翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
シャッフルを最適化する
join() や groupByKey() などの特定のオペレーションでは、Spark によるシャッフルの実行が必要です。シャッフルは、RDD パーティション全体でデータを再分散し、異なるグループにまとめ直すための Spark のメカニズムです。シャッフルによって、パフォーマンスのボトルネックを解消できることがあります。ただし、シャッフルでは通常、Spark エグゼキュター間でデータをコピーする必要があるため、複雑でコストのかかる処理となります。例えば、シャッフルによって次のようなコストが発生します。
-
ディスク I/O:
-
ディスク上に大量の中間ファイルが生成されます。
-
-
ネットワーク I/O:
-
多くのネットワーク接続が必要になります (接続数 =
Mapper × Reducer)。 -
レコードは、別の Spark エグゼキュターでホストされている可能性のある新しい RDD パーティションに集約されるため、データセットの多くが Spark エグゼキュター間でネットワーク越しに移動する可能性があります。
-
-
CPU とメモリの負荷:
-
値をソートし、データセットをマージします。これらのオペレーションはエグゼキュターで計画され、エグゼキュターに大きな負荷がかかります。
-
シャッフルは、Spark アプリケーションのパフォーマンス低下につながる最も重要な要因の 1 つです。中間データを保存する際にエグゼキュターのローカルディスクのスペースが枯渇し、Spark ジョブが失敗する可能性があります。
シャッフルパフォーマンスは、CloudWatch メトリクスと Spark UI で評価できます。
CloudWatch メトリクス
[書き込み済みシャッフルバイト数] の値が [読み取り済みシャッフルバイト数] よりも大きい場合、Spark ジョブで join()や groupByKey() などのシャッフルオペレーション
![シャッフル書き込みバイトのスパイクを示す [エグゼキュター間のデータシャッフル (バイト)] グラフ。](images/data-shuffle-across-executors.png)
Spark UI
Spark UI の [ステージ] タブで、[シャッフル読み取りサイズ/レコード数] の値を確認できます。[エグゼキュター] タブでも確認できます。
次のスクリーンショットでは、各エグゼキュターが約 18.6 GB/4020000 件のレコードをシャッフルプロセスとやり取りしており、合計のシャッフル読み取りサイズは約 75 GB になります。
[シャッフルスピル (ディスク)] 列には、大量のメモリスピルデータがディスクに書き込まれていることが示されており、ディスクのスペース不足やパフォーマンスの問題を引き起こす可能性があります。

これらの症状が見られ、ステージの処理がパフォーマンス目標と比べて時間がかかりすぎる場合、または Out Of Memory や No space
left on device エラーで失敗する場合は、次の解決策を検討してください。
結合を最適化する
テーブルを結合する join() オペレーションは、最も一般的に使用されるシャッフルオペレーションですが、多くの場合、パフォーマンスのボトルネックになります。結合はコストのかかるオペレーションであるため、ビジネス要件に不可欠でない限り、使用しないことをお勧めします。データパイプラインを効率的に使用できているか、次の質問で再確認します。
-
他のジョブでも実行され、再利用できる結合を再計算していませんか?
-
出力のコンシューマーが使用しない値を取得するためだけに、外部キーを解決する結合をしていませんか?
