翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
Connect Customer で顧客セグメントを構築する
注記
SQL (ベータ) を使用したセグメンテーションでは、データストアを有効にする必要があります。Customer Profiles のホームページ画面にアクセスし、上部の青いバナーからデータストアを有効にしてください。
注記
-
Connect Customer 管理ウェブサイトのセグメンテーションビルダーエクスペリエンスに移動するには、この機能のセキュリティプロファイルのアクセス許可が必要です。詳細については、「顧客セグメントを管理するためのセキュリティプロファイルのアクセス許可を割り当てる」を参照してください。
-
セグメントを構築する前に、Customer Profiles ドメインの設定データ統合を使用して Customer Profiles ドメインにプロファイルを入力することをお勧めします。Customer Profiles とのデータ統合の設定方法の詳細については、「外部アプリケーションを Connect Customer Profiles と統合する」を参照してください。
-
セグメントには、計算属性を使用してキャプチャしたイベントを含めることができます。カスタム計算属性を設定し、Customer Profiles が提供するデフォルトの計算属性を確認する方法の詳細については、「Connect Customer Profiles で計算属性を設定する」を参照してください。
Connect Customer には、顧客セグメントを構築する 2 つの方法があります。1/ Spark SQL を使用してセグメントを定義する (ベータ、データストアを有効にする必要があります)、2/ オーディエンスグループとフィルターを使用してセグメントを定義する (Classic Segmentation)。どちらの場合も、生成 AI を活用したセグメント AI アシスタントを介して自然言語プロンプトを使用できます。いずれかの方法でセグメントを定義する場合は、そのセグメントを別のセグメントに移動し、再度開始する必要があります。
オーディエンスグループとフィルターを使用した従来のセグメンテーション
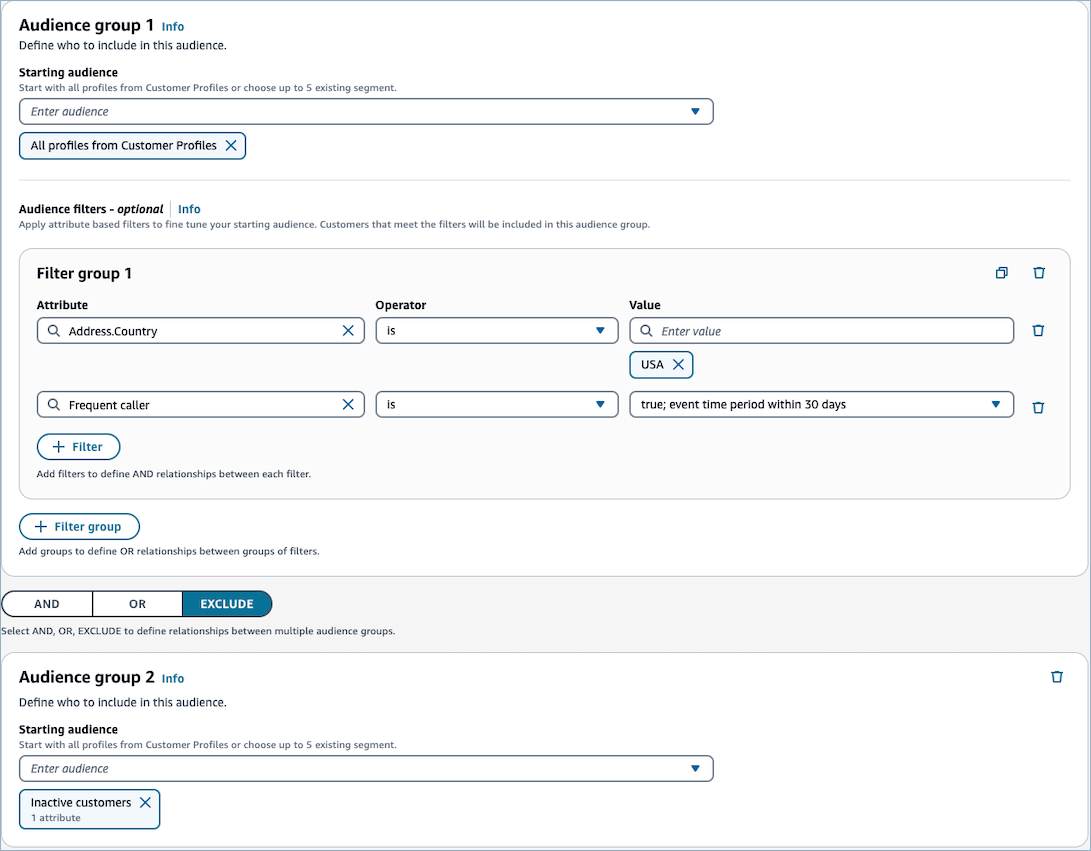
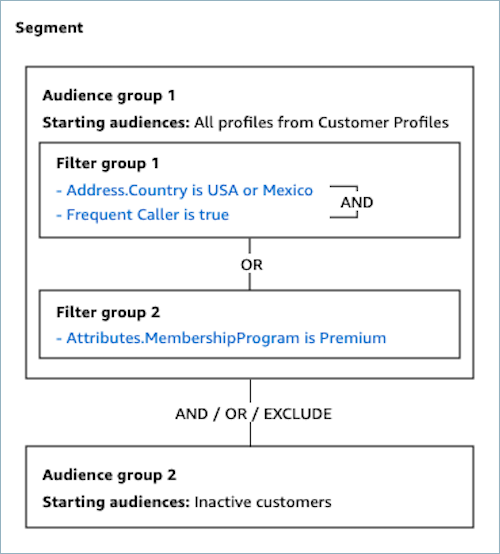
顧客セグメントを作成する際は、初期オーディエンスを選択し、セグメントを定義するフィルターを選択してそのオーディエンスを絞り込みます。例えば、オーディエンスグループを作成し、特定の国に住んでいて、頻繁に電話をかけるすべての顧客のフィルターを選択できます。セグメントは、キャンペーンの実行時、コンタクトフローの実行時、セグメントの見積りまたはエクスポート時など、オンデマンドで再計算されます。そのため、各セグメントのサイズやメンバーシップは、時間の経過とともに変化します。
さらに、2 番目のオーディエンスグループを作成し、2 つのオーディエンスグループ間の関係 (AND、OR、または EXCLUDE) を作成して、最初のオーディエンスグループから顧客をさらに絞り込んだり、連結したり、除外したりできます。
オーディエンスグループ
顧客セグメントを作成する際は、1 つまたは複数のオーディエンスグループを作成します。オーディエンスグループは、以下のコンポーネントで構成されます。
