本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
在 Connect 客户分析数据湖中调度数据
本主题详细介绍了 Connect Customer 数据湖调度表中的内容。该表列出了内容的列、类型和说明。
有两种方法可以访问分析数据湖和配置要共享的数据:
如果您无法使用选项 1 访问调度表,请尝试使用选项 2。
内容
人员调度配置文件
表名称:staff_scheduling_profile
复合主键:{instance_id, agent_arn,
staff_scheduling_profile_version}
| 列 | Type | 说明 |
|---|---|---|
| instance_id | 字符串 | Connect Customer 实例的 ID。 |
| agent_arn | 字符串 | 座席的 ARN。 |
| staff_scheduling_profile_version | bigint | 人员调度配置文件版本。 |
| instance_arn | 字符串 | Connect 客户实例的 ARN。 |
| staffing_group_arn | 字符串 | 分配给座席的人员配置组的 ARN。 |
| start_timestamp | Timestamp | StartTimestamp 适用于在《工作人员细则》中配置的代理(计划仅在此时间戳之后生成)。 |
| end_timestamp | Timestamp | EndTimestamp 适用于在《工作人员细则》中配置的代理(时间表不会超过此时间戳生成)。 |
| shift_profile_arn | 字符串 | 工作人员细则中分配给代理的轮班配置文件的 ARN。与移位旋转模式互斥。 |
| shift_rotation_pattern_arn | 字符串 | 工作人员细则中分配给代理的轮班轮换模式的 ARN。与 Shift Profile 互斥。 |
| shift_rotation_step_step_i | bigint | 代理在分配的 Shift 轮换模式中开始的步骤 ID。 |
| timezone | 字符串 | 为座席配置的时区。 |
| is_deleted | 布尔值 | 如果座席已删除,则设置为 True。否则设置为 False。 |
| last_updated_timestamp | Timestamp | /删除员工日程安排资料的时间戳。 created/updated |
| data_lake_last_processed_timestamp | Timestamp | 显示数据湖最后一次接触记录的时间戳。这可能包括转换和回填。此字段不能用于可靠地确定数据的新鲜度。 |
轮班活动
表名称:shift_activities
复合主键:{instance_id, shift_activity_arn,
shift_activity_version}
| 列 | Type | 说明 |
|---|---|---|
| instance_id | 字符串 | Connect Customer 实例的 ID。 |
| shift_activity_arn | 字符串 | 班次活动的 ARN。 |
| shift_activity_version | bigint | 班次活动版本。 |
| instance_arn | 字符串 | Connect 客户实例的 ARN。 |
| shift_activity_name | 字符串 | 班次活动名称。 |
| type | 字符串 | 班次活动类型。可能的值包括:PRODUCTIVE、NON_PRODUCTIVE 以及 LEAVE。 |
| sub_type | 字符串 | 班次活动的子类型。这仅适用于 NON_PRODUCTIVE 类型的活动。可能的值包括:BREAK_OR_MEAL 和 NONE。 |
| is_adherence_tracked | 布尔值 | 如果班次活动配置了准点率跟踪,则设置为 True。否则设置为 False。 |
| is_paid | 布尔值 | 如果班次活动配置为已支付,则设置为 True。否则设置为 False。 |
| is_deleted | 布尔值 | 如果班次活动被删除,则设置为 True。否则设置为 False。 |
| last_updated_timestamp | Timestamp | /deleted 移位活动时 created/updated的时间戳。 |
| data_lake_last_processed_timestamp | Timestamp | 显示数据湖最后一次接触记录的时间戳。这可能包括转换和回填。此字段不能用于可靠地确定数据的新鲜度。 |
轮班配置文件
表名称:shift_profiles
复合主键:{instance_id, shift_profile_arn,
shift_profile_version}
| 列 | Type | 说明 |
|---|---|---|
| instance_id | 字符串 | Connect Customer 实例的 ID。 |
| shift_profile_arn | 字符串 | 班次配置文件的 ARN。 |
| shift_profile_version | bigint | 班次配置文件版本。 |
| instance_arn | 字符串 | Connect 客户实例的 ARN。 |
| shift_profile_name | 字符串 | 班次配置文件名称。 |
| is_deleted | 布尔值 | 如果班次配置文件被删除,则设置为 True。否则设置为 False。 |
| last_updated_timestamp | Timestamp | /删除轮班配置文件时 created/updated的时间戳。 |
| data_lake_last_processed_timestamp | Timestamp | 显示数据湖最后一次接触记录的时间戳。这可能包括转换和回填。此字段不能用于可靠地确定数据的新鲜度。 |
