Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Utilizzo di machine learning di Amazon Aurora con Aurora MySQL
Utilizzando l'apprendimento automatico di Amazon Aurora con il tuo cluster Aurora MySQL DB, puoi usare Amazon Bedrock, Amazon Comprehend o Amazon AI, a seconda delle tue esigenze. SageMaker Ciascuno di essi supporta casi d’uso di machine learning diversi.
Indice
Requisiti per l'utilizzo di machine learning di Aurora con Aurora MySQL
Funzionalità supportate e limitazioni del machine learning di Aurora con Aurora MySQL
Configurazione del cluster database Aurora per utilizzare machine learning di Aurora
Configurazione del cluster di database Aurora MySQL per utilizzare Amazon Bedrock
Configurazione del cluster database Aurora MySQL per utilizzare Amazon Comprehend
Configurazione del cluster Aurora MySQL DB per l'utilizzo dell'IA SageMaker
Concessione agli utenti del database dell'accesso a machine learning di Aurora
Utilizzo di Amazon Bedrock con il cluster di database Aurora MySQL
Utilizzo di Amazon Comprehend con il cluster database Aurora MySQL
Utilizzo dell' SageMaker intelligenza artificiale con il cluster Aurora MySQL DB
Considerazioni sulle prestazioni per l'utilizzo del machine learning di Aurora con Aurora MySQL
Requisiti per l'utilizzo di machine learning di Aurora con Aurora MySQL
AWS i servizi di apprendimento automatico sono servizi gestiti che vengono configurati ed eseguiti nei propri ambienti di produzione. L'apprendimento automatico Aurora supporta l'integrazione con Amazon Bedrock, Amazon Comprehend e AI. SageMaker Prima di provare a configurare il cluster database Aurora MySQL per utilizzare il machine learning di Aurora, occorre accertarsi di aver compreso i requisiti e prerequisiti riportati di seguito.
-
I servizi di machine learning devono essere eseguiti nello Regione AWS stesso cluster Aurora MySQL DB. Non è possibile utilizzare i servizi di machine learning da un cluster di database Aurora MySQL in una Regione diversa.
-
Se il cluster Aurora MySQL DB si trova in un cloud pubblico virtuale (VPC) diverso dal servizio Amazon Bedrock, Amazon Comprehend o SageMaker AI, il gruppo Security del VPC deve consentire le connessioni in uscita al servizio di machine learning Aurora di destinazione. Per ulteriori informazioni, consulta Controlla il traffico verso le tue risorse AWS utilizzando gruppi di sicurezza nella Amazon VPC User Guide.
-
È possibile aggiornare un cluster Aurora che esegue una versione precedente di Aurora MySQL a una versione più recente se si desidera utilizzare Aurora machine learning con tale cluster. Per ulteriori informazioni, consulta Aggiornamenti del motore del database per Amazon Aurora MySQL.
-
Il cluster di database Aurora MySQL deve utilizzare un gruppo di parametri cluster di database personalizzato. Al termine del processo di configurazione per ogni servizio di machine learning di Aurora che desideri utilizzare, aggiungi il nome della risorsa Amazon (ARN) del ruolo IAM associato che è stato creato per il servizio. Ti consigliamo di creare in anticipo un gruppo di parametri cluster database personalizzato per Aurora MySQL e di configurare il cluster database Aurora MySQL per utilizzarlo in modo che sia pronto per la modifica alla fine del processo di configurazione.
-
Per SageMaker l'IA:
-
I componenti di machine learning da utilizzare per le inferenze devono essere configurati e pronti all’uso. Durante il processo di configurazione del cluster Aurora MySQL DB, assicurati di avere a disposizione l'ARN dell'endpoint AI. SageMaker I data scientist del tuo team sono probabilmente i più adatti a gestire il lavoro con l' SageMaker intelligenza artificiale per preparare i modelli e gestire le altre attività simili. Per iniziare a usare Amazon SageMaker AI, consulta Get Started with Amazon SageMaker AI. Per ulteriori informazioni su inferenze ed endpoint, consulta Real-time inferenza.
-
Per utilizzare l' SageMaker intelligenza artificiale con i tuoi dati di addestramento, devi configurare un bucket Amazon S3 come parte della configurazione Aurora MySQL per l'apprendimento automatico Aurora. A tale scopo, segui la stessa procedura generale utilizzata per la configurazione dell'integrazione AI. SageMaker Per un riepilogo di questo processo di configurazione facoltativo, consultare Configurazione del cluster Aurora MySQL DB per l'utilizzo di Amazon S3 for AI (opzionale) SageMaker.
-
-
Per i database globali di Aurora, configuri i servizi di machine learning di Aurora che desideri utilizzare in tutto ciò Regioni AWS che compone il tuo database globale Aurora. Ad esempio, se desideri utilizzare l'apprendimento automatico di Aurora con l' SageMaker intelligenza artificiale per il tuo database globale Aurora, esegui le seguenti operazioni per ogni cluster Aurora MySQL DB in ogni: Regione AWS
-
Configura i servizi Amazon SageMaker AI con gli stessi modelli di formazione e gli stessi endpoint per l' SageMaker intelligenza artificiale. Anche questi devono utilizzare gli stessi nomi.
-
Crea i ruoli IAM come descritto in Configurazione del cluster database Aurora per utilizzare machine learning di Aurora.
-
Aggiungi l'ARN del ruolo IAM al gruppo di parametri cluster database Aurora per ciascun cluster database Aurora MySQL in ogni Regione AWS.
Queste attività richiedono che l'apprendimento automatico Aurora sia disponibile per la tua versione di Aurora MySQL in tutti gli elementi che Regioni AWS compongono il tuo database globale Aurora.
-
Disponibilità di regioni e versioni
La disponibilità e il supporto della funzionalità varia tra le versioni specifiche di ciascun motore di database Aurora e tra Regioni AWS.
-
Per informazioni sulla disponibilità della versione e della regione per Amazon Comprehend e Amazon SageMaker AI con Aurora MySQL, consulta. Utilizzo di machine learning di Aurora con Aurora MySQL
-
Amazon Bedrock è supportato solo su Aurora MySQL 3.06 e versioni successive.
Per informazioni sulla disponibilità delle Regioni per Amazon Bedrock, consulta Model support by Regione AWS nella Amazon Bedrock User Guide.
Funzionalità supportate e limitazioni del machine learning di Aurora con Aurora MySQL
Quando utilizzi Aurora MySQL con il machine learning di Aurora, si applicano le seguenti limitazioni:
-
L’estensione per il machine learning di Aurora non supporta le interfacce vettoriali.
-
L’utilizzo delle integrazioni del machine learning di Aurora all’interno di un trigger non è supportato.
Le funzioni di machine learning di Aurora non sono compatibili con la replica della registrazione di log binari (binlog).
-
L'impostazione
--binlog-format=STATEMENTgenera un'eccezione per le chiamate alle funzioni Aurora machine learning. -
Le funzioni di machine Learning di Aurora sono non deterministiche e le funzioni archiviate non deterministiche non sono compatibili con il formato binlog.
Per ulteriori informazioni, consulta Binary Logging Formats
nella documentazione di MySQL. -
-
Le funzioni archiviate che chiamano tabelle con colonne sempre generate non sono supportate. Questo vale per qualsiasi funzione archiviata di Aurora MySQL. Per ulteriori informazioni su questo tipo di colonna, consultare CREATE TABLE and Generated Columns
nella documentazione di MySQL. -
Le funzioni di Amazon Bedrock non supportano
RETURNS JSON. Se necessario, puoi utilizzareCONVERToCASTper eseguire la conversione daTEXTaJSON. -
Amazon Bedrock non supporta richieste batch.
-
Aurora MySQL supporta qualsiasi endpoint SageMaker AI che legge e scrive il formato con valori separati da virgole (CSV), tramite un di.
ContentTypetext/csvQuesto formato è accettato dai seguenti algoritmi di intelligenza artificiale integrati: SageMaker-
Linear Learner
-
Random Cut Forest
-
XGBoost
Per ulteriori informazioni su questi algoritmi, consulta Choose an Algorithm nella Amazon SageMaker AI Developer Guide.
-
Configurazione del cluster database Aurora per utilizzare machine learning di Aurora
Nei seguenti argomenti sono illustrate le procedure di configurazione separate per ciascuno di questi servizi di machine learning di Aurora.
Argomenti
Configurazione del cluster di database Aurora MySQL per utilizzare Amazon Bedrock
Configurazione del cluster database Aurora MySQL per utilizzare Amazon Comprehend
Configurazione del cluster Aurora MySQL DB per l'utilizzo dell'IA SageMaker
Concessione agli utenti del database dell'accesso a machine learning di Aurora
Configurazione del cluster di database Aurora MySQL per utilizzare Amazon Bedrock
L'apprendimento automatico di Aurora si basa su ruoli e policy AWS Identity and Access Management (IAM) per consentire al cluster Aurora MySQL DB di accedere e utilizzare i servizi Amazon Bedrock. Le seguenti procedure creano un ruolo e una policy di autorizzazione IAM per consentire al cluster di database di integrarsi con Amazon Bedrock.
Per creare la policy IAM
Accedi e apri la console IAM all' Console di gestione AWS indirizzo. https://console.aws.amazon.com/iam/
-
Nel riquadro di navigazione, scegli Policy.
-
Scegliere Create a policy (Crea una policy).
-
Nella pagina Specifica le autorizzazioni, in Seleziona un servizio scegli Bedrock.
Vengono visualizzate le autorizzazioni di Amazon Bedrock.
-
Espandi Leggi, quindi seleziona InvokeModel.
-
In Risorse, seleziona Tutte.
La pagina Specifica le autorizzazioni dovrebbe essere simile alla figura seguente.

-
Scegli Next (Successivo).
-
Nella pagina Rivedi e crea, inserisci un nome per la policy, ad esempio
BedrockInvokeModel. -
Esamina la policy, quindi scegli Crea policy.
A questo punto, crea il ruolo IAM che utilizza la policy di autorizzazione di Amazon Bedrock.
Per creare il ruolo IAM
Accedi Console di gestione AWS e apri la console IAM all'indirizzo https://console.aws.amazon.com/iam/
. -
Nel riquadro di navigazione scegliere Roles (Ruoli).
-
Scegli Crea ruolo.
-
Nella pagina Seleziona un’entità attendibile, in Caso d’uso scegli RDS.
-
Seleziona RDS - Aggiungi ruolo al database, quindi scegli Avanti.
-
Nella pagina Aggiungi autorizzazioni, in Policy di autorizzazione, seleziona la policy IAM che hai creato, quindi scegli Avanti.
-
Nella pagina Nomina, verifica e crea, inserisci un nome per il ruolo, ad esempio
ams-bedrock-invoke-model-role.Il ruolo dovrebbe essere simile alla figura seguente.
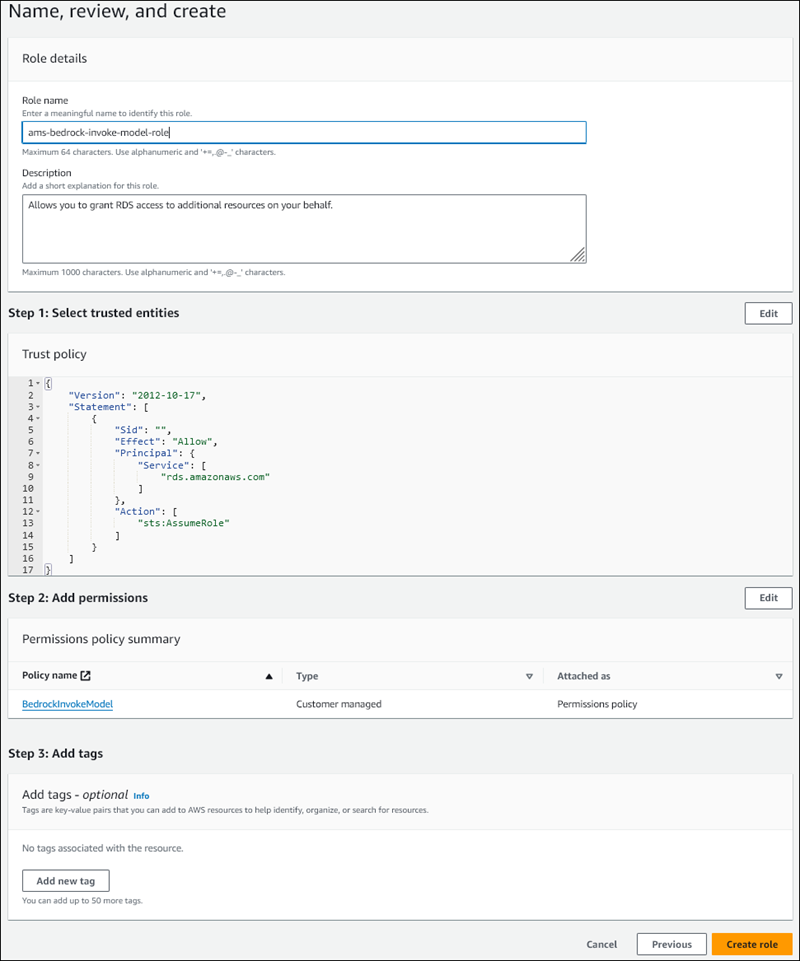
-
Verifica il ruolo, quindi scegli Crea ruolo.
Associa quindi il ruolo IAM Amazon Bedrock al cluster di database.
Per associare il ruolo IAM al tuo cluster di database
Accedi a Console di gestione AWS e apri la console Amazon RDS all'indirizzo https://console.aws.amazon.com/rds/
. -
Nel pannello di navigazione seleziona Database.
-
Scegli il cluster di database Aurora MySQL da collegare ai servizi Amazon Bedrock.
-
Scegliere la scheda Connectivity & security (Connettività e sicurezza).
-
Nella sezione Gestisci ruoli IAM, scegli Seleziona IAM da aggiungere a questo cluster.
-
Scegli l’IAM che hai creato, quindi seleziona Aggiungi ruolo.
Il ruolo IAM viene associato al tuo cluster di database, prima con lo stato In attesa, quindi con lo stato Attivo. Al termine del processo, il ruolo è disponibile nell'elenco Ruoli IAM attuali per questo cluster.
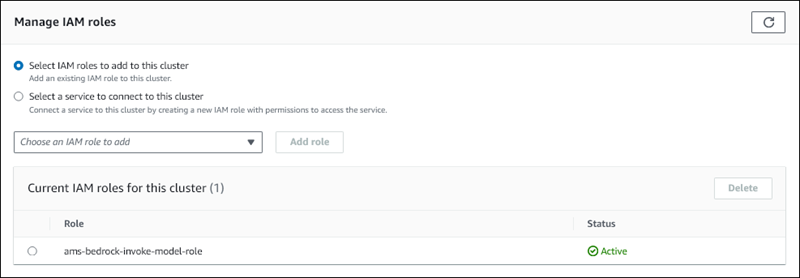
È necessario impostare l’ARN di questo ruolo IAM sul parametro aws_default_bedrock_role del parametro del cluster di database personalizzato associato al cluster di database Aurora MySQL. Se il cluster database Aurora MySQL non utilizza un gruppo di parametri cluster database personalizzato, è necessario crearne uno da utilizzare con il cluster database Aurora MySQL per completare l'integrazione. Per ulteriori informazioni, consulta Gruppi di parametri del cluster di database per i cluster di database Amazon Aurora.
Per configurare i parametri del cluster di database
-
Nella console Amazon RDS, apri la scheda Configurazione del cluster database Aurora MySQL.
-
Individua il gruppo di parametri del cluster di database configurato per il cluster. Scegli il collegamento per aprire il gruppo di parametri del cluster di database personalizzato, quindi seleziona Modifica.
-
Individua il parametro
aws_default_bedrock_rolenel gruppo di parametri cluster database personalizzato. -
Nel campo Valore, immetti l’ARN del ruolo IAM.
-
Scegli Salva modifiche per salvare l'impostazione.
-
Riavvia l'istanza primaria del cluster database Aurora MySQL per rendere effettiva questa impostazione del parametro.
L’integrazione con IAM per Amazon Bedrock è stata completata. Continua a configurare il cluster di database Aurora MySQL in modo che funzioni con Amazon Bedrock in base ai Concessione agli utenti del database dell'accesso a machine learning di Aurora.
Configurazione del cluster database Aurora MySQL per utilizzare Amazon Comprehend
L'apprendimento automatico Aurora si basa su AWS Identity and Access Management ruoli e policy per consentire al cluster Aurora MySQL DB di accedere e utilizzare i servizi Amazon Comprehend. La seguente procedura crea automaticamente un ruolo e una policy IAM per il cluster in modo che possa utilizzare Amazon Comprehend.
Come configurare il cluster database Aurora MySQL per utilizzare Amazon Comprehend
Accedi a Console di gestione AWS e apri la console Amazon RDS all'indirizzo https://console.aws.amazon.com/rds/
. -
Nel pannello di navigazione seleziona Database.
-
Scegli il cluster di database Aurora MySQL da collegare ai servizi Amazon Comprehend.
-
Scegliere la scheda Connectivity & security (Connettività e sicurezza).
-
Scorri fino alla sezione Gestisci ruoli IAM, quindi scegli Seleziona un servizio per connetterti a questo cluster.
-
Scegli Amazon Comprehend dal menu, quindi seleziona Connetti un servizio.
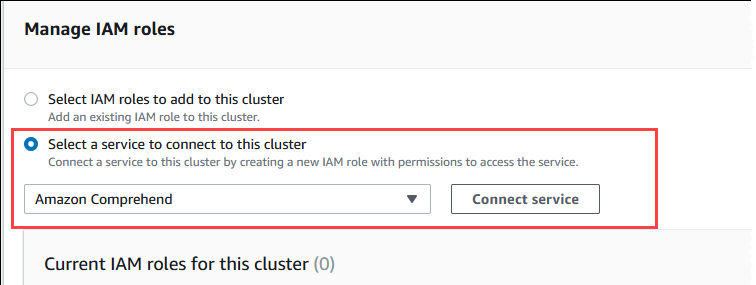
La finestra di dialogo Connetti il cluster ad Amazon Comprehend non richiede informazioni aggiuntive. Tuttavia, è possibile che venga visualizzato un messaggio che segnala che l'integrazione tra Aurora e Amazon Comprehend è al momento è in fase di anteprima. Assicurati di leggere il messaggio prima di continuare. Se preferisci non continuare, puoi scegliere Annulla.
Scegli Connetti un servizio per completare il processo di integrazione.
Aurora crea il ruolo IAM. Inoltre, crea la policy che consente al cluster di database Aurora MySQL di utilizzare i servizi Amazon Comprehend e collegare la policy al ruolo. Al termine del processo, il ruolo è disponibile nell'elenco Ruoli IAM attuali per questo cluster, come illustrato nell'immagine seguente.
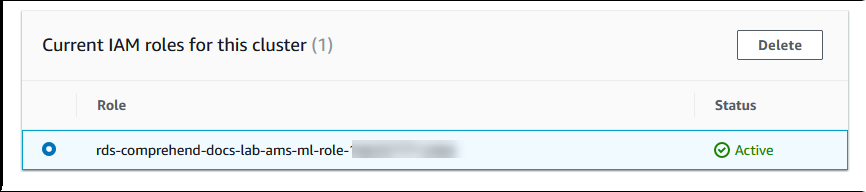
È necessario impostare l’ARN di questo ruolo IAM sul parametro
aws_default_comprehend_roledel parametro del cluster di database personalizzato associato al cluster di database Aurora MySQL. Se il cluster database Aurora MySQL non utilizza un gruppo di parametri cluster database personalizzato, è necessario crearne uno da utilizzare con il cluster database Aurora MySQL per completare l'integrazione. Per ulteriori informazioni, consulta Gruppi di parametri del cluster di database per i cluster di database Amazon Aurora.Dopo aver creato il gruppo di parametri cluster database personalizzato e averlo associato al cluster database Aurora MySQL, puoi continuare a seguire questi passaggi.
Se il cluster utilizza un gruppo di parametri cluster database personalizzato, procedi come descritto di seguito.
Nella console Amazon RDS, apri la scheda Configurazione del cluster database Aurora MySQL.
-
Individua il gruppo di parametri del cluster di database configurato per il cluster. Scegli il collegamento per aprire il gruppo di parametri del cluster di database personalizzato, quindi seleziona Modifica.
Individua il parametro
aws_default_comprehend_rolenel gruppo di parametri cluster database personalizzato.Nel campo Valore, immetti l’ARN del ruolo IAM.
Scegli Salva modifiche per salvare l'impostazione. Nell'immagine seguente, è disponibile un esempio.
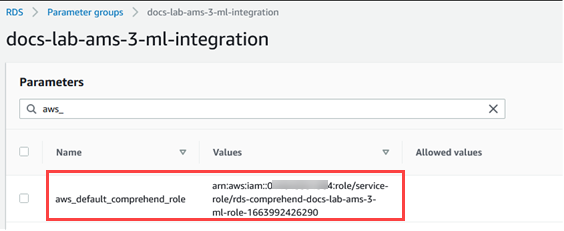
Riavvia l'istanza primaria del cluster database Aurora MySQL per rendere effettiva questa impostazione del parametro.
L'integrazione con IAM per Amazon Comprehend è stata completata. Continua a configurare il cluster database Aurora MySQL per funzionare con Amazon Comprehend concedendo l'accesso agli utenti del database appropriati.
Configurazione del cluster Aurora MySQL DB per l'utilizzo dell'IA SageMaker
La procedura seguente crea automaticamente il ruolo e la policy IAM per il cluster Aurora MySQL DB in modo che possa utilizzare l'IA. SageMaker Prima di provare a seguire questa procedura, assicurati di avere a disposizione l'endpoint SageMaker AI in modo da poterlo inserire quando necessario. In genere, i data scientist del team eseguono il lavoro per produrre un endpoint che è possibile utilizzare dal cluster database Aurora MySQL. Puoi trovare tali endpoint nella console SageMaker AI
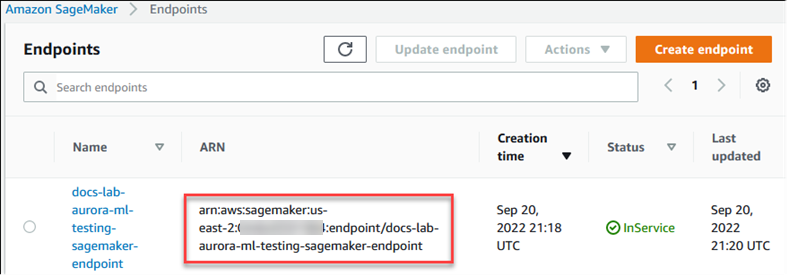
Per configurare il cluster Aurora MySQL DB per utilizzare l'intelligenza artificiale SageMaker
Accedi a Console di gestione AWS e apri la console Amazon RDS all'indirizzo https://console.aws.amazon.com/rds/
. -
Scegli Database dal menu di navigazione di Amazon RDS, quindi scegli il cluster Aurora MySQL DB che desideri connettere ai servizi AI. SageMaker
-
Scegliere la scheda Connectivity & security (Connettività e sicurezza).
-
Scorri fino alla sezione Gestisci ruoli IAM, quindi scegli Seleziona un servizio per connetterti a questo cluster. Scegli SageMaker AI dal selettore.
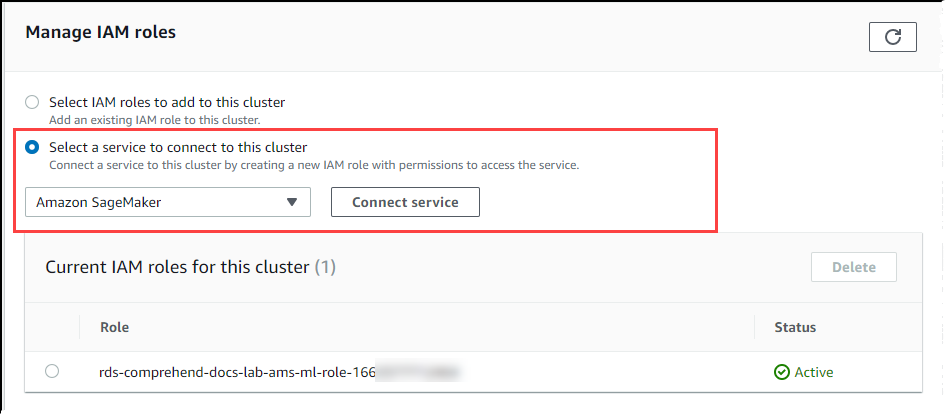
Scegliere Connect service (Connetti servizio).
Nella finestra di dialogo Connect cluster to SageMaker AI, inserisci l'ARN dell'endpoint SageMaker AI.
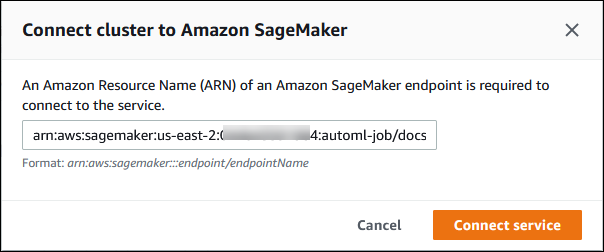
-
Aurora crea il ruolo IAM. Crea inoltre la policy che consente al cluster Aurora MySQL DB di utilizzare i servizi di SageMaker intelligenza artificiale e allega la policy al ruolo. Al termine del processo, il ruolo è disponibile nell'elenco Ruoli IAM attuali per questo cluster.
Aprire la console IAM all'indirizzo https://console.aws.amazon.com/iam/
. Scegli Ruoli dalla sezione Gestione degli accessi del menu di navigazione AWS Identity and Access Management .
Trova il ruolo tra quelli elencati. Il suo nome utilizza il seguente schema.
rds-sagemaker-your-cluster-name-role-auto-generated-digitsApri la pagina di riepilogo del ruolo e individua l'ARN. Prendi nota dell'ARN o copialo utilizzando il widget copy.
Aprire la console Amazon RDS all'indirizzo https://console.aws.amazon.com/rds/
. Scegli il cluster database Aurora MySQL, quindi seleziona la sua scheda Configurazione.
Individua il gruppo di parametri cluster database e scegli il collegamento per aprire il gruppo di parametri cluster database personalizzato. Trova il parametro
aws_default_sagemaker_rolee immetti l'ARN del ruolo IAM nel campo Valore, quindi salva l'impostazione.Riavvia l'istanza primaria del cluster database Aurora MySQL per rendere effettiva questa impostazione del parametro.
La configurazione di IAM è ora completata. Continua a configurare il cluster Aurora MySQL DB per funzionare con l' SageMaker intelligenza artificiale concedendo l'accesso agli utenti del database appropriati.
Se desideri utilizzare i tuoi modelli di SageMaker intelligenza artificiale per la formazione anziché utilizzare componenti SageMaker AI predefiniti, devi anche aggiungere il bucket Amazon S3 al tuo cluster Aurora MySQL DB, come indicato di seguito. Configurazione del cluster Aurora MySQL DB per l'utilizzo di Amazon S3 for AI (opzionale) SageMaker
Configurazione del cluster Aurora MySQL DB per l'utilizzo di Amazon S3 for AI (opzionale) SageMaker
Per utilizzare l' SageMaker intelligenza artificiale con i tuoi modelli anziché utilizzare i componenti predefiniti forniti dall' SageMaker IA, devi configurare un bucket Amazon S3 per il cluster Aurora MySQL DB da utilizzare. Per ulteriori informazioni sulla creazione di un bucket Amazon S3, consultaCreazione di un bucketnellaGuida all'utente di Amazon Simple Storage Service.
Per configurare il cluster Aurora MySQL DB per utilizzare un bucket Amazon S3 per l'intelligenza artificiale SageMaker
Accedi a Console di gestione AWS e apri la console Amazon RDS all'indirizzo https://console.aws.amazon.com/rds/
. -
Scegli Database dal menu di navigazione di Amazon RDS, quindi scegli il cluster Aurora MySQL DB che desideri connettere ai servizi AI. SageMaker
-
Scegliere la scheda Connectivity & security (Connettività e sicurezza).
-
Scorri fino alla sezione Gestisci ruoli IAM, quindi scegli Seleziona un servizio per connetterti a questo cluster. Scegli Amazon S3 dal selettore.
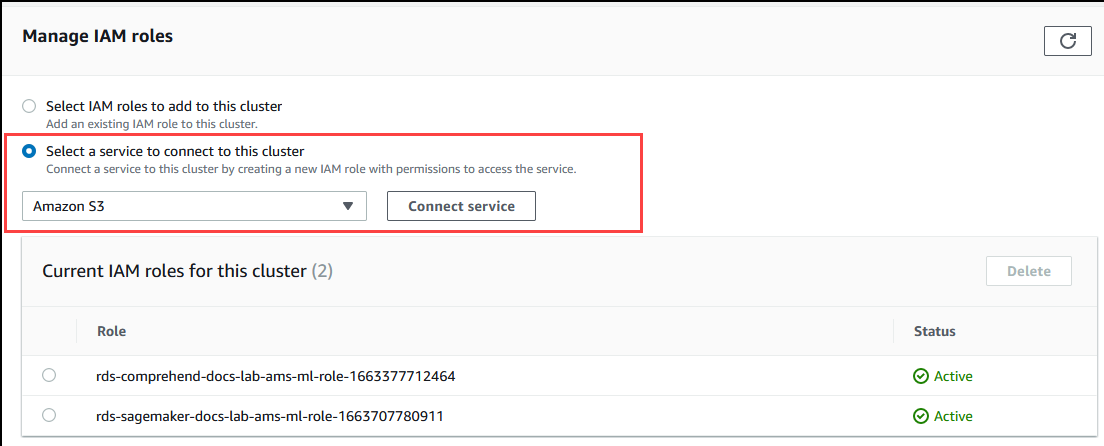
Scegliere Connect service (Connetti servizio).
Nella finestra di dialogo Connetti il cluster ad Amazon S3, inserisci l’ARN del bucket Amazon S3, come mostrato nell’immagine seguente.
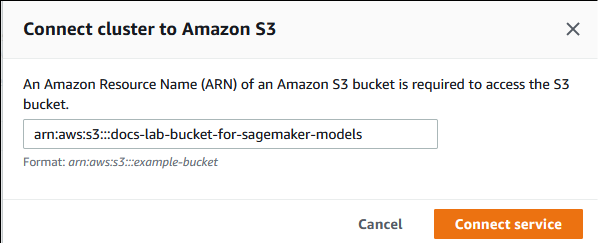
Scegli Connetti un servizio per completare questo processo.
Per ulteriori informazioni sull'uso dei bucket Amazon S3 con l' SageMaker intelligenza artificiale, consulta Specificare un bucket Amazon S3 per caricare set di dati di addestramento e archiviare i dati di output nella Amazon AI Developer Guide. SageMaker Per ulteriori informazioni su come lavorare con l' SageMaker intelligenza artificiale, consulta la sezione Get Started with Amazon SageMaker AI Notebook Instances nella Amazon SageMaker AI Developer Guide.
Concessione agli utenti del database dell'accesso a machine learning di Aurora
Per invocare le funzioni di machine learning di Aurora, gli utenti del database devono disporre dell’autorizzazione appropriata. Il modo in cui l'autorizzazione viene concessa dipende dalla versione di MySQL utilizzata per il cluster database Aurora MySQL, come descritto di seguito. L'operazione utilizzata dipende dalla versione di MySQL utilizzata dal cluster database Aurora MySQL.
Per Aurora MySQL versione 3 (compatibile con MySQL 8.0), gli utenti del database devono disporre del ruolo del database appropriato. Per ulteriori informazioni, consulta Utilizzo di ruoli
nel Manuale di riferimento di MySQL 8.0. Per Aurora MySQL versione 2 (compatibile con MySQL 5.7), gli utenti del database devono disporre di privilegi. Per ulteriori informazioni, consulta Access Control and Account Management
nel Manuale di riferimento di MySQL 5.7.
Nella tabella seguente sono raffigurati i ruoli e i privilegi necessari agli utenti del database per utilizzare le funzioni di machine learning.
| Aurora MySQL versione 3 (ruolo) | Aurora MySQL versione 2 (privilegio) |
|---|---|
|
AWS_BEDROCK_ACCESS |
– |
|
AWS_COMPREHEND_ACCESS |
INVOKE COMPREHEND |
|
AWS_SAGEMAKER_ACCESS |
INVOKE SAGEMAKER |
Concessione dell’accesso alle funzioni di Amazon Bedrock
Per fornire agli utenti del database l’accesso alle funzioni di Amazon Bedrock, utilizza la seguente istruzione SQL:
GRANT AWS_BEDROCK_ACCESS TOuser@domain-or-ip-address;
Per utilizzare Amazon Bedrock, gli utenti del database devono inoltre disporre di autorizzazioni EXECUTE per le funzioni che hai creato.
GRANT EXECUTE ON FUNCTIONdatabase_name.function_nameTOuser@domain-or-ip-address;
Infine, i ruoli degli utenti del database devono essere impostati su AWS_BEDROCK_ACCESS:
SET ROLE AWS_BEDROCK_ACCESS;
Le funzioni di Amazon Bedrock sono ora disponibili per l’uso.
Concessione dell'accesso alle funzioni Amazon Comprehend
Per fornire agli utenti del database l'accesso alle funzioni di Amazon Comprehend, utilizza l'istruzione appropriata per la versione di Aurora MySQL.
Aurora MySQL versione 3 (compatibile con MySQL 8.0)
GRANT AWS_COMPREHEND_ACCESS TOuser@domain-or-ip-address;Aurora MySQL versione 2 (compatibile con MySQL 5.7)
GRANT INVOKE COMPREHEND ON *.* TOuser@domain-or-ip-address;
Le funzioni di Amazon Comprehend sono ora disponibili per l'uso. Per esempi di utilizzo, consultare Utilizzo di Amazon Comprehend con il cluster database Aurora MySQL.
Concessione dell'accesso alle funzioni di intelligenza SageMaker artificiale
Per consentire agli utenti del database di accedere alle funzioni di SageMaker intelligenza artificiale, usa l'istruzione appropriata per la tua versione di Aurora MySQL.
Aurora MySQL versione 3 (compatibile con MySQL 8.0)
GRANT AWS_SAGEMAKER_ACCESS TOuser@domain-or-ip-address;Aurora MySQL versione 2 (compatibile con MySQL 5.7)
GRANT INVOKE SAGEMAKER ON *.* TOuser@domain-or-ip-address;
Agli utenti del database devono inoltre essere concesse EXECUTE le autorizzazioni per le funzioni create per lavorare con l'intelligenza artificiale. SageMaker Supponiamo di aver creato due funzioni db1.anomoly_score e di richiamare db2.company_forecasts i servizi del tuo SageMaker endpoint di intelligenza artificiale. Concedi i privilegi di esecuzione come illustrato nel seguente esempio.
GRANT EXECUTE ON FUNCTION db1.anomaly_score TOuser1@domain-or-ip-address1; GRANT EXECUTE ON FUNCTION db2.company_forecasts TOuser2@domain-or-ip-address2;
Le funzioni di SageMaker intelligenza artificiale sono ora disponibili per l'uso. Per esempi di utilizzo, consultare Utilizzo dell' SageMaker intelligenza artificiale con il cluster Aurora MySQL DB.
Utilizzo di Amazon Bedrock con il cluster di database Aurora MySQL
Per utilizzare Amazon Bedrock, crea nel database Aurora MySQL una funzione definita dall’utente (UDF) che invochi un modello. Per ulteriori informazioni, consulta Modelli supportati in Amazon Bedrock nella Guida per l’utente di Amazon Bedrock.
Le UDF utilizzano la sintassi seguente:
CREATE FUNCTIONfunction_name(argumenttype) [DEFINER = user] RETURNSmysql_data_type[SQL SECURITY {DEFINER | INVOKER}] ALIAS AWS_BEDROCK_INVOKE_MODEL MODEL ID 'model_id' [CONTENT_TYPE 'content_type'] [ACCEPT 'content_type'] [TIMEOUT_MStimeout_in_milliseconds];
-
Le funzioni di Amazon Bedrock non supportano
RETURNS JSON. Se necessario, puoi utilizzareCONVERToCASTper eseguire la conversione daTEXTaJSON. -
Se non specifichi
CONTENT_TYPEoACCEPT, il valore predefinito èapplication/json. -
Se non specifichi
TIMEOUT_MS, il valore predefinito èaurora_ml_inference_timeout.
Ad esempio, la seguente UDF invoca il modello Amazon Titan Text Express:
CREATE FUNCTION invoke_titan (request_body TEXT) RETURNS TEXT ALIAS AWS_BEDROCK_INVOKE_MODEL MODEL ID 'amazon.titan-text-express-v1' CONTENT_TYPE 'application/json' ACCEPT 'application/json';
Per consentire a un utente del database di utilizzare questa funzione, ricorri al seguente comando SQL:
GRANT EXECUTE ON FUNCTIONdatabase_name.invoke_titan TOuser@domain-or-ip-address;
Quindi l’utente può chiamare invoke_titan come qualsiasi altra funzione, come mostrato nell’esempio seguente. Assicurati di formattare il corpo della richiesta in base ai modelli di testo di Amazon Titan.
CREATE TABLE prompts (request varchar(1024)); INSERT INTO prompts VALUES ( '{ "inputText": "Generate synthetic data for daily product sales in various categories - include row number, product name, category, date of sale and price. Produce output in JSON format. Count records and ensure there are no more than 5.", "textGenerationConfig": { "maxTokenCount": 1024, "stopSequences": [], "temperature":0, "topP":1 } }'); SELECT invoke_titan(request) FROM prompts; {"inputTextTokenCount":44,"results":[{"tokenCount":296,"outputText":" ```tabular-data-json { "rows": [ { "Row Number": "1", "Product Name": "T-Shirt", "Category": "Clothing", "Date of Sale": "2024-01-01", "Price": "$20" }, { "Row Number": "2", "Product Name": "Jeans", "Category": "Clothing", "Date of Sale": "2024-01-02", "Price": "$30" }, { "Row Number": "3", "Product Name": "Hat", "Category": "Accessories", "Date of Sale": "2024-01-03", "Price": "$15" }, { "Row Number": "4", "Product Name": "Watch", "Category": "Accessories", "Date of Sale": "2024-01-04", "Price": "$40" }, { "Row Number": "5", "Product Name": "Phone Case", "Category": "Accessories", "Date of Sale": "2024-01-05", "Price": "$25" } ] } ```","completionReason":"FINISH"}]}
Per gli altri modelli che utilizzi, assicurati di formattare il corpo della richiesta in modo appropriato. Per ulteriori informazioni, consulta Parametri di inferenza per modelli di fondazione nella Guida per l’utente di Amazon Bedrock.
Utilizzo di Amazon Comprehend con il cluster database Aurora MySQL
Per Aurora MySQL, il machine learning di Aurora fornisce le due funzioni integrate seguenti per l'utilizzo con Amazon Comprehend e i dati di testo. Viene fornito il testo da analizzare (input_data) e specificata la lingua (language_code).
- aws_comprehend_detect_sentiment
-
Questa funzione identifica il testo come avente un assetto emotivo positivo, negativo, neutro o misto. La documentazione di riferimento di questa funzione è la seguente.
aws_comprehend_detect_sentiment( input_text, language_code [,max_batch_size] )Per ulteriori informazioni, consultare Sentiment nella Guida per gli sviluppatori di Amazon Comprehend.
- aws_comprehend_detect_sentiment_confidence
-
Questa funzione misura il livello di affidabilità del sentiment rilevato per un determinato testo. Restituisce un valore (tipo,
double) che indica l'affidabilità del sentiment assegnato dalla funzione aws_comprehend_detect_sentiment al testo. L'affidabilità è un parametro statistico compreso tra 0 e 1. Più alto è il livello di affidabilità, maggiore è il peso che è possibile assegnare al risultato. Di seguito è riportato un riepilogo della documentazione della funzione.aws_comprehend_detect_sentiment_confidence( input_text, language_code [,max_batch_size] )
In entrambe le funzioni (aws_comprehend_detect_sentiment_confidence, aws_comprehend_detect_sentiment) il parametro max_batch_size utilizza un valore predefinito pari a 25, se uno non è stato specificato. La dimensione del batch deve essere sempre maggiore di zero. max_batch_size può essere utilizzato per ottimizzare le prestazioni delle chiamate di funzione Amazon Comprehend. Un batch di grandi dimensioni ha prestazioni più veloci con un maggiore utilizzo della memoria nel cluster database Aurora MySQL. Per ulteriori informazioni, consulta Considerazioni sulle prestazioni per l'utilizzo del machine learning di Aurora con Aurora MySQL.
Per ulteriori informazioni sui parametri e sui tipi di rendimento per le funzioni di rilevamento del sentiment in Amazon Comprehend, consulta DetectSentiment
Esempio Esempio: una semplice query che utilizza funzioni Amazon Comprehend
Di seguito è riportato un esempio di una semplice query che richiama queste due funzioni per determinare il livello di soddisfazione dei clienti per il team di supporto. Si supponga di avere una tabella di database (support) che archivia il feedback dei clienti dopo ogni richiesta di assistenza. Questa query di esempio applica entrambe le funzioni integrate al testo nella colonna feedback della tabella e restituisce i risultati. I valori di affidabilità restituiti dalla funzione sono double compresi tra 0,0 e 1,0. Per un output più leggibile, questa query arrotonda i risultati a 6 punti decimali. Per semplificare i confronti, questa query ordina inoltre i risultati in senso decrescente, a partire dal risultato con il massimo grado di affidabilità.
SELECT feedback AS 'Customer feedback', aws_comprehend_detect_sentiment(feedback, 'en') AS Sentiment, ROUND(aws_comprehend_detect_sentiment_confidence(feedback, 'en'), 6) AS Confidence FROM support ORDER BY Confidence DESC;+----------------------------------------------------------+-----------+------------+ | Customer feedback | Sentiment | Confidence | +----------------------------------------------------------+-----------+------------+ | Thank you for the excellent customer support! | POSITIVE | 0.999771 | | The latest version of this product stinks! | NEGATIVE | 0.999184 | | Your support team is just awesome! I am blown away. | POSITIVE | 0.997774 | | Your product is too complex, but your support is great. | MIXED | 0.957958 | | Your support tech helped me in fifteen minutes. | POSITIVE | 0.949491 | | My problem was never resolved! | NEGATIVE | 0.920644 | | When will the new version of this product be released? | NEUTRAL | 0.902706 | | I cannot stand that chatbot. | NEGATIVE | 0.895219 | | Your support tech talked down to me. | NEGATIVE | 0.868598 | | It took me way too long to get a real person. | NEGATIVE | 0.481805 | +----------------------------------------------------------+-----------+------------+ 10 rows in set (0.1898 sec)
Esempio Esempio: determinazione del sentiment medio per testo al di sopra di un livello di affidabilità specifico
Una query Amazon Comprehend tipica cerca le righe in cui il sentiment ha un determinato valore, con un livello di confidenza maggiore di un certo numero. Ad esempio, la query seguente mostra come è possibile determinare il sentiment medio dei documenti nel database. La query considera solo i documenti in cui la confidenza della valutazione è almeno dell'80%.
SELECT AVG(CASE aws_comprehend_detect_sentiment(productTable.document, 'en') WHEN 'POSITIVE' THEN 1.0 WHEN 'NEGATIVE' THEN -1.0 ELSE 0.0 END) AS avg_sentiment, COUNT(*) AS total FROM productTable WHERE productTable.productCode = 1302 AND aws_comprehend_detect_sentiment_confidence(productTable.document, 'en') >= 0.80;
Utilizzo dell' SageMaker intelligenza artificiale con il cluster Aurora MySQL DB
Per utilizzare la funzionalità di SageMaker intelligenza artificiale del cluster Aurora MySQL DB, è necessario creare funzioni archiviate che incorporino le chiamate all'endpoint AI e alle sue funzionalità di inferenza. SageMaker Per eseguire questa operazione, si utilizza CREATE FUNCTION di MySQL esattamente come in altre attività di elaborazione sul cluster database Aurora MySQL.
Per utilizzare i modelli implementati nell' SageMaker intelligenza artificiale per l'inferenza, crei funzioni definite dall'utente utilizzando istruzioni DDL (Data Definition Language) MySQL per le funzioni archiviate. Ogni funzione memorizzata rappresenta l'endpoint AI che ospita il modello. SageMaker Quando si definisce una funzione di questo tipo, si specificano i parametri di input per il modello, l'endpoint SageMaker AI specifico da richiamare e il tipo restituito. La funzione restituisce l'inferenza calcolata dall'endpoint SageMaker AI dopo aver applicato il modello ai parametri di input.
Tutte le funzioni archiviate Aurora Machine Learning restituiscono tipi numerici o VARCHAR. È possibile utilizzare qualsiasi tipo numerico tranne BIT. Altri tipi, ad esempio JSON, BLOB, TEXT e DATE non sono consentiti.
L'esempio seguente mostra la CREATE FUNCTION sintassi per lavorare con l'IA. SageMaker
CREATE FUNCTION function_name (
arg1 type1,
arg2 type2, ...)
[DEFINER = user]
RETURNS mysql_type
[SQL SECURITY { DEFINER | INVOKER } ]
ALIAS AWS_SAGEMAKER_INVOKE_ENDPOINT
ENDPOINT NAME 'endpoint_name'
[MAX_BATCH_SIZE max_batch_size];
Questa è un'estensione della normale istruzione DDL CREATE FUNCTION. Nell'CREATE FUNCTIONistruzione che definisce la funzione SageMaker AI, non si specifica il corpo della funzione. Specifica invece la parola chiave ALIAS al posto del corpo della funzione. Attualmente, Aurora Machine Learning supporta solo aws_sagemaker_invoke_endpoint per questa sintassi estesa. È necessario specificare il parametro endpoint_name. Un endpoint SageMaker AI può avere caratteristiche diverse per ogni modello.
Nota
Per ulteriori informazioni su CREATE FUNCTION, consultare la sezione relativa alle istruzioni CREATE PROCEDURE e CREATE FUNCTION
Il parametro max_batch_size è facoltativo. Per impostazione predefinita, la dimensione batch massima è 10.000. Puoi utilizzare questo parametro nella tua funzione per limitare il numero massimo di input elaborati in una richiesta in batch all'IA. SageMaker Il max_batch_size parametro può aiutare a evitare un errore causato da input troppo grandi o a far sì che l' SageMaker IA restituisca una risposta più rapidamente. Questo parametro influisce sulla dimensione di un buffer interno utilizzato per l'elaborazione delle richieste SageMaker AI. Se specifichi un valore troppo grande per max_batch_size, è possibile che si verifichi un notevole sovraccarico di memoria nell'istanza database.
Ti consigliamo di lasciare l'impostazione MANIFEST sul valore predefinito OFF. Sebbene sia possibile utilizzare l'MANIFEST ONopzione, alcune funzionalità di SageMaker intelligenza artificiale non possono utilizzare direttamente il file CSV esportato con questa opzione. Il formato manifesto non è compatibile con il formato manifesto previsto da SageMaker AI.
Crei una funzione memorizzata separata per ciascuno dei tuoi modelli di SageMaker intelligenza artificiale. Questa mappatura delle funzioni sui modelli è necessaria perché un endpoint è associato a un modello specifico e ciascun modello accetta parametri diversi. L'utilizzo dei tipi SQL per gli input del modello e il tipo di output del modello aiuta a evitare errori di conversione dei tipi nel passaggio dei dati avanti e indietro tra i AWS servizi. È possibile controllare chi può applicare il modello. È inoltre possibile controllare le caratteristiche di runtime specificando un parametro che rappresenta la dimensione massima del batch.
Attualmente tutte le funzioni Aurora Machine Learning hanno la proprietà NOT DETERMINISTIC. Se non specifichi la proprietà esplicitamente, Aurora imposta NOT DETERMINISTIC automaticamente. Questo requisito è dovuto al fatto che il modello SageMaker AI può essere modificato senza alcuna notifica al database. In tal caso, le chiamate a una funzione Aurora Machine Learning potrebbero restituire risultati diversi per lo stesso input all'interno di una singola transazione.
Non puoi usare le caratteristiche CONTAINS SQL, NO SQL, READS SQL DATA o MODIFIES SQL DATA nell'istruzione CREATE
FUNCTION.
Di seguito è riportato un esempio di utilizzo dell'invocazione di un endpoint SageMaker AI per rilevare anomalie. Esiste un endpoint AI. SageMaker random-cut-forest-model Il modello corrispondente è già stato addestrato dall'algoritmo random-cut-forest. Per ogni input, il modello restituisce un punteggio di anomalia. Questo esempio mostra i punti dati il cui punteggio è maggiore di 3 deviazioni standard (circa il 99,9 percentile) dal punteggio medio.
CREATE FUNCTION anomaly_score(value real) returns real
alias aws_sagemaker_invoke_endpoint endpoint name 'random-cut-forest-model-demo';
set @score_cutoff = (select avg(anomaly_score(value)) + 3 * std(anomaly_score(value)) from nyc_taxi);
select *, anomaly_detection(value) score from nyc_taxi
where anomaly_detection(value) > @score_cutoff;
Requisito del set di caratteri per le funzioni SageMaker AI che restituiscono stringhe
Ti consigliamo di specificare un set di caratteri utf8mb4 come tipo restituito per le funzioni SageMaker AI che restituiscono valori di stringa. Se non è pratico, utilizza una lunghezza della stringa sufficiente per il tipo restituito per contenere un valore rappresentato nel set di caratteri utf8mb4. L'esempio seguente mostra come dichiarare il set di caratteri utf8mb4 per la tua funzione.
CREATE FUNCTION my_ml_func(...) RETURNS VARCHAR(5) CHARSET utf8mb4 ALIAS ...Attualmente, ogni funzione SageMaker AI che restituisce una stringa utilizza il set di caratteri utf8mb4 per il valore restituito. Il valore restituito utilizza questo set di caratteri anche se la funzione SageMaker AI dichiara implicitamente o esplicitamente un set di caratteri diverso per il tipo restituito. Se la funzione SageMaker AI dichiara un set di caratteri diverso per il valore restituito, i dati restituiti potrebbero essere troncati automaticamente se li memorizzi in una colonna della tabella che non è sufficientemente lunga. Ad esempio, una query con una clausola DISTINCT crea una tabella temporanea. Pertanto, il risultato della funzione SageMaker AI potrebbe essere troncato a causa del modo in cui le stringhe vengono gestite internamente durante una query.
Esportazione di dati in Amazon S3 SageMaker per la formazione su modelli di intelligenza artificiale (Advanced)
Ti consigliamo di iniziare con l'apprendimento automatico e l' SageMaker intelligenza artificiale di Aurora utilizzando alcuni degli algoritmi forniti e che i data scientist del tuo team ti forniscano gli endpoint SageMaker AI da utilizzare con il tuo codice SQL. Di seguito, puoi trovare informazioni minime sull'utilizzo del tuo bucket Amazon S3 con i tuoi modelli di SageMaker intelligenza artificiale e il tuo cluster Aurora MySQL DB.
La funzione machine learning comprende due fasi principali: training e inferenza. Per addestrare i modelli di SageMaker intelligenza artificiale, esporti i dati in un bucket Amazon S3. Il bucket Amazon S3 viene utilizzato da un'istanza di notebook Jupyter SageMaker AI per addestrare il modello prima della distribuzione. Puoi usare l'istruzione SELECT INTO OUTFILE S3 per eseguire una query sui dati da un cluster di database Aurora MySQL e salvarlo direttamente nei file di testo archiviati in un bucket Simple Storage Service (Amazon S3). Quindi, l'istanza notebook utilizza i dati dal bucket Simple Storage Service (Amazon S3) per il training.
Aurora Machine Learning estende la sintassi SELECT INTO OUTFILE esistente in Aurora MySQL per esportare i dati in formato CSV. Il file CSV generato può essere utilizzato direttamente dai modelli che necessitano di questo formato per il training.
SELECT * INTO OUTFILE S3 's3_uri' [FORMAT {CSV|TEXT} [HEADER]] FROM table_name;L'estensione supporta il formato CSV standard.
-
Il formato
TEXTè uguale al formato di esportazione MySQL esistente. Questo è il formato predefinito. -
CSVIl formato è un formato di nuova introduzione che segue le specifiche di. RFC-4180 -
Se si specifica la parola chiave facoltativa
HEADER, il file di output contiene una riga di intestazione. Le etichette nella riga di intestazione corrispondono ai nomi di colonna dell'istruzioneSELECT. -
Puoi sempre usare le parole chiave
CSVeHEADERcome identificatori.
La sintassi estesa e la grammatica di SELECT INTO ora sono le seguenti:
INTO OUTFILE S3 's3_uri'
[CHARACTER SET charset_name]
[FORMAT {CSV|TEXT} [HEADER]]
[{FIELDS | COLUMNS}
[TERMINATED BY 'string']
[[OPTIONALLY] ENCLOSED BY 'char']
[ESCAPED BY 'char']
]
[LINES
[STARTING BY 'string']
[TERMINATED BY 'string']
]
Considerazioni sulle prestazioni per l'utilizzo del machine learning di Aurora con Aurora MySQL
I servizi Amazon Bedrock, Amazon Comprehend SageMaker e AI svolgono la maggior parte del lavoro quando vengono richiamati da una funzione di machine learning di Aurora. Ciò significa che è possibile dimensionare tali risorse in base alle esigenze, in modo indipendente. Per il cluster database Aurora MySQL, è possibile rendere le chiamate di funzione il più efficienti possibile. Di seguito sono riportate alcune considerazioni sulle prestazioni da tenere presenti quando si utilizza machine learning di Aurora.
Modello e prompt
Quando utilizzi Amazon Bedrock, le prestazioni dipendono in larga misura dal modello e dal prompt in uso. Scegli un modello e un prompt ottimali per il tuo caso d’uso.
Cache delle query
La cache delle query di Aurora MySQL non funziona per le funzioni di machine learning di Aurora. Aurora MySQL non archivia i risultati della query nella cache delle query per le istruzioni SQL che richiamano le funzioni di machine learning di Aurora.
Ottimizzazione batch per le chiamate di funzione Aurora Machine Learning
L'aspetto principale delle prestazioni Aurora Machine Learning che è possibile applicare dal cluster Aurora è l'impostazione della modalità batch per le chiamate alle funzioni archiviate Aurora Machine Learning. Le funzioni di machine learning in genere richiedono un sovraccarico considerevole, rendendo impossibile chiamare separatamente un servizio esterno per ogni riga. Il machine learning di Aurora può ridurre al minimo questo sovraccarico combinando le chiamate al servizio di machine learning Aurora esterno per molte righe in un singolo batch. Il machine learning di Aurora riceve le risposte per un batch di righe di input e quindi restituisce le risposte alla query in esecuzione una riga alla volta. Questa ottimizzazione migliora la velocità effettiva e la latenza delle query Aurora senza modificare i risultati.
Quando crei una funzione memorizzata Aurora connessa a un endpoint SageMaker AI, definisci il parametro della dimensione del batch. Questo parametro influenza il numero di righe trasferite per ogni chiamata sottostante all' SageMaker IA. Per le query che elaborano un numero elevato di righe, il sovraccarico necessario per effettuare una chiamata SageMaker AI separata per ogni riga può essere notevole. Maggiore è il set di dati elaborato dalla stored procedure, maggiore è la dimensione del batch.
Se l'ottimizzazione in modalità batch può essere applicata a una funzione di SageMaker intelligenza artificiale, puoi capirlo controllando il piano di query prodotto dall'EXPLAIN PLANistruzione. In questo caso, la colonna extra nel piano di esecuzione include Batched machine learning. L'esempio seguente mostra una chiamata a una funzione SageMaker AI che utilizza la modalità batch.
mysql> CREATE FUNCTION anomaly_score(val real) returns real alias aws_sagemaker_invoke_endpoint endpoint name 'my-rcf-model-20191126';
Query OK, 0 rows affected (0.01 sec)
mysql> explain select timestamp, value, anomaly_score(value) from nyc_taxi;
+----+-------------+----------+------------+------+---------------+------+---------+------+------+----------+--------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+----------+------------+------+---------------+------+---------+------+------+----------+--------------------------+
| 1 | SIMPLE | nyc_taxi | NULL | ALL | NULL | NULL | NULL | NULL | 48 | 100.00 | Batched machine learning |
+----+-------------+----------+------------+------+---------------+------+---------+------+------+----------+--------------------------+
1 row in set, 1 warning (0.01 sec)
Quando si chiama una delle funzioni Amazon Comprehend integrate, è possibile controllare la dimensione del batch specificando il parametro facoltativo max_batch_size che limita il numero massimo di valori input_text elaborati in ogni batch. L'invio di più elementi contemporaneamente riduce il numero di passaggi tra Aurora e Amazon Comprehend. Limitare la dimensione del batch è utile in situazioni come le query con una clausola LIMIT. Utilizzando un valore basso per max_batch_size, puoi evitare di invocare Amazon Comprehend più volte di quanti sono i testi di input.
L'ottimizzazione batch per la valutazione delle funzioni Aurora Machine Learning si applica nei seguenti casi:
-
Chiamate di funzione nell’elenco di selezione o clausola
WHEREdelle istruzioniSELECT. -
Chiamate di funzione nell’elenco
VALUESdi istruzioniINSERTeREPLACE. -
SageMaker L'intelligenza artificiale funziona nei
SETvalori nelleUPDATEistruzioni:INSERT INTO MY_TABLE (col1, col2, col3) VALUES (ML_FUNC(1), ML_FUNC(2), ML_FUNC(3)), (ML_FUNC(4), ML_FUNC(5), ML_FUNC(6)); UPDATE MY_TABLE SET col1 = ML_FUNC(col2), SET col3 = ML_FUNC(col4) WHERE ...;
Monitoraggio del machine learning di Aurora
Per monitorare le operazioni batch di machine learning di Aurora, puoi eseguire query su diverse variabili globali, come illustrato nell’esempio seguente.
show status like 'Aurora_ml%';
Lo stato di queste variabili può essere ripristinato utilizzando un'istruzione FLUSH STATUS. Pertanto, tutte le cifre rappresentano i totali, le medie e così via, dall'ultima volta che la variabile è stata ripristinata.
Aurora_ml_logical_request_cnt-
Il numero di richieste logiche valutate dall'istanza database per essere inviate ai servizi di machine learning di Aurora dall'ultimo ripristino dello stato. A seconda del fatto che sia stato utilizzato il batching, questo valore può essere superiore a
Aurora_ml_actual_request_cnt. Aurora_ml_logical_response_cnt-
Il conteggio delle risposte aggregate che Aurora MySQL riceve dai servizi di machine learning di Aurora per tutte le query eseguite dagli utenti dell'istanza database.
Aurora_ml_actual_request_cnt-
Il conteggio delle richieste di aggregazione effettuate da Aurora MySQL ai servizi di machine learning di Aurora per tutte le query eseguite dagli utenti dell'istanza database.
Aurora_ml_actual_response_cnt-
Il conteggio delle risposte aggregate che Aurora MySQL riceve dai servizi di machine learning di Aurora per tutte le query eseguite dagli utenti dell'istanza database.
Aurora_ml_cache_hit_cnt-
Il conteggio degli hit della cache interna aggregata che Aurora MySQL riceve dai servizi di machine learning di Aurora per tutte le query eseguite dagli utenti dell'istanza database.
Aurora_ml_retry_request_cnt-
Il numero di richieste ripetute inviate dall'istanza database ai servizi di machine learning di Aurora dall'ultimo ripristino dello stato.
Aurora_ml_single_request_cnt-
Il conteggio aggregato delle funzioni di machine learning di Aurora valutate in modalità non batch per tutte le query eseguite dagli utenti dell'istanza database.
Per informazioni sul monitoraggio delle prestazioni delle operazioni di SageMaker intelligenza artificiale richiamate dalle funzioni di machine learning di Aurora, consulta Monitor Amazon SageMaker AI.
