouvez cloner que des clusters de bases de données Aurora ayant au moins une instance de base de données.
-
Vous pouvez créer un clone dans un cloud privé virtuel (VPC) différent de celui du cluster de bases de données Aurora. Cependant, les sous-réseaux des VPC doivent mapper aux mêmes zones de disponibilité.
-
Vous pouvez créer un clone approvisionné Aurora à partir d’un cluster de bases de données Aurora approvisionné.
-
Les clusters avec instances Aurora serverless suivent les mêmes règles que les clusters alloués.
Fonctionnement du clonage Aurora
Le clonage Aurora opère au niveau de la couche de stockage d’un cluster de bases de données Aurora. Il utilise un protocole de copie sur écriture à la fois rapide et économe en espace s’agissant du support durable sous-jacent du volume de stockage Aurora. Pour plus d’informations sur les volumes de cluster Aurora, consultez Présentation du stockage Amazon Aurora.
Présentation du protocole de copie sur écriture
Un cluster de bases de données Aurora stocke des données dans des pages du volume de stockage Aurora sous-jacent.
Par exemple, le diagramme suivant montre un cluster de bases de données Aurora (A) comptant quatre pages de données, 1, 2, 3 et 4. Imaginez qu’un clone, B, soit créé à partir du cluster de bases de données Aurora. Lors de la création du clone, aucune donnée n’est copiée. Au contraire, le clone pointe vers le même ensemble de pages que le cluster de bases de données Aurora source.

Lors de la création du clone, aucun stockage supplémentaire n’est généralement nécessaire. Le protocole de copie sur écriture utilise le même segment sur le support de stockage physique que le segment source. Un stockage supplémentaire n’est requis que si la capacité du segment source n’est pas suffisante pour le segment de clone entier. Dans ce cas, le segment source est copié sur un autre périphérique physique.
Les diagrammes suivants présentent un exemple de protocole de copie sur écriture en action utilisant les cluster A et clone B que ceux montrés précédemment. Supposons que vous apportez une modification à votre cluster de bases de données Aurora (A) qui entraîne un changement des données conservées sur la page 1. Au lieu d’écrire sur la page 1 d’origine, Aurora crée une nouvelle page 1[A]. Le volume de cluster de bases de données Aurora pour le cluster (A) pointe désormais vers les pages 1[A], 2, 3 et 4, tandis que le clone (B) continue de référencer les pages d’origine.
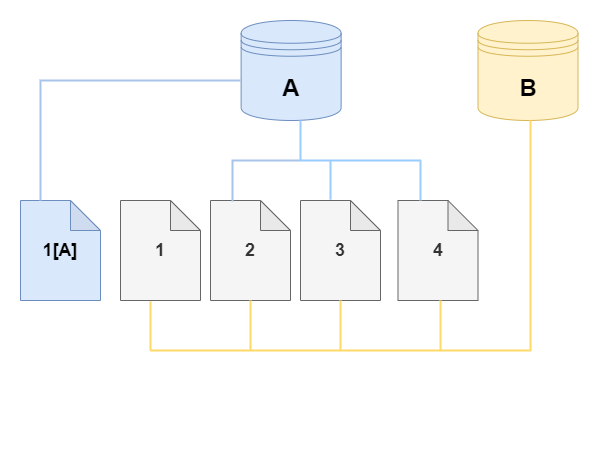
Sur le clone, une modification est apportée à la page 4 sur le volume de stockage. Au lieu d’écrire sur la page 4 d’origine, Aurora crée une nouvelle page 1[B]. Le clone pointe maintenant vers les pages 1, 2, 3 et 4[B], tandis que le cluster (A) continue de pointer vers les pages 1[A], 2, 3 et 4.
