As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Agendamento de dados no data lake de análise do Connect Customer
Este tópico detalha o conteúdo das tabelas de agendamento do data lake do Connect Customer. As tabelas listam a coluna, o tipo e a descrição do conteúdo.
Há duas maneiras de acessar o data lake de analytics e configurar os dados a serem compartilhados:
Se você não conseguir acessar as tabelas de agendamento usando a Opção 1, tente usar a Opção 2.
Conteúdo
Perfil de agendamento do funcionário
O nome da tabela: staff_scheduling_profile
Chave primária composta: {instance_id, agent_arn,
staff_scheduling_profile_version}
| Coluna | Tipo | Description |
|---|---|---|
| instance_id | string | O ID da instância Connect Customer. |
| agent_arn | string | O ARN do atendente. |
| staff_scheduling_profile_version | bigint | A versão do perfil de agendamento do funcionários. |
| instance_arn | string | O ARN da instância Connect Customer. |
| staffing_group_arn | string | O ARN do grupo de funcionários ao qual o atendente está designado. |
| start_timestamp | Timestamp | StartTimestamp para o Agente configurado nas Regras da Equipe (os horários são gerados somente após esse timestamp). |
| end_timestamp | Timestamp | EndTimestamp para o Agente configurado nas Regras da Equipe (os horários não são gerados além desse carimbo de data/hora). |
| shift_profile_arn | string | O ARN do perfil de turno atribuído ao agente nas regras da equipe. Mutuamente exclusivo com o Shift Rotation Pattern. |
| shift_rotation_pattern_arn | string | O ARN do padrão de rotação de turnos atribuído ao agente nas regras da equipe. Mutuamente exclusivo com o Shift Profile. |
| shift_rotation_start_step_id | bigint | O ID da etapa em que o agente começa no padrão de rotação de turnos atribuído. |
| timezone | string | Fuso horário configurado para o atendente. |
| is_deleted | Booleano | Defina como verdadeiro se o atendente for excluído. Caso contrário, defina como falso. |
| last_updated_timestamp | Timestamp | Registro de data e hora em que o perfil de agendamento da equipe foi /excluído. created/updated |
| data_lake_last_processed_timestamp | Timestamp | O carimbo de data/hora, que mostra a última vez que o registro foi manipulado pelo data lake. Pode incluir transformação e preenchimento. Este campo não pode ser usado para determinar com segurança a atualização dos dados. |
Atividades por turnos
O nome da tabela: shift_activities
Chave primária composta: {instance_id, shift_activity_arn,
shift_activity_version}
| Coluna | Tipo | Description |
|---|---|---|
| instance_id | string | O ID da instância Connect Customer. |
| shift_activity_arn | string | O ARN da atividade do turno. |
| shift_activity_version | bigint | A versão da atividade de turno. |
| instance_arn | string | O ARN da instância Connect Customer. |
| shift_activity_name | string | Nome da atividade de turno. |
| type | string | Tipo da atividade de turno. Os valores possíveis são: PRODUCTIVE, NON_PRODUCTIVE e LEAVE. |
| sub_type | string | O subtipo da atividade de turno. Isso só é válido para atividades do tipo NON_PRODUCTIVE. Os valores possíveis são: BREAK_OR_MEAL e NONE. |
| is_adherence_tracked | Booleano | Defina como verdadeiro se a atividade de turno estiver configurada para rastreamento de aderência. Caso contrário, defina como falso. |
| is_paid | Booleano | Defina como verdadeiro se a atividade de turno estiver configurada como paga. Caso contrário, defina como falso. |
| is_deleted | Booleano | Defina como verdadeiro se a atividade de turno for excluída. Caso contrário, defina como falso. |
| last_updated_timestamp | Timestamp | O registro de data e hora em que a atividade do turno foi /excluída. created/updated |
| data_lake_last_processed_timestamp | Timestamp | O carimbo de data/hora, que mostra a última vez que o registro foi manipulado pelo data lake. Pode incluir transformação e preenchimento. Este campo não pode ser usado para determinar com segurança a atualização dos dados. |
Perfis de turno
O nome da tabela: shift_profiles
Chave primária composta: {instance_id, shift_profile_arn,
shift_profile_version}
| Coluna | Tipo | Description |
|---|---|---|
| instance_id | string | O ID da instância Connect Customer. |
| shift_profile_arn | string | O ARN do perfil de turno. |
| shift_profile_version | bigint | A versão do perfil de turno. |
| instance_arn | string | O ARN da instância Connect Customer. |
| shift_profile_name | string | O nome do perfil do turno. |
| is_deleted | Booleano | Defina como verdadeiro se o perfil de turno for excluído. Caso contrário, defina como falso. |
| last_updated_timestamp | Timestamp | O carimbo de data/hora em que o perfil Shift foi /excluído. created/updated |
| data_lake_last_processed_timestamp | Timestamp | O carimbo de data/hora, que mostra a última vez que o registro foi manipulado pelo data lake. Pode incluir transformação e preenchimento. Este campo não pode ser usado para determinar com segurança a atualização dos dados. |
