Aviso de fim do suporte: em 30 de junho de 2027, AWS encerrará o suporte para o AMS Advanced. Depois de 30 de junho de 2027, você não poderá mais acessar o console do AMS Advanced ou os recursos do AMS Advanced. Para obter mais informações, consulte Fim do suporte do AMS Advanced.
As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Como funciona o monitoramento
Veja os gráficos a seguir sobre a arquitetura de monitoramento no AWS Managed Services (AMS).
O diagrama a seguir fornece uma visão geral de alto nível do fluxo de trabalho de monitoramento da zona de pouso com várias contas do AMS e da zona de pouso com uma única conta do AMS.
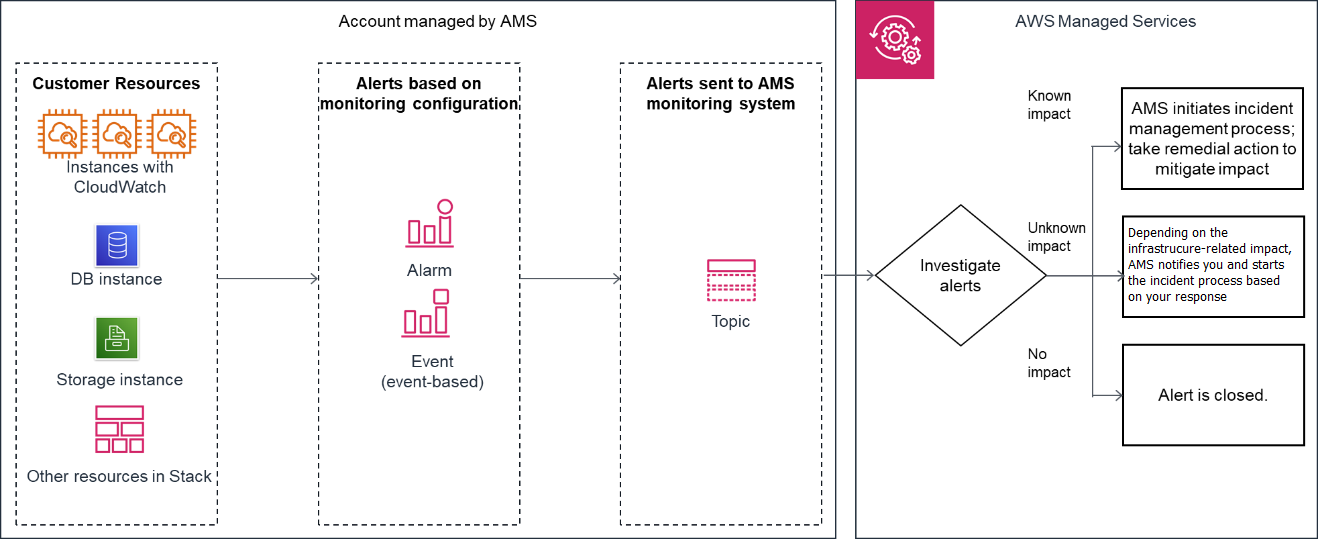
Geração: no momento da integração da conta, o AMS configura o monitoramento básico (uma combinação de alarmes CloudWatch (CW) e regras de eventos do CW) para todos os seus recursos criados em uma conta gerenciada. A configuração de monitoramento de linha de base gera um alerta quando um alarme CW é acionado ou um evento CW é gerado.
Agregação:
Multi-Account Zona de aterrissagem: os alertas são gerados por seus recursos nas contas do aplicativo e da unidade organizacional principal e enviados ao sistema de monitoramento do AMS, direcionando-os por meio da conta de segurança.
Single-Account Zona de pouso: todos os alertas gerados por seus recursos são enviados ao sistema de monitoramento do AMS, direcionando-os para um tópico do SNS na conta.