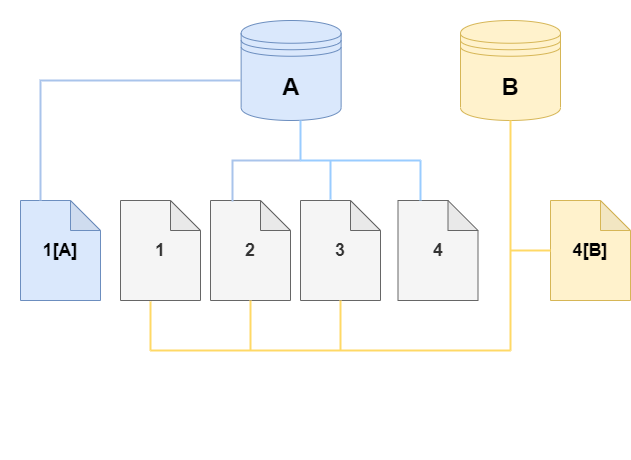
A mesure que des modifications supplémentaires sont apportées tant au volume de cluster Aurora source qu’au clone, plus de stockage est nécessaire pour capturer et stocker les modifications.
Suppression d’un volume de cluster source
Au départ, le volume du clone partage les mêmes pages de données que le volume d’origine à partir duquel le clone est créé. Tant que le volume d’origine existe, le volume du clone est uniquement considéré comme le propriétaire des pages créées ou modifiées par ce clone. La métrique VolumeBytesUsed du volume du clone est donc faible au départ et augmente uniquement à mesure que les données divergent entre le cluster d’origine et le clone. Pour les pages qui sont identiques entre le volume source et le clone, les frais de stockage s’appliquent uniquement au cluster d’origine. Pour plus d’informations sur la métrique VolumeBytesUsed, consultez Cluster-level métriques pour Amazon Aurora.
Lorsque vous supprimez un volume de cluster source auquel un ou plusieurs clones sont associés, les données des volumes de cluster des clones ne sont pas modifiées. Aurora préserve les pages qui étaient précédemment la propriété du volume de cluster source. Aurora redistribue la facturation du stockage pour les pages qui appartenaient au cluster supprimé. Supposons, par exemple, qu’un cluster d’origine associé à deux clones soit supprimé. La moitié des pages de données qui étaient la propriété du cluster d’origine appartiennent maintenant à un clone. L’autre moitié des pages appartient à l’autre clone.
Si vous supprimez le cluster d’origine, au fur et à mesure que vous créez ou supprimez d’autres clones, Aurora continue de redistribuer la propriété des pages de données entre tous les clones partageant les mêmes pages. Il se peut donc que la valeur de la métrique VolumeBytesUsed change pour le volume de cluster d’un clone. La valeur de cette métrique peut diminuer lorsque de nouveaux clones sont créés et que la propriété des pages est répartie sur un plus grand nombre de clusters. La valeur de cette métrique peut également augmenter lorsque des clones sont supprimés et que la propriété des pages est attribuée à un plus petit nombre de clusters. Pour en savoir plus sur l’impact des opérations d’écriture sur les pages de données des volumes des clones, consultez Présentation du protocole de copie sur écriture.
Lorsque le cluster d'origine et les clones appartiennent au même AWS compte, tous les frais de stockage de ces clusters s'appliquent à ce même AWS compte. Si certains clusters sont des clones entre comptes, la suppression du cluster d'origine peut entraîner des frais de stockage supplémentaires pour les AWS comptes propriétaires des clones entre comptes.
Supposons, par exemple, qu’un volume de cluster compte 1 000 pages de données utilisées avant de créer des clones. Lorsque vous clonez ce cluster, le volume du clone ne contient initialement aucune page utilisée. Si le clone apporte des modifications à 100 pages de données, seules ces 100 pages sont stockées sur le volume du clone et marquées comme utilisées. Les 900 pages inchangées restantes du volume parent sont partagées par les deux clusters. Dans ce cas, le cluster parent facture des frais de stockage pour 1 000 pages et le volume du clone pour 100 pages.
Si vous supprimez le volume source, les frais de stockage pour le clone incluent les 100 pages modifiées, plus les 900 pages partagées du volume d’origine, pour un total de 1 000 pages.
Création d’un clone Amazon Aurora
Vous pouvez créer un clone dans le même AWS compte que le cluster de base de données Aurora source. Pour ce faire, vous pouvez utiliser le AWS Management Console ou les AWS CLI et les procédures suivantes.
Pour autoriser un autre AWS compte à créer un clone ou à partager un clone avec un autre AWS compte, suivez les procédures décrites dansCross-account clonage avec AWS RAM et Amazon Aurora.
La procédure suivante explique comment cloner un cluster de bases de données Aurora à l’aide de l’ AWS Management Console.
