本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
將 Amazon Aurora Machine Learning 與 Aurora MySQL 搭配使用
透過將 Amazon Aurora 機器學習與 Aurora MySQL 資料庫叢集搭配使用,您可以根據需求使用 Amazon Bedrock、Amazon Comprehend 或 Amazon SageMaker AI。其各自支援不同的機器學習使用案例。
內容
將 Aurora Machine Learning 與 Aurora MySQL 搭配使用的建議
AWS 機器學習服務是在自己的生產環境中設定和執行的受管服務。Aurora 機器學習支援與 Amazon Bedrock、Amazon Comprehend 和 SageMaker AI 的整合。在嘗試設定 Aurora MySQL 資料庫叢集以使用 Aurora Machine Learning 之前,請務必瞭解下列要求和先決條件。
-
機器學習服務必須在與 Aurora MySQL 資料庫叢集 AWS 區域 相同的 中執行。您無法從不同區域的 Aurora MySQL 資料庫叢集使用機器學習服務。
-
如果 Aurora MySQL 資料庫叢集位於與 Amazon Bedrock、Amazon Comprehend 和 SageMaker AI 服務不同的虛擬公有雲 (VPC),則 VPC 的安全群組需要允許目標 Aurora 機器學習服務的輸出連線。如需詳細資訊,請參閱《Amazon VPC 使用者指南》中的使用安全群組控制到 AWS 資源的流量。
-
如果您想要將 Aurora Machine Learning 與該叢集搭配使用,則可以將執行較低版本的 Aurora MySQL 的 Aurora 叢集升級至支援的較高版本。如需詳細資訊,請參閱Amazon Aurora MySQL 的資料庫引擎更新。
-
Aurora MySQL 資料庫叢集必須使用自訂資料庫叢集參數群組。在設定您要使用之每個 Aurora Machine Learning 服務的程序結束時,您可以新增針對該服務所建立之相關聯 IAM 角色的 Amazon Resource Name (ARN)。我們建議您事先為 Aurora MySQL 建立自訂資料庫叢集參數群組,並將 Aurora MySQL 資料庫叢集設定為使用它,以便在安裝程序結束時您就可以加以修改。
-
對於 SageMaker AI:
-
您要用於推論的機器學習元件必須已設定並準備好使用。在設定 Aurora MySQL 資料庫叢集的過程中,您必須具有 SageMaker AI 端點的 ARN 可供使用。您團隊中的資料科學家可能最能夠處理如何使用 SageMaker,以準備模型並處理其他這類任務。若要開始使用 Amazon SageMaker AI,請參閱開始使用 Amazon SageMaker AI。如需推論和端點的詳細資訊,請參閱即時推論。
-
若要搭配您自己的訓練資料使用 SageMaker AI,您需要設定 Amazon S3 儲存貯體,作為 Aurora 機器學習的 Aurora MySQL 組態一部分。若要這樣做,請遵循與設定 SageMaker AI 整合相同的一般程序。如需此選用設定程序的摘要,請參閱 設定 Aurora MySQL 資料庫叢集來使用 Amazon S3 for SageMaker AI (選用)。
-
-
對於 Aurora 全域資料庫,您可以設定要在 AWS 區域 組成 Aurora 全域資料庫的所有 中使用的 Aurora 機器學習服務。例如,如果您想要針對 Aurora 全域資料庫使用 Aurora 機器學習搭配 SageMaker AI,請針對每個 AWS 區域中的每個 Aurora MySQL 資料庫叢集執行以下操作:
-
使用相同的 SageMaker AI 訓練模型和端點設定 Amazon SageMaker AI 服務。這些也必須使用相同的名稱。
-
建立 IAM 角色,如設定 Aurora MySQL 資料庫叢集來使用 Aurora Machine Learning中所述。
-
將 IAM 角色的 ARN 新增至每個 AWS 區域中每個 Aurora MySQL 資料庫叢集的自訂資料庫叢集參數群組。
這些任務需要 Aurora Machine Learning 可用於組成 Aurora 全域資料庫的所有 中的 Aurora MySQL AWS 區域 版本。
-
區域和版本可用性
功能可用性和支援會因每個 Aurora 資料庫引擎的特定版本以及 AWS 區域而有所不同。
-
如需 Amazon Comprehend 和 Amazon SageMaker AI 搭配 Aurora MySQL 的版本和區域可用性資訊,請參閱將機器學習與 Aurora MySQL 搭配使用。
-
僅在 Aurora MySQL 3.06 版及更新版本支援 Amazon Bedrock。
如需 Amazon Bedrock 區域可用性的相關資訊,請參閱《Amazon Bedrock 使用者指南》中的依 AWS 區域的模型支援。
Aurora Machine Learning 搭配 Aurora MySQL 支援的功能和限制
將 Aurora MySQL 與 Aurora 機器學習搭配使用時,適用下列限制:
-
Aurora 機器學習延伸模組不支援向量界面。
-
在觸發條件中使用時,不支援 Aurora 機器學習整合。
Aurora 機器學習函數與二進位記錄 (binlog) 複寫不相容。
-
對於 Aurora Machine Learning 函數的呼叫,設定
--binlog-format=STATEMENT會擲出例外狀況。 -
Aurora Machine Learning 函數是非確定性函數,而且非確定性預存函數與 binlog 格式不相容。
如需詳細資訊,請參閱 MySQL 文件中的二進位日誌格式
。 -
-
不支援呼叫具有一律產生的資料行之資料欄的預存函數。這適用於任何 Aurora MySQL 預存函數。若要進一步了解此資料欄類型,請參閱 MySQL 文件中的 CREATE TABLE和產生的資料欄
。 -
Amazon Bedrock 函數不支援
RETURNS JSON。如有需要,您可以使用CONVERT或CAST從TEXT轉換為JSON。 -
Amazon Bedrock 不支援批次請求。
-
Aurora MySQL 支援任何 SageMaker AI 端點,這些端點可透過
