翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
AWS Glue を使用してデータをエクスポートする
MySQL データは、ビッグデータシナリオ向けサーバーレス分析サービス、AWS Glue を使用して、Amazon S3 にアーカイブできます。AWS Glue では、Apache Spark が活用されます。Apache Spark は、広く利用されている分散クラスターコンピューティングフレームワークであり、さまざまなデータベースソースに対応しています。
データベースから Amazon S3 へのアーカイブデータオフロードは、AWS Glue ジョブのコードを数行記述するだけで実行できます。AWS Glue の最大の利点は、水平方向のスケーラビリティと従量制料金モデルであり、これにより、運用の効率化とコストの最適化を実現できます。
次の図は、データベースアーカイブの基本的なアーキテクチャを示しています。
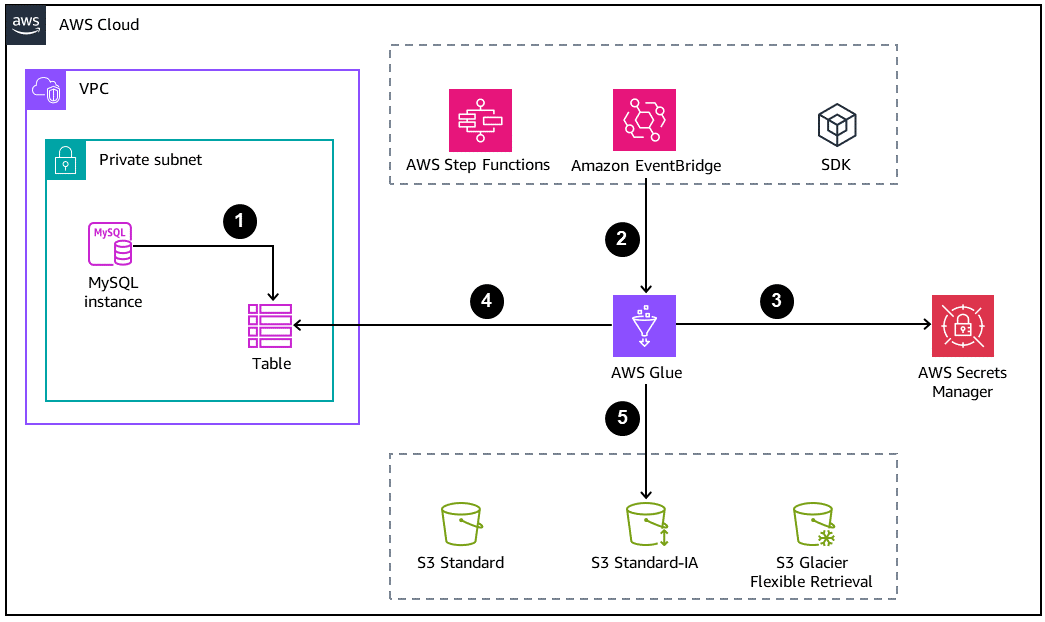
-
MySQL データベースで、Amazon S3 にオフロードするアーカイブまたはバックアップテーブルを作成します。
-
AWS Glue ジョブは、次のいずれかの方法で開始します。
-
AWS Step Functions ステートマシン内のステップとして同期的に開始
-
Amazon EventBridge イベントによって非同期的に開始
-
AWS CLI または AWS SDK を使用した手動リクエストによって開始
-
-
DB 認証情報は AWS Secrets Manager から取得します。
-
AWS Glue ジョブでは、Java Database Connectivity (JDBC) 接続を使用してデータベースにアクセスし、テーブルを読み込みます。
-
AWS Glue により、Amazon S3 に Parquet 形式でデータが書き込まれます。Parquet は、列指向で省スペースのオープンデータ形式です。
AWS Glue ジョブを設定する
AWS Glue ジョブを意図したとおりに動作させるには、以下のコンポーネントと設定が必要です。
-
AWS Glue 接続 – AWS Glue データカタログオブジェクトであり、これを、データベースにアクセスするジョブにアタッチします。ジョブは、複数のデータベースを呼び出すために複数の接続を持つことができます。この接続オブジェクトには、安全に保存されたデータベース認証情報が含まれています。
-
GlueContext – SparkContext
上のカスタムラッパー。GlueContext クラスでは高次の API オペレーションが可能で、これにより、Amazon S3 およびデータベースソースとやり取りを行えます。これが、データカタログとの統合を可能にします。また、データベース接続 (Glue 接続内で処理される) に使用するドライバーへの依存もなくなります。さらに、GlueContext クラスには、元の SparkContext クラスでは不可能な Amazon S3 API オペレーション処理の方法が用意されています。 -
IAM ポリシーとロール – AWS Glue では、他の AWS サービスとのやり取りが生じるため、最小特権を使用して、適切なロールを設定しなければなりません。以下のようなサービスには、AWS Glue とやり取りするために適切なアクセス許可が必要です。
-
Amazon S3
-
AWS Secrets Manager
-
AWS Key Management Service (AWS KMS)
-
ベストプラクティス
-
オフロード対象の行が多数あるテーブルを全体的に読み取る場合は、リードレプリカエンドポイントの使用をお勧めします。これにより、メインのライターインスタンスのパフォーマンスを低下させずに、読み取りスループットを向上させることができます。
-
ジョブ処理に必要なノード数の使用を効率化するには、AWS Glue 3.0 で自動スケーリングを有効にします。
-
S3 バケットがデータレイクアーキテクチャの一部である場合は、データを物理パーティションに移動して整理しオフロードすると良いでしょう。パーティションスキームは、アクセスパターンに基づいて設計する必要があります。日付値に基づくパーティション化は、最も推奨されるプラクティスの 1 つです。
-
Parquet や Optimized Row Columnar (ORC) などのオープン形式でデータを保存すると、Amazon Athena や Amazon Redshift といった他の分析サービスで、そうしたデータを利用しやすくなります。
-
オフロードしたデータを、他の分散サービスで、読み取りに最適化された状態にするには、出力ファイルの数を制御する必要があります。ほとんどの場合、小さいファイルの数を増やさず、大きいファイルの数を減らすと、効果的です。Spark には、パートファイルの生成を制御する設定ファイルおよびメソッドが組み込まれています。
-
アーカイブデータとは、定義上、頻繁にアクセスされるデータセットを指します。ストレージコストの効率化を実現するには、Amazon S3 クラスをより安価な階層に移行する必要があります。これを行うには、次の 2 つのアプローチを取ると良いでしょう。
-
オフロードと同時に (同期的に) 階層を移行する – オフロードしたデータをプロセスの一部として移行する必要があると確認済みの場合は、Amazon S3 にデータを書き込む AWS Glue ジョブと同じジョブ内で GlueContext メカニズム transition_s3_path を使用できます。
-
S3 ライフサイクルを使用して非同期的に移行する – Amazon S3 ストレージクラスの移行および有効期限に使用する適切なパラメータで S3 ライフサイクルルールを設定します。これをバケットに設定すると、設定は永遠に保持されます。
-
-
データベースがデプロイされている 仮想プライベートクラウド (VPC) 内に、十分な IP アドレス範囲
を持つサブネットを作成し、設定します。これにより、多数のデータ処理ユニット (DPU) が設定されているときに、不十分なネットワークアドレス数が原因で生じる AWS Glue ジョブの失敗を回避できます。