Création d'un clone à l'aide des AWS Management Console résultats dans un cluster de base de données Aurora avec une instance de base de données Aurora.
Ces instructions s'appliquent aux clusters de base de données appartenant au même AWS compte qui crée le clone. Si le cluster de base de données appartient à un autre AWS compte, consultez Cross-account clonage avec AWS RAM et Amazon Aurora plutôt.
Pour créer un clone d'un cluster de base de données appartenant à votre AWS compte à l'aide du AWS Management Console
Connectez-vous à la console Amazon RDS AWS Management Console et ouvrez-la à https://console.aws.amazon.com/rds/
l'adresse. Dans le panneau de navigation, choisissez Databases (Bases de données).
Choisissez votre cluster de bases de données Aurora dans la liste, puis, pour Actions, choisissez Create clone (Créer un clone).
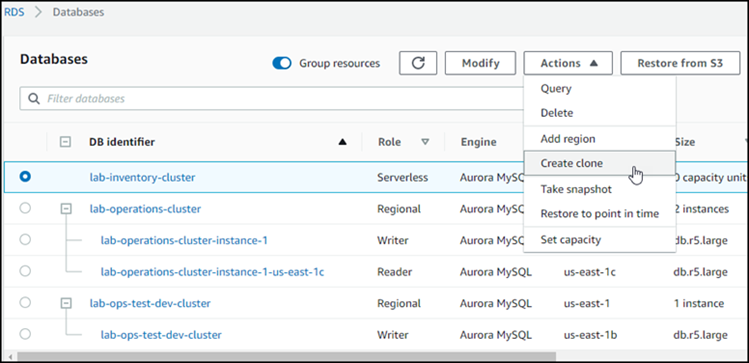
La page Créer un clone s’ouvre. Vous pouvez y configurer les options Paramètres, Connectivité et d’autres options pour le clone de cluster de bases de données Aurora.
-
Pour Identifiant d’instance de base de données, entrez le nom que vous souhaitez donner à votre cluster de bases de données Aurora cloné.
-
Pour les clusters de bases de données Aurora serverless ou provisionnés, choisissez Aurora I/O-Optimized ou Aurora Standard pour Configuration du stockage en cluster.
Pour plus d’informations, consultez Configurations de stockage pour les clusters de bases de données Amazon Aurora.
-
Choisissez la taille de l’instance de base de données ou la capacité du cluster de bases de données :
-
Pour un clone provisionné, choisissez une classe d’instance de base de données.
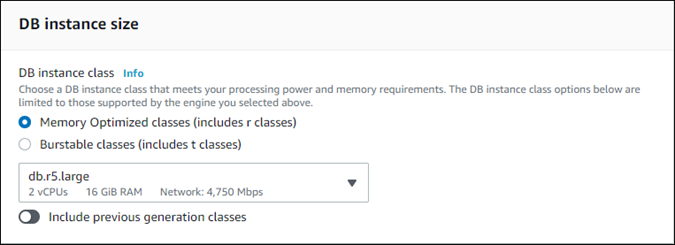
Vous pouvez accepter le paramètre fourni ou utiliser une autre classe d’instance de base de données différente pour votre clone.
-
Pour un Aurora serverless clone, choisissez les paramètres de capacité.
Vous pouvez accepter les paramètres fournis ou les modifier pour votre clone.
-
-
Choisissez les autres paramètres nécessaires pour votre clone. Pour en savoir plus sur les paramètres de cluster et d’instance de base de données Aurora, consultez Création d’un cluster de bases de données Amazon Aurora.
-
Choisissez Créer un clone.
Une fois le clone créé, il est répertorié avec vos autres clusters de bases de données Aurora dans la section Bases de données de la console, et affiche son état actuel. Votre clone est prêt à être utilisé quand son état est Disponible.
L'utilisation du AWS CLI pour cloner votre cluster de base de données Aurora implique des étapes distinctes pour créer le cluster de clones et y ajouter une ou plusieurs instances de base de données.
