Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Utilisation du machine learning Amazon Aurora avec Aurora MySQL
En utilisant l'apprentissage automatique Amazon Aurora avec votre cluster de bases de données Aurora MySQL, vous pouvez utiliser Amazon Bedrock, Amazon Comprehend ou SageMaker Amazon AI, selon vos besoins. Ils prennent chacun en charge différents cas d’utilisation de machine learning.
Table des matières
Exigences pour l’utilisation du machine learning Aurora avec Aurora MySQL
Fonctions prises en charge et limitations du machine learning Aurora avec Aurora MySQL
Configuration de votre cluster de bases de données Aurora MySQL pour utiliser Amazon Bedrock
Configuration de votre cluster de bases de données Aurora MySQL pour utiliser Amazon Comprehend
Configuration de votre cluster de base de données Aurora MySQL pour utiliser l' SageMaker IA
Autorisation d’accès aux utilisateurs de base de données pour le machine learning Aurora
Utilisation d’Amazon Bedrock avec votre cluster de bases de données Aurora MySQL
Utiliser Amazon Comprehend avec votre cluster de bases de données Aurora MySQL
Utilisation de l' SageMaker IA avec votre cluster de base de données Aurora MySQL
Considérations sur les performances du machine learning Aurora avec Aurora MySQL
Exigences pour l’utilisation du machine learning Aurora avec Aurora MySQL
AWS les services d'apprentissage automatique sont des services gérés qui sont configurés et exécutés dans leurs propres environnements de production. L'apprentissage automatique Aurora prend en charge l'intégration avec Amazon Bedrock, Amazon Comprehend et AI. SageMaker Avant d’essayer de configurer votre cluster de bases de données Aurora MySQL pour utiliser le machine learning Aurora, assurez-vous de comprendre les exigences et prérequis suivants.
-
Les services d'apprentissage automatique doivent être exécutés de la même manière Région AWS que votre cluster de base de données Aurora MySQL. Vous ne pouvez pas utiliser les services de machine learning à partir d’un cluster de bases de données Aurora MySQL situé dans une autre région.
-
Si votre cluster de base de données Aurora MySQL se trouve dans un cloud public virtuel (VPC) différent de celui de votre service Amazon Bedrock, Amazon Comprehend ou AI, le groupe de sécurité du VPC doit autoriser les connexions sortantes vers le SageMaker service d'apprentissage automatique Aurora cible. Pour plus d’informations, consultez Contrôler le trafic vers vos ressources AWS à l’aide de groupes de sécurité dans le Guide de l’utilisateur Amazon VPC.
-
Vous pouvez mettre à niveau un cluster Aurora s’exécutant sur une version plus ancienne d’Aurora MySQL vers une version plus récente si vous souhaitez utiliser le machine learning Aurora avec ce cluster. Pour plus d’informations, consultez Mises à jour du moteur de base de données pour Amazon Aurora MySQL.
-
Votre cluster de bases de données Aurora MySQL doit utiliser un groupe de paramètres de cluster de bases de données personnalisé. À la fin du processus de configuration de chaque service de machine learning Aurora que vous souhaitez utiliser, vous ajoutez l’Amazon Resource Name (ARN) du rôle IAM associé qui a été créé pour le service. Nous vous recommandons de créer à l’avance un groupe de paramètres de cluster de bases de données personnalisé pour votre Aurora MySQL et de configurer votre cluster de bases de données Aurora MySQL pour qu’il soit prêt à être modifié à la fin du processus de configuration.
-
Pour l' SageMaker IA :
-
Les composants de machine learning que vous souhaitez utiliser pour les inférences doivent être configurés et prêts à être utilisés. Pendant le processus de configuration de votre cluster de base de données Aurora MySQL, assurez-vous que l'ARN du point de terminaison SageMaker AI est disponible. Les data scientists de votre équipe sont probablement les mieux placés pour travailler avec l' SageMaker IA pour préparer les modèles et effectuer les autres tâches de ce type. Pour commencer à utiliser Amazon SageMaker AI, consultez Get Started with Amazon SageMaker AI. Pour plus d'informations sur les inférences et les points de terminaison, voir Real-time inférence.
-
Pour utiliser l' SageMaker IA avec vos propres données d'entraînement, vous devez configurer un compartiment Amazon S3 dans le cadre de votre configuration Aurora MySQL pour l'apprentissage automatique Aurora. Pour ce faire, vous devez suivre le même processus général que pour configurer l'intégration de l' SageMaker IA. Pour un résumé de ce processus de configuration facultatif, consultez Configuration de votre cluster de base de données Aurora MySQL pour utiliser Amazon S3 for SageMaker AI (facultatif).
-
-
Pour les bases de données globales Aurora, vous configurez les services d'apprentissage automatique Aurora que vous souhaitez utiliser dans tous les Régions AWS éléments de votre base de données globale Aurora. Par exemple, si vous souhaitez utiliser l'apprentissage automatique Aurora avec l' SageMaker IA pour votre base de données globale Aurora, procédez comme suit pour chaque cluster de base de données Aurora MySQL dans chaque cluster Région AWS :
-
Configurez les services Amazon SageMaker AI avec les mêmes modèles de formation et points de terminaison d' SageMaker IA. Ils doivent également porter les mêmes noms.
-
Créez les rôles IAM comme indiqué dans Configuration de votre cluster de bases de données Aurora MySQL de façon à utiliser le machine learning Aurora.
-
Ajoutez l’ARN du rôle IAM au groupe de paramètres de cluster de bases de données personnalisé pour chaque cluster de bases de données Aurora MySQL dans chaque Région AWS.
Ces tâches nécessitent que l'apprentissage automatique Aurora soit disponible pour votre version d'Aurora MySQL dans tous Régions AWS les éléments de votre base de données globale Aurora.
-
Disponibilité des régions et des versions
La disponibilité et la prise en charge des fonctions varient selon les versions spécifiques de chaque moteur de base de données Aurora, et selon les Régions AWS.
-
Pour plus d'informations sur la disponibilité des versions et des régions pour Amazon Comprehend et Amazon SageMaker AI with Aurora MySQL, consultez. Machine Learning Aurora avec Aurora MySQL
-
Amazon Bedrock est uniquement pris en charge sur Aurora MySQL 3.06 ou version ultérieure.
Pour plus d’informations sur les régions disponibles pour Amazon Bedrock, consultez Modèles pris en charge par Région AWS dans le Guide de l’utilisateur Amazon Bedrock.
Fonctions prises en charge et limitations du machine learning Aurora avec Aurora MySQL
Lorsque vous utilisez Aurora MySQL avec le machine learning Aurora, les limitations suivantes s’appliquent :
-
L’extension de machine learning Aurora ne prend pas en charge les interfaces vectorielles.
-
Les intégrations de machine learning Aurora ne sont pas prises en charge lorsqu’elles sont utilisées dans un déclencheur.
Les fonctions de machine learning Aurora ne sont pas compatibles avec la réplication de journaux binaires (binlog).
-
Le paramètre
--binlog-format=STATEMENTenvoie une exception pour les appels vers des fonctions Machine Learning Aurora. -
Les fonctions du machine learning Aurora sont non déterministes, et les fonctions stockées non déterministes ne sont pas compatibles avec ce format binlog.
Pour plus d’informations, consultez Formats de journalisation binaire
dans la documentation MySQL. -
-
Les fonctions stockées qui appellent des tables dont les colonnes sont toujours générées ne sont pas prises en charge. Cela s’applique à toutes les fonctions stockées dans Aurora MySQL. Pour en savoir plus sur ce type de colonne, consultez CREATE TABLE et colonnes générées
dans la documentation MySQL. -
Les fonctions Amazon Bedrock ne prennent pas en charge
RETURNS JSON. Vous pouvez utiliserCONVERTouCASTafin d’effectuer une conversion deTEXTversJSONsi nécessaire. -
Amazon Bedrock ne prend pas en charge les demandes par lots.
-
Aurora MySQL prend en charge tous les points de terminaison d' SageMaker IA qui lisent et écrivent le format CSV (valeurs séparées par des virgules) via un
ContentTypede.text/csvCe format est accepté par les algorithmes d' SageMaker IA intégrés suivants :-
Linear Learner
-
Random Cut Forest
-
XGBoost
Pour en savoir plus sur ces algorithmes, consultez la section Choisir un algorithme dans le manuel Amazon SageMaker AI Developer Guide.
