本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
Connect Customer 中的流量块:设置语音
本主题定义了用于设置联系流中使用的文字转语音 (TTS) 语言和语音的流数据块。
说明
-
设置用于联系流的文本到语音转换(TTS)语言和语音。
-
默认语音配置为 Joanna(对话式说话风格)。
-
运行此数据块后,任何 TTS 调用都会解析为所选的神经语音、标准语音或生成式语音。
-
如果在聊天对话过程中触发了此数据块,联系人将路由到成功分支。它不会对聊天体验产生任何影响。
-
您将需要因使用生成式语音而付费。有关定价的更多详细信息,请参阅 Amazon Polly 定价详细信息
-
如果您已启用新一代 Amazon Connect,则生成式语音将包含在新一代 Amazon Connect 定价中。
注意
如果您的实例是在 2018 年 10 月之前创建的,并且此后您已迁移到服务相关角色(SLR),则需要向服务角色(SR)添加以下自定义权限才能访问生成式引擎。
{ "Sid": "AllowPollyActions", "Effect": "Allow", "Action": [ "polly:SynthesizeSpeech" ], "Resource": [ "*" ] }
支持的渠道
下表列出了此数据块如何路由正在使用指定渠道的联系人。
| 频道 | 是否支持? |
|---|---|
语音 |
是 |
Chat |
不支持 - 成功分支 |
Task |
不支持 - 成功分支 |
电子邮件 |
不支持 - 成功分支 |
流类型
您可以在以下流类型中使用此数据块:
-
所有流
Properties
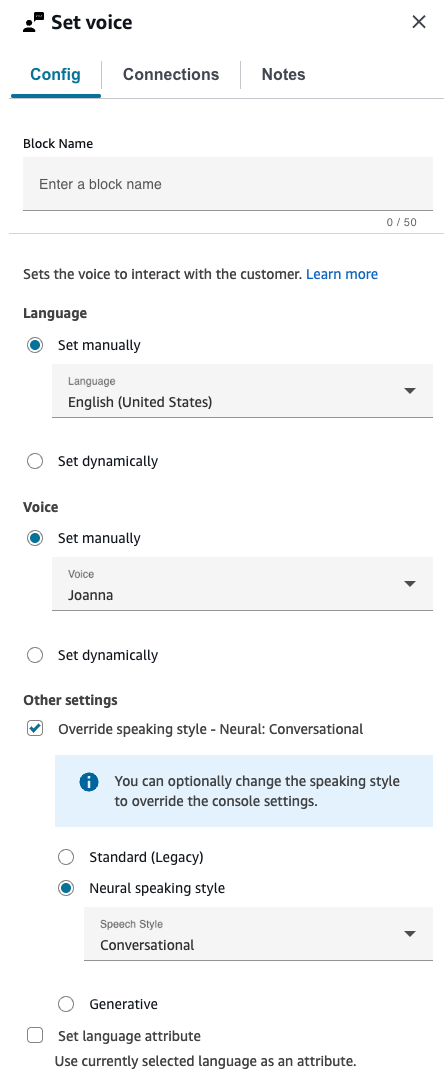
下图显示了设置语音数据块的属性页面。它配置为英语,语音为 Joanna,语音风格为对话式。
提示
对于仅支持神经说话风格但不支持标准语音的声音,系统会自动选择覆盖说话风格。您无法选择将其清除。
还可以动态设置语言、语音、引擎和风格。修改数据块时必须遵循一些配置:
-
如果语言是动态选择的,则还必须动态选择语音。
-
如果动态选择语音并覆盖讲话方式,则必须动态选择引擎和风格。
-
如果语音或引擎无效,或者所选语音不支持所选引擎,则将采用错误分支。
注意
-
只有在选择设置语言属性时,才会将语言代码传递到流操作中。因此,无效的语言代码将不会采用此数据块中的错误分支,但在与 Lex V2 机器人结合使用时,它们可能会导致错误的行为。
-
如果在 Error 分支之后添加了播放提示,则用于该分支的语音将默认为 Joanna/standard。
-
如果定义的语音不支持定义的讲话方式,则将使用无讲话方式。
-
配置
有关有效语言代码、语音和支持的引擎的列表,请参阅《Amazon Polly 开发人员指南》中的可用语音。
注意