La restore-db-cluster-to-point-in-time AWS CLI commande que vous utilisez génère un cluster de base de données Aurora avec les mêmes données de stockage que le cluster d'origine, mais aucune instance de base de données Aurora. Vous créerez les instances de base de données séparément une fois que le clone sera disponible. Vous pouvez choisir le nombre d’instances de base de données et leurs classes d’instance pour donner au clone une capacité de calcul supérieure ou inférieure à celle du cluster d’origine. Les étapes de ce processus sont les suivantes :
-
Créez le clone à l’aide de la commande de la CLI restore-db-cluster-to-point-in-time.
-
Créez l’instance de base de données d’enregistreur pour le clone à l’aide de la commande create-db-instance de la CLI.
-
(Facultatif) Exécutez des commandes create-db-instance supplémentaires de la CLI pour ajouter une ou plusieurs instances de lecteur au cluster du clone. L’utilisation d’instances de lecteur permet d’améliorer les aspects du clone en matière de haute disponibilité et de capacité de mise à l’échelle en lecture. Vous pouvez ignorer cette étape si vous prévoyez d’utiliser le clone uniquement pour le développement et les tests.
Rubriques
Création du clone
Utilisez la commande restore-db-cluster-to-point-in-time de la CLI pour créer le cluster du clone initial.
Pour créer un clone à partir d’un cluster de bases de données Aurora source
-
Utilisez la commande
restore-db-cluster-to-point-in-timede l’interface de ligne de commande. Spécifiez les valeurs des paramètres suivants. Dans ce cas typique, le clone utilise le même mode moteur que le cluster d’origine, qu’il soit provisionné ou Aurora serverless.-
--db-cluster-identifier– Choisissez un nom explicite pour votre clone. Vous nommez le clone lorsque vous utilisez la commande de la CLI restore-db-cluster-to-point-in-time. Vous passez ensuite le nom du clone dans la commande de la CLI create-db-instance. -
--restore-type: utilisez la commandecopy-on-writepour créer un clone du cluster de bases de données source. Sans ce paramètre, la commanderestore-db-cluster-to-point-in-timerestaure le cluster de bases de données Aurora au lieu de créer un clone. -
--source-db-cluster-identifier: utilisez le nom du cluster de bases de données Aurora source que vous souhaitez cloner. -
--use-latest-restorable-time: cette valeur pointe vers les données de volume restaurables les plus récentes pour le cluster de bases de données source. Utilisez-la pour créer des clones.
-
L’exemple suivant crée un clone nommé my-clone à partir d’un cluster nommé my-source-cluster.
Pour Linux, macOS ou Unix :
aws rds restore-db-cluster-to-point-in-time \ --source-db-cluster-identifiermy-source-cluster\ --db-cluster-identifiermy-clone\ --restore-type copy-on-write \ --use-latest-restorable-time
Pour Windows :
aws rds restore-db-cluster-to-point-in-time ^ --source-db-cluster-identifiermy-source-cluster^ --db-cluster-identifiermy-clone^ --restore-type copy-on-write ^ --use-latest-restorable-time
La commande renvoie l’objet JSON contenant les détails du clone. Vérifiez que votre cluster de bases de données cloné est disponible avant d’essayer de créer l’instance de base de données pour votre clone. Pour plus d’informations, consultez Vérification de l’état et obtention des détails du clone.
Par exemple, supposons que vous ayez un cluster nommé tpch100g que vous souhaitez cloner. L’exemple Linux suivant crée un cluster cloné nommé tpch100g-clone, une instance d’enregistreur Aurora serverless nommée tpch100g-clone-instance et une instance de lecteur provisionnée nommée tpch100g-clone-instance-2 pour le nouveau cluster.
Vous n’avez pas besoin de fournir certains paramètres, tels que --master-username et --master-user-password. Aurora détermine automatiquement ceux du cluster d’origine. Vous devez spécifier le moteur de base de données à utiliser. Ainsi, l’exemple teste le nouveau cluster pour déterminer la bonne valeur à utiliser pour le paramètre --engine.
Cet exemple inclut également l’option --serverless-v2-scaling-configuration lors de la création du cluster du clone. Ainsi, vous pouvez ajouter des instances Aurora serverless au clone même si le cluster d’origine n’a pas utilisé Aurora serverless.