-
Configuration de votre cluster de bases de données Aurora MySQL de façon à utiliser le machine learning Aurora
Dans les rubriques suivantes, vous pouvez trouver des procédures de configuration distinctes pour chacun de ces services de machine learning Aurora.
Rubriques
Configuration de votre cluster de bases de données Aurora MySQL pour utiliser Amazon Bedrock
Configuration de votre cluster de bases de données Aurora MySQL pour utiliser Amazon Comprehend
Configuration de votre cluster de base de données Aurora MySQL pour utiliser l' SageMaker IA
Autorisation d’accès aux utilisateurs de base de données pour le machine learning Aurora
Configuration de votre cluster de bases de données Aurora MySQL pour utiliser Amazon Bedrock
L'apprentissage automatique Aurora repose sur des rôles et des politiques Gestion des identités et des accès AWS (IAM) pour permettre à votre cluster de base de données Aurora MySQL d'accéder aux services Amazon Bedrock et de les utiliser. Les procédures suivantes créent une stratégie d’autorisation et un rôle IAM afin que votre cluster de bases de données puisse s’intégrer à Amazon Bedrock.
Pour créer la stratégie IAM
Connectez-vous à la console IAM Console de gestion AWS et ouvrez-la à https://console.aws.amazon.com/iam/
l'adresse. -
Dans le panneau de navigation, choisissez Stratégies.
-
Choisissez Créer une stratégie.
-
Sur la page Spécifier les autorisations, choisissez Bedrock dans Sélectionner un service.
Affichage des autorisations Amazon Bedrock.
-
Développez Lire, puis sélectionnez InvokeModel.
-
Sélectionnez Tout dans Ressources.
La page Spécifier les autorisations doit ressembler à la figure suivante.
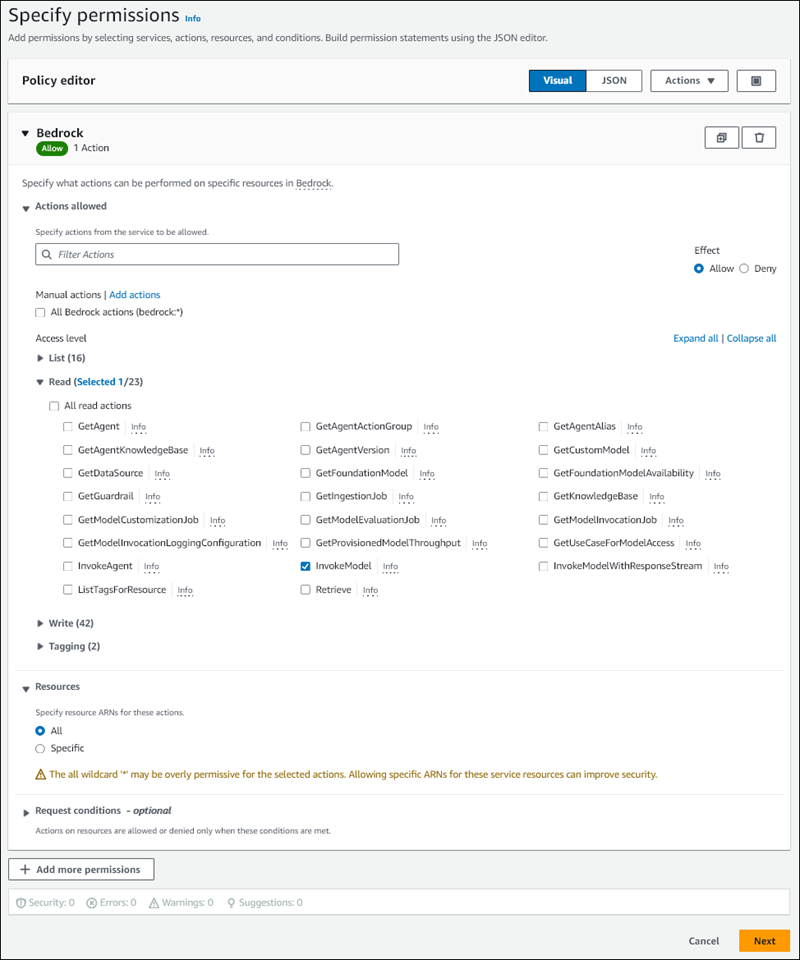
-
Choisissez Suivant.
-
Sur la page Examiner et créer, entrez un nom pour votre stratégie, par exemple
BedrockInvokeModel. -
Examinez votre stratégie, puis choisissez Créer une stratégie.
Créez ensuite le rôle IAM qui utilise la stratégie d’autorisation d’Amazon Bedrock.
Pour créer le rôle IAM
Connectez-vous à la console IAM Console de gestion AWS et ouvrez-la à https://console.aws.amazon.com/iam/
l'adresse. -
Choisissez Rôles dans le panneau de navigation.
-
Choisissez Créer un rôle.
-
Sur la page Sélectionner une entité de confiance, choisissez RDS dans Cas d’utilisation.
-
Sélectionnez RDS - Ajouter un rôle à la base de données, puis cliquez sur Suivant.
-
Sur la page Ajouter des autorisations, sélectionnez la politique IAM que vous avez créée dans Politiques d’autorisations, puis choisissez Suivant.
-
Sur la page Nommer, vérifier et créer, entrez un nom pour votre rôle, par exemple
ams-bedrock-invoke-model-role.Le rôle doit ressembler à la figure suivante.
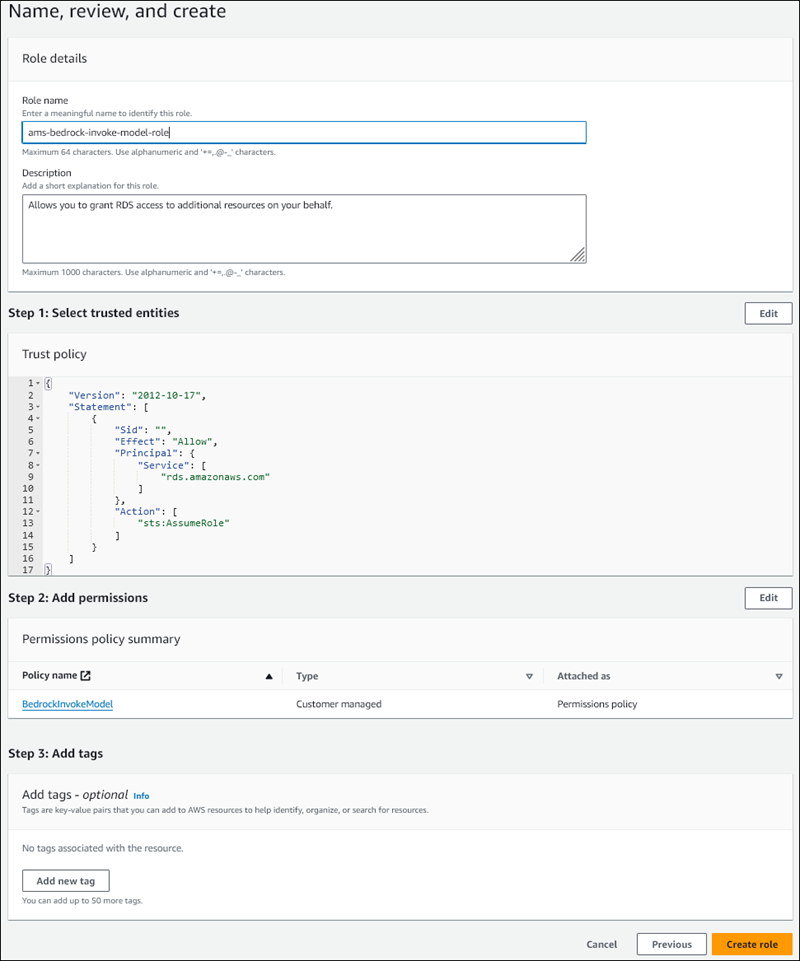
-
Passez en revue les informations de votre rôle, puis choisissez Créer un rôle.
