As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Configurando funções e usuários na Amazon OpenSearch Ingestion
O Amazon OpenSearch Ingestion usa uma variedade de modelos de permissões e funções do IAM para permitir que os aplicativos de origem gravem em pipelines e para permitir que os pipelines gravem em sumidouros. Antes de começar a ingerir dados, você precisa criar um ou mais perfis do IAM com permissões específicas com base no seu caso de uso.
No mínimo, os seguintes perfis são necessários para configurar um pipeline bem-sucedido.
| Name (Nome) | Description |
|---|---|
| Perfis do pipeline |
O perfil de pipeline fornece as permissões necessárias para que um pipeline leia na origem e escreva no domínio ou no destino da coleção. Você pode criar manualmente a função do pipeline ou fazer com que o OpenSearch Inestion a crie para você. |
| Perfil de ingestão |
O perfil de ingestão contém a permissão |
A imagem a seguir demonstra uma configuração típica de pipeline, em que uma fonte de dados, como Amazon S3 ou Fluent Bit, está gravando em um pipeline em uma conta diferente. Nesse caso, o cliente precisa assumir o perfil de ingestão para acessar o pipeline. Para obter mais informações, consulte Ingestão entre contas.
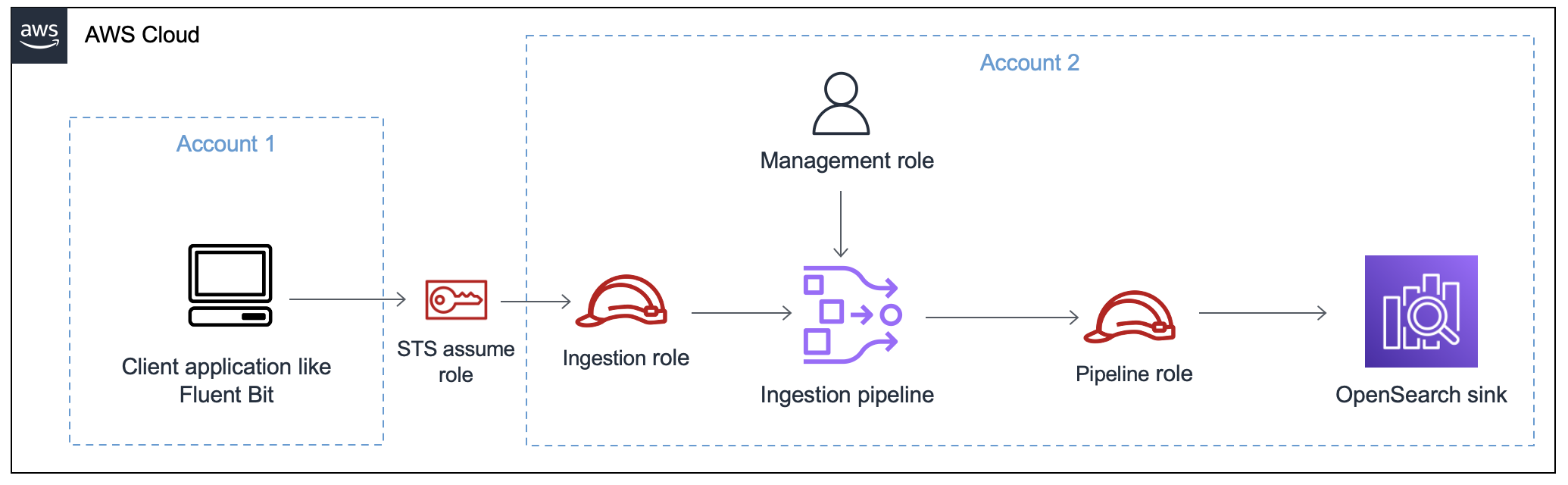
Para obter um guia de configuração simples, consulte Tutorial: Ingestão de dados em um domínio usando o Amazon OpenSearch Ingestion.
Tópicos
Perfis do pipeline
Um pipeline precisa de certas permissões ler na origem e gravar no coletor. Essas permissões dependem do aplicativo cliente ou do aplicativo AWS service (Serviço da AWS) que está gravando no pipeline e se o coletor é um domínio de OpenSearch serviço, uma coleção OpenSearch sem servidor ou o Amazon S3. Além disso, um pipeline pode precisar de permissões para fisicamente extrair por pull os dados da aplicação de origem (se a origem for um plug-in baseado em pull) e permissões para gravar em uma fila de mensagens não entregues do S3, se habilitada.