ContentType的text/csv讀取和寫入逗號分隔值 (CSV) 格式。下列內建 SageMaker AI 演算法可接受此格式:-
Linear Learner
-
Random Cut Forest
-
XGBoost
若要進一步了解這些演算法,請參閱《Amazon SageMaker AI 開發人員指南》中的選擇演算法。
-
設定 Aurora MySQL 資料庫叢集來使用 Aurora Machine Learning
在下列主題中,您可以找到其中每個 Aurora Machine Learning 服務的個別設定程序。
主題
設定 Aurora MySQL 資料庫叢集來使用 Amazon Bedrock
Aurora Machine Learning 依賴 AWS Identity and Access Management (IAM) 角色和政策,以允許 Aurora MySQL 資料庫叢集存取和使用 Amazon Bedrock 服務。下列程序會建立 IAM 許可政策和角色,讓資料庫叢集可與 Amazon Bedrock 整合。
若要建立 IAM 政策
登入 AWS Management Console ,並在 https://https://console.aws.amazon.com/iam/
開啟 IAM 主控台。 -
在導覽窗格中選擇政策。
-
選擇 Create a policy (建立政策)。
-
在指定許可頁面,針對選取服務,選擇 Bedrock。
Amazon Bedrock 許可隨即顯示。
-
展開讀取,然後選取 InvokeModel。
-
針對資源選取全部。
指定許可頁面應類似於下圖。
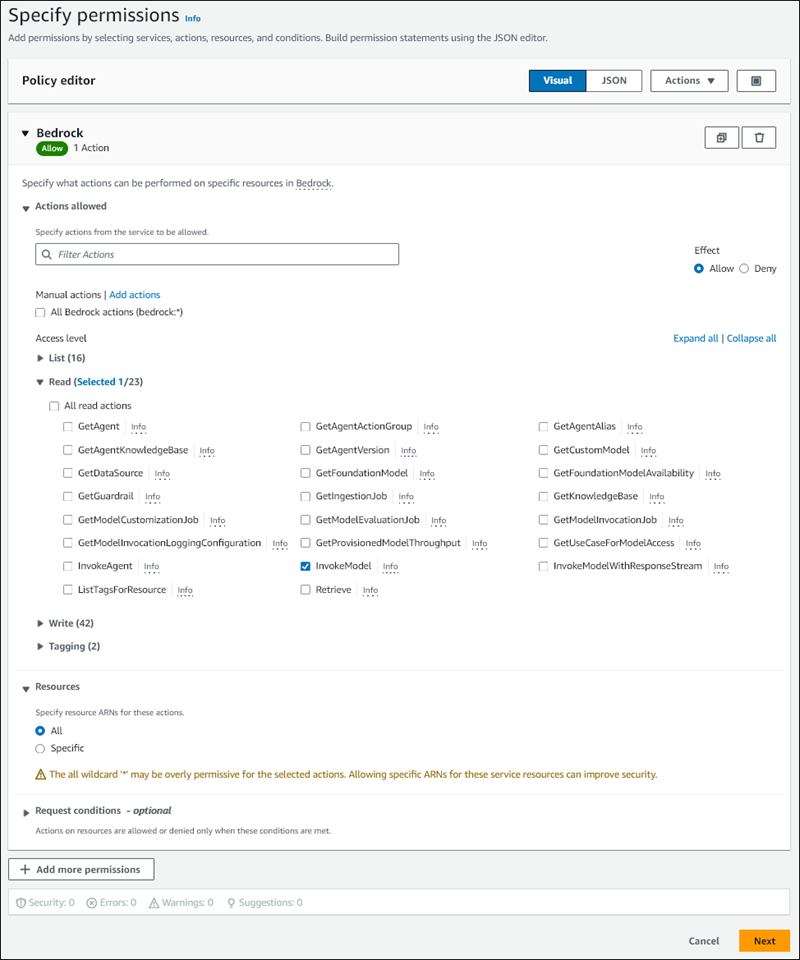
-
選擇下一步。
-
在檢閱和建立頁面,輸入政策名稱 (例如
BedrockInvokeModel)。 -
檢閱政策,然後選擇建立政策。
接著,建立使用 Amazon Bedrock 許可政策的 IAM 角色。
建立 IAM 角色
登入 AWS Management Console ,並在 https://https://console.aws.amazon.com/iam/
開啟 IAM 主控台。 -
在導覽窗格中,選擇 Roles (角色)。
-
選擇建立角色。
-
在選取信任的實體頁面中,對於使用案例選擇 RDS。
-
選取 RDS:將角色新增至資料庫,然後選擇下一步。
-
在新增許可頁面,針對許可政策,選取您建立的 IAM 政策,然後選擇下一步。
-
在命名、檢閱和建立頁面,輸入角色名稱 (例如
ams-bedrock-invoke-model-role)。角色應與下圖類似。
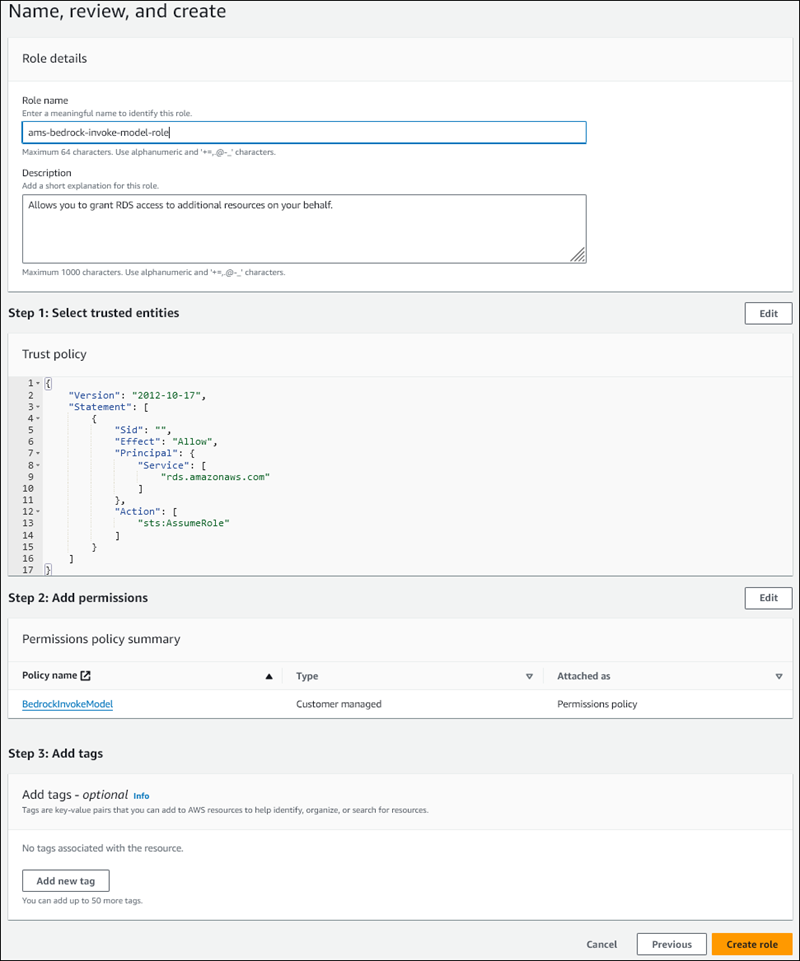
-
檢閱角色,然後選擇建立角色。
接下來,您將 Amazon Bedrock IAM 角色與資料庫叢集建立關聯。
將 IAM 角色與資料庫叢集產生關聯
登入 AWS Management Console ,並在 https://console.aws.amazon.com/rds/
:// 開啟 Amazon RDS 主控台。 -
在導覽窗格中,選擇 Databases (資料庫)。
-
選擇您要連線至 Amazon Bedrock 服務的 Aurora MySQL 資料庫叢集。
-
選擇 Connectivity & security (連線和安全) 索引標籤。
-
在管理 IAM 角色區段中,選擇選取 IAM 以新增至此叢集。
-
選擇您建立的 IAM,然後選擇新增角色。
IAM 角色與資料庫叢集相關聯,一開始的狀態為待定,接著是作用中。程序完成時,您可以在 Current IAM roles for this cluster (此叢集的目前 IAM 角色) 清單中找到該角色。
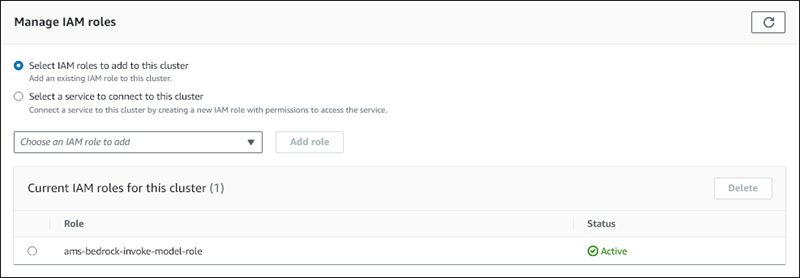
您必須將此 IAM 角色的 ARN 新增至與 Aurora MySQL 資料庫叢集相關聯之自訂資料庫叢集參數群組中的 aws_default_bedrock_role 參數。如果您的 Aurora MySQL 資料庫叢集不使用自訂資料庫叢集參數群組,您必須建立一個群組與 Aurora MySQL 資料庫叢集搭配使用,才能完成整合。如需詳細資訊,請參閱Amazon Aurora 資料庫叢集的資料庫叢集參數群組。
設定資料庫叢集參數
-
在 Amazon RDS 主控台中,開啟 Aurora MySQL 資料庫叢集的 Configuration (組態) 索引標籤。
-
找到為叢集設定的資料庫叢集參數群組。選擇連結以開啟自訂資料庫叢集參數群組,然後選擇編輯。
-
在您的自訂資料庫叢集參數群組中尋找
aws_default_bedrock_role參數。 -
在值欄位中輸入 IAM 角色的 ARN。
-
選擇 Save Changes (儲存變更) 來儲存設定。
-
重新啟動 Aurora MySQL 資料庫叢集的主要執行個體,以便此參數設定生效。
Amazon Bedrock 的 IAM 整合已完成。繼續設定 Aurora MySQL 資料庫叢集,以透過 授與資料庫使用者存取 Aurora Machine Learning 的權限 使用 Amazon Bedrock。
設定您的 Aurora MySQL 資料庫叢集來使用 Amazon Comprehend
Aurora Machine Learning 倚賴 AWS Identity and Access Management 角色和政策,讓您的 Aurora MySQL 資料庫叢集存取和使用 Amazon Comprehend 服務。下列程序會自動為您的叢集建立 IAM 角色和政策,以便其可以使用 Amazon Comprehend。
設定您的 Aurora MySQL 資料庫叢集來使用 Amazon Comprehend
登入 AWS Management Console ,並在 https://console.aws.amazon.com/rds/
:// 開啟 Amazon RDS 主控台。 -
在導覽窗格中,選擇 Databases (資料庫)。
-
選擇您要連線至 Amazon Comprehend 服務的 Aurora MySQL 資料庫叢集。
-
選擇 Connectivity & security (連線和安全) 索引標籤。
-
對於管理 IAM 角色區段中,然後選擇選取服務以連線至這個叢集。
-
從功能表中選擇 Amazon Comprehend,然後選擇連線服務。
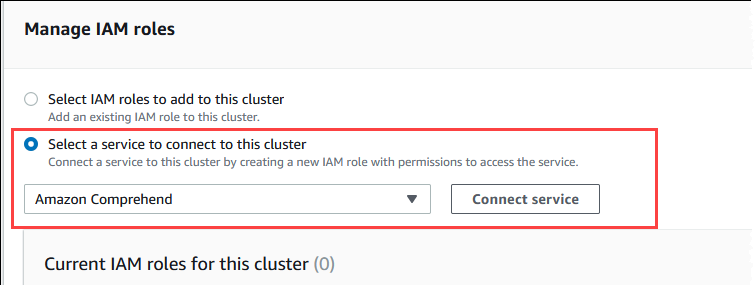
