Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Planification des données dans le lac de données d'analyse Connect Customer
Cette rubrique détaille le contenu des tables de planification des lacs de données Connect Customer. Les tables répertorient la colonne, le type et la description du contenu.
Il existe deux manières d’accéder au lac de données d’analytique et de configurer les données à partager :
Si vous ne parvenez pas à accéder aux tables de planification à l’aide de l’option 1, essayez d’utiliser l’option 2.
Table des matières
Profil de planification du personnel
Nom de table : staff_scheduling_profile
Clé primaire composite : {instance_id, agent_arn,
staff_scheduling_profile_version}
| Colonne | Type | Description |
|---|---|---|
| instance_id | chaîne | ID de l'instance Connect Customer. |
| agent_arn | chaîne | ARN de l’agent. |
| staff_scheduling_profile_version | bigint | Version du profil de planification du personnel. |
| instance_arn | chaîne | L'ARN de l'instance Connect Customer. |
| staffing_group_arn | chaîne | ARN du groupe d’effectifs auquel l’agent est affecté. |
| start_timestamp | Horodatage | StartTimestamp pour l'agent configuré dans le règlement du personnel (les plannings ne sont générés qu'après cet horodatage). |
| end_timestamp | Horodatage | EndTimestamp pour l'agent configuré dans le règlement du personnel (les plannings ne sont pas générés au-delà de cet horodatage). |
| shift_profile_arn | chaîne | L'ARN du profil de quart de travail attribué à l'agent dans le règlement du personnel. Mutuellement exclusif avec Shift Rotation Pattern. |
| shift_rotation_pattern_arn | chaîne | L'ARN du schéma de rotation des équipes attribué à l'agent dans le règlement du personnel. Mutuellement exclusif avec Shift Profile. |
| shift_rotation_start_step_id | bigint | L'ID de l'étape à laquelle l'agent commence selon le schéma de rotation des équipes attribué. |
| timezone | chaîne | Fuseau horaire configuré pour l’agent. |
| is_deleted | Booléen | Ce paramètre est défini sur True si l’agent est supprimé. Sinon, il est défini sur False. |
| last_updated_timestamp | Horodatage | Horodatage auquel le profil de planification du personnel a été/supprimé. created/updated |
| data_lake_last_processed_timestamp | Horodatage | Date et heure indiquant la dernière fois que l’enregistrement a été touché par le lac de données. Cela peut inclure la transformation et le remplissage. Ce champ ne peut pas être utilisé pour déterminer de manière fiable l’actualité des données. |
Activités de quart de travail
Nom de table : shift_activities
Clé primaire composite : {instance_id, shift_activity_arn,
shift_activity_version}
| Colonne | Type | Description |
|---|---|---|
| instance_id | chaîne | ID de l'instance Connect Customer. |
| shift_activity_arn | chaîne | ARN de l’activité de quart de travail. |
| shift_activity_version | bigint | Version de l’activité de quart de travail. |
| instance_arn | chaîne | L'ARN de l'instance Connect Customer. |
| shift_activity_name | chaîne | Nom de l’activité de quart de travail. |
| type | chaîne | Type d’activité de quart de travail. Les valeurs possibles sont : PRODUCTIVE, NON_PRODUCTIVE et LEAVE. |
| sub_type | chaîne | Sous-type de l’activité de quart de travail. Ceci n’est valable que pour les activités de type NON_PRODUCTIVE. Les valeurs possibles sont : BREAK_OR_MEAL et NONE. |
| is_adherence_tracked | Booléen | Ce paramètre est défini sur True si l’activité de quart de travail est configurée pour le suivi du respect du planning. Sinon, il est défini sur False. |
| is_paid | Booléen | Ce paramètre est défini sur True si l’activité de quart de travail est configurée comme payante. Sinon, il est défini sur False. |
| is_deleted | Booléen | Ce paramètre est défini sur True si l’activité de quart de travail est supprimée. Sinon, il est défini sur False. |
| last_updated_timestamp | Horodatage | Horodatage auquel l'activité Shift a été/supprimée. created/updated |
| data_lake_last_processed_timestamp | Horodatage | Date et heure indiquant la dernière fois que l’enregistrement a été touché par le lac de données. Cela peut inclure la transformation et le remplissage. Ce champ ne peut pas être utilisé pour déterminer de manière fiable l’actualité des données. |
Profils de quart de travail
Nom de table : shift_profiles
Clé primaire composite : {instance_id, shift_profile_arn,
shift_profile_version}
| Colonne | Type | Description |
|---|---|---|
| instance_id | chaîne | ID de l'instance Connect Customer. |
| shift_profile_arn | chaîne | ARN du profil de quart de travail. |
| shift_profile_version | bigint | Version du profil de quart de travail. |
| instance_arn | chaîne | L'ARN de l'instance Connect Customer. |
| shift_profile_name | chaîne | Nom du profil de quart de travail. |
| is_deleted | Booléen | Ce paramètre est défini sur True si le profil de quart de travail est supprimé. Sinon, il est défini sur False. |
| last_updated_timestamp | Horodatage | Horodatage auquel le profil Shift a été/supprimé. created/updated |