Associez ensuite le rôle IAM d’Amazon Bedrock à votre cluster de bases de données.
Pour associer le rôle IAM à votre cluster de bases de données
Connectez-vous à la console Amazon RDS Console de gestion AWS et ouvrez-la à https://console.aws.amazon.com/rds/
l'adresse. -
Choisissez Bases de données dans le panneau de navigation.
-
Choisissez le cluster de bases de données Aurora MySQL que vous souhaitez connecter aux services Amazon Bedrock.
-
Choisissez l’onglet Connectivity & security (Connectivité et sécurité).
-
Dans la section Gérer les rôles IAM, choisissez Sélectionner les rôles IAM à ajouter à ce cluster.
-
Choisissez le rôle IAM que vous avez créé, puis choisissez Ajouter un rôle.
Le rôle IAM est associé à votre cluster de bases de données, d’abord avec l’état En attente, puis Actif. Une fois le processus terminé, vous pouvez trouver le rôle dans la liste Current IAM roles for this cluster (Rôles IAM actuels pour ce cluster).
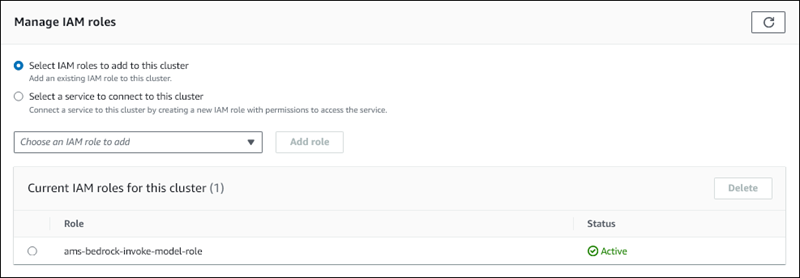
Vous devez ajouter l’ARN de ce rôle IAM au paramètre aws_default_bedrock_role dans le groupe de paramètres du cluster de bases de données associé au cluster Aurora MySQL. Si votre cluster de bases de données Aurora MySQL n’utilise pas de groupe de paramètres de cluster de bases de données personnalisé, vous devez en créer un à utiliser avec votre cluster de bases de données Aurora MySQL pour terminer l’intégration. Pour plus d’informations, consultez Groupes de paramètres de cluster de bases de données pour les clusters de bases de données Amazon Aurora.
Pour configurer le paramètre du cluster de bases de données
-
Dans la console Amazon RDS, ouvrez l’onglet Configuration de votre cluster de bases de données Aurora MySQL.
-
Localisez le groupe de paramètres du cluster de bases de données configuré pour votre cluster. Choisissez le lien pour ouvrir votre groupe de paramètres de cluster de bases de données personnalisé, puis sélectionnez Modifier.
-
Trouvez le paramètre
aws_default_bedrock_roledans votre groupe de paramètres du cluster de bases de données personnalisé. -
Dans le champ Valeur, saisissez l’ARN du rôle IAM.
-
Choisissez Save changes (Enregistrer les modifications) pour sauvegarder le paramètre.
-
Redémarrez l’instance principale de votre cluster de bases de données Aurora MySQL afin que ce paramètre prenne effet.
L’intégration IAM pour Amazon Bedrock est terminée. Poursuivez la configuration de votre cluster de bases de données Aurora MySQL pour qu’il fonctionne avec Amazon Bedrock en Autorisation d’accès aux utilisateurs de base de données pour le machine learning Aurora.
Configuration de votre cluster de bases de données Aurora MySQL pour utiliser Amazon Comprehend
L'apprentissage automatique Aurora repose sur Gestion des identités et des accès AWS des rôles et des politiques pour permettre à votre cluster de base de données Aurora MySQL d'accéder aux services Amazon Comprehend et de les utiliser. La procédure suivante crée automatiquement un rôle et une stratégie IAM pour votre cluster afin qu’il puisse utiliser Amazon Comprehend.
Configurer votre cluster de bases de données Aurora MySQL pour utiliser Amazon Comprehend
Connectez-vous à la console Amazon RDS Console de gestion AWS et ouvrez-la à https://console.aws.amazon.com/rds/
l'adresse. -
Choisissez Bases de données dans le panneau de navigation.
-
Choisissez le cluster de bases de données Aurora MySQL que vous souhaitez connecter aux services Amazon Comprehend.
-
Choisissez l’onglet Connectivity & security (Connectivité et sécurité).
-
Dans la section Gérer les rôles IAM, choisissez Sélectionner un service à connecter à ce cluster.
-
Choisissez Amazon Comprehend dans le menu, puis choisissez Connecter un service.
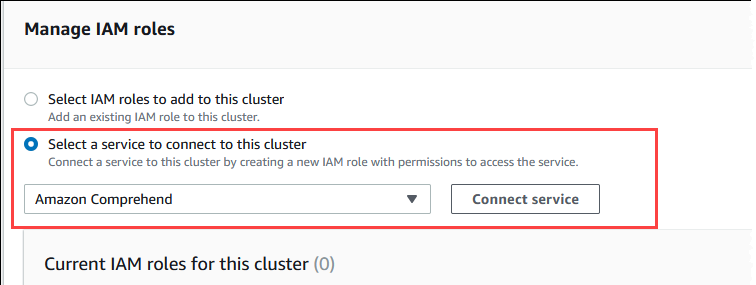
La boîte de dialogue Connect cluster to Amazon Comprehend (Connecter le cluster à Amazon Comprehend) ne nécessite aucune information supplémentaire. Toutefois, il se peut qu’un message vous avertisse que l’intégration entre Aurora et Amazon Comprehend est actuellement en version préliminaire. Assurez-vous de lire le message avant de continuer. Vous pouvez choisir Annuler si vous préférez ne pas continuer.
Choisissez Connect service (Connecter un service) pour terminer le processus d’intégration.
Aurora crée le rôle IAM. Il crée également la stratégie qui permet au cluster de bases de données Aurora MySQL d’utiliser les services Amazon Comprehend et associe la stratégie au rôle. Une fois le processus terminé, vous pouvez trouver le rôle dans la liste Current IAM roles for this cluster (Rôles IAM actuels pour ce cluster), comme indiqué dans l’image suivante.
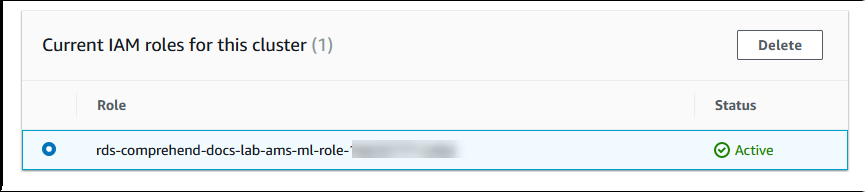
Vous devez ajouter l’ARN de ce rôle IAM au paramètre
aws_default_comprehend_roledans le groupe de paramètres du cluster de bases de données associé au cluster de bases de données Aurora MySQL. Si votre cluster de bases de données Aurora MySQL n’utilise pas de groupe de paramètres de cluster de bases de données personnalisé, vous devez en créer un à utiliser avec votre cluster de bases de données Aurora MySQL pour terminer l’intégration. Pour plus d’informations, consultez Groupes de paramètres de cluster de bases de données pour les clusters de bases de données Amazon Aurora.Après avoir créé votre groupe de paramètres de cluster de bases de données personnalisé et l’avoir associé à votre cluster de bases de données Aurora MySQL, vous pouvez continuer à suivre ces étapes.
Si votre cluster utilise un groupe de paramètres de base de données personnalisé, procédez comme suit.
Dans la console Amazon RDS, ouvrez l’onglet Configuration de votre cluster de bases de données Aurora MySQL.
-
Localisez le groupe de paramètres du cluster de bases de données configuré pour votre cluster. Choisissez le lien pour ouvrir votre groupe de paramètres de cluster de bases de données personnalisé, puis sélectionnez Modifier.
Trouvez le paramètre
aws_default_comprehend_roledans votre groupe de paramètres du cluster de bases de données personnalisé.Dans le champ Valeur, saisissez l’ARN du rôle IAM.
Choisissez Save changes (Enregistrer les modifications) pour sauvegarder le paramètre. Dans l’image suivante, vous pouvez voir un exemple.

