Para obtener capacidades similares a las de Amazon Timestream, considere Amazon Timestream LiveAnalytics para InfluxDB. Ofrece una ingesta de datos simplificada y tiempos de respuesta a las consultas en milisegundos de un solo dígito para realizar análisis en tiempo real. Obtenga más información aquí.
Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Creación de un clúster de réplica de lectura de Timestream para InfluxDB
Un clúster de réplica de lectura de Timestream para InfluxDB tiene una instancia de base de datos de escritura y una instancia de base de datos del lector en zonas de disponibilidad independientes. Los clústeres de réplica de lectura de Timestream para InfluxDB proporcionan alta disponibilidad, mayor capacidad para cargas de trabajo de lectura y una conmutación por error más rápida cuando se configura la conmutación por error a la réplica.
Requisitos previos de clúster de base de datos
importante
A continuación, se describen los requisitos previos para crear un clúster de réplica de lectura.
Configurar la red para el clúster de base de datos
Solo puede crear un clúster de base de datos de réplica de lectura de Timestream para InfluxDB en una nube privada virtual (VPC) en función del servicio de Amazon VPC. Debe estar en una zona con Región de AWS al menos tres zonas de disponibilidad. El grupo de subred de base de datos que elija para el clúster de base de datos debe abarcar al menos tres zonas de disponibilidad. Esta configuración garantiza que cada instancia de base de datos del clúster de base de datos se encuentre en una zona de disponibilidad diferente.