| data_lake_last_processed_timestamp | Horodatage | Date et heure indiquant la dernière fois que l’enregistrement a été touché par le lac de données. Cela peut inclure la transformation et le remplissage. Ce champ ne peut pas être utilisé pour déterminer de manière fiable l’actualité des données. |
Groupes de dotation en personnel
Nom de table : staffing_groups
Clé primaire composite : {instance_id, staffing_group_arn,
staffing_group_version}
| Colonne | Type | Description |
|---|---|---|
| instance_id | chaîne | ID de l'instance Connect Customer. |
| staffing_group_arn | chaîne | ARN du groupe d’effectifs. |
| staffing_group_version | bigint | Version du groupe d’effectifs. |
| instance_arn | chaîne | L'ARN de l'instance Connect Customer. |
| staffing_group_name | chaîne | Nom du groupe d’effectifs. |
| is_deleted | Booléen | Ce paramètre est défini sur True si le groupe d’effectifs est supprimé. Sinon, il est défini sur False. |
| last_updated_timestamp | Horodatage | Horodatage auquel le groupe de dotation a été/supprimé. created/updated |
| data_lake_last_processed_timestamp | Horodatage | Date et heure indiquant la dernière fois que l’enregistrement a été touché par le lac de données. Cela peut inclure la transformation et le remplissage. Ce champ ne peut pas être utilisé pour déterminer de manière fiable l’actualité des données. |
Groupes d’effectifs - Groupes de prévisions
Nom de table : staffing_group_forecast_groups
Clé primaire composite : {instance_id, staffing_group_arn,
staffing_group_version, forecast_group_arn}
Cette table doit être interrogée en la joignant à la table staffing_groups sur staffing_group_arn et staffing_group_version.
| Colonne | Type | Description |
|---|---|---|
| instance_id | chaîne | ID de l'instance Connect Customer. |
| staffing_group_arn | chaîne | ARN du groupe d’effectifs. |
| staffing_group_version | bigint | Version du groupe d’effectifs. |
| forecast_group_arn | chaîne | ARN du groupe de prévisions associé au groupe d’effectifs. |
| instance_arn | chaîne | L'ARN de l'instance Connect Customer. |
| is_deleted | Booléen | Défini sur False lorsque l' StaffingGroup-ForecastGroupassociation est valide. |
| last_updated_timestamp | Horodatage | Horodatage où se trouvait le groupe de dotation. created/updated |
| data_lake_last_processed_timestamp | Horodatage | Date et heure indiquant la dernière fois que l’enregistrement a été touché par le lac de données. Cela peut inclure la transformation et le remplissage. Ce champ ne peut pas être utilisé pour déterminer de manière fiable l’actualité des données. |
Groupes d’effectifs - Superviseurs
Nom de table : staffing_group_supervisors
Clé primaire composite : {instance_id, staffing_group_arn,
staffing_group_version, supervisor_arn}
Cette table doit être interrogée en la joignant à la table staffing_groups sur staffing_group_arn et staffing_group_version.
| Colonne | Type | Description |
|---|---|---|
| instance_id | chaîne | ID de l'instance Connect Customer. |
| staffing_group_arn | chaîne | ARN du groupe d’effectifs. |
| staffing_group_version | bigint | Version du groupe d’effectifs. |
| supervisor_arn | chaîne | ARN de l’agent du superviseur associé au groupe d’effectifs. |
| instance_arn | chaîne | L'ARN de l'instance Connect Customer. |
| is_deleted | Booléen | Défini sur False lorsque l' StaffingGroup-ForecastGroupassociation est valide. |
| last_updated_timestamp | Horodatage | Horodatage où se trouvait le groupe de dotation. created/updated |
| data_lake_last_processed_timestamp | Horodatage | Date et heure indiquant la dernière fois que l’enregistrement a été touché par le lac de données. Cela peut inclure la transformation et le remplissage. Ce champ ne peut pas être utilisé pour déterminer de manière fiable l’actualité des données. |
Quarts de travail du personnel
Nom de table : staff_shifts
Clé primaire composite : {instance_id, shift_id, shift_version}
| Colonne | Type | Description |
|---|---|---|
| instance_id | chaîne | ID de l'instance Connect Customer. |
| shift_id | chaîne | ID du quart de travail. |
| shift_version | bigint | Version du quart de travail. |
| instance_arn | chaîne | L'ARN de l'instance Connect Customer. |
| agent_arn | chaîne | ARN de l’agent. |
| shift_start_timestamp | Horodatage | Horodatage du début du quart de travail. |
| shift_end_timestamp | Horodatage | Horodatage de la fin du quart de travail. |
| created_timestamp | Horodatage | Date et heure de la création du quart de travail. |
| is_deleted | Booléen | Ce paramètre est défini sur True si le quart de travail est supprimé. Sinon, il est défini sur False. |
| last_updated_timestamp | Horodatage | L'horodatage auquel le Shift a été/supprimé. created/updated |
| data_lake_last_processed_timestamp | Horodatage | Date et heure indiquant la dernière fois que l’enregistrement a été touché par le lac de données. Cela peut inclure la transformation et le remplissage. Ce champ ne peut pas être utilisé pour déterminer de manière fiable l’actualité des données. |
Activités de quart de travail
Nom de table : staff_shift_activities
Clé primaire composite : {instance_id, shift_id, shift_version,
activity_id}
Cette table doit être interrogée en la joignant à la table staff_shifts sur shift_id et shift_version.