Grupos de pessoal
O nome da tabela: staffing_groups
Chave primária composta: {instance_id, staffing_group_arn,
staffing_group_version}
| Coluna | Tipo | Description |
|---|---|---|
| instance_id | string | O ID da instância Connect Customer. |
| staffing_group_arn | string | O ARN do grupo de funcionários. |
| staffing_group_version | bigint | A versão do grupo de funcionários. |
| instance_arn | string | O ARN da instância Connect Customer. |
| staffing_group_name | string | O nome do grupo de funcionários. |
| is_deleted | Booleano | Defina como verdadeiro se o grupo de funcionários for excluído. Caso contrário, defina como falso. |
| last_updated_timestamp | Timestamp | O carimbo de data/hora em que o Grupo de Pessoal foi /excluído. created/updated |
| data_lake_last_processed_timestamp | Timestamp | O carimbo de data/hora, que mostra a última vez que o registro foi manipulado pelo data lake. Pode incluir transformação e preenchimento. Este campo não pode ser usado para determinar com segurança a atualização dos dados. |
Grupos de funcionários - grupos de previsões
O nome da tabela: staffing_group_forecast_groups
Chave primária composta: {instance_id, staffing_group_arn,
staffing_group_version, forecast_group_arn}
Essa tabela deve ser consultada fazendo junção com a tabela staffing_groups em staffing_group_arn e staffing_group_version.
| Coluna | Tipo | Description |
|---|---|---|
| instance_id | string | O ID da instância Connect Customer. |
| staffing_group_arn | string | O ARN do grupo de funcionários. |
| staffing_group_version | bigint | A versão do grupo de funcionários. |
| forecast_group_arn | string | O ARN do grupo de previsões associado ao grupo de funcionários. |
| instance_arn | string | O ARN da instância Connect Customer. |
| is_deleted | Booleano | Defina como False quando a StaffingGroup-ForecastGroup associação for válida. |
| last_updated_timestamp | Timestamp | O carimbo de data/hora em que o Grupo de Pessoal estava. created/updated |
| data_lake_last_processed_timestamp | Timestamp | O carimbo de data/hora, que mostra a última vez que o registro foi manipulado pelo data lake. Pode incluir transformação e preenchimento. Este campo não pode ser usado para determinar com segurança a atualização dos dados. |
Grupos de funcionários - supervisores
O nome da tabela: staffing_group_supervisors
Chave primária composta: {instance_id, staffing_group_arn,
staffing_group_version, supervisor_arn}
Essa tabela deve ser consultada fazendo junção com a tabela staffing_groups em staffing_group_arn e staffing_group_version.
| Coluna | Tipo | Description |
|---|---|---|
| instance_id | string | O ID da instância Connect Customer. |
| staffing_group_arn | string | O ARN do grupo de funcionários. |
| staffing_group_version | bigint | A versão do grupo de funcionários. |
| supervisor_arn | string | O ARN do atendente do supervisor associado ao grupo de funcionários. |
| instance_arn | string | O ARN da instância Connect Customer. |
| is_deleted | Booleano | Defina como False quando a StaffingGroup-ForecastGroup associação for válida. |
| last_updated_timestamp | Timestamp | O carimbo de data/hora em que o Grupo de Pessoal estava. created/updated |
| data_lake_last_processed_timestamp | Timestamp | O carimbo de data/hora, que mostra a última vez que o registro foi manipulado pelo data lake. Pode incluir transformação e preenchimento. Este campo não pode ser usado para determinar com segurança a atualização dos dados. |
Turnos dos funcionários
O nome da tabela: staff_shifts
Chave primária composta: {instance_id, shift_id, shift_version}
| Coluna | Tipo | Description |
|---|---|---|
| instance_id | string | O ID da instância Connect Customer. |
| shift_id | string | O ID do turno. |
| shift_version | bigint | A versão do turno. |
| instance_arn | string | O ARN da instância Connect Customer. |
| agent_arn | string | O ARN do atendente. |
| shift_start_timestamp | Timestamp | O carimbo de data/hora de quando o turno começa. |
| shift_end_timestamp | Timestamp | O carimbo de data/hora de quando o turno termina. |
| created_timestamp | Timestamp | O carimbo de data/hora de quando o turno foi criado. |
| is_deleted | Booleano | Defina como verdadeiro se o turno for excluído. Caso contrário, defina como falso. |
| last_updated_timestamp | Timestamp | O carimbo de data/hora em que o Shift foi /excluído. created/updated |
| data_lake_last_processed_timestamp | Timestamp | O carimbo de data/hora, que mostra a última vez que o registro foi manipulado pelo data lake. Pode incluir transformação e preenchimento. Este campo não pode ser usado para determinar com segurança a atualização dos dados. |
Atividades por turno dos funcionários
O nome da tabela: staff_shift_activities
Chave primária composta: {instance_id, shift_id, shift_version,
activity_id}
Essa tabela deve ser consultada fazendo junção com a tabela staff_shifts em shift_id e shift_version.