Connect cluster to Amazon Comprehend (將叢集連線到 Amazon Comprehend) 對話方塊不需要任何其他資訊。不過,您可能會看到一則訊息,通知您 Aurora 與 Amazon Comprehend 之間的整合目前處於預覽狀態。請務必先閱讀訊息,然後再繼續。如果您不想繼續,則可以選擇取消。
選擇 Connect service (連線服務) 以完成整合程序。
Aurora 即會建立 IAM 角色。其也會建立允許 Aurora MySQL 資料庫叢集使用 Amazon Comprehend 服務的政策,並將該政策附加到這個角色。程序完成時,您可以在下圖中顯示的 Current IAM roles for this cluster (此叢集的目前 IAM 角色) 清單中找到該角色。
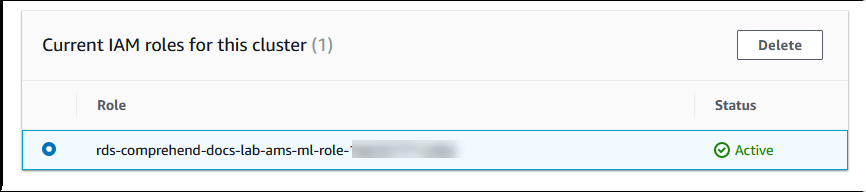
您需要將此 IAM 角色的 ARN 新增至與 Aurora MySQL 資料庫叢集相關聯之自訂資料庫叢集參數群組中的
aws_default_comprehend_role參數。如果您的 Aurora MySQL 資料庫叢集不使用自訂資料庫叢集參數群組,您必須建立一個群組與 Aurora MySQL 資料庫叢集搭配使用,才能完成整合。如需詳細資訊,請參閱Amazon Aurora 資料庫叢集的資料庫叢集參數群組。在建立自訂資料庫叢集參數群組並將其與 Aurora MySQL 資料庫叢集建立關聯之後,您可以繼續遵循下列步驟。
如果您的叢集使用自訂資料庫叢集參數群組,請執行如下操作。
在 Amazon RDS 主控台中,開啟 Aurora MySQL 資料庫叢集的 Configuration (組態) 索引標籤。
-
找到為叢集設定的資料庫叢集參數群組。選擇連結以開啟自訂資料庫叢集參數群組,然後選擇編輯。
在您的自訂資料庫叢集參數群組中尋找
aws_default_comprehend_role參數。在值欄位中輸入 IAM 角色的 ARN。
選擇 Save Changes (儲存變更) 來儲存設定。在下圖中,您可以找到一個範例。
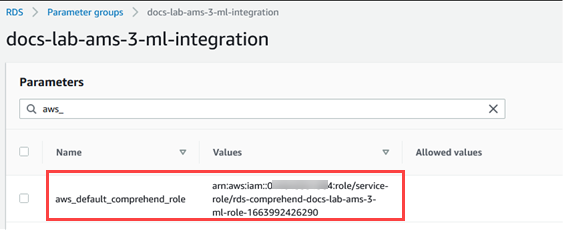
重新啟動 Aurora MySQL 資料庫叢集的主要執行個體,以便此參數設定生效。
Amazon Comprehend 的 IAM 整合已完成。透過將存取權授與適當的資料庫使用者,繼續設定 Aurora MySQL 資料庫叢集以使用 Amazon Comprehend。
設定 Aurora MySQL 資料庫叢集來使用 SageMaker AI
下列程序會自動為您的 Aurora MySQL 資料庫叢集建立 IAM 角色和政策,以便其可以使用 SageMaker AI。在嘗試遵循此程序之前,請確定您具有可用的 SageMaker AI 端點,以便可在需要時輸入它。通常,您團隊中的資料科學家會執行這項工作,以產生您可以從 Aurora MySQL 資料庫叢集使用的端點。您可以在 SageMaker AI 主控台
設定 Aurora MySQL 資料庫叢集來使用 SageMaker AI
登入 AWS Management Console ,並在 https://console.aws.amazon.com/rds/
:// 開啟 Amazon RDS 主控台。 -
從 Amazon RDS 導覽功能表選擇資料庫,然後選擇您要連線至 SageMaker AI 服務的 Aurora MySQL 資料庫叢集。
-
選擇 Connectivity & security (連線和安全) 索引標籤。
-
捲動至 Manage IAM roles (管理 IAM 角色) 區段中,然後選擇 Select a service to connect to this cluster (選取服務以連線至這個叢集)。從選擇器中選擇 SageMaker AI。
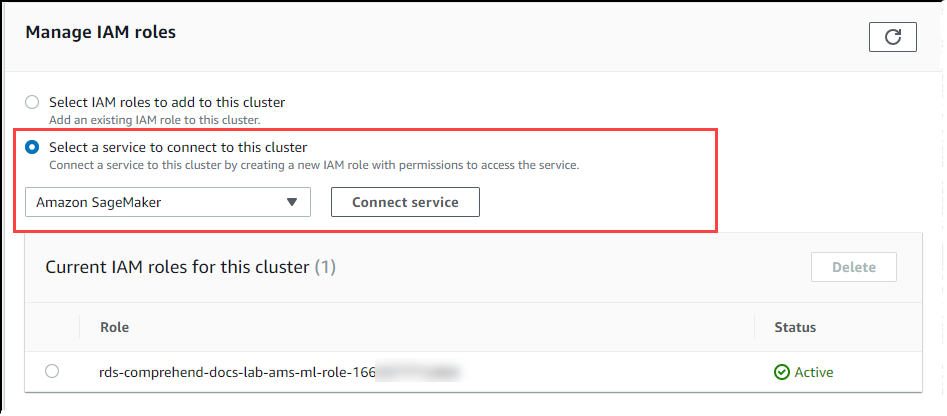
選擇 Connect service (連線服務)。
在將叢集連線至 SageMaker 對話方塊中,輸入 SageMaker AI 端點的 ARN。
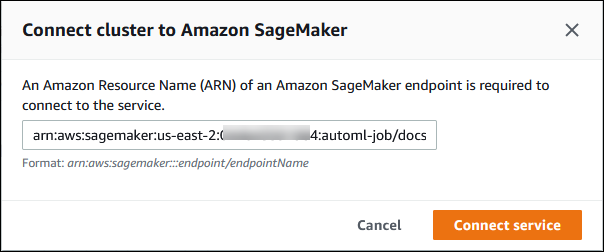
-
Aurora 即會建立 IAM 角色。其也會建立允許 Aurora MySQL 資料庫叢集使用 SageMaker AI 服務的政策,並將該政策附加到這個角色。程序完成時,您可以在 Current IAM roles for this cluster (此叢集的目前 IAM 角色) 清單中找到該角色。
前往 https://console.aws.amazon.com/iam/
開啟 IAM 主控台。 從 AWS Identity and Access Management 導覽功能表的 Access management (存取管理) 區段中選擇 Roles (角色)。
在列出的角色之中尋找該角色。它的名稱會使用以下模式。
rds-sagemaker-your-cluster-name-role-auto-generated-digits開啟角色的 Summary (摘要) 頁面並找出 ARN。請注意 ARN 或使用複製 Widget 將其複製。
前往 https://console.aws.amazon.com/rds/
,開啟 Amazon RDS 主控台。 選擇您的 Aurora MySQL 資料庫叢集,然後選擇其 Configuration (組態) 索引標籤。
找出資料庫叢集參數群組,然後選擇連結來開啟您的自訂資料庫叢集參數群組。尋找
aws_default_sagemaker_role參數並在 Value (值) 欄位中輸入 IAM 角色的 ARN,然後儲存設定。重新啟動 Aurora MySQL 資料庫叢集的主要執行個體,以便此參數設定生效。
IAM 設定現已完成。透過將存取權授與適當的資料庫使用者,繼續設定 Aurora MySQL 資料庫叢集以使用 SageMaker AI。
如果您想要使用 SageMaker AI 模型進行訓練,而不是使用預先建置的 SageMaker AI 元件,您還需要將 Amazon S3 儲存貯體新增至 Aurora MySQL 資料庫叢集,如後續的設定 Aurora MySQL 資料庫叢集來使用 Amazon S3 for SageMaker AI (選用) 中所述。
設定 Aurora MySQL 資料庫叢集來使用 Amazon S3 for SageMaker AI (選用)