| Colonne | Type | Description |
|---|---|---|
| instance_id | chaîne | ID de l'instance Connect Customer. |
| shift_id | chaîne | ID du quart de travail. |
| shift_version | bigint | Version du quart de travail. |
| activity_id | chaîne | ID de l’activité. |
| instance_arn | chaîne | L'ARN de l'instance Connect Customer. |
| activity_start_timestamp | Horodatage | Horodatage du début de l’activité. |
| activity_end_timestamp | Horodatage | Horodatage de la fin de l’activité. |
| shift_activity_arn | chaîne | ARN de l’activité de quart de travail. Si la valeur shift_activity_arn est nulle, cela indique une activité « Travail ». |
| activity_status | chaîne | Statut de l’activité. Ce paramètre est défini sur INACTIF si l’activité correspond à un congé. |
| is_overtime | Booléen | Ce paramètre est défini sur True si l’activité fait partie des heures supplémentaires. Sinon, il est défini sur False. |
| is_deleted | Booléen | Ce paramètre est défini sur False lorsque les activités de quart de travail sont valides. |
| last_updated_timestamp | Horodatage | L'horodatage du Shift. created/updated |
| data_lake_last_processed_timestamp | Horodatage | Date et heure indiquant la dernière fois que l’enregistrement a été touché par le lac de données. Cela peut inclure la transformation et le remplissage. Ce champ ne peut pas être utilisé pour déterminer de manière fiable l’actualité des données. |
Modifications du solde de congés du personnel
Nom de table : staff_timeoff_balance_changes
Clé primaire composite : {instance_id, agent_arn, shift_activity_arn,
timeoff_balance_version}
| Colonne | Type | Description |
|---|---|---|
| instance_arn | chaîne | L'ARN de l'instance Connect Customer. |
| instance_id | chaîne | ID de l'instance Connect Customer. |
| account_id | chaîne | L'identifiant du AWS compte. |
| agent_arn | chaîne | ARN de l’agent. |
| shift_activity_arn | chaîne | ARN de l’activité de quart de travail à laquelle ce solde est alloué. |
| timeoff_balance_version | bigint | Version du solde de congé, nombre incrémenté pour indiquer l’ordre des modifications. |
| balance_update_source | chaîne | Source de la mise à jour du solde. Les valeurs possibles sont TIME_OFF_BALANCE_UPLOAD, CONNECT_TIME_OFF_REQUEST, SCHEDULE_PUBLISH, CSV_TIME_OFF_BALANCE_DELETION, TIME_OFF_BALANCE_BACKFILL, SYSTEM_UPDATE |
| timeoff_id | chaîne | Identifiant du congé qui a entraîné cette modification du solde, le cas échéant. |
| last_updated_by | chaîne | ARN de l’agent à l’origine de ce changement de solde, le cas échéant. |
| balance_change_in_hours | double | Nombre d’heures du solde de congé mises à jour via ce changement d’heures. Si cette valeur est positive, cette modification crédite le solde de congé. Si cette valeur est négative, cette modification débite le solde de congé. Cette valeur n’est pas définie pour les événements de chargement et de suppression de solde. |
| remaining_balance_in_hours | double | Nombre d’heures de solde de congé restantes après cet événement de modification. Cette valeur n’est pas définie pour tout événement de suppression de solde. |
| last_created_timestamp | Horodatage | Date et heure auxquelles l’enregistrement de modification du solde de congé a été créé. |
| data_lake_last_processed_timestamp | Horodatage | Date et heure indiquant la dernière fois que l’enregistrement a été touché par le lac de données. Cela peut inclure la transformation et le remplissage. Ce champ ne peut pas être utilisé pour déterminer de manière fiable l’actualité des données. |
Congés du personnel
Nom de table : staff_timeoffs
Clé primaire composite : {instance_id, timeoff_id, agent_arn,
timeoff_version}
| Colonne | Type | Description |
|---|---|---|
| instance_id | chaîne | ID de l'instance Connect Customer. |
| timeoff_id | chaîne | Identifiant du congé. |
| agent_arn | chaîne | ARN de l’agent. |
| timeoff_version | bigint | Version du congé. |
| instance_arn | chaîne | L'ARN de l'instance Connect Customer. |
| timeoff_type | chaîne | Type de congé. Les valeurs possibles sont : TIME_OFF et VOLUNTARY_TIME_OFF. |
| timeoff_start_timestamp | Horodatage | Date et heure de début du congé. |
| timeoff_end_timestamp | Horodatage | Date et heure de fin du congé. |
| timeoff_status | chaîne | Statut du congé. Les valeurs possibles sont : PENDING_CREATE, PENDING_UPDATE, PENDING_CANCEL, PENDING_ACCEPT, PENDING_APPROVE, PENDING_DECLINE, APPROVED, ACCEPTED, REJECTED, CANCELLED, WAITING_ACCEPT et WAITING_APPROVE. Le statut WAITING indique que le congé est en attente d’une action de l’utilisateur. Les statuts PENDING indiquent que le délai d’attente est dû au traitement d’une action de l’utilisateur par le système. |
| shift_activity_arn | chaîne | ARN de l’activité de quart de travail utilisée pour le congé. |
| effective_timeoff_hours | double | Nombre total d’heures de congé effectives. Les heures de congé effectives sont calculées en fonction de la logique de déduction des congés. Ceci n’est défini que pour le type TIME_OFF. |
| last_updated_timestamp | Horodatage | Horodatage auquel le congé a été/supprimé. created/updated |
| data_lake_last_processed_timestamp | Horodatage | Date et heure indiquant la dernière fois que l’enregistrement a été touché par le lac de données. Cela peut inclure la transformation et le remplissage. Ce champ ne peut pas être utilisé pour déterminer de manière fiable l’actualité des données. |
Intervalles de congés du personnel
Nom de table : staff_timeoff_intervals
Clé primaire composite : {instance_id, timeoff_id, timeoff_version,
interval_id}
Cette table doit être interrogée en la joignant à la table staff_timeoffs sur timeoff_id et timeoff_version.