| Coluna | Tipo | Description |
|---|---|---|
| instance_id | string | O ID da instância Connect Customer. |
| shift_id | string | O ID do turno. |
| shift_version | bigint | A versão do turno. |
| activity_id | string | O ID da atividade. |
| instance_arn | string | O ARN da instância Connect Customer. |
| activity_start_timestamp | Timestamp | O carimbo de data/hora de quando a atividade começa. |
| activity_end_timestamp | Timestamp | O carimbo de data/hora de quando a atividade termina. |
| shift_activity_arn | string | O ARN da atividade do turno. Se o shift_activity_arn for nulo, isso indica a atividade “Trabalho”. |
| activity_status | string | Status da atividade. Será definido como INACTIVE se a atividade se sobrepor a uma folga. |
| is_overtime | Booleano | Defina como verdadeiro se a atividade fizer parte das horas extras. Caso contrário, defina como falso. |
| is_deleted | Booleano | Defina como falso quando as atividades do turno forem válidas. |
| last_updated_timestamp | Timestamp | O carimbo de data/hora em que ocorreu o turno. created/updated |
| data_lake_last_processed_timestamp | Timestamp | O carimbo de data/hora, que mostra a última vez que o registro foi manipulado pelo data lake. Pode incluir transformação e preenchimento. Este campo não pode ser usado para determinar com segurança a atualização dos dados. |
Mudanças no saldo de folgas dos funcionários
O nome da tabela: staff_timeoff_balance_changes
Chave primária composta: {instance_id, agent_arn, shift_activity_arn,
timeoff_balance_version}
| Coluna | Tipo | Description |
|---|---|---|
| instance_arn | string | O ARN da instância Connect Customer. |
| instance_id | string | O ID da instância Connect Customer. |
| account_id | string | O ID da AWS conta. |
| agent_arn | string | O ARN do agente. |
| shift_activity_arn | string | O ARN da atividade do turno para a qual esse saldo é alocado. |
| timeoff_balance_version | bigint | A versão do saldo de folgas, um número crescente para indicar a ordem das alterações. |
| balance_update_source | string | Fonte da atualização do saldo. Os valores possíveis são TIME_OFF_BALANCE_UPLOAD, CONNECT_TIME_OFF_REQUEST, SCHEDULE_PUBLISH, CSV_TIME_OFF_BALANCE_DELETION, TIME_OFF_BALANCE_BACKFILL, SYSTEM_UPDATE |
| timeoff_id | string | O ID da folga que causou essa alteração de saldo, se houver. |
| last_updated_by | string | O ARN do atendente que causou essa alteração de saldo, se houver. |
| balance_change_in_hours | double | Quantidade do saldo de folgas atualizada por meio dessa alteração em horas. Se esse valor for positivo, essa alteração creditará o saldo de folgas. Se esse valor for negativo, essa alteração deduzirá do saldo de folgas. Esse valor é indefinido para todos os eventos de upload e exclusão do saldo. |
| remaining_balance_in_hours | double | Horas do saldo de folga restantes após esse evento de alteração. Esse valor é indefinido para qualquer evento de exclusão do saldo. |
| last_created_timestamp | Timestamp | O carimbo de data/hora de quando o registro de alteração do saldo de folgas foi criado. |
| data_lake_last_processed_timestamp | Timestamp | O carimbo de data/hora, que mostra a última vez que o registro foi manipulado pelo data lake. Pode incluir transformação e preenchimento. Este campo não pode ser usado para determinar com segurança a atualização dos dados. |
Folgas dos funcionários
O nome da tabela: staff_timeoffs
Chave primária composta: {instance_id, timeoff_id, agent_arn,
timeoff_version}
| Coluna | Tipo | Description |
|---|---|---|
| instance_id | string | O ID da instância Connect Customer. |
| timeoff_id | string | O ID da folga. |
| agent_arn | string | O ARN do atendente. |
| timeoff_version | bigint | Versão da folga. |
| instance_arn | string | O ARN da instância Connect Customer. |
| timeoff_type | string | Tipo de folga. Os valores possíveis são: TIME_OFF e VOLUNTARY_TIME_OFF. |
| timeoff_start_timestamp | Timestamp | Carimbo de data/hora de quando a folga começa. |
| timeoff_end_timestamp | Timestamp | Carimbo de data/hora de quando a folga termina. |
| timeoff_status | string | Status da folga. Os valores possíveis são: PENDING_CREATE, PENDING_UPDATE, PENDING_CANCEL, PENDING_ACCEPT, PENDING_APPROVE, PENDING_DECLINE, APPROVED, ACCEPTED, REJECTED, CANCELLED, WAITING_ACCEPT e WAITING_APPROVE. Os status WAITING indicam que a folga está aguardando a ação do usuário. Os status PENDING indicam que a folga está aguardando o processamento de uma ação do usuário pelo sistema. |
| shift_activity_arn | string | O ARN da atividade do turno usado para a folga. |
| effective_timeoff_hours | double | Total de horas de folga efetivas. As horas de folga efetivas são calculadas com base na lógica de dedução de folga. Isso só é definido para o tipo TIME_OFF. |
| last_updated_timestamp | Timestamp | Registro de data e hora em que o horário de folga foi /excluído. created/updated |
| data_lake_last_processed_timestamp | Timestamp | O carimbo de data/hora, que mostra a última vez que o registro foi manipulado pelo data lake. Pode incluir transformação e preenchimento. Este campo não pode ser usado para determinar com segurança a atualização dos dados. |
Intervalos de folga dos funcionários
O nome da tabela: staff_timeoff_intervals
Chave primária composta: {instance_id, timeoff_id, timeoff_version,
interval_id}
Essa tabela deve ser consultada fazendo junção com a tabela staff_timeoffs em timeoff_id e timeoff_version.