Redémarrez l’instance principale de votre cluster de bases de données Aurora MySQL afin que ce paramètre prenne effet.
L’intégration IAM pour Amazon Comprehend est terminée. Continuez à configurer votre cluster de bases de données Aurora MySQL pour qu’il fonctionne avec Amazon Comprehend en accordant l’accès aux utilisateurs de base de données appropriés.
Configuration de votre cluster de base de données Aurora MySQL pour utiliser l' SageMaker IA
La procédure suivante crée automatiquement le rôle et la politique IAM pour votre cluster de base de données Aurora MySQL afin qu'il puisse utiliser l' SageMaker IA. Avant d'essayer de suivre cette procédure, assurez-vous que le point de terminaison SageMaker AI est disponible afin de pouvoir le saisir en cas de besoin. En général, les scientifiques des données de votre équipe se chargent de produire un point de terminaison que vous pouvez utiliser à partir de votre cluster de bases de données Aurora MySQL. Vous pouvez trouver de tels points de terminaison dans la console SageMaker AI.
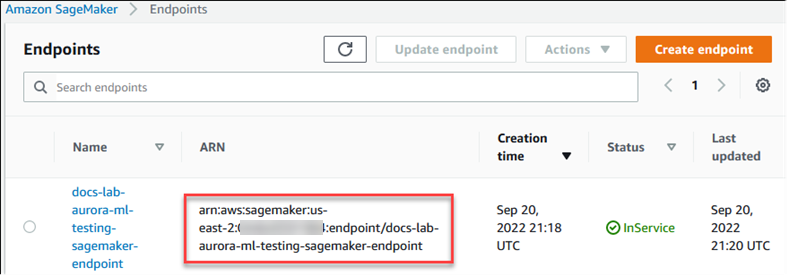
Pour configurer votre cluster de base de données Aurora MySQL afin d'utiliser l' SageMaker IA
Connectez-vous à la console Amazon RDS Console de gestion AWS et ouvrez-la à https://console.aws.amazon.com/rds/
l'adresse. -
Choisissez Databases dans le menu de navigation Amazon RDS, puis choisissez le cluster de bases de données Aurora MySQL que vous souhaitez connecter aux services d' SageMaker intelligence artificielle.
-
Choisissez l’onglet Connectivity & security (Connectivité et sécurité).
-
Choisissez Select a service to connect to this cluster (Sélectionner un service à connecter à ce cluster) dans la section Manage IAM roles (Gérer les rôles IAM). Choisissez SageMaker AI dans le sélecteur.
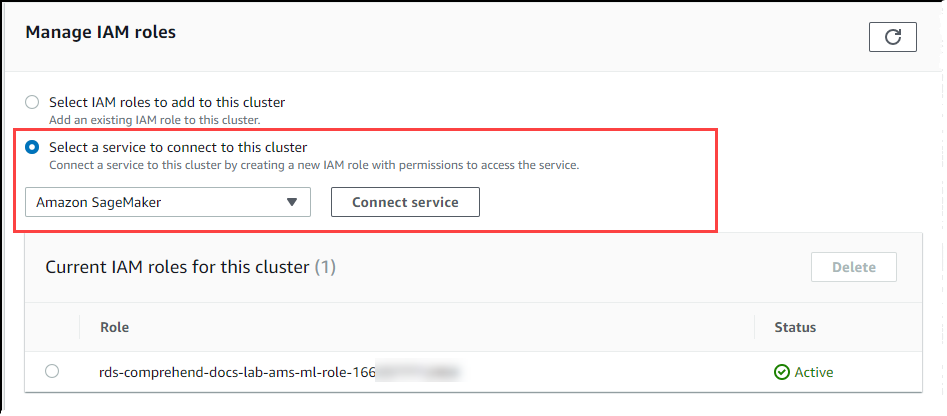
Choisissez Connect service (Connecter un service).
Dans la boîte de dialogue Connect cluster to SageMaker AI, entrez l'ARN du point de terminaison SageMaker AI.
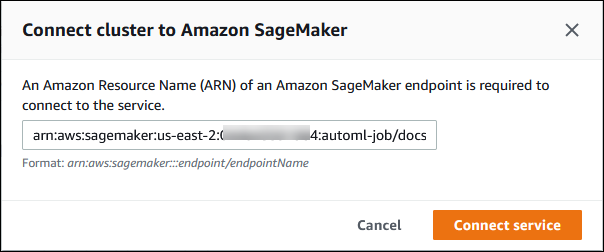
-
Aurora crée le rôle IAM. Il crée également la politique qui permet au cluster de base de données Aurora MySQL d'utiliser les services d' SageMaker intelligence artificielle et attache la politique au rôle. Une fois le processus terminé, vous pouvez trouver le rôle dans la liste Current IAM roles for this cluster (Rôles IAM actuels pour ce cluster).
Ouvrez la console IAM à l’adresse https://console.aws.amazon.com/iam/
. Choisissez Roles (Rôles) dans la section Gestion des accès du menu de navigation Gestion des identités et des accès AWS .
Trouvez le rôle parmi ceux qui figurent dans la liste. Son nom utilise le modèle suivant.
rds-sagemaker-your-cluster-name-role-auto-generated-digitsOuvrez la page Résumé du rôle et recherchez l’ARN. Notez l’ARN ou copiez-le à l’aide du widget de copie.
Ouvrez la console Amazon RDS à l'adresse https://console.aws.amazon.com/rds/
. Choisissez votre cluster de bases de données Aurora MySQL, puis son onglet Configuration.
Localisez le groupe de paramètres du cluster de bases de données et choisissez le lien pour ouvrir votre groupe de paramètres du cluster de bases de données personnalisé. Recherchez le paramètre
aws_default_sagemaker_roleet saisissez l’ARN du rôle IAM dans le champ Valeur, puis enregistrez le paramètre.Redémarrez l’instance principale de votre cluster de bases de données Aurora MySQL afin que ce paramètre prenne effet.
La configuration IAM est maintenant terminée. Continuez à configurer votre cluster de base de données Aurora MySQL pour qu'il fonctionne avec l' SageMaker IA en accordant l'accès aux utilisateurs de base de données appropriés.
Si vous souhaitez utiliser vos modèles d' SageMaker IA pour la formation plutôt que d'utiliser des composants d' SageMaker IA prédéfinis, vous devez également ajouter le bucket Amazon S3 à votre cluster de base de données Aurora MySQL, comme Configuration de votre cluster de base de données Aurora MySQL pour utiliser Amazon S3 for SageMaker AI (facultatif) indiqué ci-dessous.
Configuration de votre cluster de base de données Aurora MySQL pour utiliser Amazon S3 for SageMaker AI (facultatif)
Pour utiliser l' SageMaker IA avec vos propres modèles plutôt que d'utiliser les composants prédéfinis fournis par l' SageMaker IA, vous devez configurer un bucket Amazon S3 pour le cluster de base de données Aurora MySQL à utiliser. Pour plus d’informations sur la création d’un compartiment Amazon S3, consultez Créer un compartiment dans le Guide de l’utilisateur Amazon Simple Storage Service.
Pour configurer votre cluster de base de données Aurora MySQL afin d'utiliser un compartiment Amazon S3 pour l' SageMaker IA
Connectez-vous à la console Amazon RDS Console de gestion AWS et ouvrez-la à https://console.aws.amazon.com/rds/
l'adresse. -
Choisissez Databases dans le menu de navigation Amazon RDS, puis choisissez le cluster de bases de données Aurora MySQL que vous souhaitez connecter aux services d' SageMaker intelligence artificielle.
-
Choisissez l’onglet Connectivity & security (Connectivité et sécurité).
-
Choisissez Select a service to connect to this cluster (Sélectionner un service à connecter à ce cluster) dans la section Manage IAM roles (Gérer les rôles IAM). Choisissez Amazon S3 dans le sélecteur.
