本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
資料品質定義語言 (DQDL) 參考
Data Quality Definition Language (DQDL) 是您用來定義 Glue Data Quality AWS 規則的網域特定語言。
本指南介紹了關鍵的 DQDL 概念,可幫助您了解該語言。其中也提供 DQDL 規則類型的參考,內含語法和範例。在使用本指南之前,建議您先熟悉 AWS Glue Data Quality。如需詳細資訊,請參閱AWS Glue 資料品質。
注意
僅 AWS Glue ETL 支援 DynamicRules。
內容
DQDL 語法
DQDL 文件區分大小寫,且包含規則集,可將個別資料品質規則分組。若要建構規則集,您必須建立名為 Rules (大寫) 的清單,並以一對方括號分隔。如下列範例所示,清單應包含一或多個以逗號分隔的 DQDL 規則。
Rules = [ IsComplete "order-id", IsUnique "order-id" ]
規則結構
DQDL 規則的結構取決於規則類型。不過,DQDL 規則通常適合以下格式。
<RuleType> <Parameter> <Parameter> <Expression>
RuleType 是您要設定的規則類型名稱 (區分大小寫)。例如,IsComplete、IsUnique 或 CustomSql。每種規則類型的規則參數都不同。如需 DQDL 規則類型及其參數的完整參考資料,請參閱 DQDL 規則類型參考。
複合規則
DQDL 支援下列可用來合併規則的邏輯運算子。這些規則稱為複合規則。
- 及
-
當且僅當邏輯
and運算子連接的規則為true時,其結果為true。否則,合併規則的結果為false。您使用and運算子連接的每個規則都必須以括號括住。下列範例會使用
and運算子來合併兩個 DQDL 規則。(IsComplete "id") and (IsUnique "id") - 或
-
當且僅當邏輯
or運算子連接的一個或多個規則為true時,其結果為true。您使用or運算子連接的每個規則都必須以括號括住。下列範例會使用
or運算子來合併兩個 DQDL 規則。(RowCount "id" > 100) or (IsPrimaryKey "id")
您可以使用相同的運算子來連接多個規則,因此允許使用以下規則組合。
(Mean "Star_Rating" > 3) and (Mean "Order_Total" > 500) and (IsComplete "Order_Id")
您可以將邏輯運算子合併為單一運算式。例如:
(Mean "Star_Rating" > 3) and ((Mean "Order_Total" > 500) or (IsComplete "Order_Id"))
您也可以撰寫更複雜的巢狀規則。
(RowCount > 0) or ((IsComplete "colA") and (IsUnique "colA"))
複合規則的運作方式
依預設,複合規則會評估為整個資料集或資料表的個別規則,然後合併結果。換言之,其會先評估整個資料欄,然後套用運算子。下面透過一個範例來解釋此預設行為:
# Dataset +------+------+ |myCol1|myCol2| +------+------+ | 2| 1| | 0| 3| +------+------+ # Overall outcome +----------------------------------------------------------+-------+ |Rule |Outcome| +----------------------------------------------------------+-------+ |(ColumnValues "myCol1" > 1) OR (ColumnValues "myCol2" > 2)|Failed | +----------------------------------------------------------+-------+
在上述範例中,AWS Glue Data Quality 會先評估 (ColumnValues "myCol1" > 1),這會導致失敗。然後其會評估 (ColumnValues "myCol2" > 2),但這也會失敗。這兩個結果的組合將記錄為 FAILED。