| Coluna | Tipo | Description |
|---|---|---|
| instance_id | string | O ID da instância Connect Customer. |
| timeoff_id | string | O ID da folga. |
| timeoff_version | bigint | Versão da folga. |
| interval_id | string | O ID do intervalo de folga. |
| instance_arn | string | O ARN da instância Connect Customer. |
| timeoff_interval_start_timestamp | Timestamp | Carimbo de data/hora de quando o intervalo específico de folga começa. |
| timeoff_interval_end_timestamp | Timestamp | Carimbo de data/hora de quando o intervalo específico de folga termina. |
| interval_effective_timeoff_hours | double | Horas de folga efetivas para esse intervalo específico de folga. As horas de folga efetivas são calculadas com base na lógica de dedução de folga. |
| last_updated_timestamp | Timestamp | Registro de data e hora em que o horário de folga foi /excluído. created/updated |
| data_lake_last_processed_timestamp | Timestamp | O carimbo de data/hora, que mostra a última vez que o registro foi manipulado pelo data lake. Pode incluir transformação e preenchimento. Este campo não pode ser usado para determinar com segurança a atualização dos dados. |
Grupo de demanda de pessoal
Nome da tabela: staff_demand_group
Chave primária composta: {instance_id, agent_arn, demand_group_arn, staff_demand_group_version}
| Coluna | Tipo | Description |
|---|---|---|
| instance_id | string | O ID da instância Connect Customer. |
| agent_arn | string | O ARN do agente. |
| demand_group_arn | string | O ARN do grupo de demanda. |
| staff_demand_group_version | Longo | Versão para este agente exigir associação de grupos |
| priority | string | Prioridade do grupo de demanda desse agente. Pode ser BAIXO, MÉDIO ou ALTO |
| instance_arn | string | O ARN da instância Connect Customer. |
| é_sobrescrever | Booleano | Definido como 'verdadeiro' se for a associação entre Agente e Grupo de Demanda, é Substituição em nível de agente. |
| is_deleted | Booleano | Defina como verdadeiro se a associação entre agente e grupo de demanda for excluída. |
| last_updated_timestamp | Timestamp | O carimbo de data/hora em que o agente que exigiu a associação do grupo foi. created/updated |
| data_lake_last_processed_timestamp | Timestamp | O carimbo de data/hora, que mostra a última vez que o registro foi manipulado pelo data lake. Pode incluir transformação e preenchimento. Este campo não pode ser usado para determinar com segurança a atualização dos dados. |
Grupo de demanda de grupos de pessoal
Nome da tabela: staffing_group_demand_group
Chave primária composta: {instance_id, staffing_group_arn, demand_group_arn,
staffing_group_demand_group_version}
| Coluna | Tipo | Description |
|---|---|---|
| instance_id | string | O ID da instância Connect Customer. |
| staffing_group_arn | string | O ARN do grupo de funcionários. |
| demand_group_arn | string | O ARN do grupo de demanda. |
| staffing_group_demand_group_version | Longo | Versão para esta associação de Grupo de Pessoal a Grupo de Demanda |
| priority | string | Prioridade do grupo de demanda para este grupo de pessoal. Pode ser BAIXO, MÉDIO ou ALTO |
| instance_arn | string | O ARN da instância Connect Customer. |
| is_deleted | Booleano | Defina como verdadeiro se o grupo de funcionários para a associação do grupo de demanda for excluído. |
| last_updated_timestamp | Timestamp | Registro de data e hora em que o grupo de funcionários para a associação do grupo de demanda foi /excluído. created/updated |
| data_lake_last_processed_timestamp | Timestamp | O carimbo de data/hora, que mostra a última vez que o registro foi manipulado pelo data lake. Pode incluir transformação e preenchimento. Este campo não pode ser usado para determinar com segurança a atualização dos dados. |
Alocação de atividades por turnos de funcionários
Nome da tabela: staff_shift_activity_allocations
Chave primária composta: {instance_id, shift_id, shift_version, activity_id, demand_group_arn}
| Coluna | Tipo | Description |
|---|---|---|
| instance_id | string | O ID da instância Connect Customer. |
| shift_id | string | O ID do turno. |
| shift_version | Longo | A versão do turno. |
| activity_id | string | O ID da atividade. |
| demand_group_arn | string | O ARN do grupo de demanda. |
| foecast_group_arn | string | O ARN do grupo de previsões. |
| percentagem_de_alocação | double | Alocação percentual da Atividade para o Grupo de Demanda. |
| is_deleted | Booleano | Defina como False quando StaffingGroup-ForecastGroupassociation for válido. |
| last_updated_timestamp | Timestamp | O carimbo de data/hora em que o Grupo de Pessoal estava. created/updated |
| data_lake_last_processed_timestamp | Timestamp | O carimbo de data/hora, que mostra a última vez que o registro foi manipulado pelo data lake. Pode incluir transformação e preenchimento. Este campo não pode ser usado para determinar com segurança a atualização dos dados. |
Métricas de cronograma
O nome da tabela: schedule_metrics
