Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Utilizzo del machine learning di Amazon Aurora con Aurora PostgreSQL
Utilizzando l'apprendimento automatico di Amazon Aurora con il cluster Aurora PostgreSQL DB, puoi usare Amazon Comprehend o Amazon AI o Amazon Bedrock, a seconda delle tue esigenze. SageMaker Ciascuno di questi servizi supporta casi d’uso di machine learning specifici.
L'apprendimento automatico di Aurora è supportato solo in alcune versioni Regioni AWS e per versioni specifiche di Aurora PostgreSQL. Prima di provare a configurare il machine learning di Aurora, verifica la disponibilità della versione di Aurora PostgreSQL e della tua Regione. Per informazioni dettagliate, vedi Utilizzo della funzionalità Machine Learning di Aurora con Aurora PostgreSQL.
Argomenti
Requisiti per l'utilizzo del machine learning di Aurora con Aurora PostgreSQL
Funzionalità e limitazioni supportate del machine learning di Aurora con Aurora PostgreSQL
Configurazione del cluster database Aurora PostgreSQL per utilizzare il machine learning di Aurora
Utilizzo di Amazon Bedrock con il cluster di database Aurora PostgreSQL
Utilizzo di Amazon Comprehend con il cluster database Aurora PostgreSQL
Utilizzo dell' SageMaker intelligenza artificiale con il cluster Aurora PostgreSQL DB
Considerazioni sulle prestazioni per l'utilizzo del machine learning di Aurora con Aurora PostgreSQL
Requisiti per l'utilizzo del machine learning di Aurora con Aurora PostgreSQL
AWS i servizi di machine learning sono servizi gestiti che vengono configurati ed eseguiti nei propri ambienti di produzione. L'apprendimento automatico Aurora supporta l'integrazione con Amazon Comprehend SageMaker , AI e Amazon Bedrock. Prima di provare a configurare il tuo cluster database Aurora PostgreSQL per utilizzare il machine learning di Aurora, assicurati di aver soddisfatto i seguenti requisiti e prerequisiti.
I servizi Amazon Comprehend, SageMaker AI e Amazon Bedrock devono essere eseguiti nello stesso cluster Aurora Regione AWS PostgreSQL DB. Non puoi utilizzare i servizi Amazon Comprehend o SageMaker AI o Amazon Bedrock da un cluster Aurora PostgreSQL DB in un'altra regione.
Se il cluster Aurora PostgreSQL DB si trova in un cloud pubblico virtuale (VPC) diverso basato sul servizio Amazon VPC rispetto ai SageMaker servizi Amazon Comprehend e AI, il gruppo Security di VPC deve consentire le connessioni in uscita al servizio di machine learning Aurora di destinazione. Per ulteriori informazioni, consulta Abilitazione della comunicazione di rete da Amazon Aurora ad altri servizi AWS.
Per l' SageMaker intelligenza artificiale, i componenti di machine learning che desideri utilizzare per le inferenze devono essere configurati e pronti all'uso. Durante il processo di configurazione per il cluster Aurora PostgreSQL DB, devi avere a disposizione l'Amazon Resource Name (ARN) dell'endpoint AI. SageMaker I data scientist del tuo team sono probabilmente i più adatti a gestire il lavoro con l' SageMaker intelligenza artificiale per preparare i modelli e gestire le altre attività simili. Per iniziare a usare Amazon SageMaker AI, consulta Get Started with Amazon SageMaker AI. Per ulteriori informazioni su inferenze ed endpoint, consulta Real-time inferenza.
-
Per Amazon Bedrock, è necessario disporre dell’ID del modello dei modelli Bedrock che si desidera utilizzare per le inferenze durante il processo di configurazione del cluster di database Aurora PostgreSQL. I data scientist del tuo team sono probabilmente le persone più preparate per gestire l’utilizzo di Bedrock in modo da decidere quali modelli applicare, di quali eseguire il fine-tuning se necessario ed eseguire le altre attività correlate. Per iniziare a utilizzare Amazon Bedrock, consulta How to setup Bedrock.
-
Gli utenti di Amazon Bedrock devono richiedere l'accesso ai modelli prima di poterli utilizzare. Se vuoi aggiungere altri modelli per la generazione di testo, chat e immagini, devi richiedere l'accesso ai modelli in Amazon Bedrock. Per ulteriori informazioni, consulta Accesso ai modelli.
Funzionalità e limitazioni supportate del machine learning di Aurora con Aurora PostgreSQL
L'apprendimento automatico Aurora supporta qualsiasi endpoint di SageMaker intelligenza artificiale in grado di leggere e scrivere il formato di valori separati da virgole (CSV) tramite un valore di. ContentType text/csv Gli algoritmi di SageMaker intelligenza artificiale integrati che attualmente accettano questo formato sono i seguenti.
Linear Learner
Random Cut Forest
XGBoost
Per ulteriori informazioni su questi algoritmi, consulta Choose an Algorithm nella Amazon SageMaker AI Developer Guide.
Quando utilizzi Amazon Bedrock con machine learning di Aurora, si applicano le seguenti limitazioni:
-
Le funzioni definite dall’utente (UDF) forniscono una modalità di interazione nativa con Amazon Bedrock. Le UDF non hanno requisiti di richiesta o risposta specifici, quindi possono utilizzare qualsiasi modello.
-
Puoi utilizzare le UDF per creare qualsiasi flusso di lavoro desiderato. Ad esempio, è possibile combinare primitivi di base, come
pg_cron, per eseguire una query, recuperare dati, generare inferenze e scrivere su tabelle per servire direttamente le query. -
Le UDF non supportano chiamate in batch o parallele.
-
L’estensione per il machine learning di Aurora non supporta le interfacce vettoriali. Nell’ambito dell’estensione, è disponibile una funzione per l’output degli embedding della risposta del modello in formato
float8[]che ne consente l’archiviazione in Aurora. Per ulteriori informazioni sull’utilizzo difloat8[], consulta Utilizzo di Amazon Bedrock con il cluster di database Aurora PostgreSQL.
Configurazione del cluster database Aurora PostgreSQL per utilizzare il machine learning di Aurora
Affinché l'apprendimento automatico Aurora funzioni con il cluster Aurora PostgreSQL DB, devi creare un ruolo AWS Identity and Access Management (IAM) per ciascuno dei servizi che desideri utilizzare. Il ruolo IAM consente al cluster database Aurora PostgreSQL di utilizzare il servizio di machine learning di Aurora per conto del cluster. Dovrai inoltre installare l'estensione di machine learning di Aurora. Nei seguenti argomenti sono disponibili le procedure di configurazione per ciascuno di questi servizi di machine learning di Aurora.
Argomenti
Configurazione di Aurora PostgreSQL per utilizzare Amazon Bedrock
Nella procedura seguente, devi innanzitutto creare il ruolo e la policy IAM che autorizzano Aurora PostgreSQL a utilizzare Amazon Bedrock per conto del cluster. Devi quindi collegare la policy a un ruolo IAM utilizzato dal cluster di database Aurora PostgreSQL per poter eseguire Amazon Bedrock. Per una maggiore semplicità, questa procedura utilizza la Console di gestione AWS per completare tutte le attività.
Per configurare il cluster di database Aurora PostgreSQL in modo che utilizzi Amazon Bedrock
Accedi Console di gestione AWS e apri la console IAM all'indirizzo. https://console.aws.amazon.com/iam/
Aprire la console IAM all'indirizzo https://console.aws.amazon.com/iam/
. Scegli Policies (in Gestione degli accessi) nel menu della console AWS Identity and Access Management (IAM).
Scegli Crea policy. Nella pagina dell’editor visivo, scegli Servizio, quindi immetti Bedrock nel campo Seleziona un servizio. Espandi il livello di accesso Read (Lettura). InvokeModelScegli tra le impostazioni di lettura di Amazon Bedrock.
Scegli il Foundation/Provisioned modello a cui desideri concedere l'accesso in lettura tramite la politica.
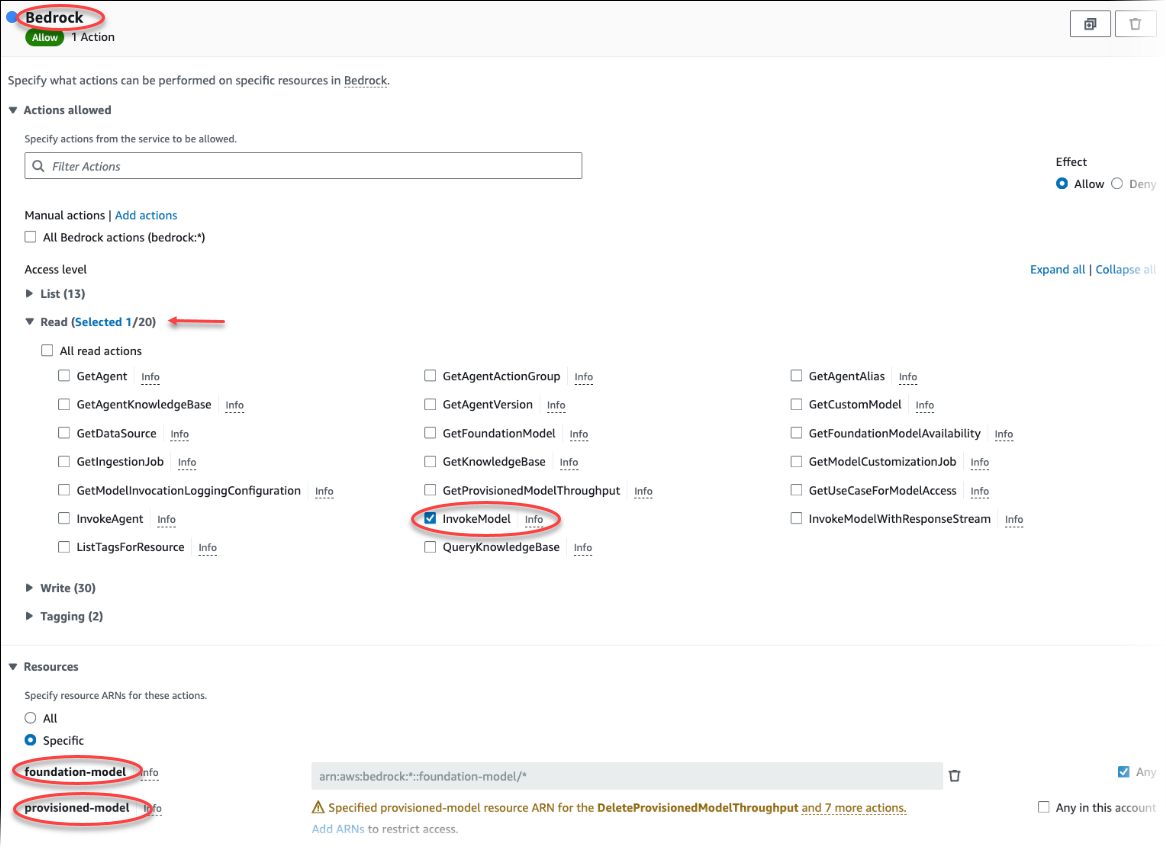
Scegli Next: Tags (Successivo: Tag) e definisci i tag (questo passaggio è facoltativo). Seleziona Next: Review (Successivo: Rivedi). Immetti un nome e una descrizione per la policy, come illustrato nell'immagine.
Scegli Crea policy. Viene visualizzato un avviso nella console quando la policy viene salvata e diventa disponibile nell'elenco delle policy.
Nella console IAM scegli Roles (Ruoli) sotto Access management (Gestione degli accessi).
Scegli Crea ruolo.
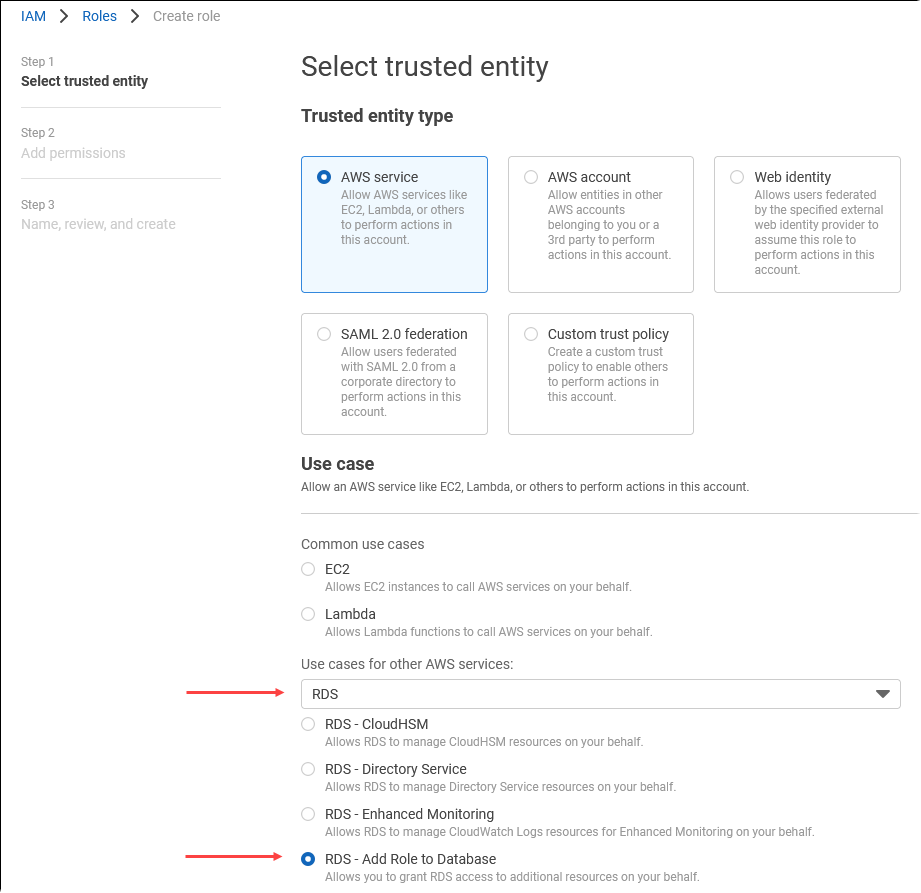
Nella pagina Select trusted entity (Seleziona entità attendibile), scegli il riquadro AWS service (Servizio AWS ), quindi seleziona RDS per aprire il selettore.
Scegli RDS – Add Role to Database (RDS - Aggiungi ruolo al database).
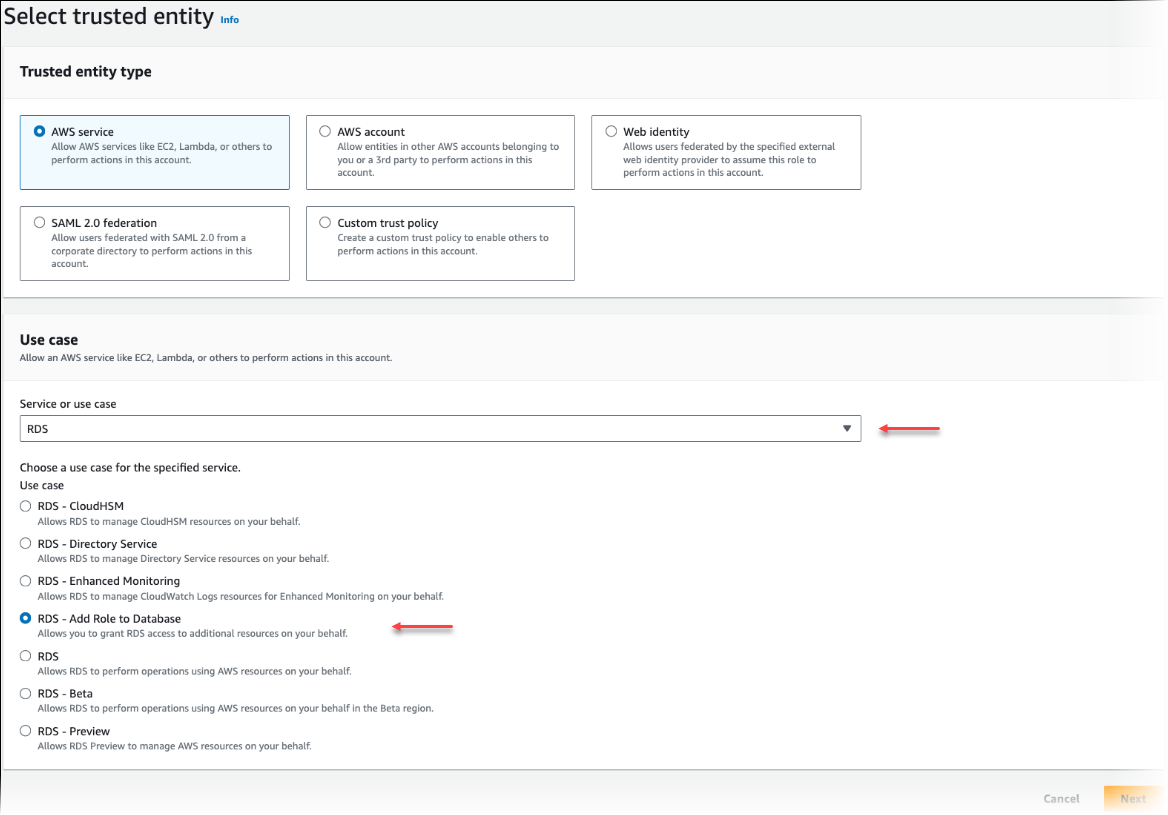
Scegli Next (Successivo). Nella pagina Add permissions (Aggiungi autorizzazioni), trova la policy creata nel passaggio precedente e selezionala tra quelle elencate. Scegli Next (Successivo).
Next: Review (Successivo: Rivedi). Immetti un nome e una descrizione per il ruolo IAM.
Aprire la console Amazon RDS all'indirizzo https://console.aws.amazon.com/rds/
. Passa alla posizione Regione AWS in cui si trova il cluster Aurora PostgreSQL DB.
-
Nel riquadro di navigazione, scegli Database, quindi seleziona il cluster di database Aurora PostgreSQL da utilizzare con Bedrock.
-
Scegli la scheda Connectivity & security (Connettività e sicurezza) e scorri fino a trovare la sezione Manage IAM roles (Gestisci ruoli IAM) della pagina. Nel selettore Add IAM roles to this cluster (Aggiungi i ruoli IAM a questo cluster) scegli il ruolo creato nei passaggi precedenti. Nel riquadro Caratteristica, scegli Bedrock, quindi seleziona Aggiungi ruolo.
Il ruolo e la relativa policy vengono associati al cluster database Aurora PostgreSQL. Al termine del processo, il ruolo viene visualizzato nell'elenco Current IAM roles for this cluster (Ruoli IAM attuali per questo cluster), come illustrato di seguito.

La configurazione di IAM per Amazon Bedrock è stata completata. Ora continua a configurare Aurora PostgreSQL per utilizzare il machine learning di Aurora installando l'estensione come descritto in Installazione dell'estensione di machine learning di Aurora
Configurazione di Aurora PostgreSQL per utilizzare Amazon Comprehend
Nella procedura seguente, per prima cosa crei il ruolo e la policy IAM che autorizzano Aurora PostgreSQL a utilizzare Amazon Comprehend per conto del cluster. Quindi colleghi la policy a un ruolo IAM che viene usato dal cluster database Aurora PostgreSQL per poter eseguire Amazon Comprehend. Per motivi di semplicità, si usa la Console di gestione AWS per completare tutte le attività di questa procedura.
Per configurare il cluster database Aurora PostgreSQL per utilizzare Amazon Comprehend
Accedi Console di gestione AWS e apri la console IAM all'indirizzo. https://console.aws.amazon.com/iam/
Aprire la console IAM all'indirizzo https://console.aws.amazon.com/iam/
. Scegli Policies (in Gestione degli accessi) nel menu della console AWS Identity and Access Management (IAM).
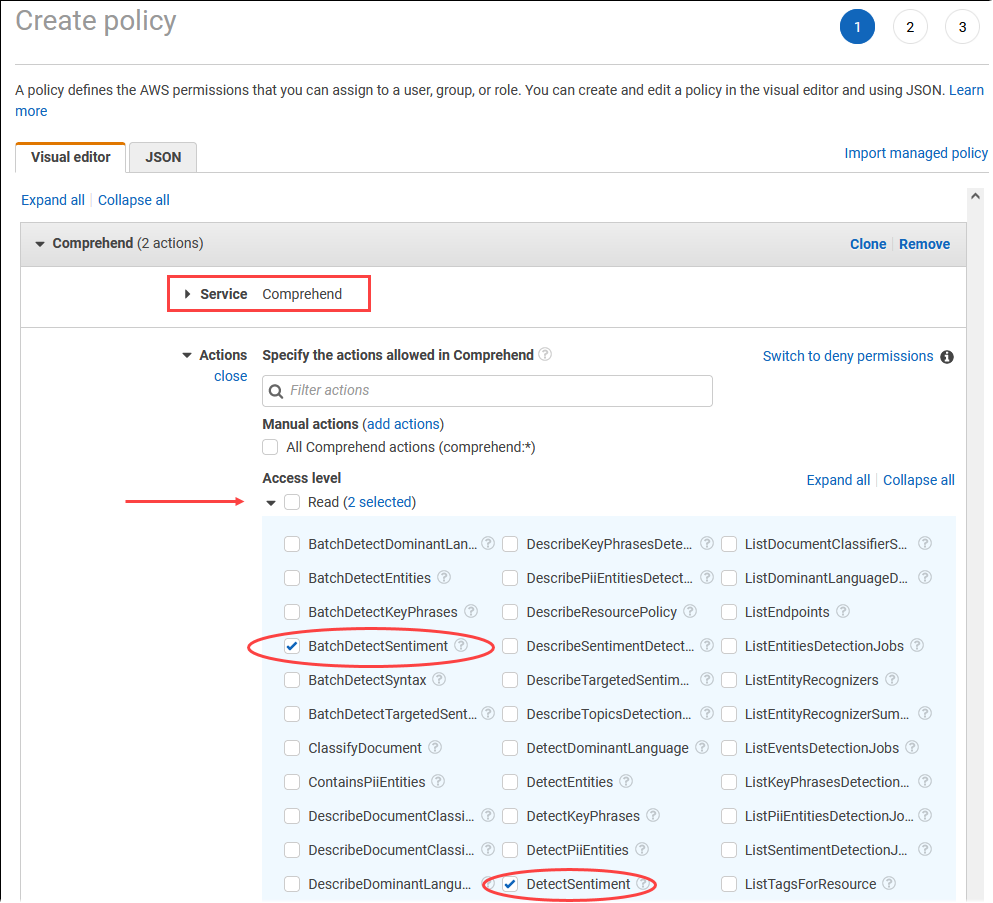
Scegli Crea policy. Nella pagina Visual editor (Editor visivo) scegli Service (Servizio), quindi immetti Comprehend nel campo Select a service (Seleziona un servizio). Espandi il livello di accesso Read (Lettura). Scegli BatchDetectSentimente tra le DetectSentimentimpostazioni di lettura di Amazon Comprehend.
Scegli Next: Tags (Successivo: Tag) e definisci i tag (questo passaggio è facoltativo). Seleziona Next: Review (Successivo: Rivedi). Immetti un nome e una descrizione per la policy, come illustrato nell'immagine.

Scegli Crea policy. Viene visualizzato un avviso nella console quando la policy viene salvata e diventa disponibile nell'elenco delle policy.
Nella console IAM scegli Roles (Ruoli) sotto Access management (Gestione degli accessi).
Scegli Crea ruolo.
Nella pagina Select trusted entity (Seleziona entità attendibile), scegli il riquadro AWS service (Servizio AWS ), quindi seleziona RDS per aprire il selettore.
Scegli RDS – Add Role to Database (RDS - Aggiungi ruolo al database).
Scegli Next (Successivo). Nella pagina Add permissions (Aggiungi autorizzazioni), trova la policy creata nel passaggio precedente e selezionala tra quelle elencate. Seleziona Next (Successivo).
Next: Review (Successivo: Rivedi). Immetti un nome e una descrizione per il ruolo IAM.
Aprire la console Amazon RDS all'indirizzo https://console.aws.amazon.com/rds/
. Passa alla posizione Regione AWS in cui si trova il cluster Aurora PostgreSQL DB.
-
Nel riquadro di navigazione, scegli Databases (Database), quindi seleziona il cluster database Aurora PostgreSQL da utilizzare con Amazon Comprehend.
-
Scegli la scheda Connectivity & security (Connettività e sicurezza) e scorri fino a trovare la sezione Manage IAM roles (Gestisci ruoli IAM) della pagina. Nel selettore Add IAM roles to this cluster (Aggiungi i ruoli IAM a questo cluster) scegli il ruolo creato nei passaggi precedenti. Nel selettore Caratteristica, scegli Comprehend, quindi seleziona Aggiungi ruolo.
Il ruolo e la relativa policy vengono associati al cluster database Aurora PostgreSQL. Al termine del processo, il ruolo viene visualizzato nell'elenco Current IAM roles for this cluster (Ruoli IAM attuali per questo cluster), come illustrato di seguito.
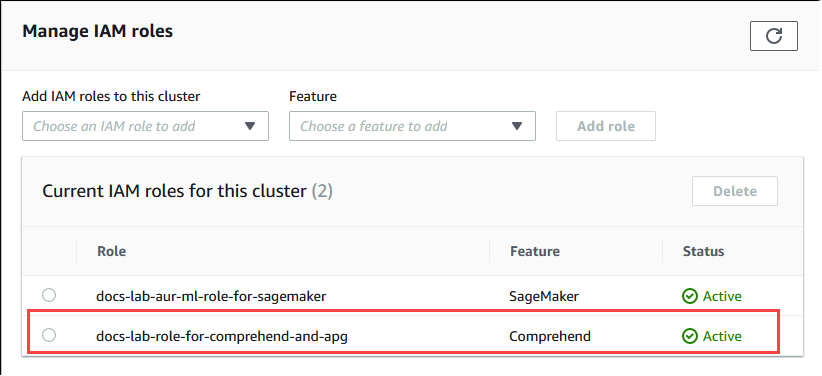
La configurazione di IAM per Amazon Comprehend è stata completata. Ora continua a configurare Aurora PostgreSQL per utilizzare il machine learning di Aurora installando l'estensione come descritto in Installazione dell'estensione di machine learning di Aurora
Configurazione di Aurora PostgreSQL per l'utilizzo di Amazon AI SageMaker
Prima di poter creare la policy e il ruolo IAM per il tuo cluster Aurora PostgreSQL DB, devi avere a disposizione la configurazione del modello di intelligenza artificiale e l'endpoint. SageMaker
Per configurare il cluster Aurora PostgreSQL DB per utilizzare l'intelligenza artificiale SageMaker
Accedi Console di gestione AWS e apri la console IAM all'indirizzo. https://console.aws.amazon.com/iam/
Scegli Policy (in Gestione degli accessi) nel menu della console AWS Identity and Access Management (IAM), quindi scegli Crea policy. Nell'editor visivo, scegli SageMakeril servizio. Per Azioni, apri il selettore di lettura (in Livello di accesso) e scegli InvokeEndpoint. Viene visualizzata un'icona di avviso quando si esegue questa operazione.
Apri il selettore Risorse e scegli il link Aggiungi ARN per limitare l'accesso sotto Specificare l'ARN della risorsa dell'endpoint per l'azione. InvokeEndpoint
Inserisci le Regione AWS tue risorse SageMaker AI e il nome del tuo endpoint. Il tuo AWS account è precompilato.
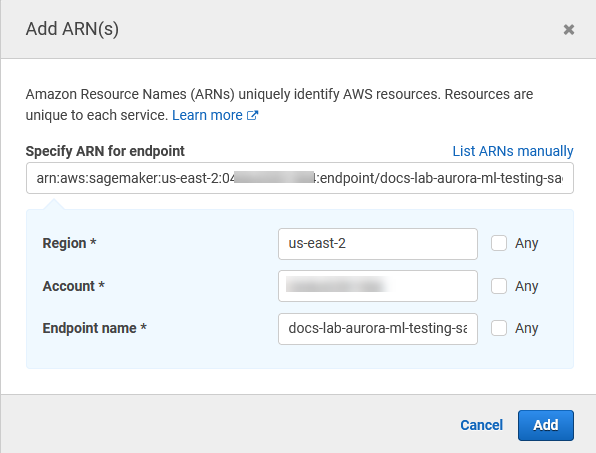
Scegli Add (Aggiungi) per salvare. Scegli Next: Tags (Successivo: Tag) e Next: Review (Successivo: Rivedi) per passare all'ultima pagina del processo di creazione della policy.
Immetti un nome e una descrizione per la policy e quindi scegli Create policy (Crea policy). La policy viene creata e aggiunta all'elenco delle policy. Quindi, viene visualizzato un avviso nella console.
Nella console IAM scegli Roles (Ruoli).
Scegli Crea ruolo.
Nella pagina Select trusted entity (Seleziona entità attendibile), scegli il riquadro AWS service (Servizio AWS ), quindi seleziona RDS per aprire il selettore.
Scegli RDS – Add Role to Database (RDS - Aggiungi ruolo al database).
Scegli Next (Successivo). Nella pagina Add permissions (Aggiungi autorizzazioni), trova la policy creata nel passaggio precedente e selezionala tra quelle elencate. Seleziona Next (Successivo).
Next: Review (Successivo: Rivedi). Immetti un nome e una descrizione per il ruolo IAM.
Aprire la console Amazon RDS all'indirizzo https://console.aws.amazon.com/rds/
. Passa alla posizione Regione AWS in cui si trova il cluster Aurora PostgreSQL DB.
-
Nel riquadro di navigazione, scegli Database, quindi scegli il cluster Aurora PostgreSQL DB che desideri utilizzare con l'intelligenza artificiale. SageMaker
-
Scegli la scheda Connectivity & security (Connettività e sicurezza) e scorri fino a trovare la sezione Manage IAM roles (Gestisci ruoli IAM) della pagina. Nel selettore Add IAM roles to this cluster (Aggiungi i ruoli IAM a questo cluster) scegli il ruolo creato nei passaggi precedenti. Nel selettore Feature, scegli SageMaker AI, quindi scegli Aggiungi ruolo.
Il ruolo e la relativa policy vengono associati al cluster database Aurora PostgreSQL. Al termine del processo, il ruolo viene visualizzato nell'elenco Current IAM roles for this cluster (Ruoli IAM attuali per questo cluster).
La configurazione IAM per l' SageMaker IA è completa. Ora continua a configurare Aurora PostgreSQL per utilizzare il machine learning di Aurora installando l'estensione come descritto in Installazione dell'estensione di machine learning di Aurora.
Configurazione di Aurora PostgreSQL per l'utilizzo di Amazon S3 for AI (Advanced) SageMaker
Per utilizzare l' SageMaker intelligenza artificiale con i tuoi modelli anziché utilizzare i componenti predefiniti forniti dall' SageMaker IA, devi configurare un cluster Amazon Simple Storage Service (Amazon S3) per Aurora PostgreSQL DB da utilizzare. Questa è un'attività avanzata non completamente documentata in questa Guida per l'utente di Amazon Aurora. Il processo generale è lo stesso dell'integrazione del supporto per l'IA, come segue. SageMaker
Crea il ruolo e la policy IAM per Amazon S3.
Aggiungi il ruolo IAM e l'importazione o l'esportazione di Amazon S3 come funzionalità nella scheda Connectivity & security (Connettività e sicurezza) del cluster database Aurora PostgreSQL.
Aggiungi l'ARN del ruolo al gruppo di parametri personalizzati del cluster database Aurora.
Per informazioni di base sull'utilizzo, consulta Esportazione di dati in Amazon S3 SageMaker per la formazione su modelli di intelligenza artificiale (Advanced).
Installazione dell'estensione di machine learning di Aurora
Le estensioni di machine learning Aurora aws_ml 1.0 offrono due funzioni che puoi usare per richiamare Amazon Comprehend, i servizi SageMaker AI e aws_ml 2.0 offrono due funzioni aggiuntive che puoi usare per richiamare i servizi Amazon Bedrock. L’installazione di queste estensioni nel cluster di database Aurora PostgreSQL crea anche un ruolo amministrativo per la funzionalità.
Nota
L'utilizzo di queste funzioni dipende dal completamento della configurazione IAM per il servizio di machine learning Aurora (Amazon Comprehend, SageMaker AI, Amazon Bedrock), come dettagliato in. Configurazione del cluster database Aurora PostgreSQL per utilizzare il machine learning di Aurora
aws_comprehend.detect_sentiment: questa funzione si utilizza per applicare l'analisi del sentiment al testo archiviato nel database del cluster database Aurora PostgreSQL.
aws_sagemaker.invoke_endpoint: utilizzi questa funzione nel codice SQL per comunicare con l'endpoint AI del tuo cluster. SageMaker
aws_bedrock.invoke_model: utilizza questa funzione nel codice SQL per comunicare con i modelli Bedrock del cluster. La risposta di questa funzione avrà il formato di un TEXT, quindi se un modello risponde nel formato di un corpo JSON, il formato dell’output della funzione inoltrato all’utente finale sarà una stringa.
aws_bedrock.invoke_model_get_embeddings: utilizza questa funzione nel codice SQL per invocare modelli Bedrock che restituiscono embedding di output all’interno di una risposta JSON. Questo può risultare utile per estrarre gli embedding direttamente associati alla chiave json per semplificare la risposta con qualsiasi flusso di lavoro autogestito.
Per installare l'estensione di machine learning di Aurora nel cluster database Aurora PostgreSQL
Utilizza
psqlper connetterti all'istanza di scrittura del cluster database Aurora PostgreSQL. Collega il database specifico in cui installare l'estensioneaws_ml.psql --host=cluster-instance-1.111122223333.aws-region.rds.amazonaws.com --port=5432 --username=postgres --password --dbname=labdb
labdb=>CREATE EXTENSION IF NOT EXISTS aws_ml CASCADE;NOTICE: installing required extension "aws_commons" CREATE EXTENSIONlabdb=>
L’installazione delle estensioni aws_ml crea anche il ruolo amministrativo aws_ml e tre nuovi schemi, come indicato di seguito.
aws_comprehend: schema del servizio Amazon Comprehend e origine della funzionedetect_sentiment(aws_comprehend.detect_sentiment).aws_sagemaker— Schema per il servizio AI e fonte della funzione (). SageMakerinvoke_endpointaws_sagemaker.invoke_endpointaws_bedrock: schema del servizio Amazon Bedrock e origine delle funzioniinvoke_model(aws_bedrock.invoke_model)einvoke_model_get_embeddings(aws_bedrock.invoke_model_get_embeddings).
Al ruolo rds_superuser viene concesso il ruolo amministrativo aws_ml e diventa OWNER di questi tre schemi di machine learning di Aurora. Per consentire ad altri utenti del database di accedere alle funzioni di machine learning di Aurora, rds_superuser deve concedere i privilegi EXECUTE per le funzioni di machine learning di Aurora. Per impostazione predefinita, i privilegi EXECUTE sono revocati da PUBLIC per le funzioni nei due schemi di machine learning di Aurora.
In una configurazione di database multi-tenant, puoi impedire ai tenant di accedere alle funzioni di machine learning di Aurora utilizzando REVOKE USAGE nello specifico schema di machine learning di Aurora che desideri proteggere.
Utilizzo di Amazon Bedrock con il cluster di database Aurora PostgreSQL
Per Aurora PostgreSQL, il machine learning di Aurora fornisce la seguente funzione Amazon Bedrock che consente di utilizzare i dati di testo. Questa funzione è disponibile solo dopo aver installato l’estensione aws_ml 2.0 e completato tutte le procedure di configurazione. Per ulteriori informazioni, consulta Configurazione del cluster database Aurora PostgreSQL per utilizzare il machine learning di Aurora.
- aws_bedrock.invoke_model
-
Questa funzione accetta il testo formattato in JSON come input, lo elabora per una varietà di modelli ospitati su Amazon Bedrock e recupera la risposta testuale JSON dal modello. Tale risposta potrebbe contenere testo, immagine o embedding. Di seguito è riportato un riepilogo della documentazione della funzione.
aws_bedrock.invoke_model( IN model_id varchar, IN content_type text, IN accept_type text, IN model_input text, OUT model_output varchar)
Gli input e gli output di questa funzione sono indicati di seguito.
-
model_id: identificatore del modello. content_type: tipo di richiesta al modello di Bedrock.accept_type: tipo di risposta che ci si aspetta dal modello di Bedrock, Di solito application/JSON per la maggior parte dei modelli.model_input: prompt, un set specifico di input per il modello nel formato specificato da content_type. Per ulteriori informazioni sulla richiesta accettata format/structure dal modello, consulta Parametri di inferenza per i modelli di base.model_output: output del modello Bedrock in formato testo.
Il seguente esempio mostra come invocare un modello Anthropic Claude 2 per Bedrock utilizzando invoke_model.
Esempio Esempio: una query semplice che utilizza le funzioni di Amazon Bedrock
SELECT aws_bedrock.invoke_model ( model_id := 'anthropic.claude-v2', content_type:= 'application/json', accept_type := 'application/json', model_input := '{"prompt": "\n\nHuman: You are a helpful assistant that answers questions directly and only using the information provided in the context below.\nDescribe the answer in detail.\n\nContext: %s \n\nQuestion: %s \n\nAssistant:","max_tokens_to_sample":4096,"temperature":0.5,"top_k":250,"top_p":0.5,"stop_sequences":[]}' );
- aws_bedrock.invoke_model_get_embeddings
-
In alcuni casi, l’output del modello può indicare embedding vettoriali. Dato che la risposta varia in base al modello, è possibile ricorrere a un’altra funzione invoke_model_get_embeddings che funziona esattamente come invoke_model, ma restituisce gli embedding specificando la chiave json appropriata.
aws_bedrock.invoke_model_get_embeddings( IN model_id varchar, IN content_type text, IN json_key text, IN model_input text, OUT model_output float8[])
Gli input e gli output di questa funzione sono indicati di seguito.
-
model_id: identificatore del modello. content_type: tipo di richiesta al modello di Bedrock. In questo caso, accept_type è impostato sul valore predefinitoapplication/json.model_input: prompt, un set specifico di input per il modello nel formato specificato da content_type. Per ulteriori informazioni sulla richiesta accettata format/structure dal modello, vedere Parametri di inferenza per i modelli di base.json_key: riferimento al campo da cui estrarre l’embedding. Può variare se il modello di embedding cambia.-
model_output: output del modello Bedrock sotto forma di array di embedding con decimali a 16 bit.
L'esempio seguente mostra come generare un incorporamento utilizzando il modello Titan Embeddings G1 — Text embedding per la frase PostgreSQL monitoring views. I/O
Esempio Esempio: una query semplice che utilizza le funzioni di Amazon Bedrock
SELECT aws_bedrock.invoke_model_get_embeddings( model_id := 'amazon.titan-embed-text-v1', content_type := 'application/json', json_key := 'embedding', model_input := '{ "inputText": "PostgreSQL I/O monitoring views"}') AS embedding;
Utilizzo di Amazon Comprehend con il cluster database Aurora PostgreSQL
Per Aurora PostgreSQL, il machine learning di Aurora fornisce la seguente funzione Amazon Comprehend per utilizzare i dati di testo. Questa funzione è disponibile solo dopo aver installato l'estensione aws_ml e completato tutte le procedure di configurazione. Per ulteriori informazioni, consulta Configurazione del cluster database Aurora PostgreSQL per utilizzare il machine learning di Aurora.
- aws_comprehend.detect_sentiment
-
Questa funzione utilizza il testo come input e valuta se ha un intento emotivo positivo, negativo, neutro o misto. Genera questo sentiment insieme a un livello di confidenza per la valutazione. Di seguito è riportato un riepilogo della documentazione della funzione.
aws_comprehend.detect_sentiment( IN input_text varchar, IN language_code varchar, IN max_rows_per_batch int, OUT sentiment varchar, OUT confidence real)
Gli input e gli output di questa funzione sono indicati di seguito.
-
input_text: il testo da valutare per assegnare il sentiment (negativo, positivo, neutro, misto). language_code: la lingua diinput_textidentificata utilizzando l'identificatore a 2 lettere ISO 639-1 con etichetta secondaria regionale (se necessaria) o il codice a tre lettere ISO 639-2, a seconda dei casi. Ad esempio,enè il codice per l'inglese,zhè il codice per il cinese semplificato. Per ulteriori informazioni, consulta Lingue supportate nella Guida per gli sviluppatori di Amazon Comprehend.max_rows_per_batch: il numero massimo di righe per batch per l'elaborazione in modalità batch. Per ulteriori informazioni, consulta Informazioni sulla modalità batch e sulle funzioni di machine learning di Aurora.sentiment: il sentiment del testo di input, identificato come POSITIVE (POSITIVO), NEGATIVE (NEGATIVO), NEUTRAL (NEUTRO) o MIXED (MISTO).confidence: il livello di confidenza della precisione delsentimentspecificato. I valori sono compresi tra 0,0 e 1,0.
Di seguito sono riportati alcuni esempi di come utilizzare questa funzione.
Esempio Esempio: una semplice query che utilizza le funzioni di Amazon Comprehend
Di seguito è riportato l'esempio di una semplice query che richiama la funzione per valutare la soddisfazione del cliente nei confronti del team di supporto. Supponi di avere una tabella di database (support) che archivia il feedback dei clienti dopo ogni richiesta di assistenza. Questa query di esempio applica la funzione aws_comprehend.detect_sentiment al testo nella colonna feedback della tabella e restituisce il sentiment e il livello di confidenza del sentiment. Inoltre i risultati vengono restituiti in ordine decrescente.
SELECT feedback, s.sentiment,s.confidence FROM support,aws_comprehend.detect_sentiment(feedback, 'en') s ORDER BY s.confidence DESC;feedback | sentiment | confidence ----------------------------------------------------------+-----------+------------ Thank you for the excellent customer support! | POSITIVE | 0.999771 The latest version of this product stinks! | NEGATIVE | 0.999184 Your support team is just awesome! I am blown away. | POSITIVE | 0.997774 Your product is too complex, but your support is great. | MIXED | 0.957958 Your support tech helped me in fifteen minutes. | POSITIVE | 0.949491 My problem was never resolved! | NEGATIVE | 0.920644 When will the new version of this product be released? | NEUTRAL | 0.902706 I cannot stand that chatbot. | NEGATIVE | 0.895219 Your support tech talked down to me. | NEGATIVE | 0.868598 It took me way too long to get a real person. | NEGATIVE | 0.481805 (10 rows)
Per evitare che ti venga addebitato il rilevamento del sentiment più di una volta per riga della tabella, puoi materializzare i risultati. Esegui questa operazione sulle righe di interesse. Ad esempio, le note del medico vengono aggiornate in modo che solo quelle in francese (fr) utilizzino la funzione di rilevamento del sentiment.
UPDATE clinician_notes SET sentiment = (aws_comprehend.detect_sentiment (french_notes, 'fr')).sentiment, confidence = (aws_comprehend.detect_sentiment (french_notes, 'fr')).confidence WHERE clinician_notes.french_notes IS NOT NULL AND LENGTH(TRIM(clinician_notes.french_notes)) > 0 AND clinician_notes.sentiment IS NULL;
Per ulteriori informazioni sull'ottimizzazione delle chiamate di funzione, consulta Considerazioni sulle prestazioni per l'utilizzo del machine learning di Aurora con Aurora PostgreSQL.
Utilizzo dell' SageMaker intelligenza artificiale con il cluster Aurora PostgreSQL DB
Dopo aver configurato l'ambiente di SageMaker intelligenza artificiale e aver effettuato l'integrazione con Aurora PostgreSQL come Configurazione di Aurora PostgreSQL per l'utilizzo di Amazon AI SageMaker descritto in, puoi richiamare le operazioni utilizzando la funzione. aws_sagemaker.invoke_endpoint La funzione aws_sagemaker.invoke_endpoint si connette a un solo endpoint del modello nella stessa Regione AWS. Se la tua istanza di database ha repliche multiple, Regioni AWS
assicurati di configurare e distribuire ogni modello di intelligenza artificiale su tutti. SageMaker Regione AWS
Le chiamate a aws_sagemaker.invoke_endpoint vengono autenticate utilizzando il ruolo IAM che hai impostato per associare il cluster Aurora PostgreSQL DB al servizio AI e all'endpoint che hai SageMaker fornito durante il processo di configurazione. SageMaker Gli endpoint del modello AI sono limitati a un singolo account e non sono pubblici. L'endpoint_nameURL non contiene l'ID dell'account. SageMaker L'IA determina l'ID dell'account dal token di autenticazione fornito dal ruolo SageMaker AI IAM dell'istanza del database.
- aws_sagemaker.invoke_endpoint
Questa funzione accetta l'endpoint SageMaker AI come input e il numero di righe che devono essere elaborate come batch. Prende anche come input i vari parametri previsti dall'endpoint del modello SageMaker AI. La documentazione di riferimento della funzione è indicata di seguito.
aws_sagemaker.invoke_endpoint( IN endpoint_name varchar, IN max_rows_per_batch int, VARIADIC model_input "any", OUT model_output varchar )
Gli input e gli output di questa funzione sono indicati di seguito.
endpoint_name— Un URL di endpoint indipendente. Regione AWSmax_rows_per_batch: il numero massimo di righe per batch per l'elaborazione in modalità batch. Per ulteriori informazioni, consulta Informazioni sulla modalità batch e sulle funzioni di machine learning di Aurora.model_input: uno o più parametri di input per il modello. Questi possono essere qualsiasi tipo di dati necessario al modello di SageMaker intelligenza artificiale. PostgreSQL consente di specificare fino a 100 parametri di input per una funzione. I tipi di dati dell'array devono essere unidimensionali, ma possono contenere tutti gli elementi previsti dal modello di SageMaker intelligenza artificiale. Il numero di input per un modello SageMaker AI è limitato solo dal limite di dimensione dei messaggi SageMaker AI di 6 MB.model_output— L'output del modello SageMaker AI come testo.
Creazione di una funzione definita dall'utente per richiamare un SageMaker modello di intelligenza artificiale
Crea una funzione definita dall'utente separata da chiamare aws_sagemaker.invoke_endpoint per ciascuno dei tuoi SageMaker modelli di intelligenza artificiale. La funzione definita dall'utente rappresenta l'endpoint SageMaker AI che ospita il modello. La aws_sagemaker.invoke_endpoint funzione viene eseguita all'interno della funzione definita dall'utente. User-defined le funzioni offrono molti vantaggi:
-
Puoi dare un nome al tuo modello di SageMaker intelligenza artificiale invece di
aws_sagemaker.invoke_endpointrichiedere solo tutti i tuoi modelli di SageMaker intelligenza artificiale. -
Puoi specificare l'URL dell'endpoint del modello in una sola posizione nel codice dell'applicazione SQL.
-
Puoi controllare i privilegi
EXECUTEper ogni funzione di machine learning di Aurora in modo indipendente. -
Puoi dichiarare i tipi di input e output del modello utilizzando i tipi SQL. SQL impone il numero e il tipo di argomenti passati al modello di SageMaker intelligenza artificiale ed esegue la conversione dei tipi, se necessario. L'utilizzo dei tipi SQL si
SQL NULLtradurrà anche nel valore predefinito appropriato previsto dal modello di SageMaker intelligenza artificiale. -
Puoi ridurre la dimensione massima del batch se desideri restituire le prime righe un po' più velocemente.
Per specificare una funzione definita dall'utente, utilizza l'istruzione SQL Data Definition Language (DDL) CREATE FUNCTION. Quando definisci la funzione, specifica quanto segue:
-
I parametri di input per il modello.
-
L'endpoint SageMaker AI specifico da richiamare.
-
Il tipo restituito.
La funzione definita dall'utente restituisce l'inferenza calcolata dall'endpoint SageMaker AI dopo aver eseguito il modello sui parametri di input. L'esempio seguente crea una funzione definita dall'utente per un modello di SageMaker intelligenza artificiale con due parametri di input.
CREATE FUNCTION classify_event (IN arg1 INT, IN arg2 DATE, OUT category INT)
AS $$
SELECT aws_sagemaker.invoke_endpoint (
'sagemaker_model_endpoint_name', NULL,
arg1, arg2 -- model inputs are separate arguments
)::INT -- cast the output to INT
$$ LANGUAGE SQL PARALLEL SAFE COST 5000;Tenere presente quanto segue:
-
L'input della funzione
aws_sagemaker.invoke_endpointpuò essere uno o più parametri di qualsiasi tipo di dati. -
In questo esempio viene utilizzato un tipo di output INT. Se esegui il cast dell'output da un tipo
varchara un tipo diverso, è necessario eseguire il cast a un tipo scalare incorporato PostgreSQL comeINTEGER,REAL,FLOAToNUMERIC. Per ulteriori informazioni su questi tipi, consulta Tipi di datinella documentazione PostgreSQL. -
Specifica
PARALLEL SAFEper abilitare l'esecuzione di query parallele. Per ulteriori informazioni, consulta Miglioramento dei tempi di risposta con l'elaborazione di query parallela. -
Specificare
COST 5000per stimare il costo di esecuzione della funzione. Utilizza un numero positivo che fornisce i costi di esecuzione stimati della funzione, in unità dicpu_operator_cost.
Passare un array come input a un modello SageMaker AI
La funzione aws_sagemaker.invoke_endpoint può avere fino a 100 parametri di input, che è il limite per le funzioni PostgreSQL. Se il modello SageMaker AI richiede più di 100 parametri dello stesso tipo, passa i parametri del modello come array.
L'esempio seguente definisce una funzione che passa un array come input al modello di regressione SageMaker AI. L'output viene trasmesso a un valore REAL.
CREATE FUNCTION regression_model (params REAL[], OUT estimate REAL) AS $$ SELECT aws_sagemaker.invoke_endpoint ( 'sagemaker_model_endpoint_name', NULL, params )::REAL $$ LANGUAGE SQL PARALLEL SAFE COST 5000;
Specificazione della dimensione del batch quando si richiama un modello di intelligenza artificiale SageMaker
L'esempio seguente crea una funzione definita dall'utente per un modello di SageMaker intelligenza artificiale che imposta la dimensione del batch predefinita su NULL. La funzione consente inoltre di fornire una dimensione batch diversa quando viene invocata.
CREATE FUNCTION classify_event (
IN event_type INT, IN event_day DATE, IN amount REAL, -- model inputs
max_rows_per_batch INT DEFAULT NULL, -- optional batch size limit
OUT category INT) -- model output
AS $$
SELECT aws_sagemaker.invoke_endpoint (
'sagemaker_model_endpoint_name', max_rows_per_batch,
event_type, event_day, COALESCE(amount, 0.0)
)::INT -- casts output to type INT
$$ LANGUAGE SQL PARALLEL SAFE COST 5000;Tieni presente quanto segue:
-
Utilizza il parametro
max_rows_per_batchopzionale per fornire il controllo del numero di righe per una chiamata della funzione in modalità batch. Se utilizzi un valore NULL, l'ottimizzatore di query sceglie automaticamente la dimensione batch massima. Per ulteriori informazioni, consulta Informazioni sulla modalità batch e sulle funzioni di machine learning di Aurora. -
Per impostazione predefinita, il passaggio di NULL come valore di un parametro viene tradotto in una stringa vuota prima di passare a AI. SageMaker Per questo esempio i tipi di input sono diversi.
-
Se si dispone di un input non di testo o di un input di testo il cui valore predefinito deve essere diverso da una stringa vuota, utilizza l'istruzione
COALESCE. UtilizzaCOALESCEper convertire NULL nel valore di sostituzione null desiderato nella chiamata aaws_sagemaker.invoke_endpoint. Per il parametroamountin questo esempio, un valore NULL viene convertito in 0.0.
Invocare un modello di SageMaker intelligenza artificiale con più output
L'esempio seguente crea una funzione definita dall'utente per un modello di SageMaker intelligenza artificiale che restituisce più output. La funzione deve eseguire il cast dell'output della funzione aws_sagemaker.invoke_endpoint a un tipo di dati corrispondente. Ad esempio, puoi utilizzare il tipo di punto PostgreSQL incorporato per coppie (x, y) o un tipo composito definito dall'utente.
Questa funzione definita dall'utente restituisce valori da un modello che restituisce più output utilizzando un tipo composito per gli output.
CREATE TYPE company_forecasts AS ( six_month_estimated_return real, one_year_bankruptcy_probability float); CREATE FUNCTION analyze_company ( IN free_cash_flow NUMERIC(18, 6), IN debt NUMERIC(18,6), IN max_rows_per_batch INT DEFAULT NULL, OUT prediction company_forecasts) AS $$ SELECT (aws_sagemaker.invoke_endpoint('endpt_name', max_rows_per_batch,free_cash_flow, debt))::company_forecasts; $$ LANGUAGE SQL PARALLEL SAFE COST 5000;
Per il tipo composito, utilizza i campi nello stesso ordine in cui vengono visualizzati nell'output del modello ed esegui il cast dell'output del aws_sagemaker.invoke_endpoint al tipo composito. Il chiamante può estrarre i singoli campi per nome o con notazione PostgreSQL ".*".
Esportazione di dati in Amazon S3 SageMaker per la formazione su modelli di intelligenza artificiale (Advanced)
Ti consigliamo di acquisire familiarità con l'apprendimento automatico e l' SageMaker intelligenza artificiale di Aurora utilizzando gli algoritmi e gli esempi forniti anziché provare ad addestrare i tuoi modelli. Per ulteriori informazioni, consulta Get Started with Amazon SageMaker AI
Per addestrare i modelli di SageMaker intelligenza artificiale, esporti i dati in un bucket Amazon S3. Il bucket Amazon S3 viene utilizzato dall' SageMaker intelligenza artificiale per addestrare il modello prima che venga distribuito. Puoi eseguire query dei dati da un cluster di database Aurora PostgreSQL e salvarli direttamente nei file di testo archiviati in un bucket Amazon S3. Quindi l' SageMaker intelligenza artificiale utilizza i dati del bucket Amazon S3 per la formazione. Per ulteriori informazioni sulla formazione dei modelli di SageMaker intelligenza artificiale, consulta Addestrare un modello con Amazon SageMaker AI.
Nota
Quando crei un bucket Amazon S3 per la formazione sui modelli di SageMaker intelligenza artificiale o il punteggio in batch, utilizzalo nel nome del bucket sagemaker Amazon S3. Per ulteriori informazioni, consulta Specificare un bucket Amazon S3 per caricare set di dati di formazione e archiviare i dati di output nella Amazon SageMaker AI Developer Guide.
Per ulteriori informazioni sull'esportazione dei dati, consulta Esportazione di dati da del cluster di database Aurora PostgreSQLRDS per PostgreSQL a Amazon S3.
Considerazioni sulle prestazioni per l'utilizzo del machine learning di Aurora con Aurora PostgreSQL
I servizi Amazon Comprehend e SageMaker AI svolgono la maggior parte del lavoro quando vengono richiamati da una funzione di machine learning di Aurora. Ciò significa che è possibile dimensionare tali risorse in base alle esigenze, in modo indipendente. Per il cluster database Aurora PostgreSQL, puoi ottenere il massimo dell'efficienza dalle tue chiamate di funzione. Di seguito sono riportate alcune considerazioni sulle prestazioni da tenere presenti quando si usa il machine learning di Aurora da Aurora PostgreSQL.
Argomenti
Informazioni sulla modalità batch e sulle funzioni di machine learning di Aurora
In genere PostgreSQL esegue le funzioni una riga alla volta. Il machine learning di Aurora può ridurre questo sovraccarico combinando in batch le chiamate al servizio di machine learning di Aurora esterno per molte righe con un approccio chiamato esecuzione in modalità batch. In modalità batch, Aurora Machine Learning riceve le risposte per un batch di righe di input e quindi restituisce le risposte alla query in esecuzione una riga alla volta. Questa ottimizzazione migliora il throughput delle query Aurora senza limitare l'ottimizzatore di query PostgreSQL.
Aurora utilizza automaticamente la modalità batch se si fa riferimento alla funzione dall'elenco SELECT, da una clausola WHERE o da una clausola HAVING. Tieni presente che le CASE espressioni semplici di primo livello sono idonee per l'esecuzione in modalità batch. Top-level CASEle espressioni ricercate sono idonee anche per l'esecuzione in modalità batch, a condizione che la prima WHEN clausola sia un predicato semplice con una chiamata di funzione in modalità batch.
La funzione definita dall'utente deve essere LANGUAGE SQL e deve specificare PARALLEL SAFE e COST 5000.
Migrazione di funzioni dall'istruzione SELECT alla clausola FROM
In genere, una funzione aws_ml che è idonea per l'esecuzione in modalità batch viene migrata automaticamente da Aurora alla clausola FROM.
La migrazione delle funzioni in modalità batch idonee alla clausola FROM può essere esaminata manualmente a livello di query. A tale scopo, utilizza le istruzioni EXPLAIN (e ANALYZE e VERBOSE) e trova le informazioni "Elaborazione in batch" sotto ogni modalità batch Function Scan. Puoi inoltre utilizzare EXPLAIN (con VERBOSE) senza eseguire la query. Osserva quindi se le chiamate alla funzione vengono visualizzate come un Function
Scan in un join loop nidificato che non è stato specificato nell'istruzione originale.
Nell'esempio seguente, l'operatore join loop nidificato nel piano mostra che Aurora ha migrato la funzione anomaly_score. Ha migrato questa funzione dall'elenco SELECT alla clausola FROM, dove è idonea per l'esecuzione in modalità batch.
EXPLAIN (VERBOSE, COSTS false)
SELECT anomaly_score(ts.R.description) from ts.R;
QUERY PLAN
-------------------------------------------------------------
Nested Loop
Output: anomaly_score((r.description)::text)
-> Seq Scan on ts.r
Output: r.id, r.description, r.score
-> Function Scan on public.anomaly_score
Output: anomaly_score.anomaly_score
Function Call: anomaly_score((r.description)::text)Per disabilitare l'esecuzione in modalità batch, imposta il parametro apg_enable_function_migration su false. Ciò impedisce la migrazione delle funzioni aws_ml da SELECT alla clausola FROM. L'esempio seguente mostra come eseguire questa operazione.
SET apg_enable_function_migration = false;Il parametro apg_enable_function_migration è di tipo GUC (Grand Unified Configuration) riconosciuto dall'estensione Aurora PostgreSQL apg_plan_mgmt per la gestione del piano di query. Per disabilitare la migrazione di funzioni in una sessione, utilizza la gestione del piano di query per salvare il piano risultante come un piano approved. In fase di runtime, la gestione del piano di query applica il piano approved con la relativa impostazione apg_enable_function_migration. Questa imposizione si verifica a prescindere dall'impostazione del parametro GUC apg_enable_function_migration. Per ulteriori informazioni, consulta Gestione dei piani di esecuzione delle query per Aurora PostgreSQL.
Utilizzo del parametro max_rows_per_batch
Entrambe le funzioni aws_comprehend.detect_sentiment e aws_sagemaker.invoke_endpoint hanno un parametro max_rows_per_batch. Questo parametro specifica il numero di righe che possono essere inviate al servizio di machine learning di Aurora. Più grande è il set di dati elaborato dalla funzione, maggiore può essere la dimensione del batch.
Batch-mode le funzioni migliorano l'efficienza creando batch di righe che distribuiscono il costo delle chiamate alle funzioni di machine learning di Aurora su un gran numero di righe. Tuttavia, se un'istruzione SELECT termina in anticipo a causa di una clausola LIMIT, il batch può essere costruito su più righe rispetto a quelle utilizzate dalla query. Questo approccio può comportare costi aggiuntivi sul tuo AWS account. Per ottenere i vantaggi dell'esecuzione in modalità batch, ma evitare di creare batch troppo grandi, utilizza un valore più piccolo per il parametro max_rows_per_batch nelle chiamate di funzione.
Se esegui un EXPLAIN (VERBOSE, ANALYZE) di una query che utilizza l'esecuzione in modalità batch, viene visualizzato un operatore FunctionScan che si trova sotto un join loop nidificato. Il numero di loop segnalati da EXPLAIN indica il numero di volte che una riga è stata recuperata dall'operatore FunctionScan. Se un'istruzione utilizza una clausola LIMIT, il numero di recuperi è coerente. Per ottimizzare le dimensioni del batch, imposta il parametro max_rows_per_batch su questo valore. Tuttavia, se si fa riferimento alla funzione in modalità batch in un predicato nella clausola WHERE o HAVING, probabilmente non è possibile conoscere il numero di recuperi in anticipo. In questo caso, utilizza i loop come una linea guida ed esegui esperimenti con max_rows_per_batch per trovare un'impostazione che ottimizzi le prestazioni.
Verifica dell'esecuzione in modalità batch
Per verificare se una funzione è stata eseguita in modalità batch, utilizzare EXPLAIN ANALYZE. Se è stata utilizzata l'esecuzione in modalità batch, il piano di query includerà le informazioni in una sezione "Elaborazione in batch".
EXPLAIN ANALYZE SELECT user-defined-function();
Batch Processing: num batches=1 avg/min/max batch size=3333.000/3333.000/3333.000
avg/min/max batch call time=146.273/146.273/146.273Questo esempio prevedeva 1 batch che conteneva 3.333 righe, che richiedevano 146,273 ms per l'elaborazione. La sezione "Elaborazione in batch" mostra quanto segue:
-
Il numero di batch per questa operazione di scansione funzione
-
La dimensione media, minima e massima del batch
-
Il tempo di esecuzione medio, minimo e massimo del batch
In genere le dimensioni del batch finale sono inferiore al resto. Questo si traduce spesso in una dimensione batch minima molto inferiore rispetto alla media.
Per restituire le prime righe più rapidamente, imposta il parametro max_rows_per_batch su un valore più piccolo.
Per ridurre il numero di chiamate in modalità batch al servizio ML quando utilizzi un LIMIT nella funzione definita dall'utente, imposta il parametro max_rows_per_batch su un valore inferiore.
Miglioramento dei tempi di risposta con l'elaborazione di query parallela
Per ottenere risultati il più velocemente possibile da un numero elevato di righe, puoi combinare l'elaborazione di query parallela con l'elaborazione in modalità batch. Puoi utilizzare l'elaborazione di query parallela per istruzioni SELECT, CREATE TABLE AS SELECT e CREATE
MATERIALIZED VIEW.
Nota
PostgreSQL non supporta ancora la query parallela per le istruzioni DML (Data Manipulation Language).
L'elaborazione di query parallela avviene sia all'interno del database sia all'interno del servizio ML. Il numero di core nella classe di istanza del database limita il grado di parallelismo che può essere utilizzato durante l'esecuzione di query. Il server di database può costruire un piano di esecuzione di query parallela che partiziona l'attività tra un set di lavoratori paralleli. Quindi ciascuno di questi lavoratori può creare richieste in batch contenenti decine di migliaia di righe (o il numero consentito da ciascun servizio).
Le richieste in batch di tutti i parallel worker vengono inviate all'endpoint SageMaker AI. Il grado di parallelismo supportato dall'endpoint è limitato dal numero e dal tipo di istanze che lo supportano. Per i gradi K di parallelismo, è necessaria una classe di istanza database con almeno i core K. È inoltre necessario configurare l'endpoint SageMaker AI per il modello in modo che abbia K istanze iniziali di una classe di istanze sufficientemente performante.
Per utilizzare l'elaborazione di query parallela, puoi impostare il parametro di archiviazione parallel_workers della tabella contenente i dati che intendi passare. Imposta parallel_workers su una funzione in modalità batch, ad esempio aws_comprehend.detect_sentiment. Se l'ottimizzatore sceglie un piano di query parallelo, i servizi AWS ML possono essere chiamati sia in batch che in parallelo.
Puoi utilizzare i seguenti parametri con la funzione aws_comprehend.detect_sentiment per ottenere un piano con parallelismo a quattro vie. Se modifichi uno dei due parametri seguenti, è necessario riavviare l'istanza database per rendere effettive le modifiche.
-- SET max_worker_processes to 8; -- default value is 8
-- SET max_parallel_workers to 8; -- not greater than max_worker_processes
SET max_parallel_workers_per_gather to 4; -- not greater than max_parallel_workers
-- You can set the parallel_workers storage parameter on the table that the data
-- for the Aurora machine learning function is coming from in order to manually override the degree of
-- parallelism that would otherwise be chosen by the query optimizer
--
ALTER TABLE yourTable SET (parallel_workers = 4);
-- Example query to exploit both batch-mode execution and parallel query
EXPLAIN (verbose, analyze, buffers, hashes)
SELECT aws_comprehend.detect_sentiment(description, 'en')).*
FROM yourTable
WHERE id < 100;Per ulteriori informazioni sul controllo della query parallela, consulta Parallel plans
Utilizzo di viste materializzate e colonne materializzate
Quando richiami un AWS servizio come SageMaker AI o Amazon Comprehend dal tuo database, il tuo account viene addebitato in base alla politica tariffaria di quel servizio. Per ridurre al minimo gli addebiti sul tuo account, puoi inserire il risultato della chiamata al AWS servizio in una colonna materializzata in modo che il AWS servizio non venga richiamato più di una volta per riga di input. Se lo desideri, puoi aggiungere una colonna timestamp materializedAt per registrare l'ora in cui le colonne sono state materializzate.
La latenza di un'istruzione INSERT a riga singola ordinaria è in genere molto inferiore rispetto alla latenza di chiamata di una funzione in modalità batch. Pertanto, potrebbe non essere possibile soddisfare i requisiti di latenza dell'applicazione se si invoca la funzione in modalità batch per ogni singola riga INSERT eseguita dall'applicazione. Per concretizzare il risultato della chiamata di un AWS servizio in una colonna materializzata, le applicazioni ad alte prestazioni in genere devono compilare le colonne materializzate. A tale scopo, inviano periodicamente un'istruzione UPDATE che opera contemporaneamente su un batch di righe di grandi dimensioni.
UPDATE accetta un blocco a livello di riga che può influire su un'applicazione in esecuzione. Quindi potrebbe essere necessario utilizzare SELECT ... FOR UPDATE SKIP LOCKED o MATERIALIZED
VIEW.
Le query analitiche che agiscono su un numero elevato di righe in tempo reale possono combinare la materializzazione in modalità batch con l'elaborazione in tempo reale. A tale scopo, queste query assemblano un UNION ALL dei risultati pre-materializzati con una query sulle righe che non dispongono ancora di risultati materializzati. In alcuni casi, tale UNION ALL è necessario in più posizioni o la query viene generata da un'applicazione di terze parti. In tal caso, puoi creare un VIEW per incapsulare l'operazione UNION ALL in modo che questo dettaglio non venga esposto al resto dell'applicazione SQL.
Puoi utilizzare una vista materializzata per materializzare i risultati di un'istruzione SELECT arbitraria in una snapshot nel tempo. Puoi inoltre utilizzarla per aggiornare la vista materializzata in qualsiasi momento in futuro. Attualmente PostgreSQL non supporta l'aggiornamento incrementale, quindi la vista materializzata viene completamente ricalcolata ogni volta che viene aggiornata.
Puoi aggiornare le viste materializzate con l'opzione CONCURRENTLY, che aggiorna il contenuto della vista materializzata senza acquisire un blocco esclusivo. In questo modo un'applicazione SQL può leggere dalla vista materializzata durante l'aggiornamento.
Monitoraggio del machine learning di Aurora
È possibile monitorare le funzioni aws_ml impostando su all il parametro track_functions nel gruppo di parametri personalizzato del cluster database. Per impostazione predefinita, questo parametro è impostato su pl, il che significa che vengono monitorate solo le funzioni del linguaggio procedurale. Modificando questa impostazione su all, vengono monitorate anche le funzioni aws_ml. Per ulteriori informazioni, consulta Run-time Statistics
Per informazioni sul monitoraggio delle prestazioni delle operazioni di SageMaker intelligenza artificiale richiamate dalle funzioni di machine learning di Aurora, consulta Monitor Amazon SageMaker AI nella Amazon SageMaker AI Developer Guide.
Con track_functions impostato su all, puoi eseguire le query nella visualizzazione pg_stat_user_functions per ottenere le statistiche sulle funzioni che definisci e utilizzi per richiamare i servizi di machine learning di Aurora. La visualizzazione fornisce il numero di calls, total_time e self_time per ogni funzione.
Per visualizzare le statistiche per le funzioni aws_sagemaker.invoke_endpoint e aws_comprehend.detect_sentiment puoi filtrare i risultati in base al nome dello schema utilizzando la seguente query.
SELECT * FROM pg_stat_user_functions WHERE schemaname LIKE 'aws_%';
Per cancellare le statistiche, procedi come indicato di seguito.
SELECT pg_stat_reset();
Puoi ottenere i nomi delle funzioni SQL che chiamano la funzione aws_sagemaker.invoke_endpoint eseguendo query nel catalogo di sistema pg_proc PostgreSQL. Questo catalogo contiene informazioni su funzioni, procedure e altri elementi. Per ulteriori informazioni, consulta pg_procproname) la cui origine (prosrc) include il testo invoke_endpoint.
SELECT proname FROM pg_proc WHERE prosrc LIKE '%invoke_endpoint%';