| Colonne | Type | Description |
|---|---|---|
| instance_id | chaîne | ID de l'instance Connect Customer. |
| timeoff_id | chaîne | Identifiant du congé. |
| timeoff_version | bigint | Version du congé. |
| interval_id | chaîne | ID de l’intervalle de congé. |
| instance_arn | chaîne | L'ARN de l'instance Connect Customer. |
| timeoff_interval_start_timestamp | Horodatage | Date et heure de début de l’intervalle spécifique de congé. |
| timeoff_interval_end_timestamp | Horodatage | Date et heure de fin de l’intervalle spécifique de congé. |
| interval_effective_timeoff_hours | double | Heures de congé effectives pour cet intervalle de congé spécifique. Les heures de congé effectives sont calculées en fonction de la logique de déduction des congés. |
| last_updated_timestamp | Horodatage | Horodatage auquel le congé a été/supprimé. created/updated |
| data_lake_last_processed_timestamp | Horodatage | Date et heure indiquant la dernière fois que l’enregistrement a été touché par le lac de données. Cela peut inclure la transformation et le remplissage. Ce champ ne peut pas être utilisé pour déterminer de manière fiable l’actualité des données. |
Groupe de demande du personnel
Nom de la table : staff_demand_group
Clé primaire composite : {instance_id, agent_arn, demand_group_arn, staff_demand_group_version}
| Colonne | Type | Description |
|---|---|---|
| instance_id | chaîne | ID de l'instance Connect Customer. |
| agent_arn | chaîne | ARN de l’agent. |
| demande_group_arn | chaîne | L'ARN du groupe de demandes. |
| personnel_demand_group_version | Long | Version permettant à cet agent de demander l'association de groupes |
| priority | chaîne | Priorité du groupe de demande pour cet agent. Peut être faible, moyen ou élevé |
| instance_arn | chaîne | L'ARN de l'instance Connect Customer. |
| is_override | Booléen | Si cette valeur est définie sur « true » s'il s'agit d'une association agent-groupe de demande, cela signifie une dérogation au niveau de l'agent. |
| is_deleted | Booléen | Défini sur true si l'association agent-groupe de demandes est supprimée. |
| last_updated_timestamp | Horodatage | Horodatage de l'agent chargé de demander l'association du groupe. created/updated |
| data_lake_last_processed_timestamp | Horodatage | Date et heure indiquant la dernière fois que l’enregistrement a été touché par le lac de données. Cela peut inclure la transformation et le remplissage. Ce champ ne peut pas être utilisé pour déterminer de manière fiable l’actualité des données. |
Groupes de dotation en personnel : groupe de demande
Nom de la table : staffing_group_demand_group
Clé primaire composite : {instance_id, staffing_group_arn, demand_group_arn,
staffing_group_demand_group_version}
| Colonne | Type | Description |
|---|---|---|
| instance_id | chaîne | ID de l'instance Connect Customer. |
| staffing_group_arn | chaîne | ARN du groupe d’effectifs. |
| demande_group_arn | chaîne | L'ARN du groupe de demandes. |
| staffing_group_demand_group_version | Long | Version pour cette association de groupe de dotation en personnel à groupe de demande |
| priority | chaîne | Priorité du groupe de demande pour ce groupe de dotation. Peut être faible, moyen ou élevé |
| instance_arn | chaîne | L'ARN de l'instance Connect Customer. |
| is_deleted | Booléen | Défini sur true si l'association entre le groupe de dotation et le groupe de demande est supprimée. |
| last_updated_timestamp | Horodatage | Horodatage auquel l'association entre le groupe de dotation et le groupe de demande a été/supprimé. created/updated |
| data_lake_last_processed_timestamp | Horodatage | Date et heure indiquant la dernière fois que l’enregistrement a été touché par le lac de données. Cela peut inclure la transformation et le remplissage. Ce champ ne peut pas être utilisé pour déterminer de manière fiable l’actualité des données. |