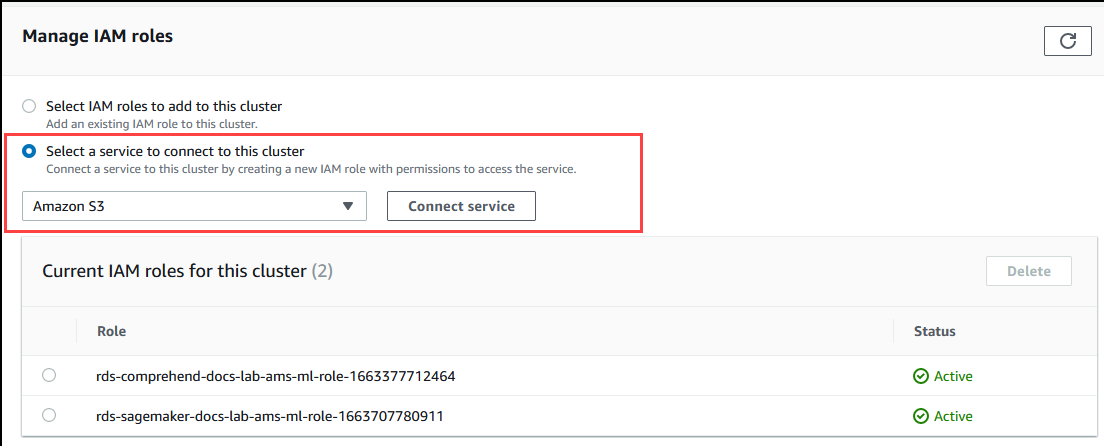
Choisissez Connect service (Connecter un service).
Dans la boîte de dialogue Connecter un cluster à Amazon S3, saisissez l’ARN du compartiment Amazon S3, comme indiqué dans l’image suivante.
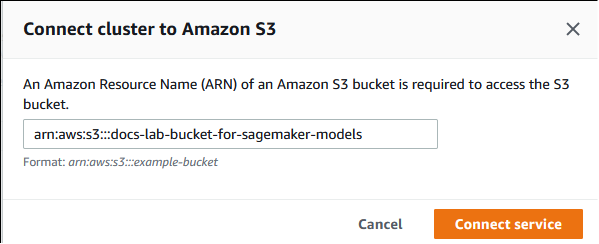
Choisissez Connect service (Connecter un service) pour terminer ce processus.
Pour plus d'informations sur l'utilisation des compartiments Amazon S3 avec l' SageMaker IA, consultez Spécifier un compartiment Amazon S3 pour télécharger des ensembles de données de formation et stocker les données de sortie dans le manuel Amazon SageMaker AI Developer Guide. Pour en savoir plus sur l'utilisation de l' SageMaker IA, consultez Get Started with Amazon SageMaker AI Notebook Instances dans le manuel du développeur Amazon SageMaker AI.
Autorisation d’accès aux utilisateurs de base de données pour le machine learning Aurora
Les utilisateurs de la base de données doivent être autorisés à invoquer ces fonctions de machine learning Aurora. La manière dont vous accordez l’autorisation dépend de la version de MySQL que vous utilisez pour votre cluster de bases de données Aurora MySQL, comme indiqué ci-dessous. La manière de procéder dépend de la version de MySQL utilisée par votre cluster de bases de données Aurora MySQL.
Pour Aurora MySQL version 3 (compatible avec MySQL 8.0), les utilisateurs de base de données doivent disposer du rôle de base de données approprié. Pour plus d’informations, consultez Utilisation de rôles
dans le Manuel de référence MySQL 8.0. Pour Aurora MySQL version 2 (compatible avec MySQL 5.7), les utilisateurs de base de données disposent de privilèges. Pour plus d’informations, consultez Contrôle d’accès et gestion des comptes
dans le Manuel de référence MySQL 5.7.
Le tableau suivant indique les rôles et les privilèges dont les utilisateurs de base de données ont besoin pour utiliser les fonctions de machine learning.
| Aurora MySQL version 3 (rôle) | Aurora MySQL version 2 (privilège) |
|---|---|
|
AWS_BEDROCK_ACCESS |
– |
|
AWS_COMPREHEND_ACCESS |
INVOKE COMPREHEND |
|
AWS_SAGEMAKER_ACCESS |
INVOKE SAGEMAKER |
Autorisation d’accès aux fonctions Amazon Bedrock
Pour permettre aux utilisateurs de base de données d’accéder aux fonctions d’Amazon Bedrock, utilisez l’instruction SQL suivante :
GRANT AWS_BEDROCK_ACCESS TOuser@domain-or-ip-address;
Les utilisateurs de base de données doivent également disposer d’autorisations EXECUTE pour les fonctions que vous créez pour travailler avec Amazon Bedrock :
GRANT EXECUTE ON FUNCTIONdatabase_name.function_nameTOuser@domain-or-ip-address;
Enfin, les rôles des utilisateurs de base de données doivent être définis sur AWS_BEDROCK_ACCESS :
SET ROLE AWS_BEDROCK_ACCESS;
Les fonctions Amazon Bedrock peuvent désormais être utilisées.
Autorisation d’accès aux fonctions Amazon Comprehend
Pour permettre aux utilisateurs de la base de données d’accéder aux fonctions d’Amazon Comprehend, utilisez l’instruction appropriée à votre version d’Aurora MySQL.
Aurora MySQL version 3 (compatible avec MySQL 8.0)
GRANT AWS_COMPREHEND_ACCESS TOuser@domain-or-ip-address;Aurora MySQL version 2 (compatible avec MySQL 5.7)
GRANT INVOKE COMPREHEND ON *.* TOuser@domain-or-ip-address;
Les fonctions Amazon Comprehend peuvent désormais être utilisées. Pour obtenir des exemples d’utilisation, consultez Utiliser Amazon Comprehend avec votre cluster de bases de données Aurora MySQL.
Octroi de l'accès aux fonctions de SageMaker l'IA
Pour permettre aux utilisateurs de base de données d'accéder aux fonctions d' SageMaker intelligence artificielle, utilisez l'instruction appropriée à votre version d'Aurora MySQL.
Aurora MySQL version 3 (compatible avec MySQL 8.0)
GRANT AWS_SAGEMAKER_ACCESS TOuser@domain-or-ip-address;Aurora MySQL version 2 (compatible avec MySQL 5.7)
GRANT INVOKE SAGEMAKER ON *.* TOuser@domain-or-ip-address;
Les utilisateurs de la base de données doivent également EXECUTE disposer d'autorisations pour les fonctions que vous créez pour travailler avec l' SageMaker IA. Supposons que vous ayez créé deux fonctionsdb2.company_forecasts, db1.anomoly_score et que vous appeliez les services de votre point de terminaison SageMaker AI. Vous accordez des privilèges d’exécution comme indiqué dans l’exemple ci-dessous.
GRANT EXECUTE ON FUNCTION db1.anomaly_score TOuser1@domain-or-ip-address1; GRANT EXECUTE ON FUNCTION db2.company_forecasts TOuser2@domain-or-ip-address2;
Les fonctions de l' SageMaker IA peuvent désormais être utilisées. Pour obtenir des exemples d’utilisation, consultez Utilisation de l' SageMaker IA avec votre cluster de base de données Aurora MySQL.
Utilisation d’Amazon Bedrock avec votre cluster de bases de données Aurora MySQL
Pour utiliser Amazon Bedrock, vous devez créer une fonction définie par l’utilisateur (UDF) dans votre base de données Aurora MySQL qui invoque un modèle. Pour plus d’informations, consultez Modèles pris en charge dans Amazon Bedrock dans le Guide de l’utilisateur Amazon Bedrock.
Un UDF utilise la syntaxe suivante :
CREATE FUNCTIONfunction_name(argumenttype) [DEFINER = user] RETURNSmysql_data_type[SQL SECURITY {DEFINER | INVOKER}] ALIAS AWS_BEDROCK_INVOKE_MODEL MODEL ID 'model_id' [CONTENT_TYPE 'content_type'] [ACCEPT 'content_type'] [TIMEOUT_MStimeout_in_milliseconds];
-
Les fonctions Amazon Bedrock ne prennent pas en charge
RETURNS JSON. Vous pouvez utiliserCONVERTouCASTafin d’effectuer une conversion deTEXTversJSONsi nécessaire. -
Si vous ne spécifiez pas la valeur
CONTENT_TYPEouACCEPT, la valeur par défaut estapplication/json. -
Si vous ne spécifiez pas la valeur
TIMEOUT_MS, la valeuraurora_ml_inference_timeoutest utilisée.