若要搭配您自己的模型使用 SageMaker AI,而不是使用 SageMaker AI 提供的預先建置元件,您需要設定 Amazon S3 儲存貯體,供 Aurora MySQL 資料庫叢集使用。如需有關建立 Amazon S3 儲存貯體的詳細資訊,請參閱 Amazon Simple Storage Service 使用者指南中的建立儲存貯體。
設定 Aurora MySQL 資料庫叢集來使用 SageMaker AI 的 Amazon S3 儲存貯體
登入 AWS Management Console ,並在 https://console.aws.amazon.com/rds/
:// 開啟 Amazon RDS 主控台。 -
從 Amazon RDS 導覽功能表選擇資料庫,然後選擇您要連線至 SageMaker AI 服務的 Aurora MySQL 資料庫叢集。
-
選擇 Connectivity & security (連線和安全) 索引標籤。
-
捲動至 Manage IAM roles (管理 IAM 角色) 區段中,然後選擇 Select a service to connect to this cluster (選取服務以連線至這個叢集)。從選擇器中選擇 Amazon S3。
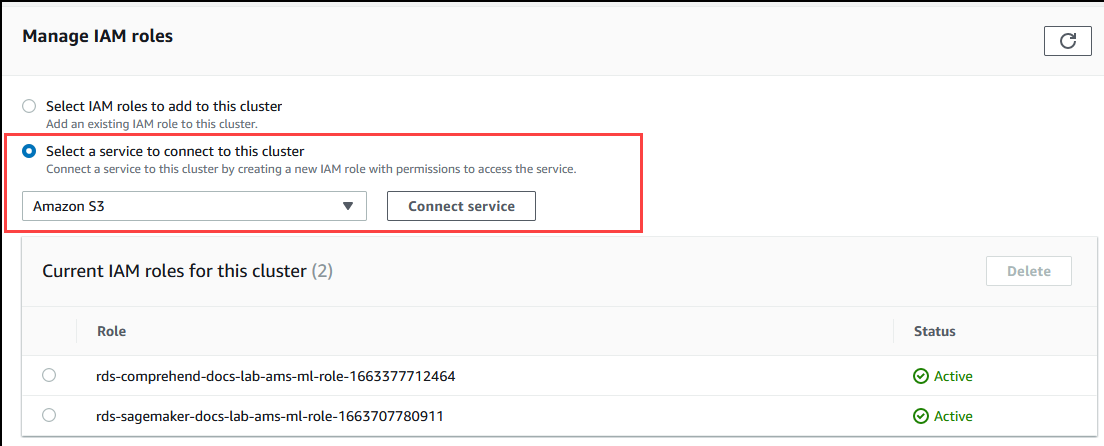
選擇 Connect service (連線服務)。
在將叢集連線至 Amazon S3 對話方塊中,輸入 Amazon S3 儲存貯體的 ARN,如下圖所示。
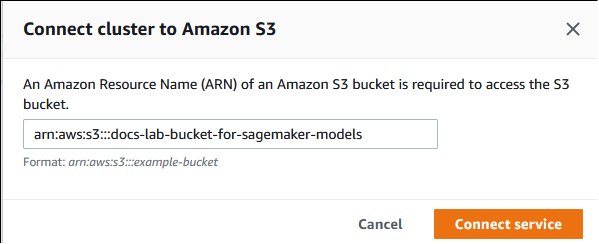
選擇 Connect service (連線服務) 以完成此程序。
如需搭配 SageMaker AI 使用 Amazon S3 儲存貯體的詳細資訊,請參閱《Amazon SageMaker AI 開發人員指南》中的指定 Amazon S3 儲存貯體以上傳訓練資料集和存放輸出資料。若要進一步了解如何使用 SageMaker AI,請參閱《Amazon SageMaker AI 開發人員指南》中的開始使用 Amazon SageMaker AI 筆記本執行個體。
授與資料庫使用者存取 Aurora Machine Learning 的權限
資料庫使用者必須獲授與調用 Aurora 機器學習函數的許可。授與許可的方式取決於您用於 Aurora MySQL 資料庫叢集的 MySQL 版本,如下所述。如何執行此操作取決於 Aurora MySQL 資料庫叢集使用的 MySQL 版本。
下表顯示資料庫使用者使用機器學習函數所需的角色和權限。
| Aurora MySQL 第 3 版 (角色) | Aurora MySQL 第 2 版 (權限) |
|---|---|
|
AWS_BEDROCK_ACCESS |
– |
|
AWS_COMPREHEND_ACCESS |
INVOKE COMPREHEND |
|
AWS_SAGEMAKER_ACCESS |
INVOKE SAGEMAKER |
授與 Amazon Bedrock 函數的存取權
若要讓資料庫使用者存取 Amazon Bedrock 函數,請使用下列 SQL 陳述式:
GRANT AWS_BEDROCK_ACCESS TOuser@domain-or-ip-address;
對於您為了使用 Amazon Bedrock 而建立的函數,資料庫使用者也需要獲授與 EXECUTE 許可:
GRANT EXECUTE ON FUNCTIONdatabase_name.function_nameTOuser@domain-or-ip-address;
最後,資料庫使用者的角色必須設為 AWS_BEDROCK_ACCESS:
SET ROLE AWS_BEDROCK_ACCESS;
Amazon Bedrock 函數現在可供使用。
授與 Amazon Comprehend 函數的存取權
若要讓資料庫使用者能夠存取 Amazon Comprehend 函數,請針對您的 Aurora MySQL 版本使用適當的陳述式。
Aurora MySQL 第 3 版 (與 MySQL 8.0 相容)
GRANT AWS_COMPREHEND_ACCESS TOuser@domain-or-ip-address;Aurora MySQL 第 2 版 (與 MySQL 5.7 相容)
GRANT INVOKE COMPREHEND ON *.* TOuser@domain-or-ip-address;
Amazon Comprehend 函數現在可供使用。如需使用範例,請參閱 搭配 Aurora MySQL 資料庫叢集使用 Amazon Comprehend。
授與 SageMaker AI 函數的存取權
若要讓資料庫使用者能夠存取 SageMaker AI 函數,請針對 Aurora MySQL 版本使用適當的陳述式。
Aurora MySQL 第 3 版 (與 MySQL 8.0 相容)
GRANT AWS_SAGEMAKER_ACCESS TOuser@domain-or-ip-address;Aurora MySQL 第 2 版 (與 MySQL 5.7 相容)
GRANT INVOKE SAGEMAKER ON *.* TOuser@domain-or-ip-address;
對於您為了使用 SageMaker AI 而建立的函數,資料庫使用者也需要獲授與 EXECUTE 許可。假設您建立了兩個函數 (db1.anomoly_score 和 db2.company_forecasts) 來調用 SageMaker AI 端點的服務。您會如下範例所示授與執行權限。
GRANT EXECUTE ON FUNCTION db1.anomaly_score TOuser1@domain-or-ip-address1; GRANT EXECUTE ON FUNCTION db2.company_forecasts TOuser2@domain-or-ip-address2;
SageMaker AI 函數現在可供使用。如需使用範例,請參閱 搭配 Aurora MySQL 資料庫叢集使用 SageMaker AI。
搭配 Aurora MySQL 資料庫叢集使用 Amazon Bedrock
若要使用 Amazon Bedrock,您可以在調用模型的 Aurora MySQL 資料庫中建立使用者定義函數 (UDF)。如需詳細資訊,請參閱《Amazon Bedrock 使用者指南》中的 Amazon Bedrock 中支援的模型。