Répartition des activités du personnel par équipes
Nom de la table : staff_shift_activity_allocations
Clé primaire composite : {instance_id, shift_id, shift_version, activity_id, demand_group_arn}
| Colonne | Type | Description |
|---|---|---|
| instance_id | chaîne | ID de l'instance Connect Customer. |
| shift_id | chaîne | L'identifiant du quart de travail. |
| shift_version | Long | Version du quart de travail. |
| activity_id | chaîne | ID de l'activité. |
| demande_group_arn | chaîne | L'ARN du groupe de demandes. |
| foecast_group_arn | chaîne | ARN du groupe de prévisions. |
| pourcent_allocation | double | Pourcentage d'allocation de l'activité au groupe de demande. |
| is_deleted | Booléen | Défini sur False lorsque le StaffingGroup-ForecastGroupassociation est valide. |
| last_updated_timestamp | Horodatage | Horodatage où se trouvait le groupe de dotation. created/updated |
| data_lake_last_processed_timestamp | Horodatage | Date et heure indiquant la dernière fois que l’enregistrement a été touché par le lac de données. Cela peut inclure la transformation et le remplissage. Ce champ ne peut pas être utilisé pour déterminer de manière fiable l’actualité des données. |
Métriques du calendrier
Nom de table : schedule_metrics
Clé primaire composite : {instance_id, metric_id, interval_start_timestamp}
| Colonne | Type | Description |
|---|---|---|
| instance_id | chaîne | ARN de l’instance Amazon Connect. |
| instance_arn | chaîne | Identifiant de l’instance Amazon Connect. |
| identifiant métrique | chaîne | Identifiant unique pour la valeur de la métrique |
| aws_account_id | chaîne | L'ID du compte AWS. |
| type_entité | chaîne | Indique si la métrique concerne un groupe de prévisions ou un groupe de demandes. |
| entity_arn | chaîne | Arn du groupe de prévisions ou du groupe de demandes |
| channel | chaîne | Désigne le canal multimédia tel que Voice, chat. Si la ligne contient des métriques qui ne sont pas au niveau du canal, elle est renseignée comme ALL |
| horodatage de début d'intervalle | timestamp | Horodatage indiquant le début de l'intervalle |
| comptage d'agents requis | float | Indique le nombre d'agents prévu |
| comptage d'agents planifiés | float | Indique le calendrier, le nombre d'agents |
| occupation planifiée | float | Indique le pourcentage d'occupation |
| pourcentage de niveau_de_service planifié | float | Indique le pourcentage du niveau de service du planning |
| niveau de service en secondes | entier | Indique le niveau de service en secondes |
| vitesse_moyen_de_réponse planifiée | float | Indique la vitesse moyenne de réponse |
| is_deleted | boolean | Indique si la métrique est supprimée |
| last_updated_timestamp | timestamp | Horodatage lors de la création de l'enregistrement métrique. |
| data_lake_last_processed_timestamp | timestamp | Date et heure indiquant la dernière fois que le lac de données a traité l’enregistrement. Cela peut inclure la transformation et le remplissage. Ce champ ne peut pas être utilisé pour déterminer de manière fiable l’actualité des données. |
Objectifs du calendrier
Nom de table : schedule_goals
Clé primaire composite : {instance_id, goal_id}
| Colonne | Type | Description |
|---|---|---|
| instance_id | chaîne | ARN de l’instance Amazon Connect. |
| instance_arn | chaîne | Identifiant de l’instance Amazon Connect. |
| identifiant de l'objectif | chaîne | Identifiant unique pour la valeur de l'objectif |
| aws_account_id | chaîne | L'ID du compte AWS. |
| type_entité | chaîne | Indique si l'objectif concerne un groupe de prévisions ou un groupe de demandes. |
| entity_arn | chaîne | Arn du groupe de prévisions ou du groupe de demandes |
| channel | chaîne | Désigne le canal multimédia tel que Voice, chat. |
| date_de_début horodatage | timestamp | Horodatage indiquant le début de l'objectif |
| horodatage de la date de fin | timestamp | Horodatage indiquant la fin de l'objectif |