結合オペレーションがビジネス要件に不可欠であることを確認したら、要件を満たす方法で結合を最適化するための以下のオプションを検討してください。
結合前にプッシュダウンを使用する
結合を実行する前に、DataFrame 内の不要な行と列を除外します。これには以下の利点があります。
-
シャッフル中のデータ転送量が削減される
-
Spark エグゼキュターでの処理量が削減される
-
データスキャン量が削減される
# Default df_joined = df1.join(df2, ["product_id"]) # Use Pushdown df1_select = df1.select("product_id","product_title","star_rating").filter(col("star_rating")>=4.0) df2_select = df2.select("product_id","category_id") df_joined = df1_select.join(df2_select, ["product_id"])
DataFrame 結合を使用する
RDD API や DynamicFrame の結合ではなく、SparkSQL、DataFrame、Datasets などの Spark 高レベル APIdyf.toDF() などのメソッド呼び出しを使用して、DynamicFrame を DataFrame に変換できます。「Key topics in Apache Spark」セクションで説明したように、これらの結合オペレーションは、Catalyst オプティマイザによるクエリ最適化を内部的に活用しています。
シャッフル結合とブロードキャストハッシュ結合、およびヒントの活用
Spark は、シャッフル結合とブロードキャストハッシュ結合の 2 種類の結合をサポートしています。ブロードキャストハッシュ結合ではシャッフルが不要となり、シャッフル結合よりも処理量を抑えられる場合があります。ただし、これは小さいテーブルを大きなテーブルに結合する場合にのみ適用できます。単一の Spark エグゼキュターのメモリに収まるテーブルを結合する場合は、ブロードキャストハッシュ結合の使用を検討してください。
次の図は、ブロードキャストハッシュ結合とシャッフル結合の全体構造とステップを示しています。
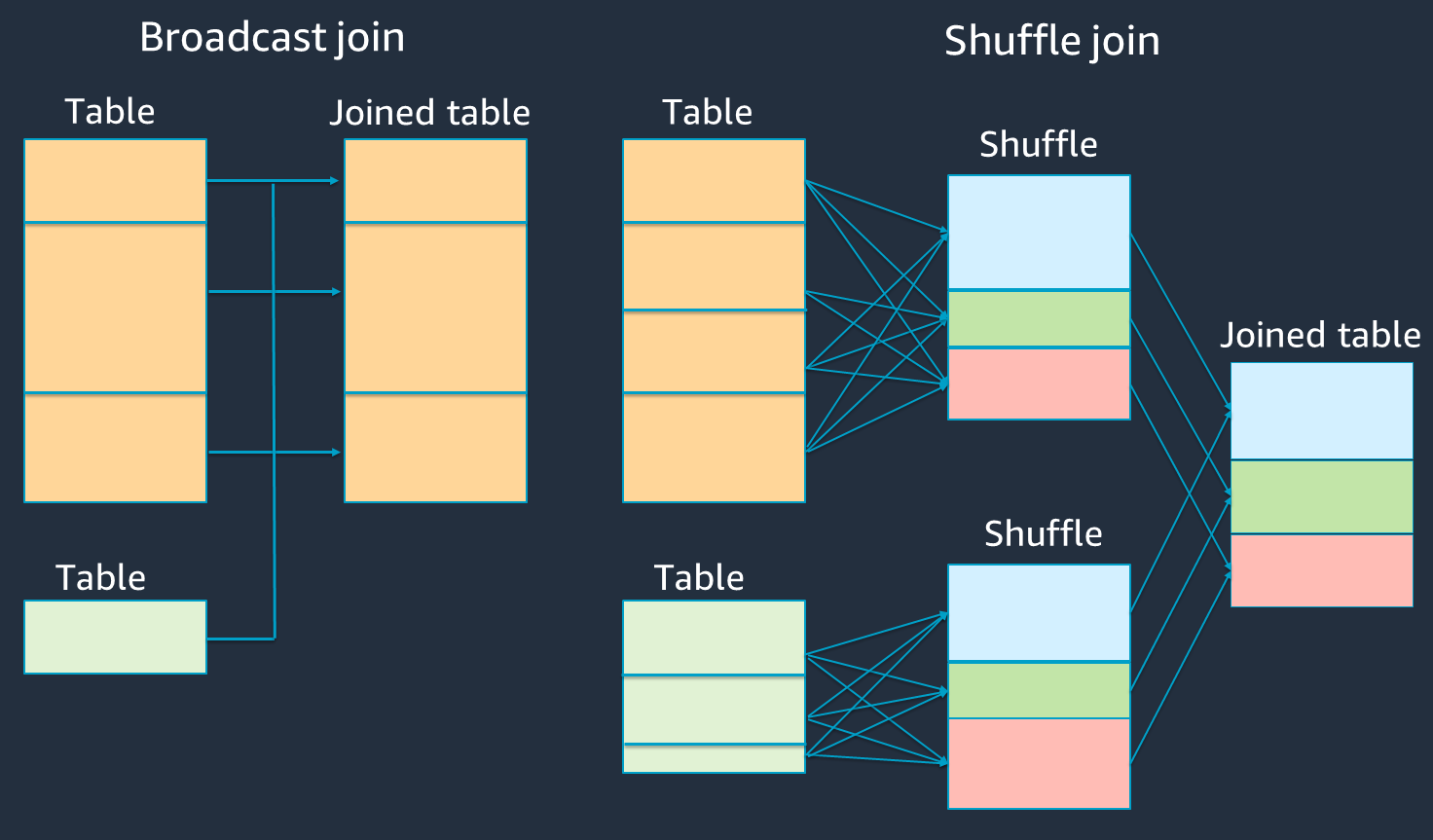
各結合の詳細は次のとおりです。
-
シャッフル結合:
-
シャッフルハッシュ結合は、ソートせずに 2 つのテーブルを結合し、2 つのテーブル間に結合を分散します。Spark エグゼキュターのメモリに収まる小規模なテーブルの結合に適しています。
-
ソートマージ結合は、結合する 2 つのテーブルをキーで分散し、結合する前にソートします。大規模なテーブルの結合に適しています。
-
-
ブロードキャストハッシュ結合:
-
ブロードキャストハッシュ結合は、小さい RDD またはテーブルを各ワーカーノードに送信し、続いて大きな RDD またはテーブルの各パーティションとマップ側で結合します。
RDD またはテーブルの一方がメモリに収まる場合、またはメモリに収まるように調整できる場合の結合に適しています。シャッフルが不要になるため、可能な場合はブロードキャストハッシュ結合を使用することが有益です。結合ヒントを使用すると、次のように Spark にブロードキャスト結合を要求できます。