Para conectarse a su clúster de base de datos desde recursos que no sean instancias de EC2 en la misma VPC, configure las conexiones de red manualmente.
Requisitos previos adicionales
Antes de crear el clúster de réplica de lectura, tenga en cuenta los siguientes requisitos previos adicionales:
para adaptar los parámetros de configuración para su clúster de base de datos, especifique un grupo de parámetros de clúster de base de datos con la configuración de parámetros requerida. Para obtener más información acerca de cómo crear un grupo de parámetros de clúster de base de datos, consulte Grupos de parámetros para clústeres de réplica de lectura.
Determine el número de TCP/IP puerto que debe especificar para su clúster de base de datos. Los firewalls de algunas compañías bloquean las conexiones a los puertos predeterminados. Si el firewall de su compañía bloquea el puerto predeterminado, elija otro puerto para el clúster de base de datos. Todas las instancias de base de datos de un clúster de base de datos utilizan el mismo puerto.
Creación de un clúster de base de datos
Puede crear un clúster de base de datos de réplica de lectura Timestream for InfluxDB mediante la API Consola de administración de AWS Amazon Timestream for InfluxDB. AWS CLI
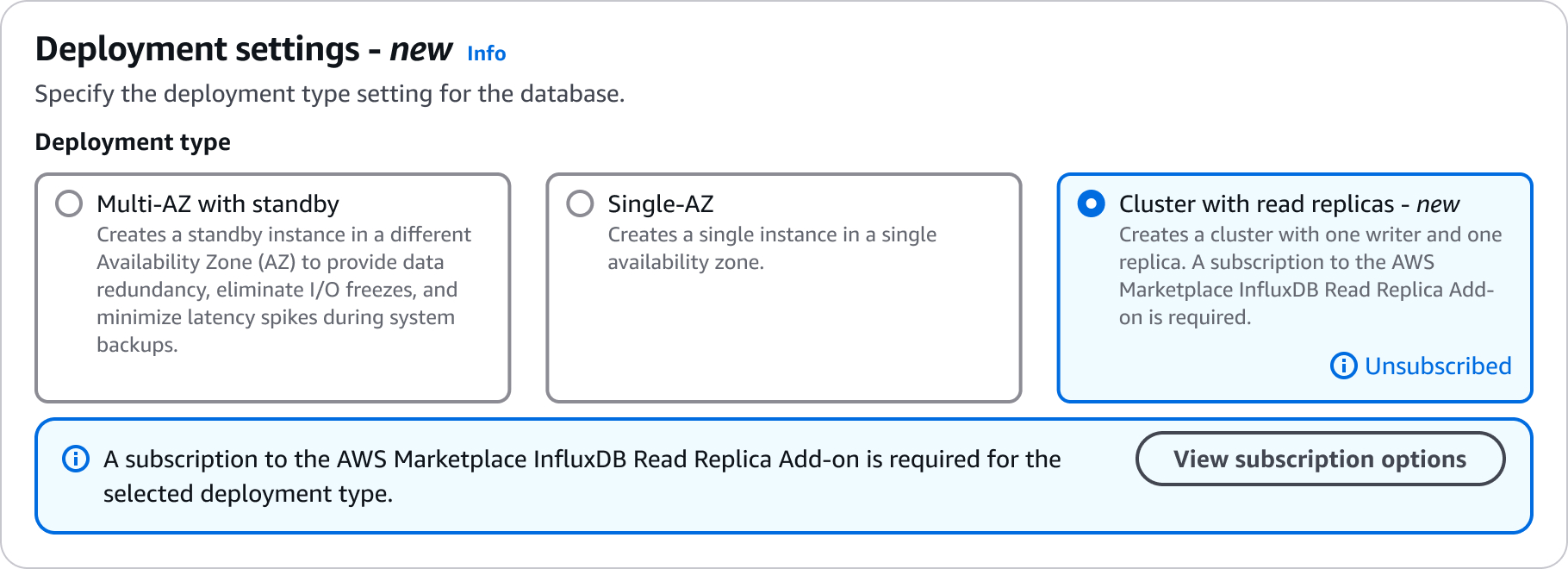
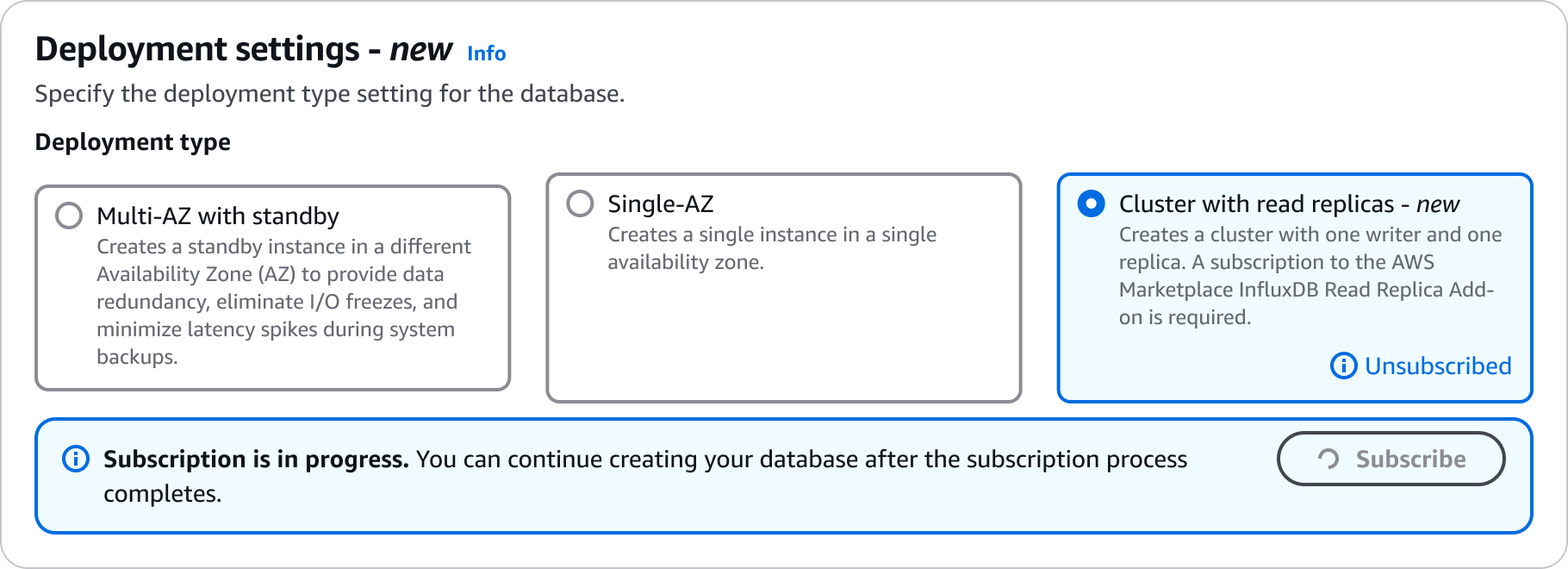
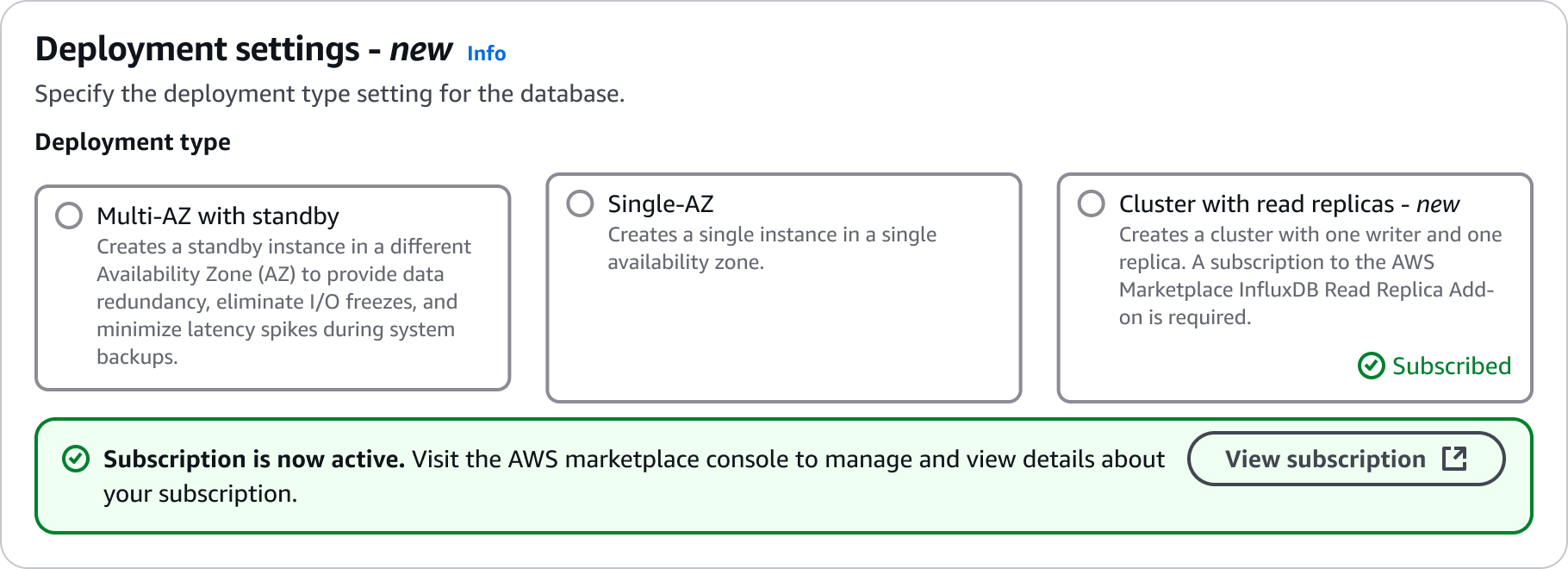
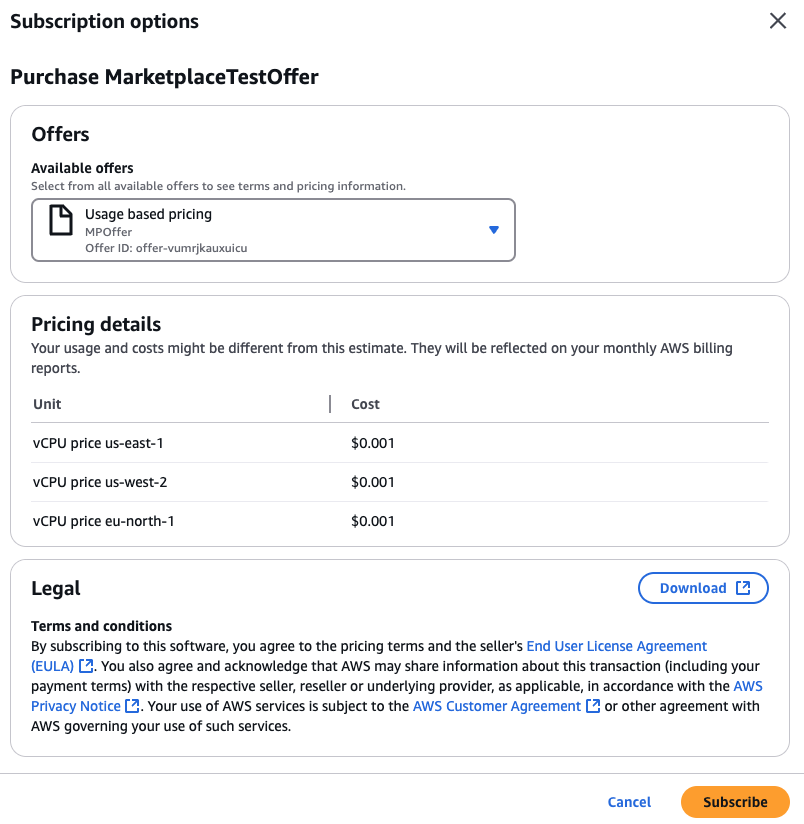
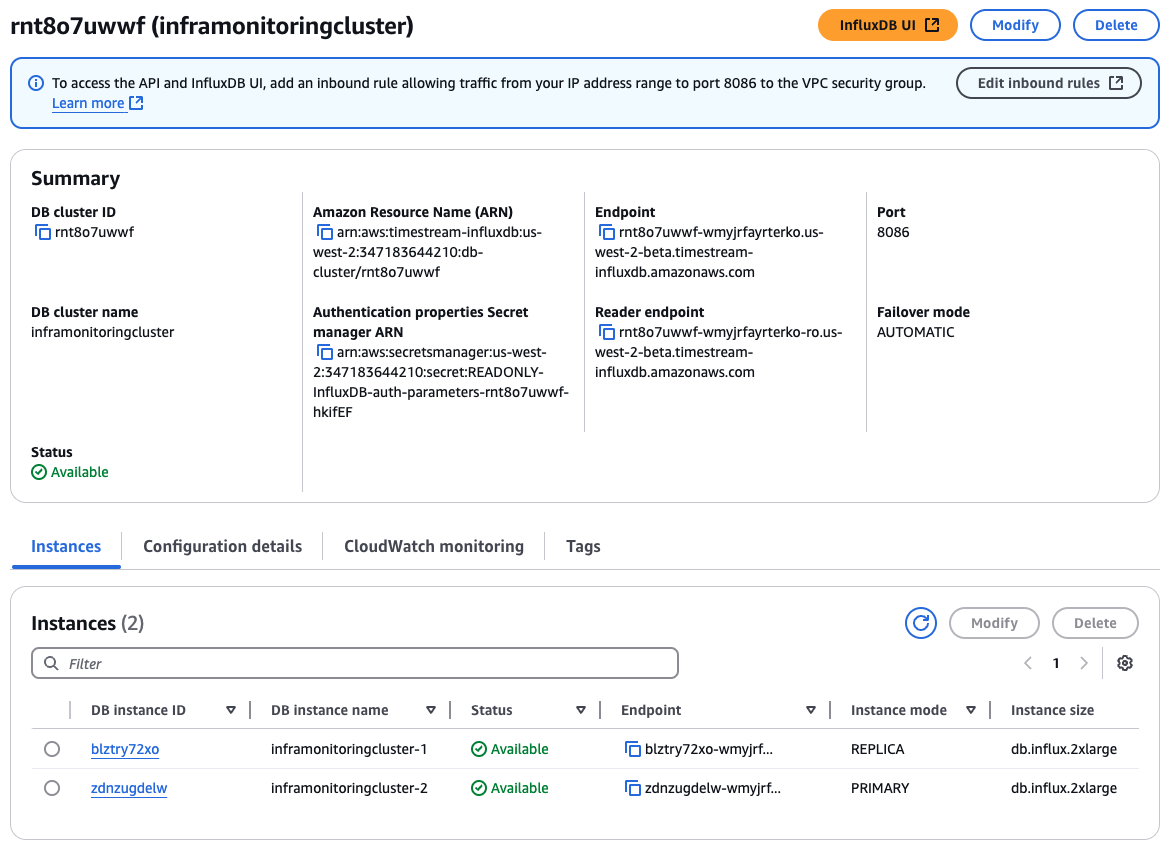
Configuración para crear clústeres de réplica de lectura
Para obtener detalles sobre los ajustes de configuración que se eligen al crear un clúster de réplica de lectura, consulte la siguiente tabla. Para obtener más información sobre las AWS CLI opciones, consulte create-db-cluster
| Configuración de la consola | Descripción de la configuración | Opción de la CLI y parámetro de la API de Timestream para InfluxDB |
|---|---|---|
| Allocated storage (Almacenamiento asignado) | La cantidad de almacenamiento que se tiene que asignar a la instancia de base de datos en el clúster de base de datos (en gibibytes). Para obtener más información, consulte Almacenamiento de instancias de InfluxDB. |
Opción CLI: Parámetro de API: |
| Puerto de base de datos | El número de puerto en el que InfluxDB acepta conexiones. Valores válidos: 1024-65535 Predeterminado: 8086 Restricciones: el valor no puede ser 2375-2376, 7788-7799, 8090 ni 51678-51680. |
Opción CLI: Parámetro de API: |
| Nombre del clúster de base de datos | El nombre que identifica de forma exclusiva el clúster de base de datos. Los nombres de las instancias de base de datos deben ser únicos por cliente y por región. |
Opción CLI: Parámetro de API: |
| Tipo de instancia de base de datos | La capacidad de memoria y computación de cada instancia de base de datos en el clúster de base de datos de Timestream para InfluxDB, por ejemplo, db.influx.xlarge. Si es posible, elija una clase de instancia de base de datos lo bastante grande como para albergar en la memoria el conjunto de trabajo de una consulta típica. Cuando los conjuntos de trabajo se albergan en la memoria, el sistema puede evitar escribir en el disco, lo que mejora su rendimiento. |
Opción CLI: Parámetro de API: |