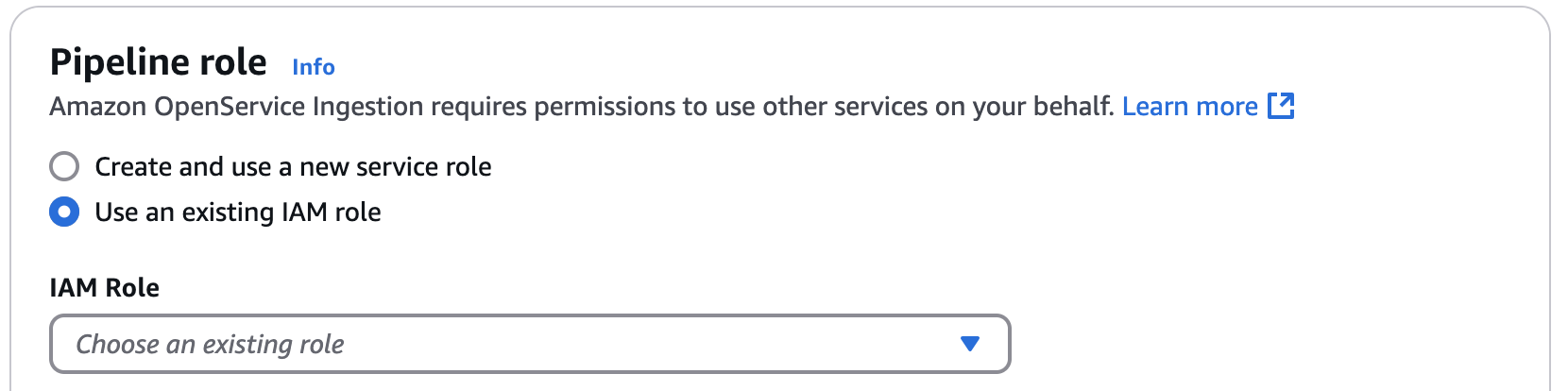
Ao criar um pipeline, você tem a opção de especificar uma função existente do IAM que você criou manualmente ou fazer com que o OpenSearch Ingestion crie automaticamente a função do pipeline com base na fonte e no coletor que você selecionou. A imagem a seguir mostra como especificar o perfil do pipeline no Console de gerenciamento da AWS.
Automatizar a criação de perfil de pipeline
Você pode escolher que o OpenSearch Inestion crie a função de pipeline para você. Ele identifica automaticamente quais permissões o perfil requer com base na origem e nos coletores configurados. Ele cria um perfil do IAM com o prefixo OpenSearchIngestion- e com o sufixo que você insere. Por exemplo, se você inserir PipelineRole como sufixo, o OpenSearch Ingestion cria uma função chamada. OpenSearchIngestion-PipelineRole
A criação automática do perfil de pipeline simplifica o processo de configuração e reduz a probabilidade de erros de configuração. Automatizando a criação de perfis, você pode evitar a atribuição manual de permissões, garantindo que as políticas corretas sejam aplicadas sem correr o risco de configurações de segurança incorretas. Isso também economiza tempo e melhora a conformidade de segurança aplicando as práticas recomendadas e, ao mesmo tempo, garantindo a consistência entre várias implantações do pipeline.
Você só pode fazer com que o OpenSearch Ingestion crie automaticamente a função do pipeline no Console de gerenciamento da AWS. Se você estiver usando a AWS CLI API de OpenSearch ingestão ou uma das SDKs, deverá especificar uma função de pipeline criada manualmente.
Para que o OpenSearch Inestion crie a função para você, selecione Criar e usar uma nova função de serviço.
Importante
Você ainda precisa modificar manualmente a política de acesso ao domínio ou à coleção para conceder acesso ao perfil do pipeline. Para domínios que usam um controle de acesso refinado, você também deve mapear o perfil do pipeline para um perfil de backend. Você pode realizar essas etapas antes ou depois de criar o pipeline.
Para obter instruções detalhadas, consulte os seguintes tópicos:
Criar o perfil de pipeline manualmente
Talvez você prefira criar manualmente o perfil do pipeline se precisar de mais controle sobre as permissões para atender aos requisitos específicos de segurança ou conformidade. A criação manual permite que você personalize as perfis de acordo com a infraestrutura existente ou com as estratégias de gerenciamento de acesso. Você também pode escolher a configuração manual para integrar a função a outra Serviços da AWS ou garantir que ela esteja alinhada às suas necessidades operacionais exclusivas.