但是,如果您偏好 SQL 之類的行為,其中您需要評估整個資料列,則必須明確設定 ruleEvaluation.scope 參數,如下面的程式碼片段中的 additionalOptions 所示。
object GlueApp { val datasource = glueContext.getCatalogSource( database="<db>", tableName="<table>", transformationContext="datasource" ).getDynamicFrame() val ruleset = """ Rules = [ (ColumnValues "age" >= 26) OR (ColumnLength "name" >= 4) ] """ val dq_results = EvaluateDataQuality.processRows( frame=datasource, ruleset=ruleset, additionalOptions=JsonOptions(""" { "compositeRuleEvaluation.method":"ROW" } """ ) ) }
在 AWS Glue Data Catalog 中,您可以在使用者介面中輕鬆設定此選項,如下所示。
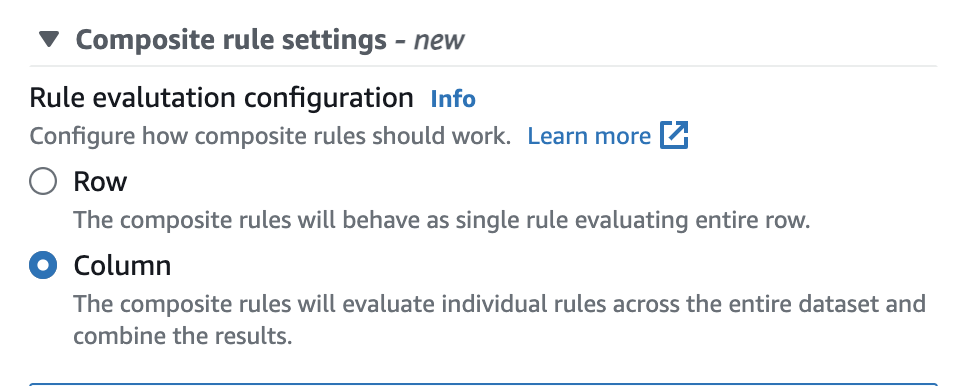
設定後,複合規則將作為評估整個資料列的單一規則。下列範例示範了此行為。
# Row Level outcome +------+------+------------------------------------------------------------+---------------------------+ |myCol1|myCol2|DataQualityRulesPass |DataQualityEvaluationResult| +------+------+------------------------------------------------------------+---------------------------+ |2 |1 |[(ColumnValues "myCol1" > 1) OR (ColumnValues "myCol2" > 2)]|Passed | |0 |3 |[(ColumnValues "myCol1" > 1) OR (ColumnValues "myCol2" > 2)]|Passed | +------+------+------------------------------------------------------------+---------------------------+
此功能不支援某些規則,因為整體結果取決於閾值或比率。將其列示如下。
依賴比率的規則:
-
完整度
-
DatasetMatch
-
ReferentialIntegrity
-
Uniqueness
相依於閾值的規則:
當下列規則包含閾值時,其不受支援。但是,不涉及 with threshold 的規則仍受支援。
-
ColumnDataType
-
ColumnValues
-
CustomSQL
表達式
如果規則類型不會產生布林值回應,您必須提供運算式作為參數,才能建立布林值回應。例如,下列規則會根據表達式檢查欄中所有值的平均值,以傳回 true 或 false 結果。
Mean "colA" between 80 and 100
某些規則類型 (例如 IsUnique 和 IsComplete) 已傳回布林值回應。
下表列出您可以在 DQDL 規則中使用的運算式。
| 表達式 | 說明 | 範例 |
|---|---|---|
=x |
如果規則類型回應等於 x,則解析為 true。 |
|
!=x |
如果規則類型回應不等於 x,則解析為 true。 |
|
> x |
如果規則類型回應大於 x,則解析為 true。 |
|
< x |
如果規則類型回應小於 x,則解析為 true。 |
|
>= x |
如果規則類型回應大於或等於 x,則解析為 true。 |
|
<= x |
如果規則類型回應小於或等於 x,則解析為 true。 |
|
between x and y |
如果規則類型回應落在指定範圍內 (不含) 時,則解析為 true。只針對數字和日期類型使用此表達式類型。 |