人员配置组
表名称:staffing_groups
复合主键:{instance_id, staffing_group_arn,
staffing_group_version}
| 列 | Type | 说明 |
|---|---|---|
| instance_id | 字符串 | Connect Customer 实例的 ID。 |
| staffing_group_arn | 字符串 | 人员配置组的 ARN。 |
| staffing_group_version | bigint | 人员配置组版本。 |
| instance_arn | 字符串 | Connect 客户实例的 ARN。 |
| staffing_group_name | 字符串 | 人员配置组名称。 |
| is_deleted | 布尔值 | 如果已删除人员配置组,则设置为 True。否则设置为 False。 |
| last_updated_timestamp | Timestamp | /删除人员配置组的时间戳。 created/updated |
| data_lake_last_processed_timestamp | Timestamp | 显示数据湖最后一次接触记录的时间戳。这可能包括转换和回填。此字段不能用于可靠地确定数据的新鲜度。 |
人员配置组 - 预测组
表名称:staffing_group_forecast_groups
复合主键:{instance_id, staffing_group_arn,
staffing_group_version, forecast_group_arn}
该表应结合 staffing_group_arn 和 staffing_group_version 的 staffing_groups 表来查询。
| 列 | Type | 说明 |
|---|---|---|
| instance_id | 字符串 | Connect Customer 实例的 ID。 |
| staffing_group_arn | 字符串 | 人员配置组的 ARN。 |
| staffing_group_version | bigint | 人员配置组版本。 |
| forecast_group_arn | 字符串 | 与人员配置组关联的预测组的 ARN。 |
| instance_arn | 字符串 | Connect 客户实例的 ARN。 |
| is_deleted | 布尔值 | StaffingGroup-ForecastGroup关联有效时设置为 False。 |
| last_updated_timestamp | Timestamp | 人员配备小组所在的时间戳。 created/updated |
| data_lake_last_processed_timestamp | Timestamp | 显示数据湖最后一次接触记录的时间戳。这可能包括转换和回填。此字段不能用于可靠地确定数据的新鲜度。 |
人员配置组 - 主管
表名称:staffing_group_supervisors
复合主键:{instance_id, staffing_group_arn,
staffing_group_version, supervisor_arn}
该表应结合 staffing_group_arn 和 staffing_group_version 的 staffing_groups 表来查询。
| 列 | Type | 说明 |
|---|---|---|
| instance_id | 字符串 | Connect Customer 实例的 ID。 |
| staffing_group_arn | 字符串 | 人员配置组的 ARN。 |
| staffing_group_version | bigint | 人员配置组版本。 |
| supervisor_arn | 字符串 | 与人员配置组关联的主管的座席 ARN。 |
| instance_arn | 字符串 | Connect 客户实例的 ARN。 |
| is_deleted | 布尔值 | StaffingGroup-ForecastGroup关联有效时设置为 False。 |
| last_updated_timestamp | Timestamp | 人员配备小组所在的时间戳。 created/updated |
| data_lake_last_processed_timestamp | Timestamp | 显示数据湖最后一次接触记录的时间戳。这可能包括转换和回填。此字段不能用于可靠地确定数据的新鲜度。 |
员工班次
表名称:staff_shifts
复合主键:{instance_id, shift_id, shift_version}
| 列 | Type | 说明 |
|---|---|---|
| instance_id | 字符串 | Connect Customer 实例的 ID。 |
| shift_id | 字符串 | 班次的 ID。 |
| shift_version | bigint | 班次版本。 |
| instance_arn | 字符串 | Connect 客户实例的 ARN。 |
| agent_arn | 字符串 | 座席的 ARN。 |
| shift_start_timestamp | Timestamp | 班次开始时的时间戳。 |
| shift_end_timestamp | Timestamp | 班次结束时的时间戳。 |
| created_timestamp | Timestamp | 创建班次时的时间戳。 |
| is_deleted | 布尔值 | 如果班次被删除,则设置为 True。否则设置为 False。 |
| last_updated_timestamp | Timestamp | /删除 Shift 时 created/updated的时间戳。 |
| data_lake_last_processed_timestamp | Timestamp | 显示数据湖最后一次接触记录的时间戳。这可能包括转换和回填。此字段不能用于可靠地确定数据的新鲜度。 |