Chave primária composta: {instance_id, metric_id, interval_start_timestamp}
| Coluna | Tipo | Description |
|---|---|---|
| instance_id | string | O ARN da instância do Amazon Connect. |
| instance_arn | string | O ID da instância do Amazon Connect. |
| identificação_métrica | string | Identificador exclusivo para o valor métrico |
| aws_account_id | string | O ID da conta da AWS. |
| entity_type | string | Indica se a métrica é para um grupo de previsão ou grupo de demanda. |
| entidade_arn | string | Arn do grupo de previsão ou grupo de demanda |
| canal | string | Denota o canal de mídia como Voice, chat. Se a linha contiver métricas que não estejam no nível do canal, ela será preenchida como ALL |
| timestamp interval_start_ | timestamp | Carimbo de data/hora indicando o início do intervalo |
| contagem_de_agentes necessários | flutuação | Indica a contagem prevista de agentes |
| contagem de agentes agendados | flutuação | Indica a contagem de agentes do cronograma |
| ocupação_programada | flutuação | Denota a porcentagem de ocupação |
| percentual do nível_de_serviço agendado | flutuação | Indica a porcentagem do nível de serviço programado |
| nível_de_segundos de serviço | integer | Indica os segundos do nível de serviço |
| velocidade_média programada da resposta | flutuação | Denota a velocidade média de resposta |
| is_deleted | booleano | Indica se a métrica foi excluída |
| last_updated_timestamp | timestamp | O carimbo de data e hora em que o registro métrico foi criado. |
| data_lake_last_processed_timestamp | timestamp | O carimbo de data/hora, que mostra a última vez que o data lake foi atualizado. Pode incluir transformação e preenchimento. Este campo não pode ser usado para determinar com segurança a atualização dos dados. |
Agende metas
O nome da tabela: schedule_goals
Chave primária composta: {instance_id, goal_id}
| Coluna | Tipo | Description |
|---|---|---|
| instance_id | string | O ARN da instância do Amazon Connect. |
| instance_arn | string | O ID da instância do Amazon Connect. |
| id_objetivo | string | Identificador exclusivo para o valor da meta |
| aws_account_id | string | O ID da conta da AWS. |
| entity_type | string | Indica se a meta é para um grupo de previsão ou grupo de demanda. |
| entidade_arn | string | Arn do grupo de previsão ou grupo de demanda |
| canal | string | Denota o canal de mídia como Voice, chat. |
| start_date_timestamp | timestamp | Registro de data e hora indicando o início da meta |
| carimbo de data/hora do fim | timestamp | Registro de data e hora indicando o fim da meta |
| porcentagem do nível_de_serviço da meta | flutuação | Indica a porcentagem do nível de serviço da meta |
| meta de nível_de_serviço_segundos | integer | Indica os segundos do nível de serviço |
| meta: velocidade média da resposta | flutuação | Denota a velocidade média de resposta |
| is_deleted | booleano | Indica se a meta foi excluída |
| last_updated_timestamp | timestamp | O carimbo de data e hora em que o registro de metas foi criado. |
| data_lake_last_processed_timestamp | timestamp | O carimbo de data/hora, que mostra a última vez que o data lake foi atualizado. Pode incluir transformação e preenchimento. Este campo não pode ser usado para determinar com segurança a atualização dos dados. |
Padrões de rotação de turnos
O nome da tabela: shift_rotation_patterns
Chave primária composta: {instance_id, shift_rotation_pattern_arn,
shift_rotation_pattern_version}
| Coluna | Tipo | Description |
|---|---|---|
| instance_id | string | O ID da instância Connect Customer. |
| shift_rotation_pattern_arn | string | O ARN do Shift Rotation Pattern. |
| versão_padrão_de_rotação do shift_rotation | bigint | A versão Shift Rotation Pattern. |
| instance_arn | string | O ARN da instância Connect Customer. |
| shift_rotation_pattern_name | string | O nome do Shift Rotation Pattern. |
| start_date | string | A data de início do Shift Rotation Pattern em yyyy-mm-dd formato. |
| is_deleted | Booleano | Defina como True se o Shift Rotation Pattern for excluído. Caso contrário, defina como falso. |
| last_updated_by | string | O ARN do usuário que created/updated /excluiu o Shift Rotation Pattern. |
| last_updated_timestamp | Timestamp | O carimbo de data/hora em que o padrão de rotação do Shift foi /excluído. created/updated |
| data_lake_last_processed_timestamp | Timestamp | O carimbo de data/hora, que mostra a última vez que o registro foi manipulado pelo data lake. Pode incluir transformação e preenchimento. Este campo não pode ser usado para determinar com segurança a atualização dos dados. |
Etapas de rotação do turno
O nome da tabela: shift_rotation_steps
Chave primária composta: {instance_id, shift_rotation_pattern_arn,
shift_rotation_pattern_version, step_id}
Essa tabela deve ser consultada fazendo junção com a tabela shift_rotation_patterns em shift_rotation_pattern_arn e shift_rotation_pattern_version.