|
not between x and y |
如果規則類型回應不屬於指定範圍 (含),則解析為 true。您應該只針對數字和日期類型使用此運算式類型。 |
|
in [a, b, c, ...] |
如果規則類型回應在指定集中,則解析為 true。 |
|
not in [a, b, c, ...] |
如果規則類型回應不在指定集中,則解析為 true。 |
|
matches /ab+c/i |
如果規則類型回應符合規則運算式,則解析為 true。 |
|
not matches /ab+c/i |
如果規則類型回應不符合規則運算式,則解析為 true。 |
|
now() |
僅適用於 ColumnValues 規則類型以建立日期運算式。 |
|
matches/in […]/not matches/not in [...] with threshold |
指定符合規則條件的值的百分比。僅適用於 ColumnValues、ColumnDataType 和 CustomSQL 規則類型。 |
|
NULL、EMPTY 和 WHITESPACES_ONLY 的關鍵字
如果您想要驗證字串資料欄是否具有 null、空白或僅包含空格的字串,您可以使用下列關鍵字:
-
NULL/null – 此關鍵字會針對字串資料欄中的
null值解析為 true。如果超過 50% 的資料沒有 null 值,
ColumnValues "colA" != NULL with threshold > 0.5會傳回 true。對於具有 null 值或長度 >5 的所有資料列,
(ColumnValues "colA" = NULL) or (ColumnLength "colA" > 5)會傳回 true。請注意,這將需要使用 “compositeRuleEvaluation.method” = “ROW” 選項。 -
EMPTY / empty – 對於字串資料欄中的空白字串 (" ") 值,此關鍵字解析為 true。有些資料格式會將字串資料欄中的 null 轉換為空白字串。此關鍵字有助於篩選掉資料中的空白字串。
如果資料列為空白、"a" 或 "b",
(ColumnValues "colA" = EMPTY) or (ColumnValues "colA" in ["a", "b"])會傳回 true。請注意,這需要使用 "compositeRuleEvaluation.method" = "ROW" 選項。 -
WHITESPACES_ONLY / whitespaces_only – 對於字串資料欄中僅包含空格 (" ") 值的字串,此關鍵字會解析為 true。
如果資料列不是 "a" 或 "b",也不只是空格,
ColumnValues "colA" not in ["a", "b", WHITESPACES_ONLY]會傳回 true。支援的規則:
對於以數字或日期為基礎的表達式,如果您要驗證資料欄是否具有 null,您可以使用下列關鍵字。
-
NULL/null – 此關鍵字會針對字串資料欄中的 null 值解析為 true。
如果資料欄中的日期為
2023-01-01或 null,ColumnValues "colA" in [NULL, "2023-01-01"]會傳回 true。對於具有 null 值或具有介於 1 至 9 之間的值的所有資料列,
(ColumnValues "colA" = NULL) or (ColumnValues "colA" between 1 and 9)會傳回 true。請注意,這將需要使用 “compositeRuleEvaluation.method” = “ROW” 選項。支援的規則:
使用 Where 子句進行篩選
注意
其中 Glue 4.0 AWS 僅支援 子句。
您可以在撰寫規則時篩選資料。在您要套用條件式規則時,這會很有幫助。
<DQDL Rule> where "<valid SparkSQL where clause> "
必須使用 where 關鍵字指定篩選條件,後接以引號 ("") 括住的有效 SparkSQL 陳述式。
如果您想要將 where 子句新增至具有閾值的規則,則應在閾值條件之前指定 where 子句。
<DQDL Rule> where "valid SparkSQL statement>" with threshold <threshold condition>
使用此語法,您可以撰寫如下所示的規則。