员工班次活动
表名称:staff_shift_activities
复合主键:{instance_id, shift_id, shift_version,
activity_id}
该表应结合 shift_id 和 shift_version 的 staff_shifts 表来查询。
| 列 | Type | 说明 |
|---|---|---|
| instance_id | 字符串 | Connect Customer 实例的 ID。 |
| shift_id | 字符串 | 班次的 ID。 |
| shift_version | bigint | 班次版本。 |
| activity_id | 字符串 | 活动的 ID。 |
| instance_arn | 字符串 | Connect 客户实例的 ARN。 |
| activity_start_timestamp | Timestamp | 活动开始时的时间戳。 |
| activity_end_timestamp | Timestamp | 活动结束时的时间戳。 |
| shift_activity_arn | 字符串 | 班次活动的 ARN。如果 shift_activity_arn 为 null,则表示“工作”活动。 |
| activity_status | 字符串 | 活动状态。如果活动与休假重叠,则设置为“INACTIVE”。 |
| is_overtime | 布尔值 | 如果活动属于加班,则设置为 True。否则设置为 False。 |
| is_deleted | 布尔值 | 当班次活动有效时,设置为 False。 |
| last_updated_timestamp | Timestamp | 移位时的时间戳。 created/updated |
| data_lake_last_processed_timestamp | Timestamp | 显示数据湖最后一次接触记录的时间戳。这可能包括转换和回填。此字段不能用于可靠地确定数据的新鲜度。 |
员工休假余额变动
表名称:staff_timeoff_balance_changes
复合主键:{instance_id, agent_arn, shift_activity_arn,
timeoff_balance_version}
| 列 | Type | 说明 |
|---|---|---|
| instance_arn | 字符串 | Connect 客户实例的 ARN。 |
| instance_id | 字符串 | Connect Customer 实例的 ID。 |
| account_id | 字符串 | AWS 账户的 ID。 |
| agent_arn | 字符串 | 座席的 ARN。 |
| shift_activity_arn | 字符串 | 分配此余额的班次活动的 ARN。 |
| timeoff_balance_version | bigint | 休假余额版本,表示变动顺序的递增数字。 |
| balance_update_source | 字符串 | 余额更新的来源。可能的值包括 TIME_OFF_BALANCE_UPLOAD、CONNECT_TIME_OFF_REQUEST、SCHEDULE_PUBLISH、CSV_TIME_OFF_BALANCE_DELETION、TIME_OFF_BALANCE_BACKFILL、SYSTEM_UPDATE |
| timeoff_id | 字符串 | 导致此余额变动的休假 ID(如果存在)。 |
| last_updated_by | 字符串 | 导致此余额变动的座席 ARN(如果存在)。 |
| balance_change_in_hours | double | 根据此变动更新的休假余额时间(以小时为单位)。如果该值为正,则此变动值将记入休假余额。如果该值为负,则从休假余额中扣除此变动值。对于任何余额上传和删除事件,均未定义此值。 |
| remaining_balance_in_hours | double | 发生此变动事件之后的剩余休假余额时长。对于任何余额删除事件,均未定义此值。 |
| last_created_timestamp | Timestamp | 创建休假余额变动记录时的时间戳。 |
| data_lake_last_processed_timestamp | Timestamp | 显示数据湖最后一次接触记录的时间戳。这可能包括转换和回填。此字段不能用于可靠地确定数据的新鲜度。 |
员工休假
表名称:staff_timeoffs
复合主键:{instance_id, timeoff_id, agent_arn,
timeoff_version}
| 列 | Type | 说明 |
|---|---|---|
| instance_id | 字符串 | Connect Customer 实例的 ID。 |
| timeoff_id | 字符串 | 休假的 ID。 |
| agent_arn | 字符串 | 座席的 ARN。 |
| timeoff_version | bigint | 休假版本。 |
| instance_arn | 字符串 | Connect 客户实例的 ARN。 |
| timeoff_type | 字符串 | 休假类型。可能的值包括:TIME_OFF 和 VOLUNTARY_TIME_OFF。 |
| timeoff_start_timestamp | Timestamp | 休假开始时的时间戳。 |
| timeoff_end_timestamp | Timestamp | 休息时间结束时的时间戳。 |
| timeoff_status | 字符串 | 休假状态。可能的值包括:PENDING_CREATE、PENDING_UPDATE、PENDING_CANCEL、PENDING_ACCEPT、PENDING_APPROVE、PENDING_DECLINE、APPROVED、ACCEPTED、REJECTED、CANCELLED、WAITING_ACCEPT 以及 WAITING_APPROVE。WAITING 状态表示休假正在等待用户操作。PENDING 状态表示休假正在等待系统处理用户操作。 |