# DataFrame from pySpark.sql.functions import broadcast df_joined= df_big.join(broadcast(df_small), right_df[key] == left_df[key], how='inner') -- SparkSQL SELECT /*+ BROADCAST(t1) / FROM t1 INNER JOIN t2 ON t1.key = t2.key;結合ヒントの詳細については、「結合ヒント
」を参照してください。
-
AWS Glue 3.0 以降では、アダプティブクエリ実行
AWS Glue 3.0 では、 を設定することで Adaptive Query Execution を有効にできますspark.sql.adaptive.enabled=true。AWS Glue 4.0 では、アダプティブクエリ実行がデフォルトで有効になっています。
シャッフル結合とブロードキャストハッシュ結合に関連する、以下の追加パラメータを設定できます。
-
spark.sql.adaptive.localShuffleReader.enabled -
spark.sql.adaptive.autoBroadcastJoinThreshold
関連パラメータの詳細については、「ソートマージ結合のブロードキャスト結合への変換
AWS Glue 3.0 以降では、シャッフルに他の結合ヒントを使用して動作を調整できます。
-- Join Hints for shuffle sort merge join SELECT /*+ SHUFFLE_MERGE(t1) / FROM t1 INNER JOIN t2 ON t1.key = t2.key; SELECT /*+ MERGEJOIN(t2) / FROM t1 INNER JOIN t2 ON t1.key = t2.key; SELECT /*+ MERGE(t1) / FROM t1 INNER JOIN t2 ON t1.key = t2.key; -- Join Hints for shuffle hash join SELECT /*+ SHUFFLE_HASH(t1) / FROM t1 INNER JOIN t2 ON t1.key = t2.key; -- Join Hints for shuffle-and-replicate nested loop join SELECT /*+ SHUFFLE_REPLICATE_NL(t1) / FROM t1 INNER JOIN t2 ON t1.key = t2.key;
バケット化を使用する
ソートマージ結合には、シャッフルとソート、そしてマージという 2 つのフェーズが必要です。これらの 2 つのフェーズでは、一部のエグゼキュターがマージを実行し、他のエグゼキュターが同時にソートを行っていると、Spark エグゼキュターが過負荷となり、OOM やパフォーマンスの問題が発生する可能性があります。このような場合には、バケット化
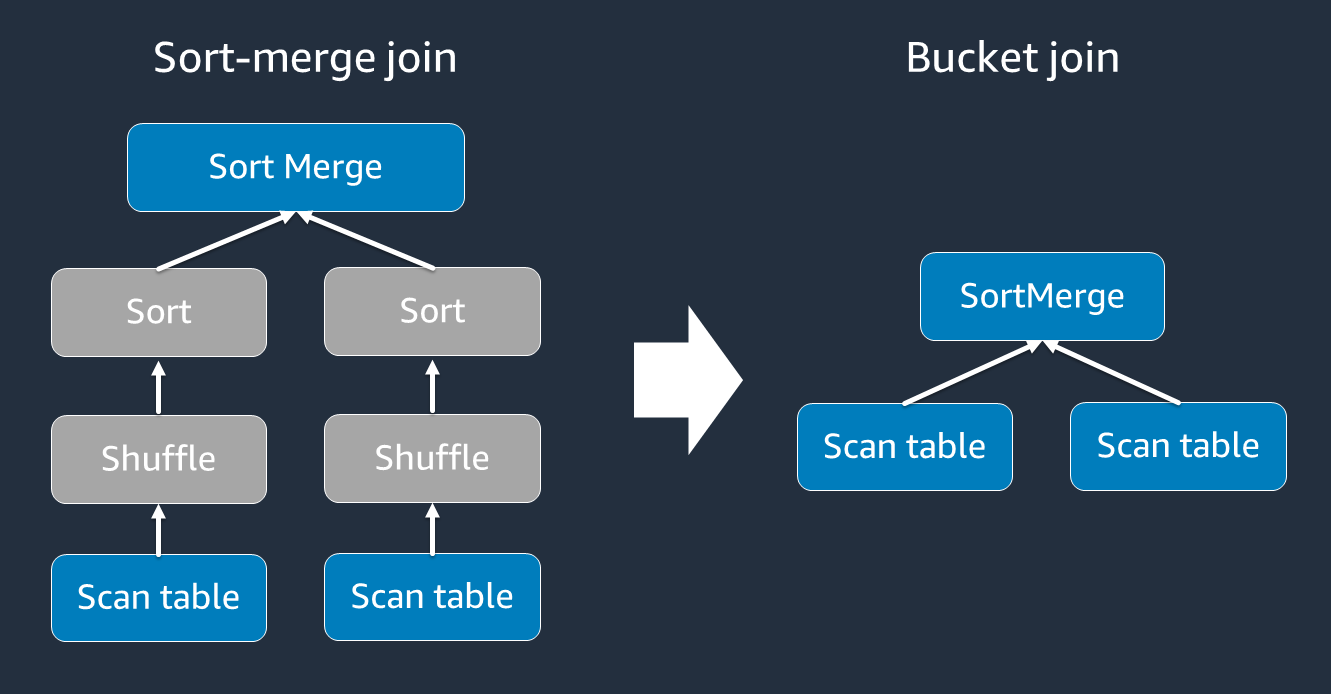
バケットテーブルは、次の場合に便利です。
-
account_idなど、同じキーで頻繁に結合されるデータ -
共通の列でバケット化できるベーステーブルやデルタテーブルなど、日次の累積テーブルをロードする場合
バケットテーブルを作成するには、次のコードを使用します。
df.write.bucketBy(50, "account_id").sortBy("age").saveAsTable("bucketed_table")
結合前に、結合キーで DataFrames を再パーティションする
結合前に 2 つの DataFrame を結合キーで再パーティションするには、次のステートメントを使用します。