| Grupo de parámetros de clúster de base de datos | El ID del grupo de parámetros de base de datos que se asignarán al clúster de base de datos. Los grupos de parámetros de base de datos especifican cómo está configurada la base de datos. Por ejemplo, los grupos de parámetros de base de datos pueden especificar el límite de simultaneidad de consultas. |
Opción CLI: Parámetro de API: |
| Tipo de implementación |
Especifica si el clúster de base de datos se implementará como una réplica de lectura multinodo o una réplica de lectura multinodo Multi-AZ. Valores posibles: |
Opción CLI: Parámetro de API: |
| ID de subred de la VPC | El ID de subred de base de datos que desea utilizar para el clúster de base de datos. Seleccione Elegir existente para usar un grupo de subredes de base de datos existente y, a continuación, elija el grupo de subredes necesario en la lista desplegable Grupos de subredes de base de datos existentes. Elija Configuración automática para permitir que Timestream para InfluxDB seleccione un grupo de subredes de base de datos compatible. |
Opción CLI: Parámetro de API: |
| Organización | El nombre de la organización inicial del usuario administrador inicial en InfluxDB. Una organización de InfluxDB es un espacio de trabajo para un grupo de usuarios. |
Opción CLI: Parámetro de API: |
| Bucket | El nombre del bucket inicial de InfluxDB. Todos los datos de InfluxDB se almacenan en un bucket. Un bucket combina el concepto de base de datos y un período de retención (el tiempo que durante el que persiste un punto de datos). Un bucket pertenece a una organización. |
Opción CLI: Parámetro de API: |
| Log exports (Exportaciones de registros) |