Você também pode configurar como o AMS agrupa os alertas do EC2. O AMS agrupa todos os alertas relacionados à mesma instância do EC2 em um único incidente ou cria um incidente por alerta, dependendo da sua preferência. Você pode alterar essa configuração a qualquer momento trabalhando com seu Cloud Service Delivery Manager ou Cloud Architect. Isso funciona da mesma forma se você estiver usando Multi-Account Landing Zone ou Single-Account Landing Zone.
Processamento: O AMS analisa os alertas e os processa com base em seu potencial de impacto. Os alertas são processados conforme descrito a seguir.
Alertas com impacto conhecido no cliente: eles levam à criação de um novo relatório de incidentes e o AMS segue o processo de gerenciamento de incidentes; para obter informações sobre o gerenciamento de incidentes, consulteResposta ao incidente do AMS.
Exemplo de alerta: uma instância do Amazon EC2 falha em uma verificação de integridade do sistema, o AMS tenta recuperar a instância interrompendo-a e reiniciando-a.
Alertas com impacto incerto no cliente: para esses tipos de alertas, o AMS envia um relatório de incidentes, em muitos casos solicitando que você verifique o impacto antes de agir. No entanto, se as verificações relacionadas à infraestrutura forem aprovadas, o AMS não enviará um relatório de incidentes para você.
Por exemplo: um alerta de mais de 85% de utilização da CPU por mais de 10 minutos em uma instância do Amazon EC2 não pode ser imediatamente classificado como um incidente, pois esse comportamento pode ser esperado com base no uso. Neste exemplo, o AMS Automation executa verificações relacionadas à infraestrutura no recurso. Se essas verificações forem aprovadas, o AMS não enviará uma notificação de alerta, mesmo que o uso da CPU ultrapasse 99%. Se a automação detectar que as verificações relacionadas à infraestrutura estão falhando no recurso, o AMS enviará uma notificação de alerta e verificará se a mitigação é necessária. As notificações de alerta são discutidas em detalhes nesta seção. O AMS oferece opções de mitigação na notificação. Quando você responde à notificação confirmando que o alerta é um incidente, o AMS cria um novo relatório de incidente e o processo de gerenciamento de incidentes do AMS começa. As notificações de serviço que recebem uma resposta de “sem impacto no cliente”, ou nenhuma resposta por três dias, são marcadas como resolvidas e o alerta correspondente é marcado como resolvido.
Alertas sem impacto no cliente: se, após a avaliação, o AMS determinar que o alerta não tem impacto no cliente, o alerta será encerrado.
Por exemplo, AWS Health notifica sobre uma instância do EC2 que precisa ser substituída, mas essa instância já foi encerrada.
Notificações agrupadas por instâncias do EC2
Você pode configurar o monitoramento do AMS para agrupar alertas da mesma instância do EC2 em um único incidente. Seu Cloud Service Delivery Manager ou Cloud Architect pode configurar isso para você. Há quatro parâmetros que você pode configurar para cada AMS-managed conta.
Escopo: escolha em toda a conta ou com base em tags.
Para especificar uma configuração que se aplique a cada instância do EC2 nessa conta, escolha scope = account-wide.
Para especificar uma configuração que se aplique somente às instâncias do EC2 nessa conta com uma tag específica, escolha scope = tag-based.
Regra de agrupamento: escolha clássica ou instância.
Para configurar o agrupamento em nível de instância para cada recurso em sua conta, escolha escopo = toda a conta e regra de agrupamento = instância.
Para configurar recursos específicos em sua conta para usar o agrupamento em nível de instância, marque essas instâncias e escolha escopo = baseado em tag e regra de agrupamento = nível de instância.
Para não usar o agrupamento de instâncias para alertas em sua conta, escolha regra de agrupamento = clássico.
Opção de engajamento: escolha nenhuma, somente relatório ou padrão.
Para que o AMS não crie incidentes ou execute automações para alarmes desses recursos enquanto a configuração estiver ativa, escolha nenhum.