| Coluna | Tipo | Description |
|---|---|---|
| instance_id | string | O ID da instância Connect Customer. |
| shift_rotation_pattern_arn | string | O ARN do Shift Rotation Pattern. |
| versão_padrão_de_rotação do shift_rotation | bigint | A versão Shift Rotation Pattern. |
| step_id | bigint | O ID da etapa dentro do padrão de rotação de turnos. As etapas são numeradas sequencialmente (1, 2, 3,... até 52). |
| instance_arn | string | O ARN da instância Connect Customer. |
| shift_profile_arn | string | O ARN do perfil de mudança associado à etapa de rotação. |
| duration | bigint | A duração da etapa de rotação em semanas. |
| is_deleted | Booleano | Defina como False quando a Etapa de Rotação do Shift for válida. |
| last_updated_by | string | O ARN do usuário que usa o Shift Rotation created/updated Pattern. |
| last_updated_timestamp | Timestamp | O carimbo de data/hora em que estava o padrão de rotação do turno. created/updated |
| data_lake_last_processed_timestamp | Timestamp | O carimbo de data/hora, que mostra a última vez que o registro foi manipulado pelo data lake. Pode incluir transformação e preenchimento. Este campo não pode ser usado para determinar com segurança a atualização dos dados. |
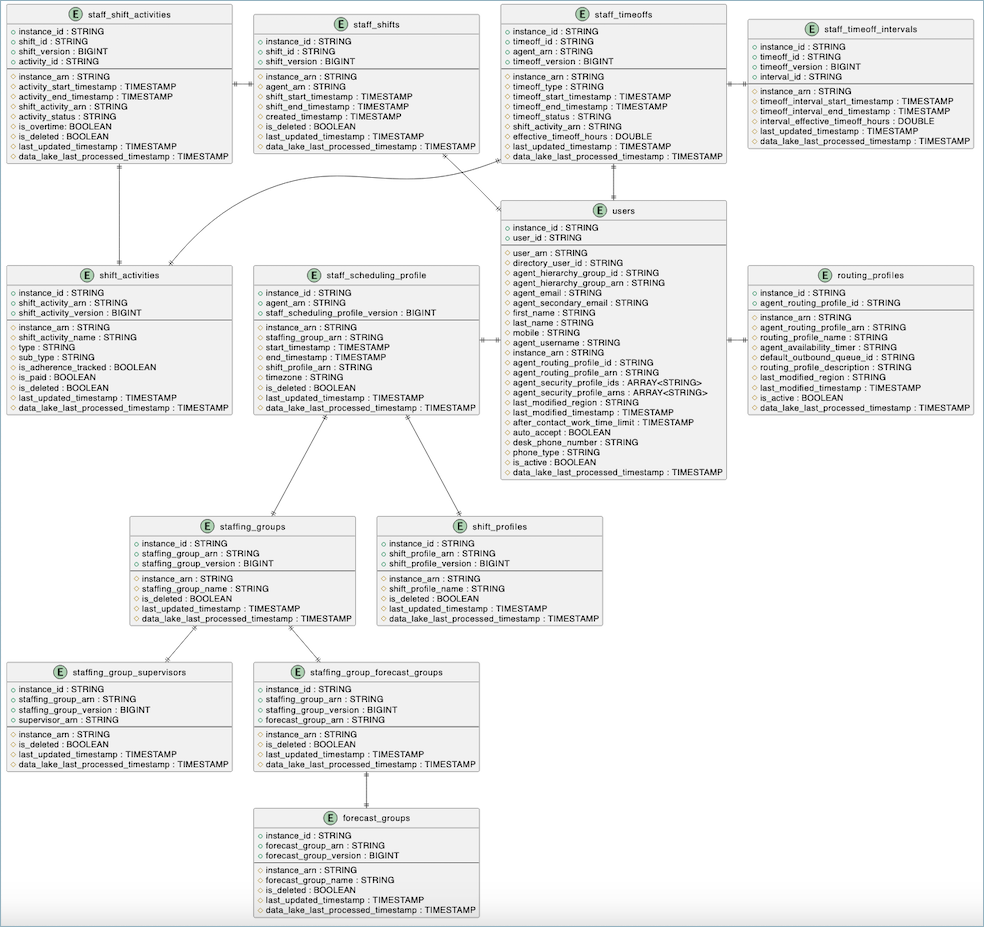
Esquema de dados
A seguir está um diagrama de relacionamento entre entidades que mostra a estrutura e os relacionamentos entre as tabelas de agendamento no data lake do Connect Customer.