UDF 使用以下語法:
CREATE FUNCTIONfunction_name(argumenttype) [DEFINER = user] RETURNSmysql_data_type[SQL SECURITY {DEFINER | INVOKER}] ALIAS AWS_BEDROCK_INVOKE_MODEL MODEL ID 'model_id' [CONTENT_TYPE 'content_type'] [ACCEPT 'content_type'] [TIMEOUT_MStimeout_in_milliseconds];
-
Amazon Bedrock 函數不支援
RETURNS JSON。如有需要,您可以使用CONVERT或CAST從TEXT轉換為JSON。 -
如未指定
CONTENT_TYPE或ACCEPT,預設值將會是application/json。 -
如未指定
TIMEOUT_MS,將會使用aurora_ml_inference_timeout值。
例如,下列 UDF 會調用 Amazon Titan Text 快捷版模型:
CREATE FUNCTION invoke_titan (request_body TEXT) RETURNS TEXT ALIAS AWS_BEDROCK_INVOKE_MODEL MODEL ID 'amazon.titan-text-express-v1' CONTENT_TYPE 'application/json' ACCEPT 'application/json';
若要允許資料庫使用者使用此函數,請使用下列 SQL 命令:
GRANT EXECUTE ON FUNCTIONdatabase_name.invoke_titan TOuser@domain-or-ip-address;
然後,如下列範例所示,使用者可以像任何其他函數一樣呼叫 invoke_titan。請務必根據 Amazon Titan 文字模型格式化請求內文。
CREATE TABLE prompts (request varchar(1024)); INSERT INTO prompts VALUES ( '{ "inputText": "Generate synthetic data for daily product sales in various categories - include row number, product name, category, date of sale and price. Produce output in JSON format. Count records and ensure there are no more than 5.", "textGenerationConfig": { "maxTokenCount": 1024, "stopSequences": [], "temperature":0, "topP":1 } }'); SELECT invoke_titan(request) FROM prompts; {"inputTextTokenCount":44,"results":[{"tokenCount":296,"outputText":" ```tabular-data-json { "rows": [ { "Row Number": "1", "Product Name": "T-Shirt", "Category": "Clothing", "Date of Sale": "2024-01-01", "Price": "$20" }, { "Row Number": "2", "Product Name": "Jeans", "Category": "Clothing", "Date of Sale": "2024-01-02", "Price": "$30" }, { "Row Number": "3", "Product Name": "Hat", "Category": "Accessories", "Date of Sale": "2024-01-03", "Price": "$15" }, { "Row Number": "4", "Product Name": "Watch", "Category": "Accessories", "Date of Sale": "2024-01-04", "Price": "$40" }, { "Row Number": "5", "Product Name": "Phone Case", "Category": "Accessories", "Date of Sale": "2024-01-05", "Price": "$25" } ] } ```","completionReason":"FINISH"}]}
對於您使用的其他模型,請務必為其適當地格式化請求內文。如需詳細資訊,請參閱《Amazon Bedrock 使用者指南》中的基礎模型的推論參數。
搭配 Aurora MySQL 資料庫叢集使用 Amazon Comprehend
對於 Aurora MySQL,Aurora Machine Learning 提供下列兩個內建函數,用於使用 Amazon Comprehend 和您的文字資料。您會提供要分析的文字 (input_data) 並指定語言 (language_code)。
- aws_comprehend_detect_sentiment
-
此函數會將文字識別為具有正面、負面、中性或混合的情緒狀態。此函數的參考文件如下。
aws_comprehend_detect_sentiment( input_text, language_code [,max_batch_size] )若要進一步了解,請參閱《Amazon 開發人員指南》中的情緒。
- aws_comprehend_detect_sentiment_confidence
-
此函數會測量針對指定文字偵測到之情緒的信賴等級。它會傳回一值 (類型
double),指出由 aws_comprehend_detect_sentiment 函數指派給文字的情緒信賴度。信賴度是介於 0 和 1 之間的統計指標。信賴等級越高,您可以給與結果的權重就越多。函數文件的摘要如下。aws_comprehend_detect_sentiment_confidence( input_text, language_code [,max_batch_size] )
