Para obtener capacidades similares a las de Amazon Timestream, considere Amazon Timestream LiveAnalytics para InfluxDB. Ofrece una ingesta de datos simplificada y tiempos de respuesta a las consultas en milisegundos de un solo dígito para realizar análisis en tiempo real. Obtenga más información aquí.
Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
¿Qué es Timestream para InfluxDB?
Amazon Timestream para InfluxDB es un motor de base de datos de series temporales gestionado que facilita a los desarrolladores DevOps y equipos de aplicaciones la ejecución de bases de datos de InfluxDB para aplicaciones de series temporales AWS en tiempo real mediante código abierto. APIs Con Amazon Timestream para InfluxDB, puede configurar, operar y escalar fácilmente cargas de trabajo de serie temporal que pueden responder consultas con un tiempo de respuesta de milisegundos de un solo dígito.
Amazon Timestream para InfluxDB le da acceso a las capacidades de la conocida versión de código abierto de InfluxDB en su ramificación 2.x. Esto significa que el código, las aplicaciones y las herramientas que ya utiliza en la actualidad con sus bases de datos de código abierto de InfluxDB existentes deberían funcionar a la perfección con Amazon Timestream para InfluxDB. Amazon Timestream para InfluxDB puede realizar automáticamente una copia de seguridad de su base de datos y mantener el software de la base de datos actualizado con la última versión. Además, Amazon Timestream para InfluxDB facilita el uso de la replicación para mejorar la disponibilidad de la base de datos y mejorar la durabilidad de los datos. Como ocurre con todos los AWS servicios, no se requieren inversiones iniciales y usted paga únicamente por los recursos que utilice.
Instancias de base de datos
Una instancia de base de datos es un entorno de base de datos aislado que se ejecuta en la nube. Es el componente básico de Amazon Timestream para InfluxDB. Una instancia de base de datos puede contener varias bases de datos creadas por el usuario (u organizaciones y grupos, en el caso de las bases de datos InfluxDb 2.x) y se puede acceder a ellas mediante las mismas herramientas y aplicaciones de cliente que podría utilizar para acceder a una instancia de InfluxDB independiente y autogestionada. Las instancias de base de datos se pueden crear y modificar fácilmente con las herramientas de la línea de comandos de AWS , las operaciones de la API de Amazon Timestream para InfluxDB o la Consola de administración de AWS.
nota
Amazon Timestream para InfluxDB permite el acceso a las bases de datos mediante las operaciones de la API de Influx y la IU de Influx. Amazon Timestream para InfluxDB no permite el acceso directo del host.
Puede tener hasta 40 instancias de Amazon Timestream para InfluxDB.
Cada instancia de base de datos tiene un ID de instancia de base de datos. Este nombre generado por el servicio identifica de forma exclusiva la instancia de base de datos cuando interactúa con la API y los comandos CLI de Amazon Timestream for InfluxDB. AWS El identificador de la instancia de base de datos es único para ese cliente en una región. AWS
El ID de instancia de base de datos se utiliza como parte del nombre de host de DNS asignado por Timestream para InfluxDB a su instancia. Por ejemplo, si especifica influxdb1 como nombre de instancia de base de datos y el servicio genera un ID de instancia c5vasdqn0b, Timestream asignará automáticamente un punto de conexión de DNS a su instancia. Un ejemplo de punto de conexión es c5vasdqn0b-3ksj4dla5nfjhi.timestream-influxdb.us-east-1.on.aws, donde c5vasdqn0b es su ID de instancia. Todas las instancias creadas antes del 09/12/2024 mantendrán la estructura anterior con un punto de conexión similar al siguiente: influxdb1-3ksj4dla5nfjhi.us-east-1.timestream-influxdb.amazonaws.com, donde influxdb1 es el nombre de su instancia.
En el punto final del ejemploc5vasdqn0b-3ksj4dla5nfjhi.timestream-influxdb.us-east-1.on.aws, la cadena 3ksj4dla5nfjhi es un identificador de cuenta único generado por AWS. El identificador 3ksj4dla5nfjhi del ejemplo no cambia para la cuenta especificada en una región determinada. Por lo tanto, todas las instancias de base de datos de la región creadas por esta cuenta comparten el mismo identificador fijo. Tenga en cuenta las siguientes características del identificador fijo:
-
Actualmente, Timestream para InfluxDB no admite el cambio de nombre de las instancias de base de datos.
-
Para todas las instancias creadas después del 09/12/2024, si elimina y vuelve a crear la instancia de base de datos con el mismo nombre, el punto de conexión cambiará, ya que se asignará un nuevo ID a la instancia. A la instancia creada antes de la fecha previamente mencionada se le asignará el mismo punto de conexión en función del nombre de la instancia.