-
初期オーディエンス: 初期のユーザー母集団を定義する顧客セグメント。最大 5 つの初期オーディエンス、または Customer Profiles ドメイン内のすべてのプロファイルを指定できます。
-
フィルターグループ: 初期オーディエンスに適用するオーディエンス情報のカテゴリ。OR 関係によって接続された複数のフィルターグループを追加できます。
-
フィルター – フィルターは、セグメントに属するオーディエンスの数を減らします。必要に応じてセグメントを調整するフィルターをいくつでも追加できます。
顧客セグメントには 1 つ以上のオーディエンスグループが必要ですが、オプションで 2 番目のオーディエンスグループを作成し、2 つのオーディエンスグループ間の関係 (AND/OR/EXCLUDE) を作成できます。関係の詳細については、「ステップ 5: 2 番目のオーディエンスグループを追加する (オプション)」を参照してください。
顧客セグメントの作成
以下の手順では、顧客セグメントの作成と設定について説明します。
-
ステップ 1: 新しいセグメントを構築する
-
ステップ 2: 名前と説明を設定する
-
ステップ 3: オーディエンスグループ 1 に含める初期オーディエンスを選択する
-
ステップ 4: フィルターグループを選択して設定する (オプション)
-
ステップ 5: オーディエンスグループ 2 を追加する (オプション)
-
ステップ 6: ソートを有効にする (オプション)
ステップ 1: 新しいセグメントを構築する
-
セグメントを作成するには、前提条件としてセキュリティプロファイルのアクセス許可を作成していることを確認します。詳細については、「顧客セグメントを管理するためのセキュリティプロファイルのアクセス許可を割り当てる」を参照してください。さらに、セグメントのメンバーシップを最もよく視覚化するには、セグメントの作成前にデータを取り込むことをお勧めします。S3 または外部アプリケーションを介してプロファイルを取り込むには、「顧客データを作成して、Customer Profiles に取り込む」または「外部アプリケーションを Connect Customer Profiles と統合する」を参照してください。
-
顧客セグメントのテーブルビューで [セグメントを作成する] を選択します。
ステップ 2: 名前と説明を指定する
-
[名前] に、後で判別しやすいような顧客セグメント名を入力します。
注記
Connect Customer 管理ウェブサイトは、入力された名前をセグメント
DisplayNameの として使用し、それに基づいて識別子を生成します。生成された識別子は、Customer Profiles API を使用してセグメントにアクセスする際にSegmentDefinitionNameとして使用されます。 -
オプションで、顧客セグメントの説明を [説明] に入力します。

ステップ 3: オーディエンスグループ 1 に含める初期オーディエンスを選択する
まず、オーディエンスグループの初期オーディエンスをどのように定義するかを選択します。
-
[オーディエンスグループ 1] の [オーディエンスグループ 1] ドロップダウンリストで、オーディエンスグループに含める 1 つまたは複数のセグメントを選択するか、[Customer Profiles のすべてのプロファイル] を選択します。