在這兩個函數 (aws_comprehend_detect_sentiment_confidence、aws_comprehend_detect_sentiment) 中,max_batch_size 會使用預設值 25,如果未指定任何值的話。批次大小應該始終大於 0。您可以使用 max_batch_size 來調整 Amazon Comprehend 函數呼叫的效能。較大的批次大小犧牲較快的效能,以換取 Aurora MySQL 資料庫叢集上較大的記憶體用量。如需詳細資訊,請參閱搭配 Aurora MySQL 使用 Aurora Machine Learning 的效能考量。
如需 Amazon Comprehend 中情緒偵測函數的參數和傳回類型的詳細資訊,請參閱 DetectSentiment
範例範例:使用 Amazon Comprehend 的簡單查詢
以下是簡單查詢的範例,該查詢會叫用這兩個函數,以查看您的客戶對支援團隊的滿意程度。假設您有一個資料庫資料表 (support),其會在每次請求協助之後存放客戶意見回饋。這個範例查詢會將兩個內建函數套用至資料表的 feedback 資料欄中的文字,並輸出結果。函數傳回的信賴度值為介於 0.0 和 1.0 之間的倍準數。為了獲得更易讀取的輸出,此查詢將結果四捨五入為 6 個小數點。為了更輕鬆地進行比較,這個查詢也會先從具有最高信賴度的結果中,以遞減順序排序結果。
SELECT feedback AS 'Customer feedback', aws_comprehend_detect_sentiment(feedback, 'en') AS Sentiment, ROUND(aws_comprehend_detect_sentiment_confidence(feedback, 'en'), 6) AS Confidence FROM support ORDER BY Confidence DESC;+----------------------------------------------------------+-----------+------------+ | Customer feedback | Sentiment | Confidence | +----------------------------------------------------------+-----------+------------+ | Thank you for the excellent customer support! | POSITIVE | 0.999771 | | The latest version of this product stinks! | NEGATIVE | 0.999184 | | Your support team is just awesome! I am blown away. | POSITIVE | 0.997774 | | Your product is too complex, but your support is great. | MIXED | 0.957958 | | Your support tech helped me in fifteen minutes. | POSITIVE | 0.949491 | | My problem was never resolved! | NEGATIVE | 0.920644 | | When will the new version of this product be released? | NEUTRAL | 0.902706 | | I cannot stand that chatbot. | NEGATIVE | 0.895219 | | Your support tech talked down to me. | NEGATIVE | 0.868598 | | It took me way too long to get a real person. | NEGATIVE | 0.481805 | +----------------------------------------------------------+-----------+------------+ 10 rows in set (0.1898 sec)
範例範例:判斷文字高於特定信賴等級的平均情緒
一般 Amazon Comprehend 查詢尋找情緒等於特定值且信心水準大於特定數字的列。例如,下列查詢顯示如何判斷資料庫中文件的平均情緒。此查詢只考量評估信心至少達 80% 的文件。
SELECT AVG(CASE aws_comprehend_detect_sentiment(productTable.document, 'en') WHEN 'POSITIVE' THEN 1.0 WHEN 'NEGATIVE' THEN -1.0 ELSE 0.0 END) AS avg_sentiment, COUNT(*) AS total FROM productTable WHERE productTable.productCode = 1302 AND aws_comprehend_detect_sentiment_confidence(productTable.document, 'en') >= 0.80;
搭配 Aurora MySQL 資料庫叢集使用 SageMaker AI
若要從 Aurora MySQL 資料庫叢集使用 SageMaker AI 功能,您需要建立預存函數,將呼叫嵌入至 SageMaker AI 端點及其推論功能。您通常會使用 MySQL 的 CREATE FUNCTION 執行此操作,其方式與您針對 Aurora MySQL 資料庫叢集上其他處理任務所做的方式相同。
若要使用於 SageMaker AI 部署的模型來推論,請使用您在預存函數中 MySQL 資料定義語言 (DDL) 陳述式,建立使用者定義的函數。每個預存函數代表託管模型的 SageMaker AI 端點。當您定義這類函數時,您指定模型的輸入參數、要調用的特定 SageMaker AI 端點,以及傳回類型。將模型套用至輸入參數後,此函數會傳回 SageMaker AI 端點計算的推論。
所有 Aurora Machine Learning 預存函數傳回數值類型或 VARCHAR。您可以使用 BIT 除外的任何數值類型。不允許其他類型,例如 JSON、BLOB、TEXT 和 DATE。
下列範例顯示使用 SageMaker AI 的 CREATE FUNCTION 語法。
CREATE FUNCTION function_name (
arg1 type1,
arg2 type2, ...)