-
Si utiliza la misma cuenta para crear una instancia de base de datos en una región diferente, el identificador generado internamente es diferente porque la región es diferente, como en
zxlasoonhvd.4a3j5du5ks7md2.timestream-influxdb.us-east-1.on.aws.
Cada instancia de base de datos admite solo un motor de base de datos de Timestream para InfluxDB.
Al crear una instancia de base de datos, InfluxDB requiere que se especifique un nombre de organización. Una instancia de base de datos puede alojar varias organizaciones y varios buckets asociados a cada organización.
Amazon Timestream para InfluxDB le permite crear una cuenta de usuario maestro y una contraseña para su instancia de base de datos como parte del proceso de creación. Este usuario maestro tiene permisos para crear organizaciones, buckets y para realizar operaciones de lectura, escritura, eliminación e inserción/actualización de los datos. También podrá acceder a InfluxUI y recuperar el token de operador al iniciar sesión por primera vez. Desde allí, también podrá gestionar todos sus tokens de acceso. Debe definir la contraseña del usuario maestro cuando cree una instancia de base de datos, pero puede cambiarla en cualquier momento mediante la API de Influx, la CLI de Influx o InfluxUI.
Clases de instancia de base de datos
La clase de instancia de base de datos determina la capacidad de cómputo y de memoria de una instancia de base de datos Amazon Timestream para InfluxDB. La clase de instancia de base de datos que se necesite dependerá de la potencia de procesamiento y de los requisitos de memoria.
Una clase de instancia de base de datos determina tanto el tamaño como el tipo de clase de instancia de base de datos. Por ejemplo, db.influx es un tipo de clase de instancia de base de datos optimizada para la memoria adecuada para los requisitos de memoria de alto rendimiento relacionados con la ejecución InfluxDb de cargas de trabajo. Dentro del tipo de clase de instancia db.influx, db.influx.2xlarge es una clase de instancia de base de datos. El tamaño de esta clase es 2xlarge.
Para obtener más información acerca de los precios de las clases de instancia, consulte Precios de Amazon Timestream para InfluxDB
Tipos de clase de instancia de base de datos
Amazon Timestream para InfluxDB admite las clases de instancia de base de datos para el siguiente caso de uso optimizadas para los casos de uso de InfluxDB.
-
db.influx: estas clases de instancia son idóneas para ejecutar cargas de trabajo de uso intensivo de memoria en bases de datos de código de InfluxDB.
Especificaciones de hardware para clases de instancia de base de datos
La siguiente terminología describe las especificaciones de hardware para clases de instancia de base de datos:
-
vCPU
El número de unidades centrales de procesamiento virtuales (). CPUs Una CPU virtual es una unidad de capacidad que se puede usar para comparar clases de instancia de base de datos.
-
Memoria (GiB)
La RAM, en gibibytes, asignada a la instancia de base de datos. A menudo, hay una relación coherente entre memoria y vCPU. Un ejemplo es la clase de instancia db.influx, que dispone de una relación de memoria y vCPU similar a la clase de instancia r7g de EC2.
-
Optimizado para Influx
La instancia de base de datos utiliza una pila de configuración optimizada y proporciona capacidad dedicada adicional I/O. This optimization provides the best performance by minimizing contention between I/O y de otro tipo para el tráfico de la instancia.
-
Ancho de banda de red
La velocidad de red relativa a otras clases de instancia de base de datos. En la siguiente tabla, podrá encontrar detalles de hardware sobre las clases de instancia de Amazon Timestream para InfluxDB.
| Clase de instancias | vCPU | Memoria (GiB) | Storage Type | Ancho de banda de la red (Gbps) |
|---|---|---|---|---|
| db.influx.medium | 1 | 8 | IOPS de Influx incluidas | 10 |
| db.influx.large | 2 | 16 | IOPS de Influx incluidas | 10 |
| db.influx.xlarge | 4 | 32 | IOPS de Influx incluidas | 10 |
| db.influx.2xlarge | 8 | 64 | IOPS de Influx incluidas | 10 |
| db.influx.4xlarge | 16 | 128 | IOPS de Influx incluidas | 10 |
| db.influx.8xlarge | 32 | 256 | IOPS de Influx incluidas | 12 |
| db.influx.12xlarge | 48 | 384 | IOPS de Influx incluidas | 20 |
| db.influx.16xlarge | 64 | 512 | IOPS de Influx incluidas | 25 |
| db.influx.24xlarge | 96 | 768 | IOPS de Influx incluidas | 40 |
Almacenamiento de instancias de InfluxDB
Las instancias de base de datos de Amazon Timestream para InfluxDB utilizan los volúmenes de IOPS incluidas de Influx para el almacenamiento de registros y bases de datos.
En algunos casos, es posible que la carga de trabajo de base de datos no alcance el 100 por ciento de las IOPS que usted aprovisionó. Para obtener más información, consulte Factores que afectan al rendimiento del almacenamiento. Para obtener más información acerca de los precios de almacenamiento de Timestream para InfluxDB, consulte Precios de Amazon Timestream
Tipos de almacenamiento de Amazon Timestream para InfluxDB
Amazon Timestream para InfluxDB admite un tipo de almacenamiento: IOPS de Influx incluidas. Puede crear instancias de Timestream para InfluxDB con hasta 16 tebibytes (TiB) de almacenamiento.
A continuación, se ofrece una breve descripción del tipo de almacenamiento disponible:
-
Almacenamiento incluido Influx IO: el rendimiento del almacenamiento es la combinación de I/O operaciones por segundo (IOPS) y la rapidez con la que el volumen de almacenamiento puede realizar lecturas y escrituras (rendimiento de almacenamiento). En cuanto a los volúmenes de almacenamiento de las IOPS de Influx incluidas, Amazon Timestream para InfluxDB ofrece 3 niveles de almacenamiento preconfigurados con las IOPS óptimas y el rendimiento necesario para los distintos tipos de cargas de trabajo.
Dimensionamiento de las instancias de InfluxDB
La configuración óptima de una instancia de Timestream para InfluxDB depende de varios factores, como la tasa de ingesta, el tamaño de los lotes, la cardinalidad de serie temporal, las consultas simultáneas y los tipos de consultas. Para ofrecer recomendaciones de dimensionamiento, consideremos una carga de trabajo modelo con las siguientes características:
-
Los datos los recopila y escribe una flota de agentes de Telegraf que recopilan el sistema, la CPU, la memoria, el disco, las E/S, etc., de un centro de datos.
Cada solicitud de escritura contiene 5000 líneas.
-
Las consultas ejecutadas en el sistema se clasifican como consultas de “complejidad moderada” y presentan las siguientes características:
-
Tienen múltiples funciones y una o dos expresiones regulares.
-
Pueden incluir grupos por cláusulas o muestrear un intervalo de tiempo de varias semanas.
-
Por lo general, tardan entre unos cientos de milisegundos y un par de miles de milisegundos en ejecutarse.
-
La CPU favorece principalmente el rendimiento de las consultas.
-
| Cantidad máxima de series | Escritura (líneas por segundo) | Lecturas (consultas por segundo) | Clase de instancia | Storage Type |
|---|---|---|---|---|
| <100 000 | ~50 000 | <10 | db.influx.large | 3000 operaciones incluidas de E/S de Influx |
| <1 MM | ~150 000 | <25 | db.influx.2xlarge | 3000 operaciones incluidas de E/S de Influx |
| ~1 MM | ~200 000 | ~25 | db.influx.4xlarge | 3000 operaciones incluidas de E/S de Influx |
| <5 MM | ~250 000 | ~35 | db.influx.4xlarge | 12 000 operaciones incluidas de E/S de Influx |
| <10 MM | ~500 000 | ~50 | db.influx.8xlarge | 12 000 operaciones incluidas de E/S de Influx |
| ~10 MM | <750 000 | <100 | db.influx.12xlarge | 12 000 operaciones incluidas de E/S de Influx |
Regiones de AWS y zonas de disponibilidad
Los recursos de informática en la nube de Amazon están alojados en varias ubicaciones de todo el mundo. Estas ubicaciones se componen de Regiones de AWS y. Cada AWS región es un área geográfica separada. Cada AWS región tiene varias ubicaciones aisladas conocidas como zonas de disponibilidad.
nota
Para obtener información sobre cómo encontrar una AWS región, consulte Regiones y zonas en la Guía del usuario de Amazon EC2.
Amazon Timestream para InfluxDB le permite colocar recursos, como instancias de base de datos, y datos en varias ubicaciones.
Amazon opera centros state-of-the-art de datos de alta disponibilidad. Aunque es infrecuente, puede suceder que se produzcan errores que afecten a la disponibilidad de las instancias de bases de datos que están en la misma ubicación. Si aloja todas sus instancias de base de datos en una ubicación que se ve afectada por dicho error, ninguna de sus instancias de base de datos estará disponible.
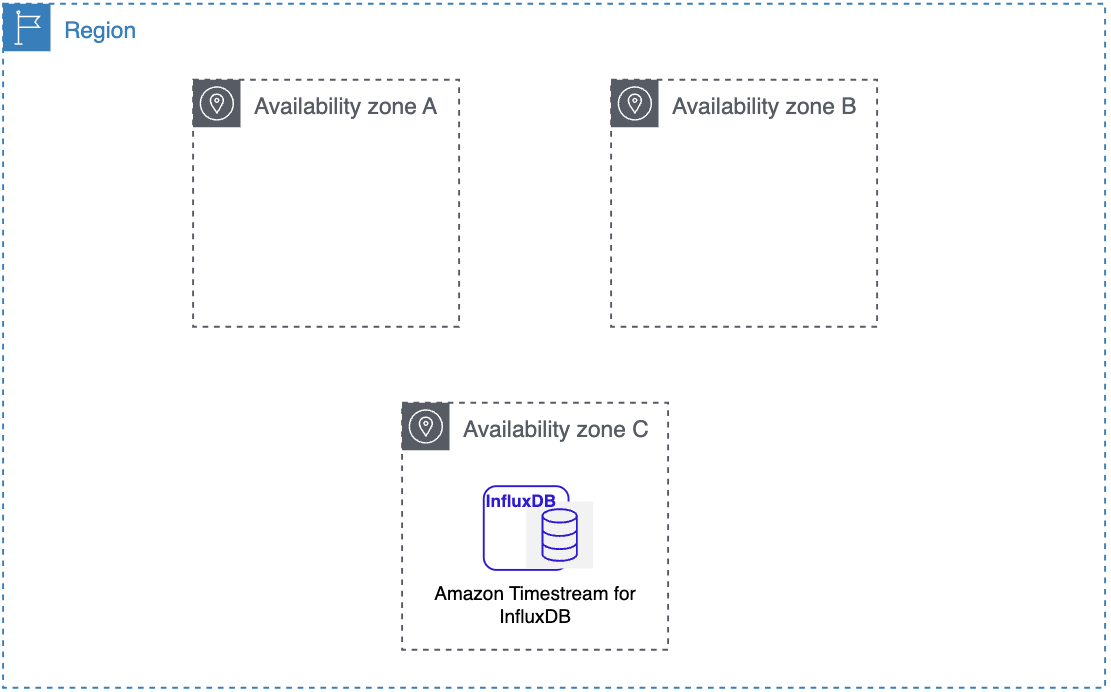
Es importante recordar que cada AWS región es completamente independiente. Cualquier actividad de Amazon Timestream for InfluxDB que inicie (por ejemplo, crear instancias de bases de datos o enumerar las instancias de bases de datos disponibles) se ejecuta solo en su región predeterminada actual. AWS La Región de AWS predeterminada se puede cambiar en la consola, o estableciendo la variable de entorno AWS_DEFAULT_REGION. O bien, se puede anular mediante el uso del parámetro con la --region tecla (). AWS Command Line Interface AWS CLI Para obtener más información, consulte Configuración de AWS Command Line Interface, específicamente, las secciones sobre variables de entorno y opciones de línea de comandos.
Para crear una instancia de base de datos de Amazon Timestream para InfluxDB o trabajar con ella en una región concreta de AWS , use el punto de conexión de servicio regional correspondiente.
AWS Disponibilidad regional
La siguiente tabla muestra AWS las regiones en las que Amazon Timestream para InfluxDB está disponible actualmente y el punto final de cada región.
| Nombre de la región de AWS | Región | Punto de conexión | Protocolo |
|---|---|---|---|
| Este de EE. UU. (Norte de Virginia) | us-east-1 | timestream-influxdb.us-east-1.amazonaws.com | HTTPS |
| Este de EE. UU. (Ohio) | us-east-2 | timestream-influxdb.us-east-2.amazonaws.com | HTTPS |
| Oeste de EE. UU. (Oregón) | us-west-2 | timestream-influxdb.us-west-2.amazonaws.com | HTTPS |
| Asia-Pacífico (Mumbai) | ap-south-1 | timestream-influxdb.ap-south-1.amazonaws.com | HTTPS |
| Asia-Pacífico (Singapur) | ap-southeast-1 | timestream-influxdb.ap-southeast-1.amazonaws.com | HTTPS |
| Asia-Pacífico (Sídney) | ap-southeast-2 | timestream-influxdb.ap-southeast-2.amazonaws.com | HTTPS |
| Asia-Pacífico (Tokio) | ap-northeast-1 | timestream-influxdb.ap-northeast-1.amazonaws.com | HTTPS |
| Europa (Fráncfort) | eu-central-1 | timestream-influxdb.eu-central-1.amazonaws.com | HTTPS |
| Europa (Irlanda) | eu-west-1 | timestream-influxdb.eu-west-1.amazonaws.com | HTTPS |
| Europa (Estocolmo) | eu-north-1 | timestream-influxdb.eu-north-1.amazonaws.com | HTTPS |
| Canadá (centro) | ca-central-1 | timestream-influxdb.ca-central-1.amazonaws.com | HTTPS |
| Europa (Londres) | eu-west-2 | timestream-influxdb.eu-west-2.amazonaws.com | HTTPS |
| Europa (París) | eu-west-3 | timestream-influxdb.eu-west-3.amazonaws.com | HTTPS |
| Asia-Pacífico (Yakarta) | ap-southeast-3 | timestream-influxdb.ap-southeast-3.amazonaws.com | HTTPS |
| Europa (Milán) | eu-south-1 | timestream-influxdb.eu-south-1.amazonaws.com | HTTPS |
| Europa (España) | eu-south-2 | timestream-influxdb.eu-south-2.amazonaws.com | HTTPS |
| Medio Oriente (EAU) | me-central-1 | timestream-influxdb.me-central-1.amazonaws.com | HTTPS |
| China (Pekín) | cn-north-1 | timestream-influxdb---cn-north-1---on.amazonwebservices.com.rproxy.govskope.ca.cn | HTTPS |
| China (Ningxia) | cn-northwest-1 | timestream-influxdb---cn-northwest-1---on.amazonwebservices.com.rproxy.govskope.ca.cn | HTTPS |
Para obtener más información sobre AWS las regiones en las que Amazon Timestream para InfluxDB está disponible actualmente y el punto de enlace de cada región, consulte los puntos de enlace y las cuotas de Amazon Timestream.
AWS Diseño de regiones
Cada AWS región está diseñada para estar aislada de las demás AWS regiones. Este diseño logra la mayor tolerancia a errores y estabilidad posibles.
Cuando consulta sus recursos, solo ve los recursos que están vinculados a la AWS región que especificó. Esto se debe a que AWS las regiones están aisladas unas de otras y no replicamos automáticamente los recursos entre AWS ellas.
AWS Zonas de disponibilidad
Cuando crea una instancia de base de datos, Amazon Timestream para InfluxDB elige una al azar en función de su configuración de subred. Una zona de disponibilidad se representa mediante un código de AWS región seguido de una letra identificadora (por ejemplo,us-east-1a).
Utilice el comando describe-availability-zones de Amazon EC2, tal y como se indica a continuación, para describir las zonas de disponibilidad dentro de la región especificada que están habilitadas para su cuenta.
aws ec2 describe-availability-zones --region region-name
Por ejemplo, para describir las de la región Este de EE. UU. (Norte de Virginia) (us-east-1) que están habilitadas para su cuenta, ejecute el siguiente comando:
aws ec2 describe-availability-zones --regionus-east-1
No puede elegir para las instancias de base de datos primaria y secundaria en una implementación de base de datos Multi-AZ. Amazon Timestream para InfluxDB las elige de forma aleatoria. Para obtener más información sobre las implementaciones multi-AZ, consulte Configuración y administración de una implementación multi-AZ.
Facturación de instancias de base de datos de Amazon Timestream para InfluxDB
Las instancias de Amazon Timestream para InfluxDB se facturan en función de los siguientes componentes:
-
Horas de instancia de base de datos (por hora): en función de la clase de instancia de base de datos. Por ejemplo, db.influx.large. Los precios se muestran por hora, pero las facturas se ajustan hasta el segundo y muestran las horas en formato decimal. El uso de Amazon Timestream para InfluxDB se factura por incrementos de 1 segundo, con un mínimo de 10 minutos. Para obtener más información, consulte Clases de instancia de base de datosClases de instancia de base de datos.
-
Almacenamiento (por GiB al mes): la capacidad de almacenamiento que ha aprovisionado para su instancia de base de datos. Para obtener más información, consulte Almacenamiento de instancias de InfluxDB.
-
Transferencia de datos (por GB): transferencia de datos de entrada y salida de la instancia de base de datos desde o hacia Internet y otras AWS regiones.
Para obtener información sobre los precios de Amazon Timestream para InfluxDB, consulte la página de precios de Amazon Timestream para InfluxDB
Configuración de Amazon Timestream para InfluxDB
Antes de usar Amazon Timestream para InfluxDB por primera vez, complete las siguientes tareas:
Si ya tienes una AWS cuenta, conoce tus requisitos de Amazon Timestream for InfluxDB y prefieres usar los valores predeterminados para IAM y Amazon VPC. Introducción a Timestream para InfluxDB
Regístrese para obtener una cuenta AWS
Si no tiene una AWS cuenta, complete los siguientes pasos para crear una.
Cómo crear una cuenta de AWS
-
Diríjase a la página de inicio de sesión
de AWS . -
Seleccione Crear una nueva cuenta y siga las instrucciones.
nota
Parte del procedimiento de registro consiste en recibir una llamada telefónica e indicar un código de verificación en el teclado del teléfono.
Al crear una AWS cuenta, se crea un usuario raíz de la AWS cuenta. El usuario raíz tiene acceso a todos los AWS servicios y recursos de la cuenta. Como práctica recomendada de seguridad, asigne acceso administrativo a un usuario administrativo y utilice únicamente el usuario raíz para realizar tareas que requieran acceso de usuario raíz.
AWS le envía un correo electrónico de confirmación una vez finalizado el proceso de registro. En cualquier momento, puede ver la actividad de su cuenta actual y administrarla accediendo a https://aws.amazon.com/
Administración de usuarios
Crear un usuario administrativo
Creación de un usuario administrativo
Después de crear una AWS cuenta, cree un usuario administrativo para no usar el usuario root para las tareas diarias.
Proteja el usuario raíz de su AWS cuenta
Inicia sesión Consola de administración de AWS como propietario de la cuenta seleccionando Usuario root e introduciendo la dirección de correo electrónico de tu AWS cuenta. En la siguiente página, escriba su contraseña. Para obtener ayuda para iniciar sesión con el usuario raíz, consulte Iniciar sesión como usuario raíz en la Guía de inicio de sesión del usuario de AWS .
Active la autenticación multifactor (MFA) para el usuario raíz. Para obtener instrucciones, consulte Habilitar un dispositivo MFA virtual para el usuario raíz de su AWS cuenta (consola) en la Guía del usuario de IAM.
Conceda acceso programático
Los usuarios necesitan acceso programático si quieren interactuar con personas AWS ajenas a. Consola de administración de AWS La forma de conceder el acceso programático depende del tipo de usuario que acceda a AWS.
Para conceder acceso programático a los usuarios, elija una de las siguientes opciones:
| ¿Qué usuario necesita acceso programático? | Para | Mediante |
|---|---|---|
| Identidad del personal (usuarios administrados en IAM Identity Center) | Use credenciales temporales para firmar solicitudes programáticas a la AWS CLI AWS SDKs, o AWS APIs. |
Siga las instrucciones de la interfaz que desea utilizar: Para ello AWS CLI, consulte Configuración de la autenticación del IAM Identity Center con la AWS CLI Guía del AWS Command Line Interface usuario. Para AWS SDKs ver las herramientas y AWS APIs, consulte Uso del IAM Identity Center para autenticar el AWS SDK y las herramientas en la Guía de referencia de herramientas AWS SDKs y herramientas. |
| IAM | Utilice credenciales temporales para firmar solicitudes programáticas a la AWS CLI SDKs, y APIs. | Siga las instrucciones de la Guía del AWS Identity and Access Management usuario sobre cómo usar credenciales temporales con los AWS recursos. |
| IAM | (No se recomienda) Utilice credenciales de larga duración para firmar las solicitudes programáticas a la AWS CLI SDKs, y APIs. |
Siga las instrucciones de la interfaz que desea utilizar: Para ello AWS CLI, consulte Autenticación con credenciales de usuario de IAM AWS CLI en la Guía del usuario.AWS Command Line Interface Para obtener AWS SDKs información sobre las herramientas y herramientas, consulte Uso de credenciales a largo plazo para autenticarse AWS SDKs y herramientas en la Guía de referencia de herramientas AWS SDKs y herramientas. Para ello AWS APIs, consulte Administrar las claves de acceso para los usuarios de IAM en la Guía del AWS Identity and Access Management usuario. |
Determinar las necesidades
El componente básico de Amazon Timestream para InfluxDB es la instancia de base de datos. En una instancia de este tipo, usted crea sus buckets. Una instancia de base de datos proporciona una dirección de red llamada punto de enlace. Sus aplicaciones usarán este punto de enlace para conectarse a su instancia de base de datos. También accederá a su InfluxUI a través de este mismo punto de conexión desde su navegador. Al crear una instancia de base de datos, se especifican detalles como el almacenamiento, la memoria, el motor de base de datos y la versión, la configuración de red y la seguridad. Controla el acceso de red a una instancia de base de datos mediante un grupo de seguridad.
Antes de crear una instancia de base de datos y un grupo de seguridad, debe conocer su instancia de base de datos y las necesidades de la red. Aquí se indican algunos aspectos importantes que se deben tener en cuenta:
-
Requisitos de recursos: ¿cuáles son los requisitos en términos de memoria y de procesador para su aplicación o su servicio? Use esta configuración como ayuda para determinar la clase de instancia de base de datos que se usará. Para conocer las especificaciones de las clases de instancia de base de datos, consulte Clases de instancia de base de datos.
-
VPC y grupo de seguridad: es muy probable que la instancia de base de datos se encuentre en una nube privada virtual (VPC). Para conectarse a su instancia de base de datos, debe configurar reglas de grupo de seguridad. Estas reglas se configuran de forma diferente según el tipo de VPC que utilice y cómo la utilice. Por ejemplo, puede utilizar: una VPC predeterminada o una VPC definida por el usuario.
En la siguiente lista se describen las reglas de cada opción de VPC:
-
VPC predeterminada: si su AWS cuenta tiene una VPC predeterminada en la región actual AWS , esa VPC está configurada para admitir instancias de base de datos. Si especifica la VPC predeterminada al crear la instancia de base de datos, asegúrese de crear un grupo de seguridad de VPC que autorice las conexiones desde la aplicación o el servicio hacia la instancia de base de datos Amazon Timestream para InfluxDB. Use la opción Grupo de seguridad en la consola de VPC o en la AWS CLI para crear grupos de seguridad de VPC. Para obtener más información, consulte Paso 3: crear un grupo de seguridad de VPC.
-
-
VPC definida por el usuario: si desea especificar una VPC definida por el usuario al crear una instancia de base de datos, tenga en cuenta lo siguiente:
-
Asegúrese de crear un grupo de seguridad de VPC que autorice las conexiones desde la aplicación o el servicio hacia la instancia de base de datos de Amazon Timestream para InfluxDB. Use la opción Grupo de seguridad en la consola de VPC o en la AWS CLI para crear grupos de seguridad de VPC. Para obtener información, consulte Paso 3: crear un grupo de seguridad de VPC.
-
La VPC debe cumplir ciertos requisitos para alojar instancias de base de datos, como tener al menos dos subredes, cada una en una zona de disponibilidad independiente. Para obtener información, consulte Amazon VPC y Amazon Timestream para InfluxDB.
-
-
Alta disponibilidad: ¿necesita compatibilidad con la conmutación por error? En Amazon Timestream para InfluxDB, una implementación multi-AZ crea una instancia de base de datos principal y otra instancia en espera secundaria alojada otra zona de disponibilidad para permitir la conmutación por error. Es recomendable usar implementaciones Multi-AZ para las cargas de trabajo de producción con el objeto de mantener una alta disponibilidad. Para fines de desarrollo y de pruebas, puede utilizar una implementación no Multi-AZ. Para obtener más información, consulte Implementaciones de instancias de base de datos Multi-AZ.
-
Políticas de IAM: ¿su AWS cuenta tiene políticas que concedan los permisos necesarios para realizar las operaciones de Amazon Timestream for InfluxDB? Si se conecta AWS mediante credenciales de IAM, su cuenta de IAM debe tener políticas de IAM que concedan los permisos necesarios para realizar las operaciones del plano de control de Amazon Timestream for InfluxDB. Para obtener más información, consulte Administración de identidades y accesos para Amazon Timestream para InfluxDB.
-
Puertos abiertos: ¿qué TCP/IP puerto escucha su base de datos? Los firewall de algunas empresas podrían bloquear las conexiones al puerto predeterminado para el motor de base de datos. El valor predeterminado de Timestream para InfluxDB es 8086.
-
AWS Región: ¿en qué AWS región desea que aparezca su base de datos? Tener la base de datos cerca de la aplicación o el servicio web puede reducir la latencia de la red. Para obtener más información, consulte Regiones de AWS y zonas de disponibilidad.
-
Subsistema de disco de base de datos: ¿cuáles son sus requisitos de almacenamiento? Amazon Timestream para InfluxDB proporciona tres configuraciones para el tipo de almacenamiento IOPS de Influx incluidas:
-
3000 IOPS incluidas de E/S de Influx (SSD)
-
12 000 IOPS incluidas de E/S de Influx (SSD)
-
16 000 IOPS incluidas de E/S de Influx (SSD)
Para obtener más información sobre el almacenamiento de Amazon Timestream para InfluxDB, consulte el almacenamiento de instancias de base de datos de Amazon Timestream para InfluxDB. Cuando tenga la información que necesita para crear el grupo de seguridad y la instancia de base de datos, vaya al siguiente paso.