| Pourcentage de niveau_de_service | float | Indique le pourcentage de niveau de service cible |
| goal_service_level_seconds | entier | Indique le niveau de service en secondes |
| objectif_moyen_vitesse_de_réponse | float | Indique la vitesse moyenne de réponse |
| is_deleted | boolean | Indique si l'objectif est supprimé |
| last_updated_timestamp | timestamp | Horodatage lors de la création de l'enregistrement des objectifs. |
| data_lake_last_processed_timestamp | timestamp | Date et heure indiquant la dernière fois que le lac de données a traité l’enregistrement. Cela peut inclure la transformation et le remplissage. Ce champ ne peut pas être utilisé pour déterminer de manière fiable l’actualité des données. |
Changez les modèles de rotation
Nom de table : shift_rotation_patterns
Clé primaire composite : {instance_id, shift_rotation_pattern_arn,
shift_rotation_pattern_version}
| Colonne | Type | Description |
|---|---|---|
| instance_id | chaîne | ID de l'instance Connect Customer. |
| shift_rotation_pattern_arn | chaîne | L'ARN du schéma de rotation Shift. |
| Shift_Rotation_Pattern_Version | bigint | La version du schéma de rotation Shift. |
| instance_arn | chaîne | L'ARN de l'instance Connect Customer. |
| shift_rotation_pattern_name | chaîne | Nom du schéma de rotation Shift. |
| start_date | chaîne | Date de début du schéma de rotation Shift au yyyy-mm-dd format. |
| is_deleted | Booléen | Défini sur True si le schéma de rotation Shift est supprimé. Sinon, il est défini sur False. |
| last_updated_by | chaîne | L'ARN de l'utilisateur qui a created/updated /supprimé le schéma de rotation Shift. |
| last_updated_timestamp | Horodatage | Horodatage auquel le schéma de rotation Shift a été /supprimé. created/updated |
| data_lake_last_processed_timestamp | Horodatage | Date et heure indiquant la dernière fois que l’enregistrement a été touché par le lac de données. Cela peut inclure la transformation et le remplissage. Ce champ ne peut pas être utilisé pour déterminer de manière fiable l’actualité des données. |
Étapes de rotation des décalages
Nom de table : shift_rotation_steps
Clé primaire composite : {instance_id, shift_rotation_pattern_arn,
shift_rotation_pattern_version, step_id}
Cette table doit être interrogée en la joignant à la table shift_rotation_patterns sur shift_rotation_pattern_arn et shift_rotation_pattern_version.
| Colonne | Type | Description |
|---|---|---|
| instance_id | chaîne | ID de l'instance Connect Customer. |
| shift_rotation_pattern_arn | chaîne | L'ARN du schéma de rotation Shift. |
| Shift_Rotation_Pattern_Version | bigint | La version du schéma de rotation Shift. |
| step_id | bigint | L'ID de l'étape dans le schéma de rotation Shift. Les étapes sont numérotées séquentiellement (1, 2, 3,... jusqu'à 52). |
| instance_arn | chaîne | L'ARN de l'instance Connect Customer. |
| shift_profile_arn | chaîne | L'ARN du profil de changement associé à l'étape de rotation. |
| duration | bigint | Durée de l'étape de rotation en semaines. |
| is_deleted | Booléen | Défini sur False lorsque l'étape Shift Rotation est valide. |
| last_updated_by | chaîne | L'ARN de l'utilisateur qui utilise created/updated le schéma de rotation Shift. |
| last_updated_timestamp | Horodatage | Horodatage du schéma de rotation des équipes. created/updated |
| data_lake_last_processed_timestamp | Horodatage | Date et heure indiquant la dernière fois que l’enregistrement a été touché par le lac de données. Cela peut inclure la transformation et le remplissage. Ce champ ne peut pas être utilisé pour déterminer de manière fiable l’actualité des données. |
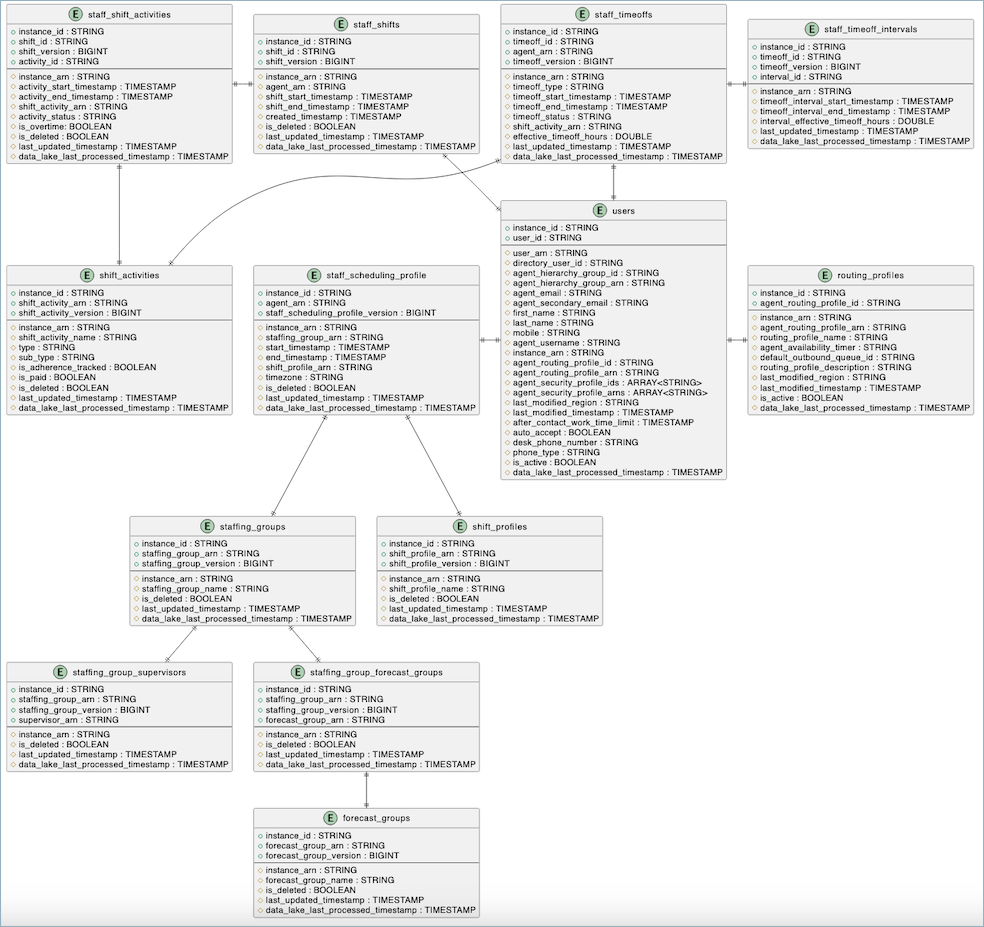
Schéma de données
Vous trouverez ci-dessous un diagramme de relations entre les entités qui montre la structure et les relations entre les tables de planification dans le lac de données Connect Customer.