[DEFINER = user]
RETURNS mysql_type
[SQL SECURITY { DEFINER | INVOKER } ]
ALIAS AWS_SAGEMAKER_INVOKE_ENDPOINT
ENDPOINT NAME 'endpoint_name'
[MAX_BATCH_SIZE max_batch_size];
這是一般 CREATE FUNCTION DDL 陳述式的延伸。在定義 SageMaker AI 函數的 CREATE FUNCTION 陳述式中,您不指定函數主體。反之,在通常出現函數主體的地方,您指定關鍵字 ALIAS。目前,對於此延伸語法,Aurora Machine Learning 僅支援 aws_sagemaker_invoke_endpoint。您必須指定 endpoint_name 參數。針對每個模型,SageMaker AI 端點可能有不同的特性。
注意
如需 CREATE FUNCTION 的詳細資訊,請參閱《MySQL 8.0 參考手冊》中的 CREATE PROCEDURE 和 CREATE FUNCTION 陳述式
max_batch_size 為選用參數。根據預設,批次大小上限為 10,000。您可以在函數中使用此參數,來限制 SageMaker AI 批次請求中處理的輸入數目上限。max_batch_size 參數有助於避免太大的輸入所造成的錯誤,或讓 SageMaker AI 更快傳回回應。此參數會影響 SageMaker AI 請求處理使用的內部緩衝區大小。指定太大的 max_batch_size 值可能造成資料庫執行個體耗用大量記憶體。
建議將 MANIFEST 設定保留為預設值 OFF。雖然您可以使用 MANIFEST ON 選項,但有些 SageMaker AI 功能無法直接使用以此選項匯出的 CSV。資訊清單格式與 SageMaker AI 預期的資訊清單格式不相容。
您為每個 SageMaker AI 模型建立個別的預存函數。因為端點與特定模型相關聯,而且每個模型接受的參數不同,函數至模型的這種對應有其必要。針對模型輸入和模型輸出類型使用 SQL 類型,有助於避免在 AWS 服務之間來回傳遞資料的類型轉換錯誤。您可以控制誰可以套用模型。您也可以指定參數來代表批次大小上限,以控制執行時間特性。
目前,所有 Aurora Machine Learning 函數都有 NOT DETERMINISTIC 屬性。如果您不明確指定屬性,Aurora 會自動設定 NOT DETERMINISTIC。有此需求是因為 SageMaker AI 模型可能變更,但完全不通知資料庫。如果發生此狀況,在單一交易內呼叫 Aurora Machine Learning 函數時,即使是相同輸入,也可能傳回不同結果。
在 CONTAINS SQL 陳述式中,您不能使用特性 NO SQL、READS SQL DATA、MODIFIES SQL DATA 或 CREATE
FUNCTION。
以下是調用 SageMaker AI 端點來偵測異常的使用範例。有一個 SageMaker AI 端點 random-cut-forest-model。對應的模型已由 random-cut-forest 演算法訓練。對於每個輸入,模型傳回異常分數。此範例顯示資料點的分數比平均分數還大 3 個標準差 (大約第 99.9 百分位數)。
CREATE FUNCTION anomaly_score(value real) returns real
alias aws_sagemaker_invoke_endpoint endpoint name 'random-cut-forest-model-demo';
set @score_cutoff = (select avg(anomaly_score(value)) + 3 * std(anomaly_score(value)) from nyc_taxi);
select *, anomaly_detection(value) score from nyc_taxi
where anomaly_detection(value) > @score_cutoff;
傳回字串的 SageMaker AI 函數的字元集需求
對於傳回字串值的 SageMaker AI 函數,建議指定字元集 utf8mb4 當作傳回類型。如果這不切實際,請對傳回類型使用夠大的字串長度,以保存 utf8mb4 字元集所代表的值。下列範例顯示如何為函數宣告 utf8mb4 字元集。
CREATE FUNCTION my_ml_func(...) RETURNS VARCHAR(5) CHARSET utf8mb4 ALIAS ...目前,每個會傳回字串的 SageMaker AI 函數都以 utf8mb4 作為傳回值的字元集。即使 SageMaker AI 函數隱含或明確宣告其傳回類型為不同字元集,傳回值還是使用此字元集。如果 SageMaker AI 函數宣告傳回值為不同字元集,假設傳回的資料存放在不夠長的資料表欄,則可能自動截斷。例如,搭配 DISTINCT 子句的查詢會導致建立臨時資料表。因此,由於查詢期間內部處理字串的方式,SageMaker AI 函數結果可能截斷。
將資料匯出至 Amazon S3 進行 SageMaker AI 模型訓練 (進階)
我們建議您使用一些提供的演算法,開始使用 Aurora 機器學習和 SageMaker AI,並建議團隊中的資料科學家會為您提供可與 SQL 程式碼搭配使用的 SageMaker AI 端點。在下文中,您可以找到有關將自己的 Amazon S3 儲存貯體與您自己的 SageMaker AI 模型和 Aurora MySQL 資料庫叢集搭配使用的基本資訊。
機器學習包括兩個主要步驟:訓練和推論。如要訓練 SageMaker AI 模型,您可以將資料匯出到 Amazon S3 儲存貯體。部署模型之前,Jupyter SageMaker AI 筆記本執行個體使用 Amazon S3 儲存貯體來訓練模型。您可以使用 SELECT INTO OUTFILE S3 陳述式從 Aurora MySQL 資料庫叢集查詢資料,然後將資料直接儲存至 Amazon S3 儲存貯體中存放的文字檔案。然後,筆記本執行個體從 Amazon S3 儲存貯體取用資料進行訓練。
Aurora Machine Learning 延伸 Aurora MySQL 中現有的 SELECT INTO OUTFILE 語法,將資料匯出為 CSV 格式。在訓練用途上需要此格式的模型,可以直接取用產生的 CSV 檔案。
SELECT * INTO OUTFILE S3 's3_uri' [FORMAT {CSV|TEXT} [HEADER]] FROM table_name;此延伸支援標準 CSV 格式。
-
格式
TEXT與現有的 MySQL 匯出格式相同。此為預設格式。 -
格式
CSV是新推出的格式,遵守 RFC-4180的規格。 -
如果您指定選用的關鍵字
HEADER,則輸出檔包含一個標題列。標題列的標籤對應於SELECT陳述式中的欄名稱。 -
您仍可使用關鍵字
CSV和HEADER當作識別符。
SELECT INTO 延伸的語法和文法現在如下所示:
INTO OUTFILE S3 's3_uri'
[CHARACTER SET charset_name]
[FORMAT {CSV|TEXT} [HEADER]]
[{FIELDS | COLUMNS}
[TERMINATED BY 'string']
[[OPTIONALLY] ENCLOSED BY 'char']
[ESCAPED BY 'char']
]
[LINES
[STARTING BY 'string']
[TERMINATED BY 'string']
]