Par exemple, l’UDF suivant invoque le modèle Amazon Titan Text Express :
CREATE FUNCTION invoke_titan (request_body TEXT) RETURNS TEXT ALIAS AWS_BEDROCK_INVOKE_MODEL MODEL ID 'amazon.titan-text-express-v1' CONTENT_TYPE 'application/json' ACCEPT 'application/json';
Pour autoriser un utilisateur de base de données à utiliser cette fonction, utilisez la commande SQL suivante :
GRANT EXECUTE ON FUNCTIONdatabase_name.invoke_titan TOuser@domain-or-ip-address;
L’utilisateur peut ensuite appeler invoke_titan comme n’importe quelle autre fonction, comme illustré dans l’exemple suivant. Assurez-vous de formater le corps de la demande conformément aux modèles de texte Amazon Titan.
CREATE TABLE prompts (request varchar(1024)); INSERT INTO prompts VALUES ( '{ "inputText": "Generate synthetic data for daily product sales in various categories - include row number, product name, category, date of sale and price. Produce output in JSON format. Count records and ensure there are no more than 5.", "textGenerationConfig": { "maxTokenCount": 1024, "stopSequences": [], "temperature":0, "topP":1 } }'); SELECT invoke_titan(request) FROM prompts; {"inputTextTokenCount":44,"results":[{"tokenCount":296,"outputText":" ```tabular-data-json { "rows": [ { "Row Number": "1", "Product Name": "T-Shirt", "Category": "Clothing", "Date of Sale": "2024-01-01", "Price": "$20" }, { "Row Number": "2", "Product Name": "Jeans", "Category": "Clothing", "Date of Sale": "2024-01-02", "Price": "$30" }, { "Row Number": "3", "Product Name": "Hat", "Category": "Accessories", "Date of Sale": "2024-01-03", "Price": "$15" }, { "Row Number": "4", "Product Name": "Watch", "Category": "Accessories", "Date of Sale": "2024-01-04", "Price": "$40" }, { "Row Number": "5", "Product Name": "Phone Case", "Category": "Accessories", "Date of Sale": "2024-01-05", "Price": "$25" } ] } ```","completionReason":"FINISH"}]}
Pour les autres modèles que vous utilisez, veillez à appliquer le format approprié. Pour plus d’informations, consultez Paramètres d’inférence pour les modèles de fondation dans le Guide de l’utilisateur Amazon Bedrock.
Utiliser Amazon Comprehend avec votre cluster de bases de données Aurora MySQL
Pour Aurora MySQL, le machine learning Aurora fournit les deux fonctions intégrées suivantes pour travailler avec Amazon Comprehend et vos données texte. Vous fournissez le texte à analyser (input_data) et vous spécifiez la langue (language_code).
- aws_comprehend_detect_sentiment
-
Cette fonction identifie le texte comme ayant une posture émotionnelle positive, négative, neutre ou mixte. La documentation de référence de cette fonction est la suivante.
aws_comprehend_detect_sentiment( input_text, language_code [,max_batch_size] )Pour en savoir plus, consultez Sentiment dans le Guide du développeur Amazon Comprehend.
- aws_comprehend_detect_sentiment_confidence
-
Cette fonction mesure le niveau de confiance du sentiment détecté pour un texte donné. Elle renvoie une valeur (type
double) qui indique la confiance du sentiment attribué par la fonction aws_comprehend_detect_sentiment au texte. La confiance est une mesure statistique comprise entre 0 et 1. Plus le niveau de confiance est élevé, plus vous pouvez donner de poids au résultat. Voici un résumé de la documentation de la fonction.aws_comprehend_detect_sentiment_confidence( input_text, language_code [,max_batch_size] )
Pour les deux fonctions (aws_comprehend_detect_sentiment_confidence, aws_comprehend_detect_sentiment), max_batch_size utilise une valeur par défaut de 25 si aucune valeur n’est spécifiée. La taille de lot doit toujours être supérieure à 0. Le paramètre max_batch_size vous permet d’ajuster les performances des appels de fonction Amazon Comprehend. Une taille de lot importante est l’assurance de performances plus rapides pour une meilleure utilisation de la mémoire sur le cluster de bases de données Aurora MySQL. Pour de plus amples informations, veuillez consulter Considérations sur les performances du machine learning Aurora avec Aurora MySQL.
Pour plus d'informations sur les paramètres et les types de retours pour les fonctions de détection des sentiments dans Amazon Comprehend, consultez DetectSentiment
Exemple Exemple : une requête simple utilisant les fonctions Amazon Comprehend
Voici un exemple de requête simple qui invoque ces deux fonctions pour voir dans quelle mesure vos clients sont satisfaits de votre équipe d’assistance. Supposons que vous disposiez d’une table de base de données (support) qui enregistre les commentaires des clients après chaque demande d’aide. Cet exemple de requête applique les deux fonctions intégrées au texte de la colonne feedback du tableau et génère les résultats. Les valeurs de confiance renvoyées par la fonction sont des valeurs de confiance doubles comprises entre 0,0 et 1,0. Pour une sortie plus lisible, cette requête arrondit les résultats à 6 décimales. Pour faciliter les comparaisons, cette requête trie également les résultats par ordre décroissant, en commençant par le résultat présentant le degré de confiance le plus élevé.
SELECT feedback AS 'Customer feedback', aws_comprehend_detect_sentiment(feedback, 'en') AS Sentiment, ROUND(aws_comprehend_detect_sentiment_confidence(feedback, 'en'), 6) AS Confidence FROM support ORDER BY Confidence DESC;+----------------------------------------------------------+-----------+------------+ | Customer feedback | Sentiment | Confidence | +----------------------------------------------------------+-----------+------------+ | Thank you for the excellent customer support! | POSITIVE | 0.999771 | | The latest version of this product stinks! | NEGATIVE | 0.999184 | | Your support team is just awesome! I am blown away. | POSITIVE | 0.997774 | | Your product is too complex, but your support is great. | MIXED | 0.957958 | | Your support tech helped me in fifteen minutes. | POSITIVE | 0.949491 | | My problem was never resolved! | NEGATIVE | 0.920644 | | When will the new version of this product be released? | NEUTRAL | 0.902706 | | I cannot stand that chatbot. | NEGATIVE | 0.895219 | | Your support tech talked down to me. | NEGATIVE | 0.868598 | | It took me way too long to get a real person. | NEGATIVE | 0.481805 | +----------------------------------------------------------+-----------+------------+ 10 rows in set (0.1898 sec)
Exemple Exemple : détermination du sentiment moyen pour un texte supérieur à un niveau de confiance spécifique
Généralement, une requête Amazon Comprehend recherche les lignes dans lesquelles le sentiment représente une certaine valeur, avec un niveau de confiance supérieur à un certain nombre. Par exemple, la requête suivante illustre comment vous pouvez déterminer le sentiment moyen des documents dans votre base de données. La requête prend uniquement en compte les documents dans lesquels la confiance de l’évaluation est de 80 % minimum.
SELECT AVG(CASE aws_comprehend_detect_sentiment(productTable.document, 'en') WHEN 'POSITIVE' THEN 1.0 WHEN 'NEGATIVE' THEN -1.0 ELSE 0.0 END) AS avg_sentiment, COUNT(*) AS total FROM productTable WHERE productTable.productCode = 1302 AND aws_comprehend_detect_sentiment_confidence(productTable.document, 'en') >= 0.80;
Utilisation de l' SageMaker IA avec votre cluster de base de données Aurora MySQL
Pour utiliser les fonctionnalités d' SageMaker IA de votre cluster de base de données Aurora MySQL, vous devez créer des fonctions stockées qui intègrent vos appels au point de terminaison SageMaker AI et à ses fonctionnalités d'inférence. Pour ce faire, vous utilisez CREATE FUNCTION de MySQL de la même manière que vous le faites pour les autres tâches de traitement sur votre cluster de bases de données Aurora MySQL.