Chaque table affiche ses clés primaires et attributs ainsi que ses types de données. Ce diagramme illustre la façon dont ces tables sont liées les unes aux autres par le biais de relations de clés étrangères, fournissant ainsi une vue complète du modèle de données de planification.
Exemples de requêtes
1. Requête pour générer toutes les activités planifiées des agents travaillant sur un groupe de prévisions spécifique
SELECT * FROM agent_scheduled_shift_activities_view
where forecast_group_name = 'AnyDepartmentForecastGroup'
Procédez comme suit pour créer la vue agent_scheduled_shift_activities_view mentionnée ci-dessus.
Étape 1 : créer une vue pour obtenir le nom des superviseurs
CREATE OR REPLACE VIEW "latest_supervisor_names_view" AS SELECT staffing_group_arn , array_agg(supervisor_name ORDER BY supervisor_name ASC) supervisor_names FROM ( SELECT s.staffing_group_arn , CONCAT(u.first_name, ' ', u.last_name) supervisor_name FROM (( SELECT staffing_group_arn , supervisor_arn FROM ( SELECT * , RANK() OVER (PARTITION BY staffing_group_arn ORDER BY staffing_group_version DESC) recency FROM staffing_group_supervisors WHERE (instance_id = 'YourAmazonConnectInstanceId') ) t WHERE (recency = 1) ) s INNER JOIN USERS u ON (s.supervisor_arn = u.user_arn)) ) GROUP BY staffing_group_arn
Étape 2 : créer une vue pour associer le groupe d’effectifs et le groupe de prévisions à un agent
CREATE OR REPLACE VIEW "latest_agent_staffing_group_forecast_group_view" AS WITH latest_staff_scheduling_profile AS ( SELECT agent_arn , staffing_group_arn , last_updated_timestamp FROM ( SELECT * , RANK() OVER (PARTITION BY agent_arn ORDER BY staff_scheduling_profile_version DESC) recency FROM staff_scheduling_profile WHERE ((instance_id = 'YourAmazonConnectInstanceId') AND (is_deleted = false)) ) t WHERE (recency = 1) ) , latest_staffing_groups AS ( SELECT staffing_group_name , staffing_group_arn FROM ( SELECT * , RANK() OVER (PARTITION BY staffing_group_arn ORDER BY staffing_group_version DESC) recency FROM staffing_groups WHERE (instance_id = 'YourAmazonConnectInstanceId') ) t WHERE (recency = 1) ) , latest_forecast_groups AS ( SELECT forecast_group_arn , forecast_group_name FROM ( SELECT * , RANK() OVER (PARTITION BY forecast_group_arn ORDER BY forecast_group_version DESC) recency FROM forecast_groups WHERE (instance_id = 'YourAmazonConnectInstanceId') ) t WHERE (recency = 1) ) , latest_staffing_group_forecast_groups AS ( SELECT staffing_group_arn , forecast_group_arn FROM ( SELECT * , RANK() OVER (PARTITION BY staffing_group_arn ORDER BY staffing_group_version DESC) recency FROM staffing_group_forecast_groups WHERE (instance_id = 'YourAmazonConnectInstanceId') ) t WHERE (recency = 1) ) SELECT ssp.agent_arn , U.agent_username AS username , U.agent_routing_profile_id AS routing_profile_id , CONCAT(u.first_name, ' ', u.last_name) agent_name , fg.forecast_group_arn , fg.forecast_group_name , sg.staffing_group_arn , sg.staffing_group_name FROM latest_staff_scheduling_profile ssp INNER JOIN latest_staffing_groups sg ON ssp.staffing_group_arn = sg.staffing_group_arn INNER JOIN latest_staffing_group_forecast_groups sgfg ON ssp.staffing_group_arn = sgfg.staffing_group_arn INNER JOIN latest_forecast_groups fg ON fg.forecast_group_arn = sgfg.forecast_group_arn INNER JOIN USERS u ON ssp.agent_arn = u.user_arn
Étape 3 : obtenir les dernières activités de quart de travail
CREATE OR REPLACE VIEW "latest_shift_activities_view" AS SELECT shift_activity_arn , shift_activity_name , shift_activity_version , type , sub_type , is_adherence_tracked , is_paid , last_updated_timestamp FROM ( SELECT * , RANK() OVER (PARTITION BY shift_activity_arn ORDER BY shift_activity_version DESC) recency FROM shift_activities WHERE (instance_id = 'YourAmazonConnectInstanceId') ) t WHERE (recency = 1)