搭配 Aurora MySQL 使用 Aurora Machine Learning 的效能考量
當透過 Aurora 機器學習函數調用時,Amazon Bedrock、Amazon Comprehend 和 SageMaker AI 服務會執行大部分工作。這表示您可以視需要獨立擴展這些資源。對於您的 Aurora MySQL 資料庫叢集,您可以盡可能有效地進行函數呼叫。接下來,您可以找到使用 Aurora Machine Learning 時需要注意的一些效能考量。
模型和提示
使用 Amazon Bedrock 時的效能高度取決於您所使用的模型和提示。選擇最適合您使用案例的模型和提示。
查詢快取
Aurora MySQL 查詢快取不適用於 Aurora Machine Learning 函數。Aurora MySQL 不將查詢結果存放在查詢快取中任何呼叫 Aurora Machine Learning 函數的 SQL 陳述式之中。
Aurora Machine Learning 函數呼叫的批次最佳化
您從 Aurora 叢集可影響的主要 Aurora Machine Learning 效能方面,是 Aurora Machine Learning 預存函數呼叫的批次模式設定。機器學習函數通常需要大量的額外負荷,因此為每個資料列單獨呼叫外部服務並不實用。Aurora Machine Learning 可以將許多資料列對外部 Aurora Machine Learning 服務的呼叫合併成單一批次,來減少這項額外負荷。Aurora Machine Learning 會收到所有輸入資料列的回應,然後一次一列將回應傳給執行中的查詢。此最佳化改善 Aurora 查詢的傳輸量和延遲,而不變更結果。
建立會連線至 SageMaker AI 端點的 Aurora 預存函數時,您會定義批次大小參數。此參數影響每次在幕後呼叫 SageMaker AI 時傳輸多少列。如果查詢處理許多列,針對每一列來個別呼叫 SageMaker AI 會產生極大的額外負荷。預存程序處理的資料集越大,批次大小就應該越大。
如果批次模式最佳化可套用至 SageMaker AI 函數,您可以檢查 EXPLAIN PLAN 陳述式產生的查詢計劃來辨別。在此情況下,執行計劃的 extra 欄包含 Batched machine learning。下列範例顯示對 SageMaker AI 函數的呼叫 (使用批次模式)。
mysql> CREATE FUNCTION anomaly_score(val real) returns real alias aws_sagemaker_invoke_endpoint endpoint name 'my-rcf-model-20191126';
Query OK, 0 rows affected (0.01 sec)
mysql> explain select timestamp, value, anomaly_score(value) from nyc_taxi;
+----+-------------+----------+------------+------+---------------+------+---------+------+------+----------+--------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+----------+------------+------+---------------+------+---------+------+------+----------+--------------------------+
| 1 | SIMPLE | nyc_taxi | NULL | ALL | NULL | NULL | NULL | NULL | 48 | 100.00 | Batched machine learning |
+----+-------------+----------+------------+------+---------------+------+---------+------+------+----------+--------------------------+
1 row in set, 1 warning (0.01 sec)
當您呼叫其中一個內建的 Amazon Comprehend 函數時,您可以指定選用的 max_batch_size 參數,以控制批次大小。此參數限制每個批次中處理的 input_text 值數量上限。一次傳送多個項目可減少 Aurora 與 Amazon Comprehend 之間的來回次數。在查詢搭配 LIMIT 子句的情況下,限制批次大小很有用。max_batch_size 使用較小的值可避免叫用 Amazon Comprehend 的次數超過您輸入文字的次數。
評估 Aurora Machine Learning 函數時的批次最佳化適用於下列情況:
-
在 select 清單或
SELECT陳述式的WHERE子句內的函數呼叫 -
在
INSERT和REPLACE陳述式VALUES清單中的函數呼叫 -
在
UPDATE陳述式的SET值中的 SageMaker AI 函數:INSERT INTO MY_TABLE (col1, col2, col3) VALUES (ML_FUNC(1), ML_FUNC(2), ML_FUNC(3)), (ML_FUNC(4), ML_FUNC(5), ML_FUNC(6)); UPDATE MY_TABLE SET col1 = ML_FUNC(col2), SET col3 = ML_FUNC(col4) WHERE ...;
監控 Aurora Machine Learning
如下範例所示,您可以查詢數個全域變數來監控 Aurora 機器學習批次作業。
show status like 'Aurora_ml%';
您可以使用 FLUSH STATUS 陳述式來重設狀態變數。因此,所有數據代表上次重設變數以來的總計、平均等。
Aurora_ml_logical_request_cnt-
自上次重新設定狀態後,資料庫執行個體已評估傳送至 Aurora 機器學習服務的邏輯請求數目。視是否使用批次處理而定,此值可能會大於
Aurora_ml_actual_request_cnt。 Aurora_ml_logical_response_cnt-
Aurora MySQL 從 Aurora Machine Learning 服務接收的彙總回應計數,涵蓋資料庫執行個體的使用者執行的所有查詢。
Aurora_ml_actual_request_cnt-
Aurora MySQL 從 Aurora 機器學習服務接收的彙總請求計數,涵蓋資料庫執行個體的使用者執行的所有查詢。
Aurora_ml_actual_response_cnt-
Aurora MySQL 從 Aurora Machine Learning 服務接收的彙總回應計數,涵蓋資料庫執行個體的使用者執行的所有查詢。
Aurora_ml_cache_hit_cnt-
Aurora MySQL 從 Aurora Machine Learning 服務接收的彙總內部快取命中計數,涵蓋資料庫執行個體的使用者執行的所有查詢。
Aurora_ml_retry_request_cnt-
自上次重新設定狀態後,資料庫執行個體傳送至 Aurora 機器學習服務的重試請求數目。
Aurora_ml_single_request_cnt-
由非批次模式評估的 Aurora Machine Learning 函數的彙總計數,涵蓋資料庫執行個體的使用者執行的所有查詢。
如需詳細資訊,了解如何監控從 Aurora 機器學習函數呼叫之 SageMaker AI 操作的效能,請參閱監控 Amazon SageMaker AI。