Pour utiliser des modèles déployés dans l' SageMaker IA à des fins d'inférence, vous devez créer des fonctions définies par l'utilisateur à l'aide des instructions du langage de définition de données (DDL) MySQL pour les fonctions stockées. Chaque fonction stockée représente le point de terminaison SageMaker AI hébergeant le modèle. Lorsque vous définissez une telle fonction, vous spécifiez les paramètres d'entrée du modèle, le point de terminaison SageMaker AI spécifique à invoquer et le type de retour. La fonction renvoie l'inférence calculée par le point de terminaison de l' SageMaker IA après avoir appliqué le modèle aux paramètres d'entrée.
Toutes les fonctions stockées de machine learning Aurora retournent des types numériques ou VARCHAR. Vous pouvez utiliser tous les types numériques à l’exception de BIT. Les autres types, tels que JSON, BLOB, TEXT et DATE ne sont pas autorisés.
L'exemple suivant montre la CREATE FUNCTION syntaxe permettant de travailler avec l' SageMaker IA.
CREATE FUNCTION function_name (
arg1 type1,
arg2 type2, ...)
[DEFINER = user]
RETURNS mysql_type
[SQL SECURITY { DEFINER | INVOKER } ]
ALIAS AWS_SAGEMAKER_INVOKE_ENDPOINT
ENDPOINT NAME 'endpoint_name'
[MAX_BATCH_SIZE max_batch_size];
Il s’agit d’une extension de l’instruction DDL CREATE FUNCTION normale. Dans l'CREATE FUNCTIONinstruction qui définit la fonction SageMaker AI, vous ne spécifiez pas de corps de fonction. Au lieu de cela, vous spécifiez le mot-clé ALIAS à la place du corps de la fonction. Actuellement, le machine learning Aurora prend uniquement en charge aws_sagemaker_invoke_endpoint pour cette syntaxe étendue. Vous devez spécifier le paramètre endpoint_name. Un point de terminaison d' SageMaker IA peut avoir des caractéristiques différentes pour chaque modèle.
Note
Pour plus d’informations sur CREATE FUNCTION, consultez CREATE PROCEDURE et CREATE FUNCTION
Le paramètre max_batch_size est facultatif. Par défaut, la taille maximale du lot est de 10 000. Vous pouvez utiliser ce paramètre dans votre fonction pour limiter le nombre maximum d'entrées traitées dans une demande groupée adressée à l' SageMaker IA. Le max_batch_size paramètre peut aider à éviter une erreur causée par des entrées trop volumineuses ou à faire en sorte que l' SageMaker IA renvoie une réponse plus rapidement. Ce paramètre affecte la taille d'une mémoire tampon interne utilisée pour le traitement des demandes d' SageMaker IA. Une valeur trop importante pour max_batch_size peut entraîner une surcharge de mémoire substantielle sur votre instance de base de données.
Nous recommandons de laisser le paramètre MANIFEST sur sa valeur par défaut de OFF. Bien que vous puissiez utiliser MANIFEST ON cette option, certaines fonctionnalités de l' SageMaker IA ne peuvent pas utiliser directement le fichier CSV exporté avec cette option. Le format du manifeste n'est pas compatible avec le format du manifeste attendu par SageMaker AI.
Vous créez une fonction stockée distincte pour chacun de vos modèles d' SageMaker IA. Ce mappage de fonctions vers des modèles est obligatoire, car un point de terminaison est associé à un modèle spécifique, et chaque modèle accepte différents paramètres. L'utilisation de types SQL pour les entrées du modèle et le type de sortie du modèle permet d'éviter les erreurs de conversion de type lors du transfert de données entre les AWS services. Vous pouvez contrôler qui peut appliquer le modèle. Vous pouvez également contrôler les caractéristiques d’exécution en spécifiant un paramètre représentant la taille de lot maximum.
Actuellement, toutes les fonctions de machine learning Aurora disposent de la propriété NOT DETERMINISTIC. Si vous ne spécifiez pas cette propriété de manière explicite, Aurora définit automatiquement NOT DETERMINISTIC. Cette exigence est due au fait que le modèle d' SageMaker IA peut être modifié sans aucune notification à la base de données. Dans ce cas, les appels à une fonction de machine learning Aurora peuvent retourner différents résultats pour la même entrée au sein d’une seule transaction.
Vous ne pouvez pas utiliser les caractéristiques CONTAINS SQL, NO SQL, READS SQL DATA ou MODIFIES SQL DATA dans votre instruction CREATE
FUNCTION.
Voici un exemple d'utilisation de l'appel d'un point de terminaison d' SageMaker IA pour détecter des anomalies. Il existe un point de terminaison SageMaker basé sur l'IArandom-cut-forest-model. Le modèle correspondant est déjà entraîné par l’algorithme random-cut-forest. Pour chaque entrée, le modèle retourne un score d’anomalie. Cet exemple illustre les points de données dont le score dépasse de 3 déviations standard (environ le 99,9e centile) le score moyen.
CREATE FUNCTION anomaly_score(value real) returns real
alias aws_sagemaker_invoke_endpoint endpoint name 'random-cut-forest-model-demo';
set @score_cutoff = (select avg(anomaly_score(value)) + 3 * std(anomaly_score(value)) from nyc_taxi);
select *, anomaly_detection(value) score from nyc_taxi
where anomaly_detection(value) > @score_cutoff;
Jeu de caractères requis pour les fonctions d' SageMaker IA renvoyant des chaînes
Nous vous recommandons de spécifier un jeu de caractères utf8mb4 comme type de retour pour vos fonctions d' SageMaker IA qui renvoient des valeurs de chaîne. Si cela n’est pas pratique, utilisez une chaîne suffisamment longue pour que le type de retour conserve une valeur représentée dans le jeu de caractères utf8mb4. L’exemple suivant illustre comment déclarer le jeu de caractères utf8mb4 pour votre fonction.
CREATE FUNCTION my_ml_func(...) RETURNS VARCHAR(5) CHARSET utf8mb4 ALIAS ...Actuellement, chaque fonction d' SageMaker IA qui renvoie une chaîne utilise le jeu de caractères utf8mb4 pour la valeur de retour. La valeur de retour utilise ce jeu de caractères même si votre fonction SageMaker AI déclare implicitement ou explicitement un jeu de caractères différent pour son type de retour. Si votre fonction SageMaker AI déclare un jeu de caractères différent pour la valeur de retour, les données renvoyées peuvent être tronquées silencieusement si vous les stockez dans une colonne de table trop courte. Par exemple, une requête avec une clause DISTINCT crée un tableau temporaire. Ainsi, le résultat de la fonction SageMaker AI peut être tronqué en raison de la façon dont les chaînes sont traitées en interne lors d'une requête.
Exportation de données vers Amazon S3 pour la formation de modèles d' SageMaker IA (niveau avancé)
Nous vous recommandons de commencer à utiliser l'apprentissage automatique et l' SageMaker IA Aurora en utilisant certains des algorithmes fournis, et de demander aux data scientists de votre équipe de vous fournir les points de terminaison d' SageMaker IA que vous pouvez utiliser avec votre code SQL. Vous trouverez ci-dessous des informations minimales sur l'utilisation de votre propre compartiment Amazon S3 avec vos propres modèles d' SageMaker IA et votre cluster de base de données Aurora MySQL.
Le machine learning comprend deux étapes principales : la formation et l’inférence. Pour entraîner des modèles d' SageMaker IA, vous exportez des données vers un compartiment Amazon S3. Le compartiment Amazon S3 est utilisé par une instance de bloc-notes Jupyter SageMaker AI pour entraîner votre modèle avant son déploiement. Vous pouvez utiliser l’instruction SELECT INTO OUTFILE S3 pour interroger les données d’un cluster de bases de données Aurora MySQL et les enregistrer directement dans des fichiers texte stockés dans un compartiment Amazon S3. Ensuite, l’instance de bloc-bote consomme les données du compartiment Amazon S3 dans le cadre de la formation.
Le machine learning Aurora étend la syntaxe SELECT INTO OUTFILE existante dans Aurora MySQL pour exporter les données au format CSV. Le fichier CSV généré peut être directement consommé par des modèles ayant besoin de ce format dans le cadre de la formation.
SELECT * INTO OUTFILE S3 's3_uri' [FORMAT {CSV|TEXT} [HEADER]] FROM table_name;L’extension prend en charge le format CSV standard.