| shift_activity_arn | 字符串 | 用于休假的班次活动的 ARN。 |
| effective_timeoff_hours | double | 总的有效休假时间。有效休假时间是根据休假扣除逻辑计算的。此设置仅适用于 TIME_OFF 类型。 |
| last_updated_timestamp | Timestamp | /deleted 关闭时间的时间戳。 created/updated |
| data_lake_last_processed_timestamp | Timestamp | 显示数据湖最后一次接触记录的时间戳。这可能包括转换和回填。此字段不能用于可靠地确定数据的新鲜度。 |
员工休假间隔
表名称:staff_timeoff_intervals
复合主键:{instance_id, timeoff_id, timeoff_version,
interval_id}
该表应结合 timeoff_id 和 timeoff_version 的 staff_timeoffs 表来查询。
| 列 | Type | 说明 |
|---|---|---|
| instance_id | 字符串 | Connect Customer 实例的 ID。 |
| timeoff_id | 字符串 | 休假的 ID。 |
| timeoff_version | bigint | 休假版本。 |
| interval_id | 字符串 | 休假间隔的 ID。 |
| instance_arn | 字符串 | Connect 客户实例的 ARN。 |
| timeoff_interval_start_timestamp | Timestamp | 特定休假间隔开始时的时间戳。 |
| timeoff_interval_end_timestamp | Timestamp | 特定休假间隔结束时的时间戳。 |
| interval_effective_timeoff_hours | double | 此特定休假间隔的有效休假时间。有效休假时间是根据休假扣除逻辑计算的。 |
| last_updated_timestamp | Timestamp | /deleted 关闭时间的时间戳。 created/updated |
| data_lake_last_processed_timestamp | Timestamp | 显示数据湖最后一次接触记录的时间戳。这可能包括转换和回填。此字段不能用于可靠地确定数据的新鲜度。 |
员工需求组
表名:staff_demand_group
复合主键:{instance_id, agent_arn, demand_group_arn, staff_demand_group_version}
| 列 | Type | 说明 |
|---|---|---|
| instance_id | 字符串 | Connect Customer 实例的 ID。 |
| agent_arn | 字符串 | 座席的 ARN。 |
| demand_group_arn | 字符串 | 需求组的 ARN。 |
| 员工需求群组版本 | 长整型 | 此代理与需求组关联的版本 |
| priority | 字符串 | 该代理的需求组的优先级。可以是低、中或高 |
| instance_arn | 字符串 | Connect 客户实例的 ARN。 |
| is_overrid | 布尔值 | 如果这是代理与需求组的关联是代理级别的覆盖,则设置为 “true”。 |
| is_deleted | 布尔值 | 如果删除了代理与需求组的关联,则设置为 true。 |
| last_updated_timestamp | Timestamp | 代理与需求组关联的时间戳。 created/updated |
| data_lake_last_processed_timestamp | Timestamp | 显示数据湖最后一次接触记录的时间戳。这可能包括转换和回填。此字段不能用于可靠地确定数据的新鲜度。 |
人员配备组需求组
表名:staffing_group_demand_group
复合主键:{instance_id, staffing_group_arn, demand_group_arn,
staffing_group_demand_group_version}
| 列 | Type | 说明 |
|---|---|---|
| instance_id | 字符串 | Connect Customer 实例的 ID。 |
| staffing_group_arn | 字符串 | 人员配置组的 ARN。 |
| demand_group_arn | 字符串 | 需求组的 ARN。 |
| 员工群组_需求_群组_版本 | 长整型 | 此人员配备组与需求组关联的版本 |
| priority | 字符串 | 此人员配备组的需求组的优先级。可以是低、中或高 |
| instance_arn | 字符串 | Connect 客户实例的 ARN。 |
| is_deleted | 布尔值 | 如果删除了人员配备组与需求组的关联,则设置为 true。 |
| last_updated_timestamp | Timestamp | /deleted 将人员配备组与需求组关联的时间戳。 created/updated |
| data_lake_last_processed_timestamp | Timestamp | 显示数据湖最后一次接触记录的时间戳。这可能包括转换和回填。此字段不能用于可靠地确定数据的新鲜度。 |
员工轮班活动分配
表名:staff_shift_activity_allocations
复合主键:{instance_id, shift_id, shift_version, activity_id, demand_group_arn}
| 列 | Type | 说明 |
|---|---|---|