df1_repartitioned = df1.repartition(N,"join_key") df2_repartitioned = df2.repartition(N,"join_key") df_joined = df1_repartitioned.join(df2_repartitioned,"product_id")
これにより、結合を開始する前に、2 つの (まだ分離された) RDD を結合キーでパーティションします。2 つの RDD が同じキーで同じパーティションコードを用いてパーティションされている場合、結合する予定の RDD レコードは、結合のためのシャッフルが行われる前に、同じワーカー上に配置される可能性が高くなります。これにより、結合時のネットワークアクティビティとデータスキューが減少し、パフォーマンスが向上する可能性があります。
データスキューを克服する
データスキューは、Spark ジョブのボトルネックとして最も一般的な原因の 1 つです。これは、データが RDD のパーティション間で均等に分散されていない場合に発生します。これにより、そのパーティションのタスクに他のタスクよりもはるかに長い時間がかかり、アプリケーション全体の処理時間に遅延が生じます。
データスキューを特定するには、Spark UI で次のメトリクスを評価します。
-
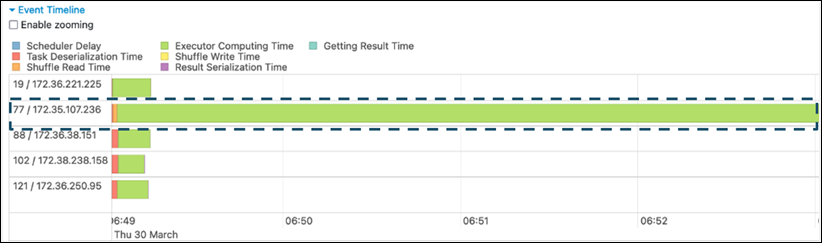
Spark UI の [ステージ] タブで、[イベントタイムライン] ページを確認します。次のスクリーンショットでは、タスクが不均等に分布している様子が示されています。不均等に分布しているタスクや、実行に時間がかかりすぎているタスクは、データスキューの兆候である可能性があります。
-
もう 1 つの重要なページは、Spark タスクの統計を表示する [概要メトリクス] です。次のスクリーンショットには、[時間]、[GC 時間]、[スピル (メモリ)]、[スピル (ディスク)] などのパーセンタイルメトリクスが示されています。
![[時間] 行が強調表示された [概要メトリクス] テーブル。](images/summary-metrics.png)
タスクが均等に分散されると、すべてのパーセンタイルで類似した数値が表示されます。データスキューがある場合は、各パーセンタイルに大きく偏った値が表示されます。この例では、タスクの処理時間は [最小値]、[25 パーセンタイル]、[中央値]、[75 パーセンタイル] で 13 秒未満です。一方、[最大値] のタスクは [75 パーセンタイル] の 100 倍のデータを処理しており、その処理時間は 6.4 分で、約 30 倍の長さになります。つまり、少なくとも 1 件のタスク (またはタスクの最大 25%) が、残りのタスクよりもはるかに長い時間を要したことになります。
データスキューが見られる場合は、以下を試してください。
-
AWS Glue 3.0 を使用する場合は、 を設定して Adaptive Query Execution を有効にします
spark.sql.adaptive.enabled=true。アダプティブクエリの実行は、デフォルトで AWS Glue 4.0 で有効になっています。結合によって発生するデータスキューにも、次の関連パラメータを設定することで、アダプティブクエリ実行を使用できます。
-
spark.sql.adaptive.skewJoin.skewedPartitionFactor -
spark.sql.adaptive.skewJoin.skewedPartitionThresholdInBytes -
spark.sql.adaptive.advisoryPartitionSizeInBytes=128m (128 mebibytes or larger should be good) -