Configuración para enviar registros del motor de InfluxDB a un bucket de S3 específico. Configuración para la entrega de registro de bucket de S3: El nombre del bucket de S3 al que se enviarán los registros: Indica si la entrega de registros al bucket de S3 está habilitada: Sintaxis abreviada: |
Opción CLI: Parámetro de API: |
| Contraseña | La contraseña del usuario administrador inicial que usted creó en InfluxDB. Esta contraseña le permitirá acceder a la IU de InfluxDB para realizar diversas tareas administrativas y también utilizar la CLI de InfluxDB para crear un token de operador. Estos atributos se almacenarán en un secreto creado en AWS Secrets Manager en su cuenta. |
Opción CLI: Parámetro de API: |
| Nombre de usuario | El nombre de usuario del usuario administrador inicial creado en InfluxDB. Debe comenzar por una letra y no puede terminar con un guion ni contener dos guiones seguidos. Por ejemplo, my-user1. Este nombre de usuario le permitirá acceder a la IU de InfluxDB para realizar diversas tareas administrativas y también utilizar la CLI de InfluxDB para crear un token de operador. Estos atributos se almacenarán en un secreto creado en AWS Secrets Manager en su cuenta. |
Opción CLI: Parámetro de API: |
| Acceso público | Indica si se puede acceder al clúster de base de datos desde fuera de la VPC. De acceso público le otorga al clúster de base de datos una dirección IP pública, lo que significa que es accesible desde fuera de la VPC. Para que sea accesible públicamente, el clúster de base de datos también debe estar en una subred pública de la VPC. No es de acceso público para que el clúster de base de datos sea accesible solo desde dentro de la VPC. |