| instance_id | 字符串 | Connect Customer 实例的 ID。 |
| shift_id | 字符串 | 班次的 ID。 |
| shift_version | 长整型 | 班次版本。 |
| activity_id | 字符串 | 活动的 ID。 |
| demand_group_arn | 字符串 | 需求组的 ARN。 |
| foecast_group_arn | 字符串 | 预测组的 ARN。 |
| 分配百分比 | double | 活动分配给需求组的百分比。 |
| is_deleted | 布尔值 | 有效时设置为 False。 StaffingGroup-ForecastGroupassociation |
| last_updated_timestamp | Timestamp | 人员配备小组所在的时间戳。 created/updated |
| data_lake_last_processed_timestamp | Timestamp | 显示数据湖最后一次接触记录的时间戳。这可能包括转换和回填。此字段不能用于可靠地确定数据的新鲜度。 |
计划指标
表名称:schedule_metrics
复合主键:{instance_id, metric_id, interval_start_timestamp}
| 列 | Type | 说明 |
|---|---|---|
| instance_id | 字符串 | Amazon Connect 实例的 ARN。 |
| instance_arn | 字符串 | Amazon Connect 实例的 ID。 |
| metric_id | 字符串 | 指标值的唯一标识符 |
| aws_account_id | 字符串 | AWS 账户的 ID。 |
| entity_type | 字符串 | 表示该指标是针对预测组还是需求组。 |
| entity_arn | 字符串 | 预测组或需求组的 arn |
| 渠道 | 字符串 | 表示媒体频道,例如语音、聊天。如果该行包含的指标不是频道级别,则会将其填充为 “全部” |
| 间隔开始时间戳 | timestamp | 表示间隔开始的时间戳 |
| 必填代理人数 | 浮点数 | 表示预测的代理人数 |
| scheduled_agent_count | 浮点数 | 表示计划代理人数 |
| 预定占用率 | 浮点数 | 表示占用百分比 |
| 计划服务级别百分比 | 浮点数 | 表示计划服务级别百分比 |
| 服务级别秒 | integer | 表示服务级别(秒) |
| 答案的预定平均速度 | 浮点数 | 表示平均应答速度 |
| is_deleted | 布尔值 | 表示指标是否已删除 |
| last_updated_timestamp | timestamp | 创建指标记录的时间戳。 |
| data_lake_last_processed_timestamp | timestamp | 显示数据湖最后一次处理记录的时间戳。这可能包括转换和回填。此字段不能用于可靠地确定数据的新鲜度。 |
安排目标
表名称:schedule_goals
复合主键:{instance_id, goal_id}
| 列 | Type | 说明 |
|---|---|---|
| instance_id | 字符串 | Amazon Connect 实例的 ARN。 |
| instance_arn | 字符串 | Amazon Connect 实例的 ID。 |
| goal_id | 字符串 | 目标值的唯一标识符 |
| aws_account_id | 字符串 | AWS 账户的 ID。 |
| entity_type | 字符串 | 表示目标是针对预测组还是需求组。 |
| entity_arn | 字符串 | 预测组或需求组的 arn |
| 渠道 | 字符串 | 表示媒体频道,例如语音、聊天。 |
| 开始_日期_时间戳 | timestamp | 表示球门开始的时间戳 |
| 结束日期时间戳 | timestamp | 表示目标结束的时间戳 |
| 目标服务等级百分比 | 浮点数 | 表示目标服务水平百分比 |
| 目标服务等级秒 | integer | 表示服务级别(秒) |
| 答案的目标平均速度 | 浮点数 | 表示平均应答速度 |
| is_deleted | 布尔值 | 表示目标是否已删除 |
| last_updated_timestamp | timestamp | 创建进球记录的时间戳。 |
| data_lake_last_processed_timestamp | timestamp | 显示数据湖最后一次处理记录的时间戳。这可能包括转换和回填。此字段不能用于可靠地确定数据的新鲜度。 |
轮班轮换模式
表名称:shift_rotation_patterns
复合主键:{instance_id, shift_rotation_pattern_arn,
shift_rotation_pattern_version}
| 列 | Type | 说明 |
|---|---|---|
| instance_id | 字符串 | Connect Customer 实例的 ID。 |
| shift_rotation_pattern_arn | 字符串 | 移位旋转模式的 ARN。 |
| shift_rotation_pattern_版本 | bigint | 移位轮换模式版本。 |
| instance_arn | 字符串 | Connect 客户实例的 ARN。 |
| Shift_rotation_pattern_name | 字符串 | 移位旋转模式的名称。 |
| start_date | 字符串 | yyyy-mm-dd格式化的 Shift 旋转模式的开始日期。 |
| is_deleted | 布尔值 | 如果移位旋转模式被删除,则设置为 True。否则设置为 False。 |
| last_updated_by | 字符串 | created/updated/删除移位轮换模式的用户的 ARN。 |