Completeness "colA" > 0.5 where "colB = 10" ColumnValues "colB" in ["A", "B"] where "colC is not null" with threshold > 0.9 ColumnLength "colC" > 10 where "colD != Concat(colE, colF)"
我們將驗證提供的 SparkSQL 陳述式是否有效。如果無效,規則評估將會失敗,我們將擲回格式如下的 IllegalArgumentException:
Rule <DQDL Rule> where "<invalid SparkSQL>" has provided an invalid where clause : <SparkSQL Error>
開啟資料列層級錯誤記錄識別時的 Where 子句行為
透過 AWS Glue Data Quality,您可以識別失敗的特定記錄。將 where 子句套用至支援資料列層級結果的規則時,我們會將由 where 子句篩選的資料列標記為 Passed。
如果您偏好將篩選出的資料列單獨標記為 SKIPPED,可以為 ETL 任務設定下列 additionalOptions。
object GlueApp { val datasource = glueContext.getCatalogSource( database="<db>", tableName="<table>", transformationContext="datasource" ).getDynamicFrame() val ruleset = """ Rules = [ IsComplete "att2" where "att1 = 'a'" ] """ val dq_results = EvaluateDataQuality.processRows( frame=datasource, ruleset=ruleset, additionalOptions=JsonOptions(""" { "rowLevelConfiguration.filteredRowLabel":"SKIPPED" } """ ) ) }
例如,請參閱下列規則和資料框:
IsComplete att2 where "att1 = 'a'"
| id | att1 | att2 | 資料列層級結果 (預設值) | 資料列層級結果 (已略過選項) | 說明 |
|---|---|---|---|---|---|
| 1 | a | f | PASSED | PASSED | |
| 2 | b | d | PASSED | 略過 | 資料列會篩選掉,因為 att1 不是 "a" |
| 3 | a | null | 失敗 | 失敗 | |
| 4 | a | f | PASSED | PASSED | |
| 5 | b | null | PASSED | 略過 | 資料列會篩選掉,因為 att1 不是 "a" |
| 6 | a | f | PASSED | PASSED |
常數
在 DQDL 中,您可以定義常數值,並在指令碼中參考它們。這有助於防止與查詢大小限制相關的問題,例如,使用可能超過允許界限的大型 SQL 陳述式時。透過將這些值指派給常數,您可以簡化 DQDL 並避免達到這些限制。
下列範例示範如何定義和使用常數:
mySql = "select count(*) from primary" Rules = [ CustomSql $mySql between 0 and 100 ]
在此範例中,SQL 查詢會指派給常數 mySql,然後使用 $字首在規則中參考。
標籤
標籤提供有效的方法來組織和分析資料品質結果。您可以依特定標籤查詢結果,以識別特定類別內失敗的規則、依團隊或網域計算規則結果,並為不同的利益相關者建立重點報告。
例如,您可以使用標籤套用與財務團隊相關的所有規則,"team=finance"並產生自訂報告來展示財務團隊特有的品質指標。您可以使用 標記高優先順序規則"criticality=high",以排定修復工作的優先順序。標籤可以撰寫為 DQDL 的一部分。您可以在規則結果、資料列層級結果和 API 回應中查詢標籤,以便輕鬆與現有的監控和報告工作流程整合。
注意
標籤僅適用於 AWS Glue ETL,不適用於以 Glue Data Catalog AWS 為基礎的資料品質。
DQDL 標籤的語法