-
Le format
TEXTest identique au format d’exportation MySQL existant. Il s’agit du format par défaut. -
CSVLe format est un format récemment introduit qui suit les spécifications de RFC-4180. -
Si vous spécifiez le mot-clé facultatif
HEADER, le fichier de sortie contient une ligne d’en-tête. Les étiquettes de la ligne d’en-tête correspondent aux noms de colonnes de l’instructionSELECT. -
Vous pouvez toujours utiliser les mots-clés
CSVetHEADERcomme identifiants.
La syntaxe étendue et la grammaire de SELECT INTO sont désormais comme suit :
INTO OUTFILE S3 's3_uri'
[CHARACTER SET charset_name]
[FORMAT {CSV|TEXT} [HEADER]]
[{FIELDS | COLUMNS}
[TERMINATED BY 'string']
[[OPTIONALLY] ENCLOSED BY 'char']
[ESCAPED BY 'char']
]
[LINES
[STARTING BY 'string']
[TERMINATED BY 'string']
]
Considérations sur les performances du machine learning Aurora avec Aurora MySQL
Les services Amazon Bedrock, Amazon Comprehend SageMaker et AI effectuent l'essentiel du travail lorsqu'ils sont invoqués par une fonction d'apprentissage automatique Aurora. Cela signifie que vous pouvez adapter ces ressources selon vos besoins, de manière indépendante. Pour votre cluster de bases de données Aurora MySQL, vous pouvez rendre vos appels de fonctions aussi efficaces que possible. Vous trouverez ci-dessous quelques considérations relatives aux performances à prendre en compte lors de l’utilisation du machine learning Aurora.
Modèle et invite
Les performances obtenues avec Amazon Bedrock varient considérablement selon le modèle et l’invite utilisés. Choisissez le modèle et l’invite qui conviennent le mieux à votre cas d’utilisation.
Cache de requête
Le cache de requête MySQL Aurora ne fonctionne pas pour les fonctions de machine learning Aurora. Aurora MySQL ne stocke pas de résultats de requête dans le cache de requête pour aucune instruction SQL appelant des fonctions de machine learning Aurora.
Optimisation par lots pour les appels de fonction de machine learning Aurora
L’élément principal des performances de machine learning Aurora que vous pouvez influencer depuis votre cluster Aurora est le paramètre du mode par lots pour les appels vers les fonctions stockées de machine learning Aurora. Les fonctions de machine learning occasionnant généralement une surcharge conséquente, l’appel d’un service externe séparément pour chaque ligne est impraticable. Le machine learning Aurora peut réduire cette surcharge en combinant dans un seul lot les appels au service de machine learning Aurora externe pour de nombreuses lignes. Le machine learning Aurora reçoit les réponses pour toutes les lignes d’entrée, puis transmet les réponses, ligne par ligne, à la requête en cours d’exécution. Cette optimisation améliore le débit et la latence de vos requêtes Aurora sans en modifier les résultats.
Lorsque vous créez une fonction stockée Aurora connectée à un point de terminaison SageMaker AI, vous définissez le paramètre de taille du lot. Ce paramètre influence le nombre de lignes transférées pour chaque appel sous-jacent à l' SageMaker IA. Pour les requêtes qui traitent un grand nombre de lignes, la charge nécessaire pour effectuer un appel d' SageMaker IA distinct pour chaque ligne peut être importante. Plus l’ensemble de données traité par la procédure stockée est important, plus grande sera la taille de lot.
Si l'optimisation du mode batch peut être appliquée à une fonction d' SageMaker IA, vous pouvez le savoir en vérifiant le plan de requête produit par l'EXPLAIN PLANinstruction. Dans ce cas, la colonne extra du plan d’exécution inclut Batched machine learning. L'exemple suivant montre un appel à une fonction d' SageMaker IA qui utilise le mode batch.
mysql> CREATE FUNCTION anomaly_score(val real) returns real alias aws_sagemaker_invoke_endpoint endpoint name 'my-rcf-model-20191126';
Query OK, 0 rows affected (0.01 sec)
mysql> explain select timestamp, value, anomaly_score(value) from nyc_taxi;
+----+-------------+----------+------------+------+---------------+------+---------+------+------+----------+--------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+----------+------------+------+---------------+------+---------+------+------+----------+--------------------------+
| 1 | SIMPLE | nyc_taxi | NULL | ALL | NULL | NULL | NULL | NULL | 48 | 100.00 | Batched machine learning |
+----+-------------+----------+------------+------+---------------+------+---------+------+------+----------+--------------------------+
1 row in set, 1 warning (0.01 sec)
Lorsque vous appelez l’une des fonctions Amazon Comprehend intégrées, vous pouvez contrôler le taille de lot en spécifiant le paramètre max_batch_size facultatif. Ce paramètre limite le nombre maximum de valeurs input_text traitées dans chaque lot. En envoyant plusieurs objets à la fois, cela réduit le nombre d’allers-retours entre Aurora et Amazon Comprehend. Limiter la taille de lot s’avère utile dans les situations impliquant une requête avec une clause LIMIT. En utilisant une petite valeur pour max_batch_size, vous pouvez éviter d’appeler Amazon Comprehend plus de fois que vous n’avez de textes d’entrée.
L’optimisation par lots pour l’évaluation des fonctions de machine learning Aurora s’applique dans les cas suivants :
-
Appels de fonction dans la liste sélectionnée ou la clause
WHEREdes instructionsSELECT. -
Appels de fonction dans la liste
VALUESdes instructionsINSERTetREPLACE. -
SageMaker Fonctions de l'IA dans
SETles valeursUPDATEdes déclarations :INSERT INTO MY_TABLE (col1, col2, col3) VALUES (ML_FUNC(1), ML_FUNC(2), ML_FUNC(3)), (ML_FUNC(4), ML_FUNC(5), ML_FUNC(6)); UPDATE MY_TABLE SET col1 = ML_FUNC(col2), SET col3 = ML_FUNC(col4) WHERE ...;
Surveillance du machine learning Aurora
Vous pouvez surveiller les opérations par lots de machine learning Aurora en interrogeant plusieurs variables globales, comme indiqué dans l’exemple ci-dessous.
show status like 'Aurora_ml%';
Vous pouvez réinitialiser ces variables d’état en utilisant une instruction FLUSH STATUS. Ainsi, tous les chiffres représentent des totaux, des moyennes, etc. depuis la dernière réinitialisation de la variable.
Aurora_ml_logical_request_cnt-
Nombre de demandes logiques que l’instance de base de données a évaluées pour qu’elles soient envoyées aux services de machine learning Aurora depuis la dernière réinitialisation de l’état. Si un traitement par lots a été utilisé, cette valeur peut être supérieure à
Aurora_ml_actual_request_cnt. Aurora_ml_logical_response_cnt-
Le nombre total de réponses reçues par Aurora MySQL de la part des services de machine learning Aurora dans toutes les requêtes exécutées par des utilisateurs de l’instance de base de données.
Aurora_ml_actual_request_cnt-
Nombre total de demandes effectuées par Aurora MySQL auprès des services de machine learning Aurora sur l’ensemble des requêtes exécutées par les utilisateurs de l’instance de base de données.
Aurora_ml_actual_response_cnt-
Le nombre total de réponses reçues par Aurora MySQL de la part des services de machine learning Aurora dans toutes les requêtes exécutées par des utilisateurs de l’instance de base de données.
Aurora_ml_cache_hit_cnt-
Le nombre total d’accès au cache interne reçus par Aurora MySQL de la part des services de machine learning Aurora dans toutes les requêtes exécutées par des utilisateurs de l’instance de base de données.
Aurora_ml_retry_request_cnt-
Nombre de nouvelles tentatives de demande que l’instance de base de données a envoyées aux services de machine learning Aurora depuis la dernière réinitialisation de l’état.
Aurora_ml_single_request_cnt-
Le nombre total de fonctions de machine learning Aurora évaluées par un mode autre que par lots dans toutes les requêtes exécutées par des utilisateurs de l’instance de base de données.
Pour plus d'informations sur la surveillance des performances des opérations d' SageMaker IA appelées par les fonctions d'apprentissage automatique Aurora, consultez la section Surveiller Amazon SageMaker AI.