注記
初期オーディエンスとして複数のセグメントを選択すると、セグメントは
OR関係によって接続されます。例えば、[Premium メンバーシップの顧客] セグメントおよび [Basic メンバーシップの顧客] セグメントを初期オーディエンスとして選択すると、いずれかのセグメントに含まれるすべてのプロファイルが含まれます。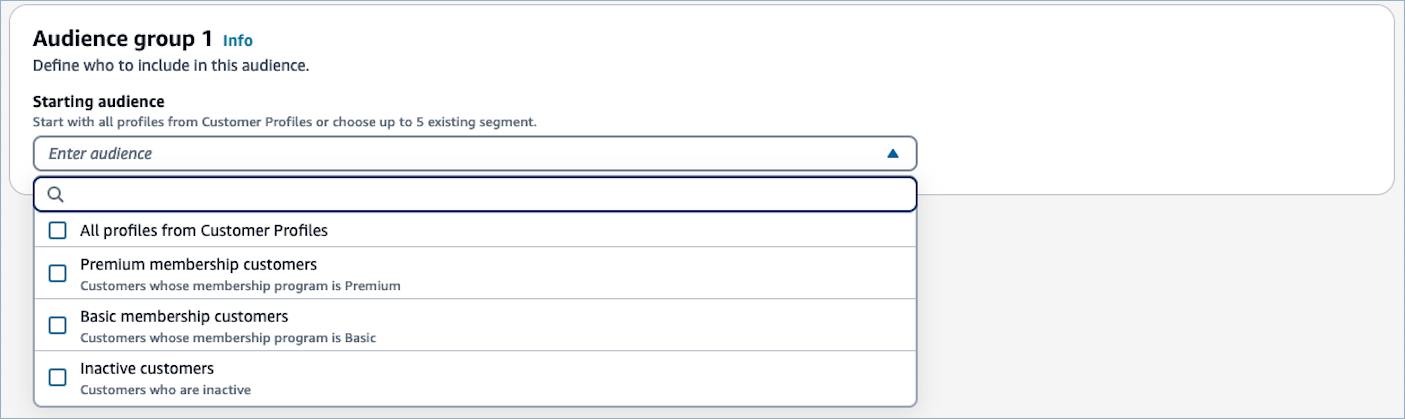
-
ProfileType でセグメントを作成するには、まず [Customer Profiles のすべてのプロファイル] を初期オーディエンスとして使用します。このアプローチにより、アカウントベースのプロファイルを効果的にフィルタリングできます。特に指定しない限り、セグメントテーションプロセスは Customer Profiles ドメイン内のすべてのプロファイルを自動的にエクスポートすることに注意してください。このデフォルトの動作により、包括的なカバレッジが保証されますが、特定のターゲットニーズに合わせて調整できます。
以下は、セグメント定義の作成方法の例です (アカウントベースまたは標準プロファイルベース)。
すべてのアカウントベースのプロファイルをフィルタリングします (ProfileType=ACCOUNT_PROFILE)。
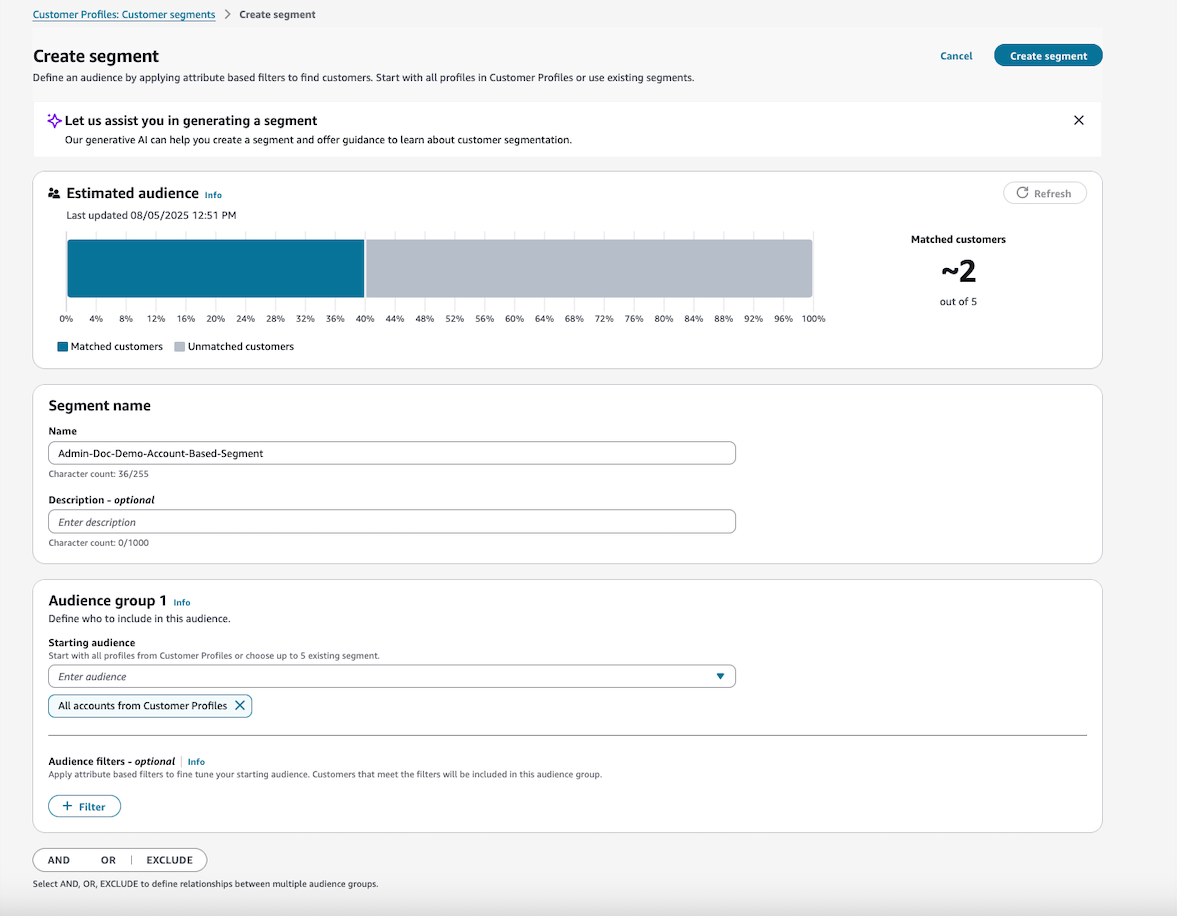
注記
サブプロファイルのみを使用してセグメントを作成するには、アカウントベースのプロファイルを除外する新しいオーディエンスを作成します。例えば、
ProfileTypeを含むプロファイルは PROFILE でProfileTypeは空です。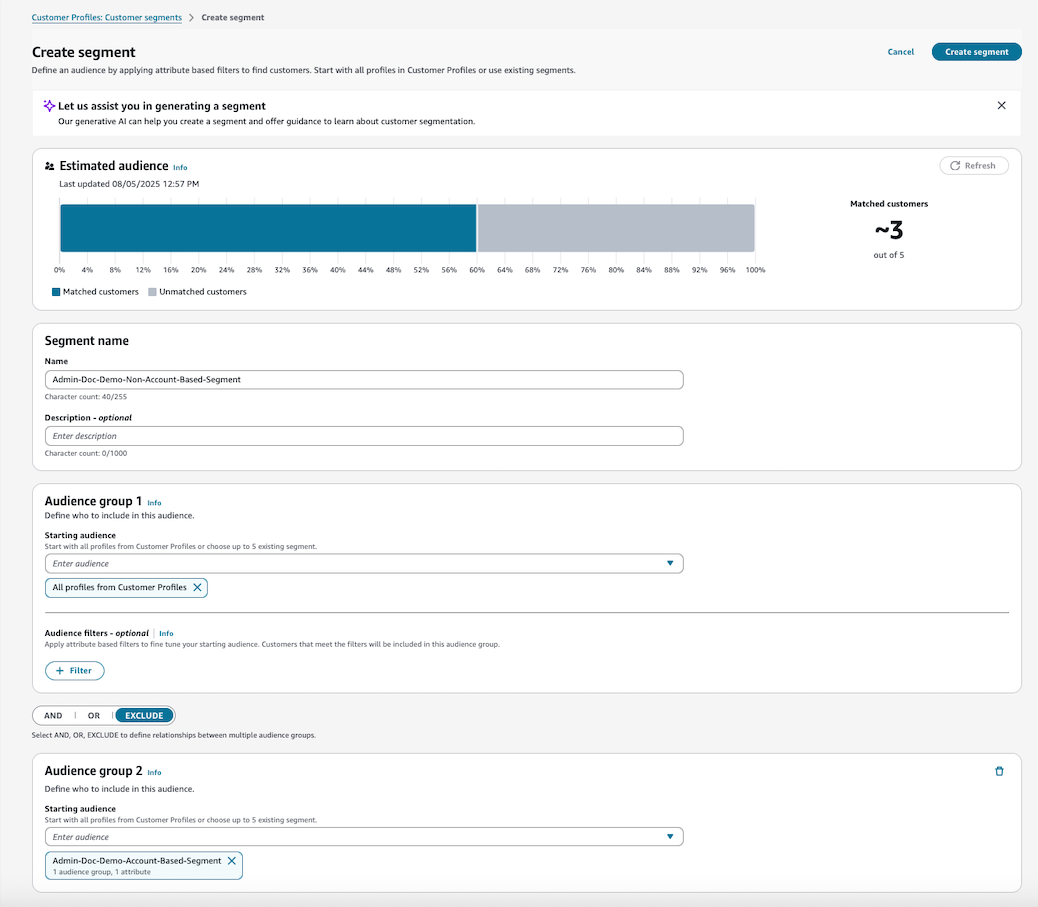
Phoneを使用してリーチするアカウントをターゲットとするキャンペーンの例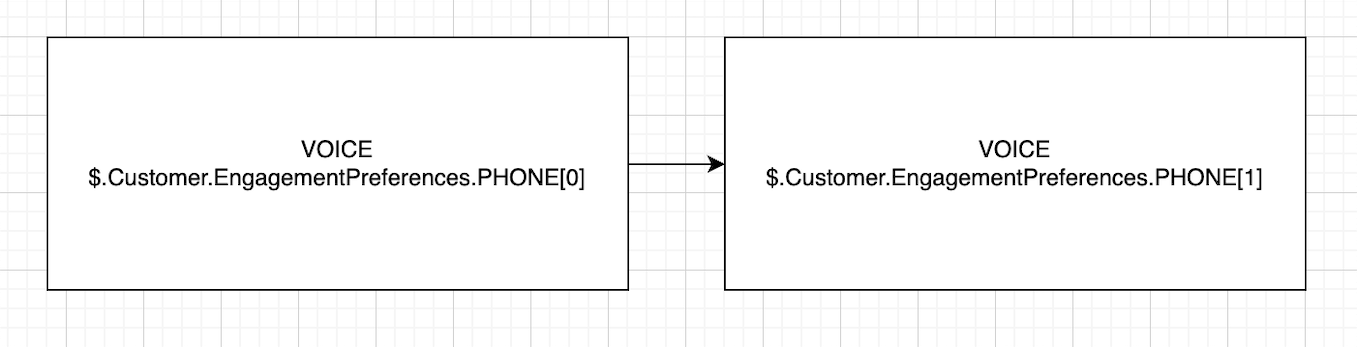
この例では、キャンペーンは次の呼び出しシーケンスを持つ単一のアカウントを対象としています。
-
John にリーチする最初の試み (ID: 2)
-
John が応答しない場合、バックアップ連絡先として Sally (ID: 3) を呼び出します。
-
-
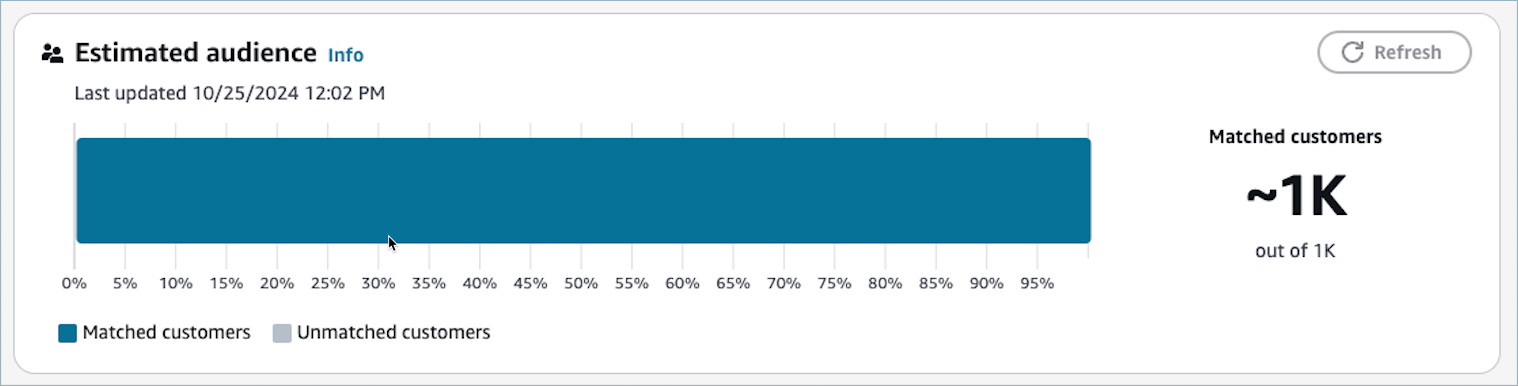
初期オーディエンスを選択すると、[推定オーディエンス] セクションが更新され、対象となるプロファイルが表示されます。対象者グループを編集したら、推定対象者セクション の更新ボタンを選択して見積りを再取得できます。
ステップ 4: オーディエンスフィルターを選択して適用する (オプション)
初期オーディエンスを選択したら、条件付きロジックを属性に適用することでオーディエンスをさらに絞り込むことができます。セグメントは、標準プロファイル属性、カスタムプロファイル属性、計算属性をサポートします。
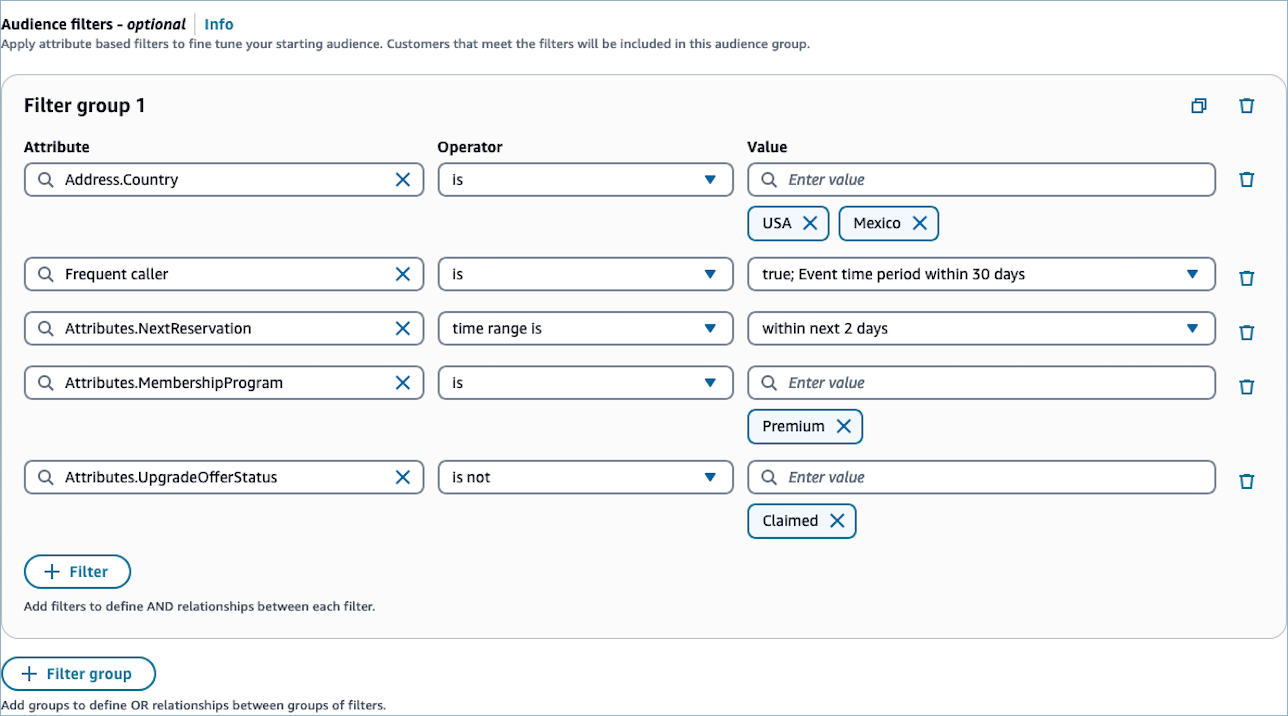
オーディエンスフィルターを選択して設定するには、次の手順を実行します。
-
[属性] では、以下のタイプの属性を選択できます。
-
計算属性 - 計算属性のいずれかに基づいてオーディエンスをフィルタリングします。
デフォルトの計算属性、およびカスタム計算属性の設定方法については、「Connect Customer Profiles で計算属性を設定する」を参照してください。