Étape 4 : créer une vue pour obtenir les activités de quart de travail planifiées de l’agent
CREATE OR REPLACE VIEW "agent_scheduled_shift_activities_view" AS WITH latest_staff_shifts AS ( SELECT agent_arn , shift_id , shift_version , shift_start_timestamp , shift_end_timestamp , created_timestamp , last_updated_timestamp , data_lake_last_processed_timestamp , recency FROM ( SELECT RANK() OVER (PARTITION BY shift_id ORDER BY shift_version DESC) recency , * FROM staff_shifts sa WHERE (instance_id = 'YourAmazonConnectInstanceId') ) t WHERE ((recency = 1) AND (is_deleted = false)) ) SELECT asgfg.forecast_group_name , array_join(sn.supervisor_names, ',') supervisor_names , s.agent_arn , u.first_name , u.last_name , asgfg.staffing_group_name , ssa.activity_id , (CASE WHEN (ssa.shift_activity_arn IS NULL) THEN COALESCE(sa.shift_activity_name, 'Work') ELSE sa.shift_activity_name END) shift_activity_name , s.shift_start_timestamp , s.shift_end_timestamp , (CASE WHEN (ssa.shift_activity_arn IS NULL) THEN COALESCE(sa.type, 'PRODUCTIVE') ELSE sa.type END) type , (CASE WHEN (ssa.shift_activity_arn IS NULL) THEN COALESCE(sa.is_paid, true) ELSE sa.is_paid END) is_paid , ssa.activity_start_timestamp , ssa.activity_end_timestamp , ssa.last_updated_timestamp , ssa.data_lake_last_processed_timestamp , u.agent_username as username , u.agent_routing_profile_id as routing_profile_id FROM staff_shift_activities ssa INNER JOIN latest_staff_shifts s ON s.shift_id = ssa.shift_id AND s.shift_version = ssa.shift_version INNER JOIN USERS u ON s.agent_arn = u.user_arn INNER JOIN latest_agent_staffing_group_forecast_group_view asgfg ON s.agent_arn = asgfg.agent_arn LEFT JOIN latest_shift_activities_view sa ON sa.shift_activity_arn = ssa.shift_activity_arn INNER JOIN latest_supervisor_names_view sn ON sn.staffing_group_arn = asgfg.staffing_group_arn WHERE (ssa.is_deleted = false) AND (COALESCE(ssa.activity_status, ' ') <> 'INACTIVE') AND (ssa.instance_id = 'YourAmazonConnectInstanceId')
2. Requête pour obtenir toutes les demandes de congés des agents d’un groupe de prévisions spécifique
SELECT * FROM agent_timeoff_report_view where forecast_group_name =
'AnyDepartmentForecastGroup'
Utilisez la requête suivante pour créer la vue agent_timeoff_report_view mentionnée ci-dessus.
CREATE OR REPLACE VIEW "agent_timeoff_report_view" AS WITH latest_staff_timeoffs AS ( SELECT t1.*, CAST((t1.effective_timeoff_hours * 60) AS INT) total_effective_timeoff_minutes FROM ( SELECT RANK() OVER ( PARTITION BY timeoff_id ORDER BY timeoff_version DESC ) recency, agent_arn, timeoff_id, shift_activity_arn, timeoff_status, timeoff_version, effective_timeoff_hours, timeoff_start_timestamp, timeoff_end_timestamp, last_updated_timestamp, data_lake_last_processed_timestamp FROM staff_timeoffs WHERE ( instance_id = 'YourAmazonConnectInstanceId' ) ) t1 WHERE (recency = 1) ) SELECT asgfg.forecast_group_name, to.agent_arn, asgfg.agent_name, asgfg.staffing_group_name, asgfg.username, sa.shift_activity_name, to.timeoff_start_timestamp, to.timeoff_end_timestamp, to.timeoff_status, array_join(sn.supervisor_names, ',') AS supervisor_names, sa.is_paid, to.last_updated_timestamp, to.data_lake_last_processed_timestamp, u.agent_routing_profile_id AS routing_profile_id, to.timeoff_id, to.shift_activity_arn, to.total_effective_timeoff_minutes FROM latest_staff_timeoffs to INNER JOIN latest_agent_staffing_group_forecast_group_view asgfg ON asgfg.agent_arn = to.agent_arn INNER JOIN latest_shift_activities_view sa ON sa.shift_activity_arn = to.shift_activity_arn INNER JOIN latest_supervisor_names_view sn ON sn.staffing_group_arn = asgfg.staffing_group_arn INNER JOIN users u ON u.user_arn = to.agent_arn