Cada tabela exibe suas chaves primárias e atributos com os respectivos tipos de dados. O diagrama ilustra como essas tabelas se relacionam entre si por meio de relacionamentos de chave externa, fornecendo uma visão abrangente do modelo de dados de agendamento.
Exemplos de consultas
1. Consulta para acessar todas as atividades de turno agendadas dos atendentes que trabalham em um grupo de previsões específico.
SELECT * FROM agent_scheduled_shift_activities_view
where forecast_group_name = 'AnyDepartmentForecastGroup'
Conclua as etapas a seguir para criar a agent_scheduled_shift_activities_view mencionada acima.
Etapa 1: criar uma visualização para acessar os nomes dos supervisores
CREATE OR REPLACE VIEW "latest_supervisor_names_view" AS SELECT staffing_group_arn , array_agg(supervisor_name ORDER BY supervisor_name ASC) supervisor_names FROM ( SELECT s.staffing_group_arn , CONCAT(u.first_name, ' ', u.last_name) supervisor_name FROM (( SELECT staffing_group_arn , supervisor_arn FROM ( SELECT * , RANK() OVER (PARTITION BY staffing_group_arn ORDER BY staffing_group_version DESC) recency FROM staffing_group_supervisors WHERE (instance_id = 'YourAmazonConnectInstanceId') ) t WHERE (recency = 1) ) s INNER JOIN USERS u ON (s.supervisor_arn = u.user_arn)) ) GROUP BY staffing_group_arn
Etapa 2: criar uma visualização para associar o grupo de funcionários e o grupo de previsões a um atendente
CREATE OR REPLACE VIEW "latest_agent_staffing_group_forecast_group_view" AS WITH latest_staff_scheduling_profile AS ( SELECT agent_arn , staffing_group_arn , last_updated_timestamp FROM ( SELECT * , RANK() OVER (PARTITION BY agent_arn ORDER BY staff_scheduling_profile_version DESC) recency FROM staff_scheduling_profile WHERE ((instance_id = 'YourAmazonConnectInstanceId') AND (is_deleted = false)) ) t WHERE (recency = 1) ) , latest_staffing_groups AS ( SELECT staffing_group_name , staffing_group_arn FROM ( SELECT * , RANK() OVER (PARTITION BY staffing_group_arn ORDER BY staffing_group_version DESC) recency FROM staffing_groups WHERE (instance_id = 'YourAmazonConnectInstanceId') ) t WHERE (recency = 1) ) , latest_forecast_groups AS ( SELECT forecast_group_arn , forecast_group_name FROM ( SELECT * , RANK() OVER (PARTITION BY forecast_group_arn ORDER BY forecast_group_version DESC) recency FROM forecast_groups WHERE (instance_id = 'YourAmazonConnectInstanceId') ) t WHERE (recency = 1) ) , latest_staffing_group_forecast_groups AS ( SELECT staffing_group_arn , forecast_group_arn FROM ( SELECT * , RANK() OVER (PARTITION BY staffing_group_arn ORDER BY staffing_group_version DESC) recency FROM staffing_group_forecast_groups WHERE (instance_id = 'YourAmazonConnectInstanceId') ) t WHERE (recency = 1) ) SELECT ssp.agent_arn , U.agent_username AS username , U.agent_routing_profile_id AS routing_profile_id , CONCAT(u.first_name, ' ', u.last_name) agent_name , fg.forecast_group_arn , fg.forecast_group_name , sg.staffing_group_arn , sg.staffing_group_name FROM latest_staff_scheduling_profile ssp INNER JOIN latest_staffing_groups sg ON ssp.staffing_group_arn = sg.staffing_group_arn INNER JOIN latest_staffing_group_forecast_groups sgfg ON ssp.staffing_group_arn = sgfg.staffing_group_arn INNER JOIN latest_forecast_groups fg ON fg.forecast_group_arn = sgfg.forecast_group_arn INNER JOIN USERS u ON ssp.agent_arn = u.user_arn
Etapa 3: acessar as atividades mais recentes do turno
CREATE OR REPLACE VIEW "latest_shift_activities_view" AS SELECT shift_activity_arn , shift_activity_name , shift_activity_version , type , sub_type , is_adherence_tracked , is_paid , last_updated_timestamp FROM ( SELECT * , RANK() OVER (PARTITION BY shift_activity_arn ORDER BY shift_activity_version DESC) recency FROM shift_activities WHERE (instance_id = 'YourAmazonConnectInstanceId') ) t WHERE (recency = 1)