-
標準属性 — 標準プロファイル属性のいずれかに基づいてオーディエンスをフィルタリングします。
標準プロファイル属性の一覧については、「Connect Customer Profiles の標準プロファイル定義」を参照してください。
-
カスタム属性 — カスタムプロファイル属性のいずれかに基づいてオーディエンスをフィルタリングします。
注記
ドメイン内には、最新のプロファイル属性を最大 1000 個保存できます。ドメインに大量の属性が含まれている場合、最も古い属性がこの一覧に表示されない可能性があります。
-
-
[演算子] を選択します。演算子は、入力された値と属性の関係を決定します。利用できる演算子について説明します。利用可能な演算子は、選択した属性の値のタイプによって異なります。
| サポートされている属性値のタイプ | 演算子 | 説明 |
|---|---|---|
| Number | Greater than | 数値属性にのみ使用されます。この演算子は、渡された数より大きい結果をフィルタリングします。例えば、顧客の平均保留時間が 10 秒を超えている場合です。 |
| Greater than or equal | 数値属性にのみ使用されます。この演算子は、渡された数と同じか、より大きい結果をフィルタリングします。例えば、Customer’s average hold time が 10 秒以上の場合です。 | |
| Equals | 数値属性にのみ使用されます。この演算子は、同じ数値を持つオーディエンスをフィルタリングします。例えば、Customer’s average hold time が 10 秒である場合です。 | |
| Less than | 数値属性にのみ使用されます。この演算子は、渡された数より小さい結果をフィルタリングします。例えば、Customer’s average hold time が 10 秒未満の場合です。 | |
| Less than or equal | 数値属性にのみ使用されます。この演算子は、渡された数と同じか、より小さい結果をフィルタリングします。例えば、Customer’s average hold time が 10 秒以下の場合です。 | |
| String | Is | 指定した文字列に一致するオーディエンスをフィルタリングします。例えば、顧客の Address.Country が USA の場合です。 |
| Is not | 特定の文字列に一致しないオーディエンスをフィルタリングします。例えば、顧客の Address.Country が USA でない場合です。 | |
| Contains | 文字列内の部分文字列に基づいてオーディエンスをフィルタリングするために使用します。例えば、Address.Country 属性のフィルターがある場合、US を渡して US または USA を返すことができます。 | |
| Begind with | 属性が指定された文字列で始まるオーディエンスをフィルタリングします。例えば、顧客の Address.Country が US で始まる場合です。 | |
| Ends with | 属性が指定された文字列で終わるオーディエンスをフィルタリングします。例えば、顧客の EmailAddress が @amazon.com で終わる場合です。 | |