Opciones de CLI: Parámetro de API: |
| Tipo de almacenamiento de la base de datos | Datos de InfluxDB. Puede elegir entre tres tipos diferentes de almacenamiento aprovisionado de IOPS incluidas de Influx en función de los requisitos de su carga de trabajo. Valores posibles:
|
Opciones de CLI: Parámetro de API: |
| VPC security group (Grupo de seguridad de VPC) | Una lista de grupos de seguridad de VPC que se van IDs a asociar a la instancia de base de datos. |
Opciones de CLI: Parámetro de API: |
| Subred de VPC IDs | Una lista de subredes de VPC IDs para asociarlas a la instancia de base de datos. Proporcione al menos dos subredes de VPC IDs en diferentes zonas de disponibilidad al implementar con un clúster de base de datos Timestream for InfluxDB. |
Opciones de CLI: Parámetro de API: |
| Modo de conmutación por error | Cómo responde el clúster ante un error en la instancia principal. Puede configurar esto con las siguientes opciones:
|
Opciones de CLI: Parámetro de API: |
importante
Como parte del objeto de respuesta del clúster de base de datos, recibirá uninfluxAuthParametersSecretArn. Esto incluirá el ARN de un secreto de Secrets Manager en su cuenta. Solo se completará cuando sus instancias de base de datos de InfluxDB estén disponibles. El secreto contiene los parámetros de autenticación de Influx proporcionados durante el proceso CreateDbInstance. Se trata de una copia de solo lectura, ya que cualquier dato de este secreto no afecta updates/modifications/deletions a la instancia de base de datos creada. Si elimina este secreto, la respuesta de nuestra API seguirá haciendo referencia al ARN del secreto eliminado.