| last_updated_timestamp | Timestamp | /deleted 移位旋转模式的时间戳。 created/updated |
| data_lake_last_processed_timestamp | Timestamp | 显示数据湖最后一次接触记录的时间戳。这可能包括转换和回填。此字段不能用于可靠地确定数据的新鲜度。 |
轮班轮换步骤
表名称:shift_rotation_steps
复合主键:{instance_id, shift_rotation_pattern_arn,
shift_rotation_pattern_version, step_id}
该表应结合 shift_rotation_pattern_arn 和 shift_rotation_pattern_version 的 shift_rotation_patterns 表来查询。
| 列 | Type | 说明 |
|---|---|---|
| instance_id | 字符串 | Connect Customer 实例的 ID。 |
| shift_rotation_pattern_arn | 字符串 | 移位旋转模式的 ARN。 |
| shift_rotation_pattern_版本 | bigint | 移位轮换模式版本。 |
| step_id | bigint | 移位旋转模式中步骤的 ID。步骤按顺序编号(1、2、3、... 最多 52)。 |
| instance_arn | 字符串 | Connect 客户实例的 ARN。 |
| shift_profile_arn | 字符串 | 与轮换步骤关联的班次配置文件的 ARN。 |
| duration | bigint | 轮换步骤的持续时间(以周为单位)。 |
| is_deleted | 布尔值 | 当移位旋转步骤有效时,设置为 False。 |
| last_updated_by | 字符串 | 使用移位轮换模式的用户 created/updated 的 ARN。 |
| last_updated_timestamp | Timestamp | 移位旋转模式的时间戳。 created/updated |
| data_lake_last_processed_timestamp | Timestamp | 显示数据湖最后一次接触记录的时间戳。这可能包括转换和回填。此字段不能用于可靠地确定数据的新鲜度。 |
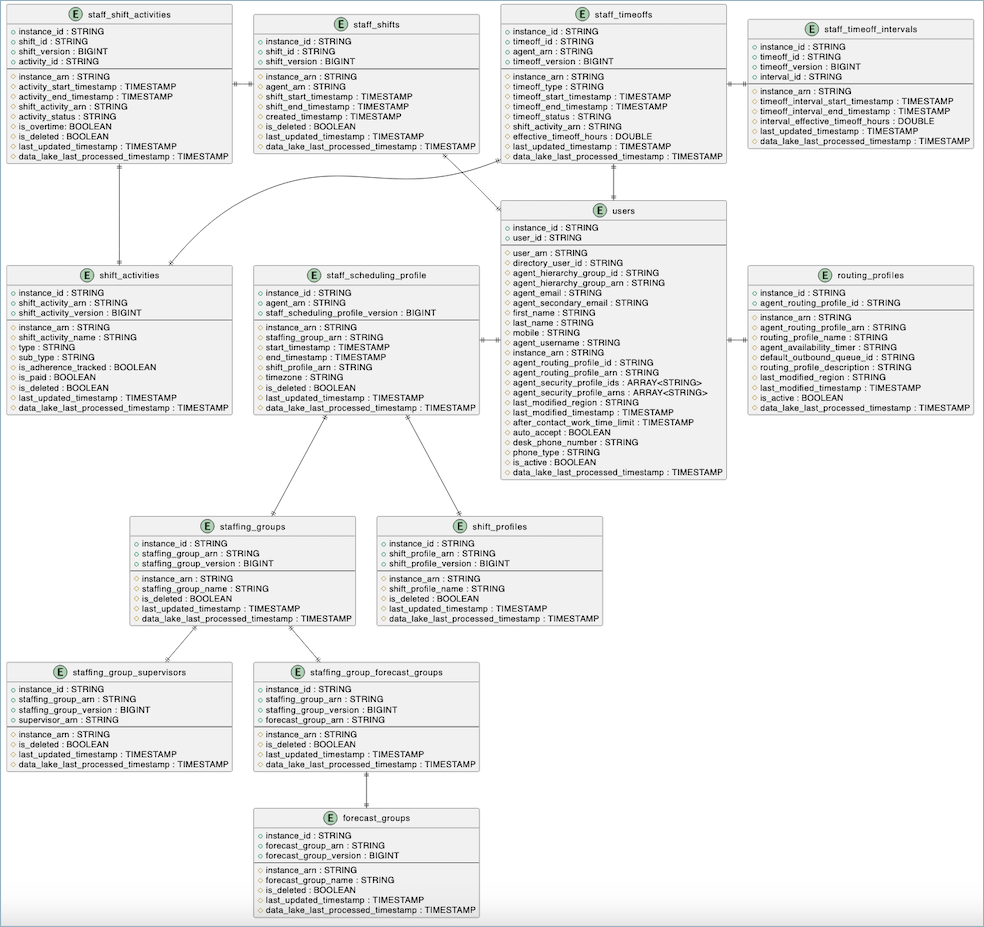
数据架构
以下是实体关系图,显示了 Connect Customer 数据湖中计划表之间的结构和关系。
每个表都显示了其主键和属性及其数据类型。该图展示了这些表如何通过外键关系相互关联,从而全面展示了调度数据模型。
查询示例
1. 查询以获取处理特定预测组的座席的所有预排班次活动
SELECT * FROM agent_scheduled_shift_activities_view
where forecast_group_name = 'AnyDepartmentForecastGroup'
要创建上述 agent_scheduled_shift_activities_view,请完成以下步骤。
步骤 1:创建视图以获取主管姓名
CREATE OR REPLACE VIEW "latest_supervisor_names_view" AS SELECT staffing_group_arn , array_agg(supervisor_name ORDER BY supervisor_name ASC) supervisor_names FROM ( SELECT s.staffing_group_arn , CONCAT(u.first_name, ' ', u.last_name) supervisor_name FROM (( SELECT staffing_group_arn , supervisor_arn FROM ( SELECT * , RANK() OVER (PARTITION BY staffing_group_arn ORDER BY staffing_group_version DESC) recency FROM staffing_group_supervisors WHERE (instance_id = 'YourAmazonConnectInstanceId') ) t WHERE (recency = 1) ) s INNER JOIN USERS u ON (s.supervisor_arn = u.user_arn)) ) GROUP BY staffing_group_arn
步骤 2:创建视图以获取与座席关联的人员配置组和预测组
CREATE OR REPLACE VIEW "latest_agent_staffing_group_forecast_group_view" AS WITH latest_staff_scheduling_profile AS ( SELECT agent_arn , staffing_group_arn , last_updated_timestamp FROM ( SELECT * , RANK() OVER (PARTITION BY agent_arn ORDER BY staff_scheduling_profile_version DESC) recency FROM staff_scheduling_profile WHERE ((instance_id = 'YourAmazonConnectInstanceId') AND (is_deleted = false)) ) t WHERE (recency = 1) ) , latest_staffing_groups AS ( SELECT staffing_group_name , staffing_group_arn FROM ( SELECT * , RANK() OVER (PARTITION BY staffing_group_arn ORDER BY staffing_group_version