| 日付 | Before | 属性に特定の日付より前の日付値があるオーディエンスをフィルタリングします。例えば、Attributes.NextReservation が 2024/10/01 より前の顧客です。 |
| On | 属性値が特定の日付と一致するオーディエンスをフィルタリングします。例えば、Attributes.NextReservation が 2024/10/01 である顧客です。 | |
| After | 属性に特定の日付より後の日付値があるオーディエンスをフィルタリングします。例えば、Attributes.NextReservation が 2024/10/01 より後である顧客です。 | |
| Time range is | 属性の日付値が特定の時間範囲にあるオーディエンスをフィルタリングします。時間範囲は、絶対時間モードまたは相対時間モードで指定できます。 | |
| 絶対時間モード: 絶対時間範囲を指定できます。例えば、2024/10/01 午前 0 時 ~ 2024/10/07 午前 0 時です。 | ||
| 相対時間モード: 将来または過去の X 時間、X 日、X 週、X 月、または X 年を相対時間範囲として指定できます。 - 将来の時間方向: 属性の日付値が現在から指定された将来の時間の間であるオーディエンスをフィルタリングします。例えば、今後 2 日以内です。 - 過去の時間方向: 属性の日付値が指定された過去の時間から現在の間であるオーディエンスをフィルタリングします。例えば、過去 2 日以内です。 | ||
| Time range is not | 属性の日付値が特定の時間範囲にないオーディエンスをフィルタリングします。時間範囲は、絶対時間モードまたは相対時間モードで指定できます。詳細については、この表の「Time range is」演算子を参照してください。 |
注記
Connect Customer 管理ウェブサイトの顧客セグメントは、すべての時間ベースのフィルターに UTC タイムゾーンとデフォルトの時刻 00:00:00 UTC を使用します。日付でフィルタリングできますが、時刻は同じ値として記録されます。2024-01-01 と日付を入力すると、コンソールは 2024-01-01T00:00:00Z として時刻を渡します。
注記
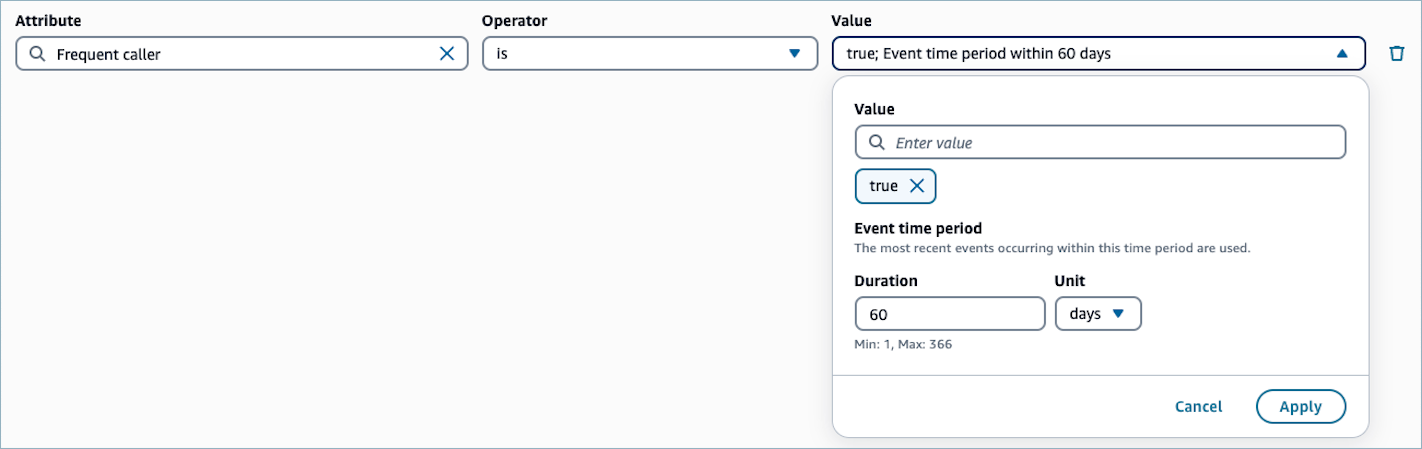
計算属性のフィルターを指定すると、計算属性定義の期間を上書きできます。例えば、フィルター Frequent caller is true for the event time period of 60
days は 頻繁な発信者 Connect Customer Profiles のデフォルトの計算属性 を上書きして、計算属性定義で設定された期間ではなく、過去 60 日間の値を評価することができます。この上書きはセグメントに固有であり、計算属性定義自体には影響しません。
-
値を指定します。
OR関係によって接続された複数の値を指定できます。例えば、Address.CountryはUSAまたはMexicoです。値の入力では、ドメインに保存されている顧客プロファイルに基づいて文字列演算子の候補がドロップダウンに表示されます。注記
値は大文字と小文字が区別されます。例えば、Address.Country is US は Address.Country is us とは異なる結果を返します。
-
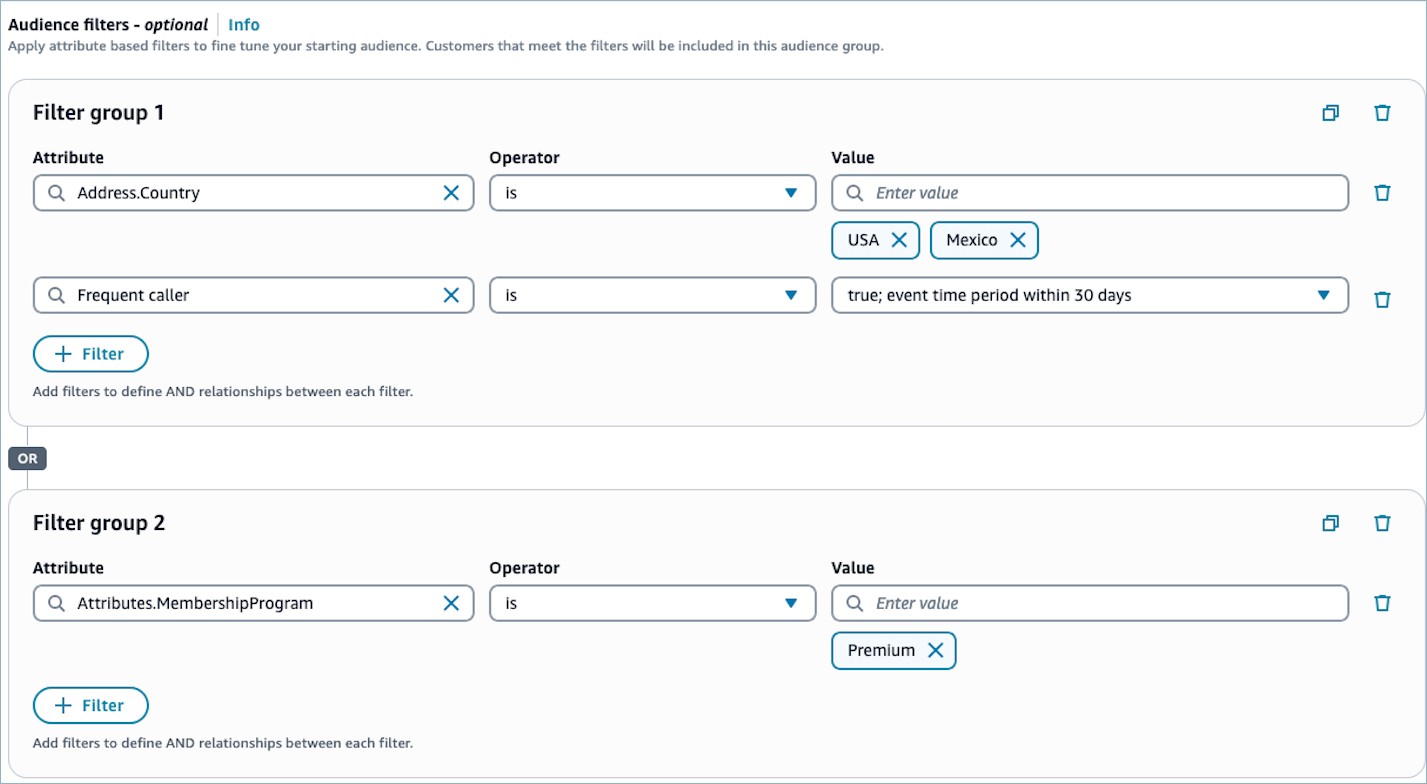
(オプション) このフィルターグループに追加の属性を適用するには、[+ フィルター] を選択します。フィルターの別のグループを作成するには、[+グループ] を選択します。
注記
フィルターグループに複数のフィルターがある場合、フィルターは AND 関係によって接続されます。例えば、「Address.Country is USA」と「Customer’s average hold time is more than 10 seconds」の 2 つのフィルターを含むフィルターグループの場合、Address.Country が USA で、かつ平均保留時間が 10 秒を超えるプロファイルはセグメントに含まれます。
オーディエンスグループに複数のフィルターグループがある場合、管理ウェブサイトの顧客セグメントは OR Connect Customer 関係を使用してフィルターグループ間を接続します。
-
オーディエンスグループのセットアップが完了したら、[セグメントを作成] を選択します。
ステップ 5: 2 番目のオーディエンスグループを追加する (オプション)
必要に応じて、2 番目のオーディエンスグループを追加し、オーディエンスグループ 1 との関係を定義します。Connect Customer 管理ウェブサイトを使用して顧客セグメントを作成する場合、各セグメントは最大 2 つのオーディエンスグループを持つことができます。セグメントに 2 つ目のオーディエンスグループを追加する場合、2 つのオーディエンスグループの接続方法を 2 つの方法から選択することができます。
-
AND 関係 — AND 関係を使用して 2 つのオーディエンスを接続する場合、セグメントにはオーディエンスグループ 1 とオーディエンスグループ 2 の両方のフィルターを満たすすべてのプロファイルが含まれます。
-
OR 関係 — OR 関係を使用して 2 つのオーディエンスを接続する場合、セグメントにはオーディエンスグループ 1 またはオーディエンスグループ 2 のフィルターを満たすすべてのプロファイルが含まれます。
-
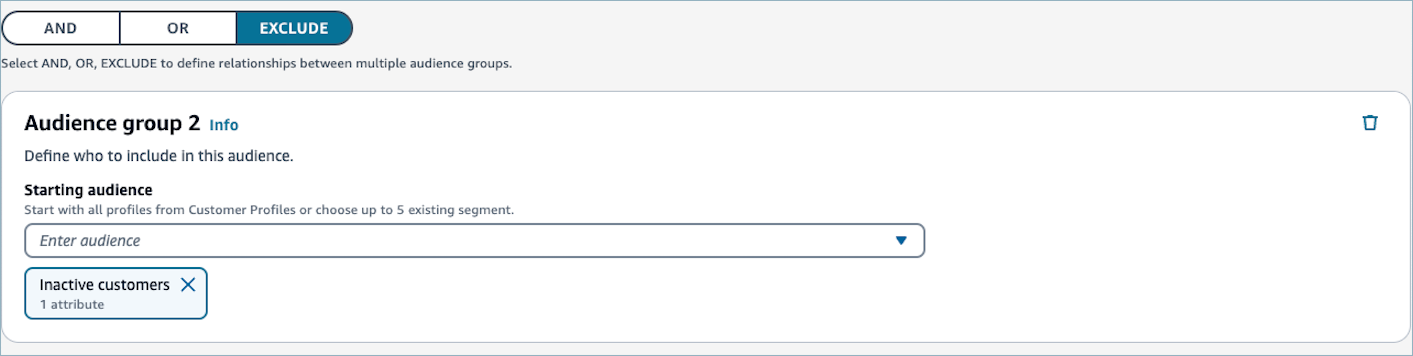
EXCLUDE 関係 — EXCLUDE 関係を使用して 2 つのオーディエンスを接続する場合、セグメントにはオーディエンスグループ 2 のプロファイルを除くオーディエンスグループ 1 のプロファイルが含まれます。
2 番目のオーディエンスグループを設定するには、次の手順を実行します。
-
オーディエンスグループ 1 を設定した後、AND、OR、または EXCLUDE の関係を選択します。
-
オーディエンスグループ 2 で初期オーディエンスを選択します。詳細については、「ステップ 3: オーディエンスグループ 1 に含める初期オーディエンスを選択する」を参照してください。
-
(オプション) セグメントを絞り込むフィルターを選択します。詳細については、「ステップ 4: オーディエンスフィルターを選択して適用する (オプション)」を参照してください。
-
セグメントのセットアップが完了したら、[Create segment] を選択します。これで、セグメントが作成され、アウトバウンドキャンペーンまたはアウトバウンドフローでセグメントを使用できるようになりました。