Connect Customer 支持标准、神经和生成引擎,因此您可以将标准、神经或生成引擎作为值传递到引擎参数中。
要设置语言属性,请将特定的语言代码传递到该参数中(例如 en-US 或 ar-AE)。对于语音,只需传递语音的名称(例如 Joanna 或 Hala)。
Connect Customer 还支持说话风格,可以定义为 “无”、“会话” 或 “新闻播客”。“新闻播音员”和“对话”方式都适用于神经引擎中的以下语音:
-
Matthew(en-US)
-
Joanna(en-US)
-
Lupe(es-US)
-
Amy(en-GB)
注意
如果您未指定引擎,则默认情况下使用标准引擎。但是,有些语音,例如 Ruth(en-US),不支持标准引擎。对于这些语音,您必须指定支持的引擎。否则,操作就会失败,因为 Ruth 不支持标准引擎。
下表包含一些有关配置及其结果的示例:
| 语言代码 | 语音 | Engine | 讲话方式 | 结果 + 推理 |
|---|---|---|---|---|
| en-US | Ruth | N/D | N/D | 错误分支:未指定引擎,因此默认为标准。Ruth 不支持标准引擎,这会导致使用错误分支。 |
| en-US | Ruth | 神经 | none | 成功分支:Ruth 支持神经引擎 |
| en-US | Ruth | 神经 | 对话 | 成功分支:尽管 Ruth 不支持对话讲话方式,但数据块不会采用错误分支。相反,当合成语音时,它只使用“无”讲话方式。 |
| ar-AE | Ruth | 神经 | none | 成功分支:此数据块不对语言代码进行验证。只有语音用于合成讲话。但是,与 Lex V2 机器人结合使用时,语言代码不正确可能会导致错误的行为。 |
与 Connect 客户一起使用 Amazon Lex V2 机器人
如果您使用的是 Amazon Lex V2 机器人,则您在 Connect Customer 中的语言属性必须与用于构建 Lex 机器人的语言模型相匹配。这与 Amazon Lex (Classic) 不同。
-
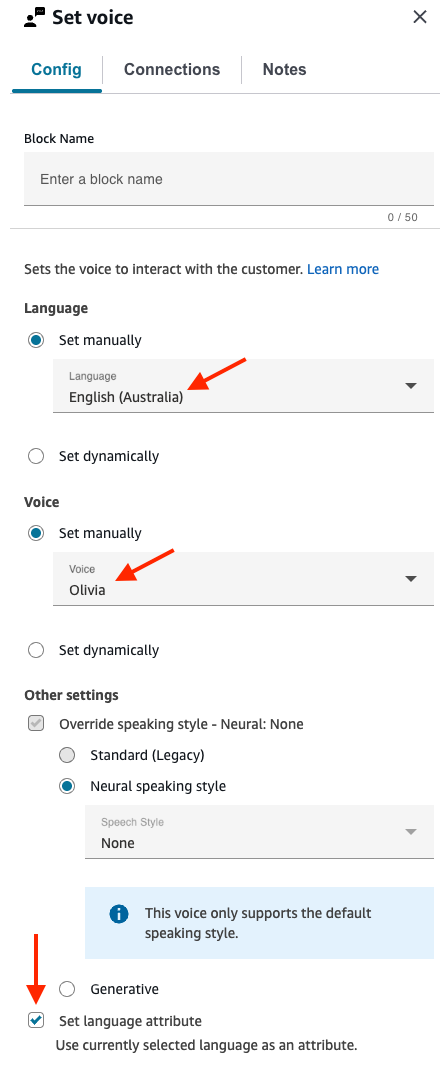
如果您使用不同的语言模型(例如 en_AU、fr_FR、es_ES 等)构建 Amazon Lex V2 自动程序,请在语音下选择与该语言对应的语音,然后务必选择设置语言属性,如下图所示。
-
如果您没有在 Amazon Lex V2 自动程序中使用 en-US 语音,也没有选择设置语言属性,则会导致获取客户输入数据块错误。
-
对于使用多种语言的自动程序(例如 en_AU 和 en_GB),请为其中一种语言选择设置语言属性,如下图所示。
配置提示
-
对于美式英语 (en-US) 的 Joanna 和 Matthew 神经语音,您还可以指定新闻播音员说话风格。
已配置的数据块
下图显示了该数据块已配置好的样子。它有以下分支:成功和错误。
场景
有关使用此数据块的场景,请参阅以下主题:
