Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Fonctionnement de la surveillance
Consultez les graphiques suivants sur l'architecture de surveillance dans AWS Managed Services (AMS).
Le schéma suivant fournit une vue d'ensemble du flux de travail de surveillance des zones d'atterrissage multi-comptes AMS et des zones d'atterrissage monocomptes AMS.
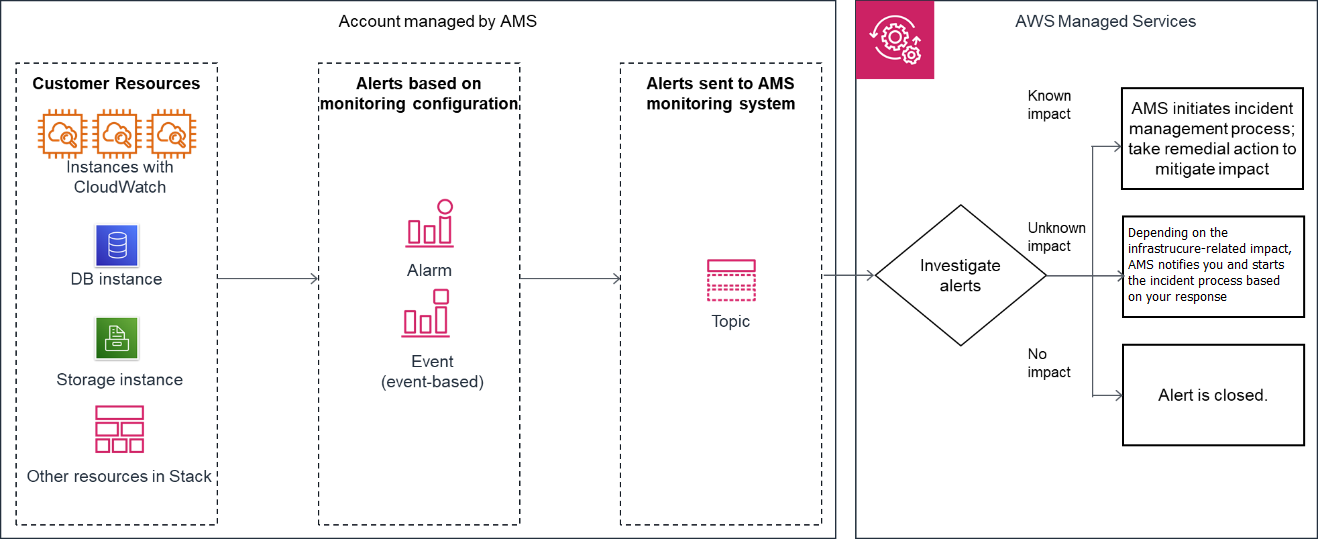
Génération : Au moment de l'intégration du compte, AMS configure la surveillance de base (combinaison d'alarmes CloudWatch (CW) et de règles relatives aux événements CW) pour toutes vos ressources créées dans un compte géré. La configuration de surveillance de base génère une alerte lorsqu'une alarme CW est déclenchée ou qu'un événement CW est généré.
Agrégation :
Zone d'accueil multi-comptes : les alertes sont générées par vos ressources au sein des comptes de l'application et de l'unité organisationnelle principale et envoyées au système de surveillance AMS en les dirigeant via le compte Security.
Zone d'accueil à compte unique : toutes les alertes générées par vos ressources sont envoyées au système de surveillance AMS en les dirigeant vers une rubrique SNS du compte.
Vous pouvez également configurer la manière dont AMS regroupe les EC2 alertes. AMS regroupe toutes les alertes relatives à la même EC2 instance en un seul incident ou crée un incident par alerte, selon vos préférences. Vous pouvez modifier cette configuration à tout moment en travaillant avec votre responsable de prestation de services cloud ou votre architecte cloud. Cela fonctionne de la même manière, que vous utilisiez une zone d'atterrissage multi-comptes ou une zone d'atterrissage à compte unique.
Traitement : AMS analyse les alertes et les traite en fonction de leur impact potentiel. Les alertes sont traitées comme décrit ci-dessous.
Alertes ayant un impact connu sur le client : elles mènent à la création d'un nouveau rapport d'incident et AMS suit le processus de gestion des incidents ; pour plus d'informations sur la gestion des incidents, voirRéponse aux incidents AMS.
Exemple d'alerte : une EC2 instance Amazon échoue à une vérification de l'état du système, AMS tente de récupérer l'instance en l'arrêtant puis en la redémarrant.
Alertes dont l'impact sur le client est incertain : pour ces types d'alertes, AMS envoie un rapport d'incident, vous demandant dans de nombreux cas de vérifier l'impact avant qu'AMS ne prenne des mesures. Toutefois, si les contrôles liés à l'infrastructure sont réussis, AMS ne vous envoie pas de rapport d'incident.
Par exemple : une alerte signalant une utilisation du processeur supérieure à 85 % pendant plus de 10 minutes sur une EC2 instance Amazon ne peut pas être immédiatement considérée comme un incident, car ce comportement peut être attendu en fonction de l'utilisation. Dans cet exemple, AMS Automation effectue des contrôles liés à l'infrastructure sur la ressource. Si ces contrôles sont réussis, AMS n'envoie pas de notification d'alerte, même si l'utilisation du processeur dépasse les 99 %. Si Automation détecte que les contrôles liés à l'infrastructure échouent sur la ressource, AMS envoie une notification d'alerte et vérifie si des mesures d'atténuation sont nécessaires. Les notifications d'alerte sont abordées en détail dans cette section. AMS propose des options d'atténuation dans la notification. Lorsque vous répondez à la notification confirmant que l'alerte est un incident, AMS crée un nouveau rapport d'incident et le processus de gestion des incidents AMS démarre. Les notifications de service qui reçoivent une réponse indiquant « aucune incidence sur le client », ou aucune réponse pendant trois jours, sont marquées comme résolues et l'alerte correspondante est marquée comme résolue.
Alertes sans impact sur le client : si, après évaluation, AMS détermine que l'alerte n'a pas d'impact sur le client, l'alerte est fermée.
Par exemple, AWS Health indique qu'une EC2 instance doit être remplacée mais que cette instance a depuis été résiliée.
EC2 notifications groupées par instances
Vous pouvez configurer la surveillance AMS pour regrouper les alertes provenant d'une même EC2 instance en un seul incident. Votre responsable de prestation de services cloud ou votre architecte cloud peuvent le configurer pour vous. Vous pouvez configurer quatre paramètres pour chaque compte géré par AMS.
Champ d'application : choisissez soit à l'échelle du compte, soit basé sur des balises.
Pour spécifier une configuration qui s'applique à chaque EC2 instance de ce compte, choisissez scope = account-wide.
Pour spécifier une configuration qui s'applique uniquement aux EC2 instances de ce compte dotées d'une balise spécifique, choisissez scope = tag-based.
Règle de regroupement : Choisissez classique ou instance.
Pour configurer le regroupement au niveau de l'instance pour chaque ressource de votre compte, choisissez scope = à l'échelle du compte et règle de regroupement = instance.
Pour configurer des ressources spécifiques de votre compte afin d'utiliser le regroupement au niveau des instances, balisez ces instances, puis choisissez scope = basé sur des balises et règle de regroupement = niveau d'instance.
Pour ne pas utiliser le regroupement d'instances pour les alertes de votre compte, choisissez la règle de regroupement = classique.
Option d'engagement : choisissez aucun, rapport uniquement ou par défaut.
Pour qu'AMS ne crée pas d'incidents ou n'exécute pas d'automatisations pour les alarmes provenant de ces ressources lorsque la configuration est active, choisissez aucun.
Pour qu'AMS ne crée pas d'incidents ou n'exécute pas d'automatisations pour les alarmes provenant de ces ressources lorsque la configuration est active, et qu'il n'exécute pas de documents de guérison automatique de Systems Manager, mais pour inclure des enregistrements de ces événements dans vos rapports, choisissez report only. Cela peut être utile si vous souhaitez réduire le volume de demandes d'assistance avec lesquelles vous interagissez et si certains incidents liés à certaines ressources ne nécessitent pas une attention immédiate, par exemple ceux liés à un compte hors production.
Pour qu'AMS puisse traiter vos alertes, exécuter des automatisations et créer des cas d'incident en cas de besoin, choisissez le paramètre par défaut.
Résoudre après : choisissez 24 heures, 48 heures ou 72 heures. Enfin, configurez le moment où les cas d'incidents sont automatiquement fermés. Si le délai écoulé depuis la dernière correspondance de cas atteint la valeur Resolve after configurée, l'incident est clos.
Notification d'alerte
Dans le cadre du traitement des alertes, sur la base de l'analyse d'impact, AWS Managed Services (AMS) crée un incident et lance le processus de gestion des incidents pour y remédier, lorsque l'impact peut être déterminé. Si l'impact ne peut être déterminé, AMS envoie une notification d'alerte à l'adresse e-mail associée à votre compte par le biais d'une notification de service. Dans certains scénarios, cette notification d'alerte n'est pas envoyée. Par exemple, si les vérifications liées à l'infrastructure aboutissent à une alerte d'utilisation élevée du processeur, aucune notification d'alerte ne vous est envoyée. Pour plus d'informations, consultez le schéma de l'architecture de surveillance AMS pour le processus de gestion des alertes dansFonctionnement de la surveillance.
Notification d'alerte basée sur des balises
Utilisez des balises pour envoyer des notifications d'alerte concernant vos ressources à différentes adresses e-mail. Il est recommandé d'utiliser des notifications d'alerte basées sur des balises, car les notifications envoyées à une seule adresse e-mail peuvent être source de confusion lorsque plusieurs équipes de développeurs utilisent le même compte. Les notifications d'alerte basées sur des balises ne sont pas affectées par les EC2 notifications groupées par instances paramètres que vous choisissez.
Grâce aux notifications d'alerte basées sur des balises, vous pouvez :
Envoyer des alertes à une adresse e-mail spécifique : Marquez les ressources dont les alertes doivent être envoyées à une adresse e-mail spécifique avec le
key = OwnerTeamEmail,value =.EMAIL_ADDRESSEnvoyer des alertes à plusieurs adresses e-mail : pour utiliser plusieurs adresses e-mail, spécifiez une liste de valeurs séparées par des virgules. Par exemple,
key =,OwnerTeamEmailvalue =. Le nombre total de caractères pour le champ de valeur ne peut pas dépasser 260.EMAIL_ADDRESS_1,EMAIL_ADDRESS_2,EMAIL_ADDRESS_3, ...Utiliser une clé de balise personnalisée : pour utiliser une clé de balise personnalisée, fournissez le nom de la clé de balise personnalisée à votre CSDM dans un e-mail qui donne explicitement votre accord pour activer les notifications automatiques pour la communication basée sur des balises. Il est recommandé d'utiliser la même stratégie de balisage pour les balises de contact dans toutes vos instances et ressources.
Note
Il n'est OwnerTeamEmail pas nécessaire que la valeur clé soit dans Camel Case. Toutefois, les balises font la distinction majuscules/majuscules et il est recommandé d'utiliser le format recommandé.
L'adresse e-mail doit être spécifiée dans son intégralité, avec le signe « at » (@) pour séparer la partie locale du domaine. Exemples d'adresses e-mail non valides : Team.AppATabc.xyz oujohn.doe. Pour obtenir des conseils généraux sur votre stratégie de balisage, consultez la section Ressources relatives au balisage AWS. N'ajoutez pas d'informations personnelles identifiables (PII) dans vos tags. Utilisez des listes de distribution ou des alias dans la mesure du possible.
Les notifications d'alerte basées sur des balises sont prises en charge pour les ressources des services Amazon suivants : Elastic Block Store (EBS) EC2, Elastic Load Balancing (ELB), Application Load Balancer (ALB), Network Load Balancer, Relational Database Service (RDS), Elastic File System (EFS) et VPN. OpenSearch FSx Site-to-Site