$aws rds restore-db-cluster-to-point-in-time \ --source-db-cluster-identifier tpch100g \ --db-cluster-identifier tpch100g-clone \ --serverless-v2-scaling-configuration MinCapacity=0.5,MaxCapacity=16\ --restore-type copy-on-write \ --use-latest-restorable-time$aws rds describe-db-clusters \ --db-cluster-identifier tpch100g-clone \ --query '*[].[Engine]' \ --output textaurora-mysql$aws rds create-db-instance \ --db-instance-identifier tpch100g-clone-instance \ --db-cluster-identifier tpch100g-clone \ --db-instance-class db.serverless \ --engine aurora-mysql$aws rds create-db-instance \ --db-instance-identifier tpch100g-clone-instance-2 \ --db-cluster-identifier tpch100g-clone \ --db-instance-class db.r6g.2xlarge \ --engine aurora-mysql
Vérification de l’état et obtention des détails du clone
Vous pouvez utiliser la commande suivante pour vérifier l’état du cluster du clone que vous venez de créer.
$aws rds describe-db-clusters --db-cluster-identifiermy-clone--query '*[].[Status]' --output text
Vous pouvez également obtenir le statut et les autres valeurs dont vous avez besoin pour créer l'instance de base de données pour votre clone à l'aide de la AWS CLI requête suivante.
Pour Linux, macOS ou Unix :
aws rds describe-db-clusters --db-cluster-identifiermy-clone\ --query '*[].{Status:Status,Engine:Engine,EngineVersion:EngineVersion,EngineMode:EngineMode}'
Pour Windows :
aws rds describe-db-clusters --db-cluster-identifiermy-clone^ --query "*[].{Status:Status,Engine:Engine,EngineVersion:EngineVersion,EngineMode:EngineMode}"
Cette requête retourne une sortie similaire à la suivante.
[ { "Status": "available", "Engine": "aurora-mysql", "EngineVersion": "8.0.mysql_aurora.3.04.1", "EngineMode": "provisioned" } ]
Création de l’instance de base de données Aurora pour votre clone
Utilisez la commande create-db-instance de la CLI pour créer l’instance de base de données de votre clone Aurora serverless ou provisionné.
L’instance de base de données hérite des propriétés --master-username et --master-user-password du cluster de bases de données source.
L’exemple suivant créé une instance de base de données pour un clone provisionné.
Pour Linux, macOS ou Unix :
aws rds create-db-instance \ --db-instance-identifiermy-new-db\ --db-cluster-identifiermy-clone\ --db-instance-classdb.r6g.2xlarge\ --engine aurora-mysql
Pour Windows :
aws rds create-db-instance ^ --db-instance-identifiermy-new-db^ --db-cluster-identifiermy-clone^ --db-instance-classdb.r6g.2xlarge^ --engine aurora-mysql
L’exemple suivant crée une instance de base de données Aurora serverless pour un clone qui utilise une version de moteur compatible avec Aurora serverless.
Pour Linux, macOS ou Unix :
aws rds create-db-instance \ --db-instance-identifiermy-new-db\ --db-cluster-identifiermy-clone\ --db-instance-class db.serverless \ --engine aurora-postgresql
Pour Windows :
aws rds create-db-instance ^ --db-instance-identifiermy-new-db^ --db-cluster-identifiermy-clone^ --db-instance-class db.serverless ^ --engine aurora-mysql
Paramètres à utiliser pour le clonage
Le tableau suivant récapitule les différents paramètres utilisés avec la commande restore-db-cluster-to-point-in-time pour cloner des clusters de bases de données Aurora.
| Paramètre | Description |
|---|---|
|
|
Utilisez le nom du cluster de bases de données Aurora source que vous souhaitez cloner. |
|
|
Choisissez un nom explicite pour votre clone lorsque vous le créez avec la commande |
|
|
Spécifiez |
|
|
Cette valeur pointe vers les données de volume restaurables les plus récentes pour le cluster de bases de données source. Utilisez-la pour créer des clones. |
|
|
(Versions récentes compatibles avec Aurora serverless) Utilisez ce paramètre pour configurer la capacité minimale et maximale d’un clone Aurora serverless. Si vous ne spécifiez pas ce paramètre, vous ne pourrez créer aucune instance Aurora serverless dans le cluster du clone tant que vous n’aurez pas modifié le cluster pour y ajouter cet attribut. |
Pour plus d’informations sur le clonage entre VPC et entre comptes, consultez les sections suivantes.