DQDL 同時支援預設和規則特定的標籤。預設標籤是在規則集層級定義,並自動套用到該規則集內的所有規則。個別規則也可以有自己的標籤,而且由於標籤會實作為索引鍵/值對,因此使用相同索引鍵時,規則特定的標籤可以覆寫預設標籤。
下列範例示範如何使用預設和規則特定的標籤:
DefaultLabels=["frequency"="monthly"] Rules = [ // Auto includes the default label ["frequency"="monthly"] ColumnValues "col" > 21, // Add ["foo"="bar"] to default label. Labels for this rule would be ["frequency"="monthly", "foo"="bar"] RowCount > 0 with threshold > 0.8 labels=["foo"="bar"], // Override default label. Labels for this rule would be ["frequency"="daily", "foo"="bar"] ColumnValues "colA" in ["A", "B"] with threshold > 0.8 labels=["foo"="bar", "frequency"="daily"] // Labels must be applied to the entire composite rule (parentheses required) (isComplete "col" AND RowCount > 0) labels=["foo"="bar] ]
下列範例顯示標籤和複合規則的無效語法:
(isComplete "colA") AND (RowCount > 0) labels=["foo"="bar"] (isComplete "colA" labels=["foo"="bar"]) AND (RowCount > 0) isComplete "col" AND RowCount > 0 labels=["foo"="bar]
標籤限制條件
標籤有下列限制:
-
每個 DQDL 規則最多 10 個標籤。
-
標籤會指定為索引鍵/值對的清單。
-
標籤索引鍵和標籤值區分大小寫。
-
標籤索引鍵的長度上限為 128 個字元。標籤索引鍵不得為空白或 null。
-
標籤值長度上限為 256 個字元。標籤值可以是空白或 null。
擷取 DQDL 標籤
您可以從規則結果、資料列層級結果和 API 回應擷取 DQDL 標籤。
規則結果
DQDL 標籤一律會顯示在規則結果中。不需要額外的組態即可啟用。
資料列層級結果
DQDL 標籤預設會在資料列層級結果中停用,但可以在 AdditionalOptions中使用 啟用EvaluateDataQuality。
下列範例顯示如何在資料列層級結果中啟用標籤:
val evaluateResult = EvaluateDataQuality.processRows( frame=AmazonS3_node1754591511068, ruleset=example_ruleset, publishingOptions=JsonOptions("""{ "dataQualityEvaluationContext": "evaluateResult", "enableDataQualityCloudWatchMetrics": "true", "enableDataQualityResultsPublishing": "true" }"""), additionalOptions=JsonOptions("""{ "performanceTuning.caching":"CACHE_NOTHING", "observations.scope":"ALL", "rowLevelConfiguration.ruleWithLabels":"ENABLED" }""") )
啟用時,資料列層級結果資料框架會包含 DataQualityRulesPass、 DataQualityRulesFail和 DataQualityRulesSkip欄中每個規則的標籤。
API 回應
DQDL 標籤一律會顯示在RuleResults物件中新欄位下的 API 回應Labels中。
下列範例顯示 API 回應中的標籤:
{ "ResultId": "dqresult-example", "ProfileId": "dqprofile-example", "Score": 0.6666666666666666, "RulesetName": "EvaluateDataQuality_node1754591514205", "EvaluationContext": "EvaluateDataQuality_node1754591514205", "StartedOn": "2025-08-22T19:36:10.448000+00:00", "CompletedOn": "2025-08-22T19:36:16.368000+00:00", "JobName": "anniezc-test-labels", "JobRunId": "jr_068f6d7a45074d9105d14e4dee09db12c3b95664b45f6ee44fa29ed7e5619ba8", "RuleResults": [ { "Name": "Rule_0", "Description": "IsComplete colA", "EvaluationMessage": "Input data does not include column colA!", "Result": "FAIL", "EvaluatedMetrics": {}, "EvaluatedRule": "IsComplete colA", "Labels": { "frequency": "monthly" } }, { "Name": "Rule_1", "Description": "Rule 1 with threshold > 0.8", "Result": "PASS", "EvaluatedMetrics": {}, "EvaluatedRule": "Rule 1 with threshold > 0.8", "Labels": { "frequency": "monthly", "foo": "bar" } }, { "Name": "Rule_3", "Description": "Rule 2 with threshold > 0.8", "Result": "PASS", "EvaluatedMetrics": {}, "EvaluatedRule": "Rule 2 with threshold > 0.8", "Labels": { "frequency": "daily", "foo": "bar" } } ] }
動態規則
注意
動態規則僅在 AWS Glue ETL 中受支援,且在 Glue Data Catalog AWS 中不受支援。
您現在可以編寫動態規則,將規則產生的目前指標與其歷史值進行比較。這些歷史比較是透過在表達式中使用 last() 運算子來啟用。例如,當目前執行中的資料列數目大於相同資料集的最近先前一個資料列計數時,規則 RowCount >
last() 便會成功。last() 採用可選的自然數引數,描述要考慮的先前指標;last(k) 中 k
>= 1 將參考最後 k 個指標。
-
如果沒有可用的資料點,
last(k)將傳回預設值 0.0。 -
如果可用的指標少於
k,last(k)將傳回所有先前的指標。
為了形成使用 last(k) 的有效表達式,k > 1 需要彙總函數將多個歷史結果簡化為一個數字。例如,RowCount > avg(last(5)) 將檢查目前資料集的資料列計數是否嚴格大於相同資料集最後五個資料列計數的平均值。RowCount > last(5) 將產生錯誤,因為當前資料集的資料列計數不能與清單進行有意義的比較。
支援的彙總函數:
-
avg -
median -
max -
min -
sum -
std(標準偏差) -
abs(絕對值) -
index(last(k), i)將允許從最後k個值中選取第i個最近的值。i從零開始索引,所以index(last(3), 0)將傳回最新的資料點;而index(last(3), 3)會導致錯誤,因為只有三個資料點,但我們嘗試對第 4 個最新的資料點編製索引。
範例表達式
ColumnCorrelation
ColumnCorrelation "colA" "colB" < avg(last(10))
DistinctValuesCount
DistinctValuesCount "colA" between min(last(10))-1 and max(last(10))+1