spark.sql.adaptive.coalescePartitions.enabled=true (when you want to coalesce partitions)
詳細については、Apache Spark のドキュメント
を参照してください。 -
-
結合キーには、値の範囲が広いキーを使用します。シャッフル結合では、パーティションはキーのハッシュ値ごとに決定されます。結合キーのカーディナリティが低すぎる場合、ハッシュ関数がデータをパーティション間で均等に分散できない可能性が高くなります。そのため、アプリケーションやビジネスロジックでサポートされている場合は、よりカーディナリティの高いキー、または複合キーを使用することを検討してください。
# Use Single Primary Key df_joined = df1_select.join(df2_select, ["primary_key"]) # Use Composite Key df_joined = df1_select.join(df2_select, ["primary_key","secondary_key"])
キャッシュを使用する
繰り返し使用する DataFrames では、df.cache() または df.persist() を使用して、各 Spark エグゼキュターのメモリとディスクに計算結果をキャッシュすることで、追加のシャッフルや計算を回避します。Spark では、RDD をディスクに永続化したり、複数のノードにレプリケートしたりすること (ストレージレベル
例えば、df.persist() を追加することで DataFrames を永続化できます。キャッシュが不要になった場合は、unpersist を使用してキャッシュされたデータを破棄できます。
df = spark.read.parquet("s3://<Bucket>/parquet/product_category=Books/") df_high_rate = df.filter(col("star_rating")>=4.0) df_high_rate.persist() df_joined1 = df_high_rate.join(<Table1>, ["key"]) df_joined2 = df_high_rate.join(<Table2>, ["key"]) df_joined3 = df_high_rate.join(<Table3>, ["key"]) ... df_high_rate.unpersist()
不要な Spark アクションを削除する
count、show、collect などの不要なアクションは実行しないでください。「Key topics in Apache Spark」セクションで説明したように、Spark は遅延評価を採用しており、変換された各 RDD は、アクションを実行するたびに再計算される可能性があります。多くの Spark アクションを使用すると、アクションごとに複数のソースアクセス、タスク計算、シャッフル実行が呼び出されます。
商用環境で collect() やその他のアクションが不要な場合は、それらを削除することを検討してください。
注記
商用環境では、Spark の collect() をできるだけ使用しないでください。collect() アクションは、Spark エグゼキュターでのすべての計算結果を Spark ドライバーに返すため、Spark ドライバーで OOM エラーが発生する可能性があります。OOM エラーを回避するため、Spark では spark.driver.maxResultSize = 1GB がデフォルトで設定されており、Spark ドライバーに返されるデータサイズは最大 1 GB に制限されています。