Para escolher um perfil de pipeline criado manualmente, selecione Usar um perfil do IAM existente e escolha um perfil existente. O perfil deve ter todas as permissões necessárias para receber dados da origem selecionada e gravar no coletor selecionado. As seções a seguir descrevem como criar manualmente um perfil de pipeline.
Tópicos
Permissões para ler uma origem
Um pipeline OpenSearch de ingestão precisa de permissão para ler e receber dados da fonte especificada. Por exemplo, para uma origem do Amazon DynamoDB, ele precisa de permissões como dynamodb:DescribeTable e dynamodb:DescribeStream. Para exemplos de políticas de acesso à função de pipeline para fontes comuns, como Amazon S3, Fluent Bit e OpenTelemetry Collector, consulte. Integração dos pipelines OpenSearch de ingestão da Amazon com outros serviços e aplicativos
Permissões para gravar em um coletor de domínios
Um pipeline OpenSearch de ingestão precisa de permissão para gravar em um domínio OpenSearch de serviço configurado como coletor. Essas permissões incluem a capacidade de descrever o domínio e enviar solicitações HTTP para ele. Essas permissões são as mesmas para domínios públicos e domínios de VPC. Para obter instruções para criar um perfil de pipeline e especificá-lo na política de acesso ao domínio, consulte Permitir que pipelines acessem domínios.
Permissões para gravar em um coletor de coleções
Um pipeline OpenSearch de ingestão precisa de permissão para gravar em uma coleção OpenSearch Serverless configurada como coletor. Essas permissões incluem a capacidade de descrever a coleção e enviar solicitações HTTP para ela.
Primeiro, certifique-se de que sua política de acesso ao perfil do pipeline conceda as permissões necessárias. Em seguida, inclua esse perfil em uma política de acesso a dados e forneça permissões para criar índices, atualizar índices, descrever índices e escrever documentos na coleção. Para obter instruções sobre como concluir cada uma dessas etapas, consulte Como permitir que os pipelines acessem as coleções.
Permissões para gravar no Amazon S3 ou em uma fila de mensagens não entregues
Se você especificar o Amazon S3 como destino do coletor do pipeline ou se habilitar uma fila de mensagens não entregues
Anexe uma política de permissões separada ao perfil do pipeline que fornece acesso à DLQ. No mínimo, o perfil deve ter permissão para a ação S3:PutObject no recurso de bucket:
Perfil de ingestão
A função de ingestão é uma função do IAM que permite que serviços externos interajam com segurança e enviem dados para um OpenSearch pipeline de ingestão. Para origens baseadas em push, como o Amazon Security Lake, esse perfil deve conceder permissões para enviar dados ao pipeline por push, incluindo osis:Ingest. Para fontes baseadas em pull, como o Amazon S3, a função deve OpenSearch permitir que a Ingestion a assuma e acesse os dados com as permissões necessárias.
Tópicos
Perfil de ingestão para origens baseadas em push
Para origens baseadas em push, os dados são enviados por push de outro serviço, como o Amazon Security Lake ou o Amazon DynamoDB, para o pipeline de ingestão. Nesse cenário, o perfil de ingestão precisa, no mínimo, da permissão osis:Ingest para interagir com o pipeline.
A seguinte política de acesso do IAM demonstra como conceder essa permissão ao perfil de ingestão:
Perfil de ingestão para origens baseadas em pull
Para fontes baseadas em pull, o pipeline de OpenSearch ingestão extrai ou busca ativamente dados de uma fonte externa, como o Amazon S3. Nesse caso, o pipeline deve assumir um perfil de pipeline do IAM que conceda as permissões necessárias para acessar a fonte de dados. Nesses cenários, perfil de ingestão é sinônimo de perfil de pipeline.
A função deve incluir uma relação de confiança que permita que a OpenSearch Inestion a assuma e permissões específicas para a fonte de dados. Para obter mais informações, consulte Permissões para ler uma origem.
Ingestão entre contas
Talvez seja necessário ingerir dados em um pipeline de outro Conta da AWS, como uma conta de aplicativo. Para configurar a ingestão entre contas, defina uma perfil de ingestão na mesma conta do pipeline e estabeleça uma relação de confiança entre o perfil de ingestão e a conta do aplicativo:
Em seguida, configure seu aplicativo para assumir o perfil de ingestão. A conta do aplicativo deve conceder AssumeRolepermissões à função do aplicativo para a função de ingestão na conta do pipeline.
Para obter etapas detalhadas e exemplos de políticas do IAM, consulte Concessão de acesso de ingestão entre contas.