DESC) recency FROM staffing_groups WHERE (instance_id = 'YourAmazonConnectInstanceId') ) t WHERE (recency = 1) ) , latest_forecast_groups AS ( SELECT forecast_group_arn , forecast_group_name FROM ( SELECT * , RANK() OVER (PARTITION BY forecast_group_arn ORDER BY forecast_group_version DESC) recency FROM forecast_groups WHERE (instance_id = 'YourAmazonConnectInstanceId') ) t WHERE (recency = 1) ) , latest_staffing_group_forecast_groups AS ( SELECT staffing_group_arn , forecast_group_arn FROM ( SELECT * , RANK() OVER (PARTITION BY staffing_group_arn ORDER BY staffing_group_version DESC) recency FROM staffing_group_forecast_groups WHERE (instance_id = 'YourAmazonConnectInstanceId') ) t WHERE (recency = 1) ) SELECT ssp.agent_arn , U.agent_username AS username , U.agent_routing_profile_id AS routing_profile_id , CONCAT(u.first_name, ' ', u.last_name) agent_name , fg.forecast_group_arn , fg.forecast_group_name , sg.staffing_group_arn , sg.staffing_group_name FROM latest_staff_scheduling_profile ssp INNER JOIN latest_staffing_groups sg ON ssp.staffing_group_arn = sg.staffing_group_arn INNER JOIN latest_staffing_group_forecast_groups sgfg ON ssp.staffing_group_arn = sgfg.staffing_group_arn INNER JOIN latest_forecast_groups fg ON fg.forecast_group_arn = sgfg.forecast_group_arn INNER JOIN USERS u ON ssp.agent_arn = u.user_arn
第 3 步:获取最新班次活动
CREATE OR REPLACE VIEW "latest_shift_activities_view" AS SELECT shift_activity_arn , shift_activity_name , shift_activity_version , type , sub_type , is_adherence_tracked , is_paid , last_updated_timestamp FROM ( SELECT * , RANK() OVER (PARTITION BY shift_activity_arn ORDER BY shift_activity_version DESC) recency FROM shift_activities WHERE (instance_id = 'YourAmazonConnectInstanceId') ) t WHERE (recency = 1)
步骤 4:创建视图以获取座席预排班次活动
CREATE OR REPLACE VIEW "agent_scheduled_shift_activities_view" AS WITH latest_staff_shifts AS ( SELECT agent_arn , shift_id , shift_version , shift_start_timestamp , shift_end_timestamp , created_timestamp , last_updated_timestamp , data_lake_last_processed_timestamp , recency FROM ( SELECT RANK() OVER (PARTITION BY shift_id ORDER BY shift_version DESC) recency , * FROM staff_shifts sa WHERE (instance_id = 'YourAmazonConnectInstanceId') ) t WHERE ((recency = 1) AND (is_deleted = false)) ) SELECT asgfg.forecast_group_name , array_join(sn.supervisor_names, ',') supervisor_names , s.agent_arn , u.first_name , u.last_name , asgfg.staffing_group_name , ssa.activity_id , (CASE WHEN (ssa.shift_activity_arn IS NULL) THEN COALESCE(sa.shift_activity_name, 'Work') ELSE sa.shift_activity_name END) shift_activity_name , s.shift_start_timestamp , s.shift_end_timestamp , (CASE WHEN (ssa.shift_activity_arn IS NULL) THEN COALESCE(sa.type, 'PRODUCTIVE') ELSE sa.type END) type , (CASE WHEN (ssa.shift_activity_arn IS NULL) THEN COALESCE(sa.is_paid, true) ELSE sa.is_paid END) is_paid , ssa.activity_start_timestamp , ssa.activity_end_timestamp , ssa.last_updated_timestamp , ssa.data_lake_last_processed_timestamp , u.agent_username as username , u.agent_routing_profile_id as routing_profile_id FROM staff_shift_activities ssa INNER JOIN latest_staff_shifts s ON s.shift_id = ssa.shift_id AND s.shift_version = ssa.shift_version INNER JOIN USERS u ON s.agent_arn = u.user_arn INNER JOIN latest_agent_staffing_group_forecast_group_view asgfg ON s.agent_arn = asgfg.agent_arn LEFT JOIN latest_shift_activities_view sa ON sa.shift_activity_arn = ssa.shift_activity_arn INNER JOIN latest_supervisor_names_view sn ON sn.staffing_group_arn = asgfg.staffing_group_arn WHERE (ssa.is_deleted = false) AND (COALESCE(ssa.activity_status, ' ') <> 'INACTIVE') AND (ssa.instance_id = 'YourAmazonConnectInstanceId')
2. 查询以获取特定预测组中座席的所有休假请求
SELECT * FROM agent_timeoff_report_view where forecast_group_name =
'AnyDepartmentForecastGroup'
使用以下查询来创建上述 agent_timeoff_report_view。
CREATE OR REPLACE VIEW "agent_timeoff_report_view" AS WITH latest_staff_timeoffs AS ( SELECT t1.*, CAST((t1.effective_timeoff_hours * 60) AS INT) total_effective_timeoff_minutes FROM ( SELECT RANK() OVER ( PARTITION BY timeoff_id ORDER BY timeoff_version DESC ) recency, agent_arn, timeoff_id, shift_activity_arn, timeoff_status, timeoff_version, effective_timeoff_hours, timeoff_start_timestamp, timeoff_end_timestamp, last_updated_timestamp, data_lake_last_processed_timestamp FROM staff_timeoffs WHERE ( instance_id = 'YourAmazonConnectInstanceId' ) ) t1 WHERE (recency = 1) ) SELECT asgfg.forecast_group_name, to.agent_arn, asgfg.agent_name, asgfg.staffing_group_name, asgfg.username, sa.shift_activity_name, to.timeoff_start_timestamp, to.timeoff_end_timestamp, to.timeoff_status, array_join(sn.supervisor_names, ',') AS supervisor_names, sa.is_paid, to.last_updated_timestamp, to.data_lake_last_processed_timestamp, u.agent_routing_profile_id AS routing_profile_id, to.timeoff_id, to.shift_activity_arn, to.total_effective_timeoff_minutes FROM latest_staff_timeoffs to INNER JOIN latest_agent_staffing_group_forecast_group_view asgfg ON asgfg.agent_arn = to.agent_arn INNER JOIN latest_shift_activities_view sa ON sa.shift_activity_arn = to.shift_activity_arn INNER JOIN latest_supervisor_names_view sn ON sn.staffing_group_arn = asgfg.staffing_group_arn INNER JOIN users u ON u.user_arn = to.agent_arn