Etapa 4: criar uma visualização para acessar as atividades de turno agendadas do atendente
CREATE OR REPLACE VIEW "agent_scheduled_shift_activities_view" AS WITH latest_staff_shifts AS ( SELECT agent_arn , shift_id , shift_version , shift_start_timestamp , shift_end_timestamp , created_timestamp , last_updated_timestamp , data_lake_last_processed_timestamp , recency FROM ( SELECT RANK() OVER (PARTITION BY shift_id ORDER BY shift_version DESC) recency , * FROM staff_shifts sa WHERE (instance_id = 'YourAmazonConnectInstanceId') ) t WHERE ((recency = 1) AND (is_deleted = false)) ) SELECT asgfg.forecast_group_name , array_join(sn.supervisor_names, ',') supervisor_names , s.agent_arn , u.first_name , u.last_name , asgfg.staffing_group_name , ssa.activity_id , (CASE WHEN (ssa.shift_activity_arn IS NULL) THEN COALESCE(sa.shift_activity_name, 'Work') ELSE sa.shift_activity_name END) shift_activity_name , s.shift_start_timestamp , s.shift_end_timestamp , (CASE WHEN (ssa.shift_activity_arn IS NULL) THEN COALESCE(sa.type, 'PRODUCTIVE') ELSE sa.type END) type , (CASE WHEN (ssa.shift_activity_arn IS NULL) THEN COALESCE(sa.is_paid, true) ELSE sa.is_paid END) is_paid , ssa.activity_start_timestamp , ssa.activity_end_timestamp , ssa.last_updated_timestamp , ssa.data_lake_last_processed_timestamp , u.agent_username as username , u.agent_routing_profile_id as routing_profile_id FROM staff_shift_activities ssa INNER JOIN latest_staff_shifts s ON s.shift_id = ssa.shift_id AND s.shift_version = ssa.shift_version INNER JOIN USERS u ON s.agent_arn = u.user_arn INNER JOIN latest_agent_staffing_group_forecast_group_view asgfg ON s.agent_arn = asgfg.agent_arn LEFT JOIN latest_shift_activities_view sa ON sa.shift_activity_arn = ssa.shift_activity_arn INNER JOIN latest_supervisor_names_view sn ON sn.staffing_group_arn = asgfg.staffing_group_arn WHERE (ssa.is_deleted = false) AND (COALESCE(ssa.activity_status, ' ') <> 'INACTIVE') AND (ssa.instance_id = 'YourAmazonConnectInstanceId')
2. Consulta para acessar todas as solicitações de folga dos atendentes em um grupo de previsão específico.
SELECT * FROM agent_timeoff_report_view where forecast_group_name =
'AnyDepartmentForecastGroup'
Use a consulta a seguir para criar a agent_timeoff_report_view mencionada acima.
CREATE OR REPLACE VIEW "agent_timeoff_report_view" AS WITH latest_staff_timeoffs AS ( SELECT t1.*, CAST((t1.effective_timeoff_hours * 60) AS INT) total_effective_timeoff_minutes FROM ( SELECT RANK() OVER ( PARTITION BY timeoff_id ORDER BY timeoff_version DESC ) recency, agent_arn, timeoff_id, shift_activity_arn, timeoff_status, timeoff_version, effective_timeoff_hours, timeoff_start_timestamp, timeoff_end_timestamp, last_updated_timestamp, data_lake_last_processed_timestamp FROM staff_timeoffs WHERE ( instance_id = 'YourAmazonConnectInstanceId' ) ) t1 WHERE (recency = 1) ) SELECT asgfg.forecast_group_name, to.agent_arn, asgfg.agent_name, asgfg.staffing_group_name, asgfg.username, sa.shift_activity_name, to.timeoff_start_timestamp, to.timeoff_end_timestamp, to.timeoff_status, array_join(sn.supervisor_names, ',') AS supervisor_names, sa.is_paid, to.last_updated_timestamp, to.data_lake_last_processed_timestamp, u.agent_routing_profile_id AS routing_profile_id, to.timeoff_id, to.shift_activity_arn, to.total_effective_timeoff_minutes FROM latest_staff_timeoffs to INNER JOIN latest_agent_staffing_group_forecast_group_view asgfg ON asgfg.agent_arn = to.agent_arn INNER JOIN latest_shift_activities_view sa ON sa.shift_activity_arn = to.shift_activity_arn INNER JOIN latest_supervisor_names_view sn ON sn.staffing_group_arn = asgfg.staffing_group_arn INNER JOIN users u ON u.user_arn = to.agent_arn