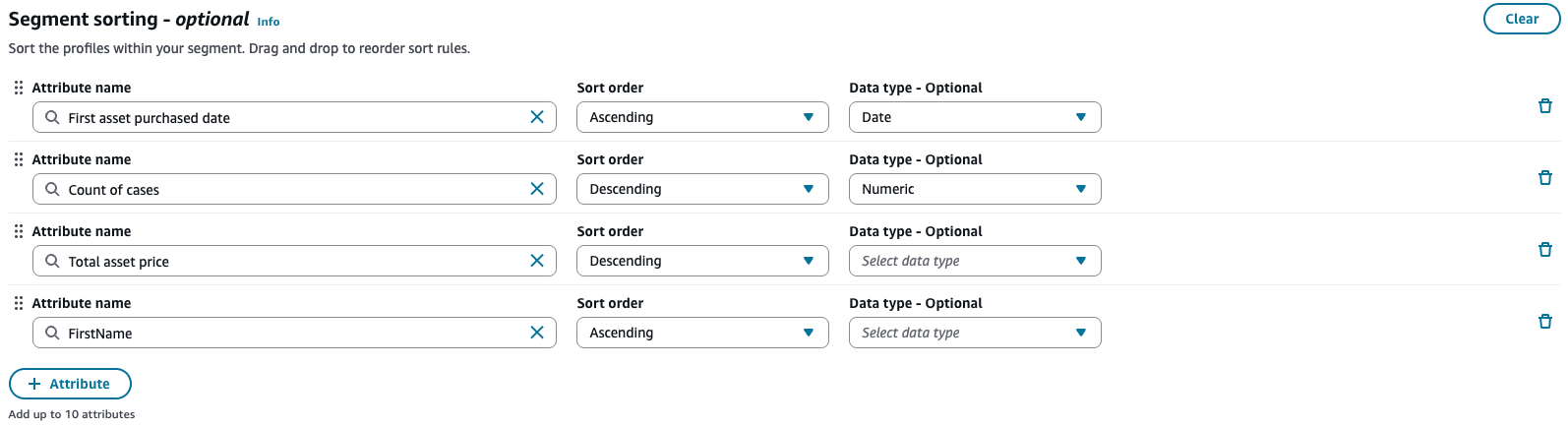
ステップ 6: ソートを有効にする (オプション)
必要に応じて、セグメント結果のソートを設定します。ソートを使用すると、セグメント出力にプロファイルが表示される順序を制御できます。最大 10 個の属性でソートできます。属性は上から下に評価されます。複数のプロファイルが属性に対して同じ値を共有する場合、リスト内の次の属性がタイブレーカーとして使用されます。
アウトバウンドキャンペーンとジャーニーは、実行時にこのソート順序に従います。つまり、プロファイルはセグメントで定義された順序で処理およびダイヤルされます。アウトバウンドキャンペーンでソートされたセグメントを使用する方法の詳細については、「アウトバウンドキャンペーンのベストプラクティス」を参照してください。セグメントのソートは、次の場合に便利です。
-
ライフタイム値やアカウント階層などの属性をソートして、価値の高い顧客を優先します。
-
予約日にソートして、予定されている予約を最初に顧客に連絡します。
-
時間的制約のある通信を特定の順序で処理します。
注記
セグメントのソート順序は、ジャーニーの音声キャンペーンと音声アクティビティでのみ尊重されます。他の通信チャネルは、未ソートの順序でプロファイルを処理します。
ソートを有効にするには
-
ソートする属性名を入力します。標準属性または計算属性のいずれかの属性を使用できます。
-
ソート順を指定します。昇順または降順を選択します。
-
(オプション) 文字列、数値、または日付を選択してデータ型を指定します。タイプを指定しない場合、サンプリングされたデータに基づいて自動的に推測されます。
Spark SQL を使用したセグメントの作成
Spark SQL を搭載したセグメントを使用すると、完全な Customer Profile データおよび拡張機能を使用してセグメントを定義できます。標準プロファイルオブジェクト属性とカスタムオブジェクト属性を使用できます。標準オブジェクトとカスタムオブジェクトを結合してさまざまなオブジェクトのデータを使用したり、パーセンタイルなどの統計でセグメントをフィルタリングしたり、日付フィールドを標準化して比較したりするなど、SQL ベースの機能を使用することもできます。
まず、Segment Assistant AI に自然言語プロンプトを入力します。セグメント AI アシスタントは、Spark SQL への翻訳を含むセグメントを定義します。Segment Assistant AI は、セグメントの定義にかかったステップを提供し、作成しようとしていたものと一致することを検証できます。SQL、自然言語の SQL ステップ、Spark SQL の AI 生成の概要を表示して、さらに検証に役立てることもできます。変更する場合は、自然言語プロンプトを更新するか、Spark SQL を直接編集できます。
Spark SQL セグメントを直接作成することもできます。
Classic セグメンテーションと同様に、Spark SQL を搭載したセグメントは、セグメントメンバーシップコール、フローブロック、アウトバウンドキャンペーンで使用できます。