Para que o AMS não crie incidentes ou execute automações para alarmes desses recursos enquanto a configuração estiver ativa, e não execute a correção automática de documentos do Systems Manager, mas inclua registros desses eventos em seus relatórios, escolha somente relatório. Isso pode ser útil se você quiser reduzir o volume de casos de suporte a incidentes com os quais interage e se alguns incidentes de alguns recursos não exigirem atenção imediata, por exemplo, aqueles em uma conta que não seja de produção.
Para que o AMS processe seus alertas, execute automações e crie casos de incidentes quando necessário, escolha padrão.
Resolver depois: escolha 24 horas, 48 horas ou 72 horas. Por fim, configure quando os casos de incidentes são encerrados automaticamente. Se a hora da correspondência do último caso atingir o valor de Resolver após configurado, o incidente será encerrado.
Notificação de alerta
Como parte do processamento do alerta, com base na análise de impacto, o AWS Managed Services (AMS) cria um incidente e inicia o processo de gerenciamento de incidentes para remediação, quando o impacto pode ser determinado. Se o impacto não puder ser determinado, o AMS enviará uma notificação de alerta para o endereço de e-mail associado à sua conta por meio de uma notificação de serviço. Em alguns cenários, essa notificação de alerta não é enviada. Por exemplo, se as verificações relacionadas à infraestrutura estiverem passando por um alerta de alta utilização da CPU, uma notificação de alerta não será enviada para você. Para obter mais informações, consulte o diagrama da arquitetura de monitoramento do AMS para o processo de tratamento de alertas emComo funciona o monitoramento.
Tag-based notificação de alerta
Use tags para enviar notificações de alerta de seus recursos para diferentes endereços de e-mail. É uma prática recomendada usar notificações de alerta baseadas em tags, pois as notificações enviadas para um único endereço de e-mail podem causar confusão quando várias equipes de desenvolvedores usam a mesma conta. Tag-based as notificações de alerta não são afetadas pelas Notificações agrupadas por instâncias do EC2 configurações que você escolher.
Com as notificações de alerta baseadas em tags, você pode:
Envie alertas para um endereço de e-mail específico: Marque os recursos que têm alertas que devem ser enviados para um endereço de e-mail específico com o
key = OwnerTeamEmail,value =.EMAIL_ADDRESSEnviar alertas para vários endereços de e-mail: para usar vários endereços de e-mail, especifique uma lista de valores separados por vírgula. Por exemplo,
key =,OwnerTeamEmailvalue =. O número total de caracteres para o campo de valor não pode exceder 260.EMAIL_ADDRESS_1,EMAIL_ADDRESS_2,EMAIL_ADDRESS_3, ...Use uma chave de tag personalizada: para usar uma chave de tag personalizada, forneça o nome da chave de tag personalizada ao seu CSDM em um e-mail que autorize explicitamente a ativação de notificações automáticas para a comunicação baseada em tags. É uma prática recomendada usar a mesma estratégia de marcação para tags de contato em todas as suas instâncias e recursos.
nota
O valor chave OwnerTeamEmail não precisa estar em camel case. No entanto, as tags diferenciam maiúsculas de minúsculas e é uma prática recomendada usar o formato recomendado.
O endereço de e-mail deve ser especificado por completo, com o “sinal de arroba” (@) para separar a parte local do domínio. Exemplos de endereços de e-mail inválidos: Team.AppATabc.xyz oujohn.doe. Para obter orientação geral sobre sua estratégia de marcação, consulte Recursos de marcação AWS. Não adicione informações de identificação pessoal (PII) em suas tags. Use listas de distribuição ou aliases sempre que possível.
Tag-based a notificação de alerta é compatível com recursos dos seguintes serviços da Amazon: EC2, Elastic Block Store (EBS), Elastic Load Balancing (ELB), Application Load Balancer (ALB), Network Load Balancer, Relational Database Service (RDS), Elastic File System (EFS), FSx x e VPN OpenSearch. Site-to-Site