大多數具有數值條件或閾值的規則類型都支援動態規則;請參閱提供的資料表分析器和規則,判斷規則類型是否支援動態規則。
從動態規則排除統計資料
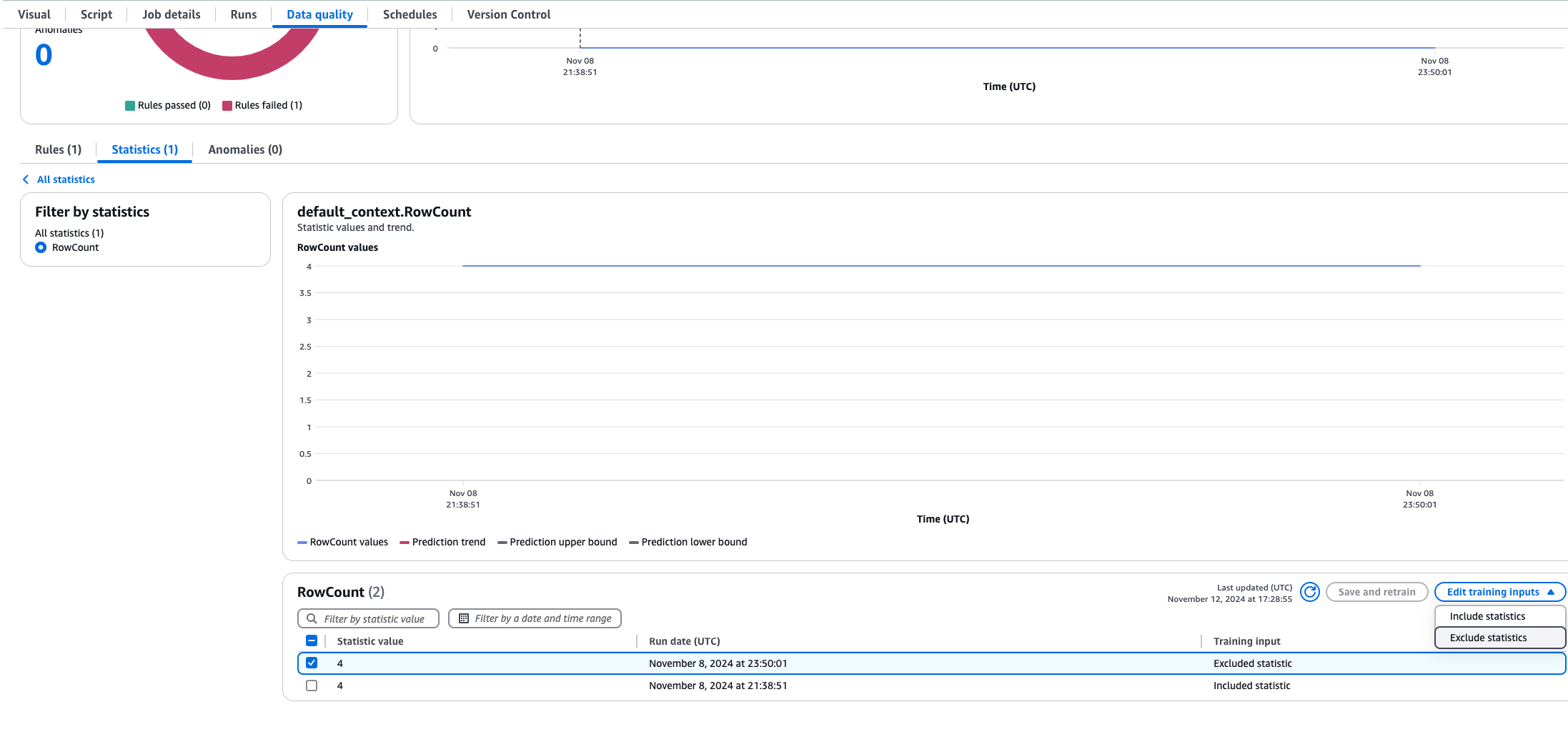
有時,您將需要從動態規則計算中排除資料統計資料。假設您執行了歷史資料載入,而且不想影響您的平均值。若要這樣做,請在 Glue ETL AWS 中開啟任務,然後選擇資料品質索引標籤,然後選擇統計資料,然後選取您要排除的統計資料。您將可以看到趨勢圖表以及統計資料表。選取您要排除的值,然後選擇排除統計資料。現在,排除的統計資料不會包含在動態規則計算中。
分析器
注意
Glue Data Catalog AWS 不支援分析器。
DQDL 規則使用名為 Analyzers 的函數來收集與資料有關的資訊。規則的布林表達式會使用此資訊來判斷規則是成功或是失敗。例如,RowCount 規則 RowCount > 5 會使用資料列計數分析器來探索資料集中的資料列數目,並將該計數與表達式 > 5 進行比較,從而檢查目前資料集中是否存在五個以上的資料列。
有時候,我們建議您建立分析器而不是撰寫規則,然後讓這些分析器產生可用來偵測異常的統計資料。對於這種情況,您可以建立分析器。分析器與規則有下列不同之處。
| 特性 | 分析器 | 規則 |
|---|---|---|
| 規則集的一部分 | 是 | 是 |
| 產生統計資料 | 是 | 是 |
| 產生觀察 | 是 | 是 |
| 可以評估和斷言條件 | 否 | 是 |
| 您可以設定動作,例如在失敗時停止作業、繼續處理作業 | 否 | 是 |
分析器可以在沒有規則的情況下獨立存在,因此您可以快速設定這些分析器並逐步建置資料品質規則。
您可以在規則集的 Analyzers 區塊中輸入某些規則類型,以執行分析器所需的規則並收集資訊,而無需對任何條件套用檢查。某些分析器不會與規則相關聯,在 Analyzers 區塊中只能作為輸入。下表指出每個項目是否受到規則或獨立分析器的支援,以及每個規則類型的其他詳細資訊。
使用 Analyzer 的範例 Ruleset
以下規則集使用:
-
動態規則,檢查資料集的成長速度是否超過在過去三次作業執行的結尾平均值
-
DistinctValuesCount分析器,記錄資料集Name資料欄中相異值的數目 -
ColumnLength分析器,追蹤隨時間變化的最小和最大Name尺寸
您可以在作業執行的「資料品質」索引標籤中檢視分析器指標結果。
Rules = [ RowCount > avg(last(3)) ] Analyzers = [ DistinctValuesCount "Name", ColumnLength "Name" ]
AWS Glue Data Quality 支援下列分析器。
| 分析器名稱 | 功能 |
|---|---|
RowCount |
計算資料集的資料列計數 |
Completeness |
計算資料欄的完整性百分比 |
Uniqueness |
計算資料欄的唯一性百分比 |
Mean |
計算數值資料欄的平均值 |
Sum |
計算數值資料欄的總和 |
StandardDeviation |
計算數值資料欄的標準差 |
Entropy |
計算數值資料欄的熵 |
DistinctValuesCount |
計算資料欄中相異值的數目 |
UniqueValueRatio |
計算資料欄中的唯一值比率 |
ColumnCount |
計算資料集中的資料欄數 |
ColumnLength |
計算資料欄的長度 |
ColumnValues |
計算數值資料欄數的下限和上限。計算非數值資料欄的 ColumnLength 下限和 ColumnLength 上限 |
ColumnCorrelation |
計算所指定資料欄的資料欄關聯性 |
CustomSql |
計算 CustomSQL 傳回的統計資料 |
AllStatistics |
計算下列統計資料:
|
說明
您可以使用 '#' 字元將註解新增至 DQDL 文件。DQDL 會忽略 '#' 字元之後直到行尾的任何內容。
Rules = [ # More items should generally mean a higher price, so correlation should be positive ColumnCorrelation "price" "num_items" > 0 ]