顧客イベントによって開始されたセグメントメンバーシップコール、フローブロック、またはアウトバウンドキャンペーンで Spark SQL セグメントを使用すると、最後にエクスポートされたセグメント (セグメントスナップショット) が使用されます。メンバーシップに使用されるセグメントスナップショットは、作成から 1 年後に期限切れになります。4XX エラーが発生した場合は、セグメント (セグメントスナップショット) をエクスポートしていることを確認してください。
カスタマーセグメントによって開始されたアウトバウンドキャンペーンでは、セグメント (セグメントスナップショット) をエクスポートする必要はありません。
注記
SQL セグメンテーションは、最大 10 年分のデータがあるデータストアで実行されます。クラシックセグメンテーションでは、最新のデータ (過去 3 年間に更新されたデータ) を使用します。
ステップ 1: 新しいセグメントを構築する
セグメント AI アシスタントで、「セグメントの作成方法」を選択して貴重なセグメントの作成に関する詳細なガイダンスを表示するか、「セグメントを生成したい」を選択して自然言語プロンプトを入力してセグメントを作成します。
または、SQL を使用してクエリエディタで新しいセグメントを定義します。
ステップ 2: 名前と説明を指定する
[名前] に、後で判別しやすいような顧客セグメント名を入力します。
注記
Amazon Connect 管理ウェブサイトは、入力された名前をセグメントDisplayNameの として使用し、それに基づいて識別子を生成します。生成された識別子は、Customer Profiles API を使用してセグメントにアクセスする際に SegmentDefinitionName として使用されます。
オプションで、顧客セグメントの説明を [説明] に入力します。
ステップ 3: セグメントを確認して検証する
セグメント AI アシスタントが使用したデータと、セグメントの生成にかかった AI モデルの手順を確認します。作成した SQL を確認して、クエリエディタでセグメントを定義することもできます。セグメントを作成できなかった場合は、正確なセグメントを作成するために提供されたフィードバックに対処します。セグメントが生成されると、Customer Profiles は自動的にセグメント見積りを作成します。
編集する場合は、「新しい会話」を選択するか、クエリエディタで SQL を作成/編集して、新しいプロンプトを指定できます。
セグメント AI アシスタントを使用していない場合は、クエリを検証し、クエリエディタの下にある「クエリの検証と見積り」ボタンを選択して見積りを作成できます。
注記
Spark SQL を使用するセグメントは、他のクエリエンジンと同様に、セグメントで使用するプロファイルデータの量と使用する SQL に応じて時間がかかります (たとえば、オブジェクト間での複数の結合には通常時間がかかります)。
ステップ 4: セグメントを作成する
セグメントを構築し、満足したら、右上の「セグメントの作成」ボタンを選択します。セグメントを作成したら、フローのセグメントとアウトバウンドキャンペーンのセグメントを使用して、アクション - .csv へのエクスポートを選択できます。
注記
アウトバウンドキャンペーンまたはフローブロックでセグメントを使用する場合、セグメントが最後に作成された日時に基づいてセグメントメンバーシップがチェックされます。フローまたはキャンペーンの実行中にリアルタイムのセグメントメンバーシップチェックが必要な場合は、 Classic セグメンテーションを使用します。