-
Proporcionar acceso a la instancia de base de datos en la VPC mediante la creación de un grupo de seguridad
Los grupos de seguridad de VPC proporcionan acceso a las instancias de base de datos en una VPC. Actúan como firewall para la instancia de base de datos asociada, controlan el tráfico entrante y saliente a nivel de instancia de base de datos. Las instancias de base de datos se crean de manera predeterminada con un firewall y un grupo de seguridad predeterminado que protege la instancia de base de datos.
Para poder conectarse a la instancia de base de datos, debe agregar reglas a un grupo de seguridad que permitan conectarse. Use la información de red y de configuración para crear reglas que permitan el acceso a la instancia de base de datos.
Por ejemplo, supongamos que tiene una aplicación que accede a una base de datos en su instancia de base de datos en una VPC. En este caso, debe añadir una regla de TCP personalizada que especifique el rango de puertos y direcciones IP que la aplicación utiliza para obtener acceso a la base de datos. Si tiene una aplicación en una instancia Amazon EC2, puede usar el grupo de seguridad que configuró para la instancia Amazon EC2.
Crear un grupo de seguridad para acceder a la VPC
Para crear un grupo de seguridad de VPC, inicie sesión Consola de administración de AWS y elija VPC.
nota
Asegúrese de estar en la consola de VPC, no en la consola de Amazon Timestream para InfluxDB.
-
En la esquina superior derecha de Consola de administración de AWS, elija la AWS región en la que desee crear el grupo de seguridad de VPC y la instancia de base de datos. En la lista de recursos de Amazon VPC para esa AWS región, debería ver al menos una VPC y varias subredes. Si no lo tiene, no tiene una VPC predeterminada en esa AWS región. .
-
En el panel de navegación, elija Grupos de seguridad.
-
Elija Create Security Group (Creación de grupo de seguridad).
-
En la sección Detalles básicos de la página del grupo de seguridad, ingrese el nombre del grupo de seguridad y la descripción. En VPC, elija la VPC en la que desea crear su instancia de base de datos.
-
En Inbound rules (Reglas de entrada), elija Add rule (Agregar regla).
-
En Type (Tipo), elija Custom TCP (TCP personalizada).
-
En Origen, elija un nombre de grupo de seguridad o escriba el rango de direcciones IP (valor CIDR) desde donde accede a la instancia de base de datos. Si elige My IP (Mi IP), esto permite el acceso a la instancia de base de datos desde la dirección IP detectada en su navegador.
En Source (Origen), elija un nombre de grupo de seguridad o escriba el rango de direcciones IP (valor CIDR) desde donde accede a la instancia de base de datos. Si elige My IP (Mi IP), esto permite el acceso a la instancia de base de datos desde la dirección IP detectada en su navegador.
-
-
(Opcional) En Outbound rules (Reglas de salida), agregue reglas para el tráfico saliente. De forma predeterminada, se permite todo el tráfico de salida.
-
Elija Create Security Group (Crear grupo de seguridad).
Puede usar el grupo de seguridad de VPC como grupo de seguridad de la instancia de base de datos cuando la cree.
nota
Si usa una VPC predeterminada, se crea un grupo de subredes predeterminado que abarca todas las subredes de la VPC. Al crear una instancia de base de datos, puede seleccionar la VPC eiifccntf predeterminada y seleccionar predeterminado para el grupo de subred de base de datos.
Una vez que haya completado los requisitos de configuración, puede crear una instancia de base de datos con sus requisitos y grupo de seguridad. Para ello, siga las instrucciones que se indican en Creación de una instancia de base de datos.
Prácticas recomendadas de seguridad de Timestream para InfluxDB
Optimizar las escrituras en InfluxDB
Como cualquier otra base de datos de serie temporal, InfluxDB está diseñada para poder ingerir y procesar datos en tiempo real. Para que el sistema funcione al máximo, recomendamos realizar las siguientes optimizaciones al escribir datos en InfluxDB:
Realizar escrituras por lotes: al escribir datos en InfluxDB, hágalo en lotes para minimizar la sobrecarga de red relacionada con cada solicitud de escritura. El tamaño de lote óptimo es de 5000 líneas de protocolo de línea por solicitud de escritura. Para escribir varias líneas en una solicitud, cada línea del protocolo de línea debe estar delimitada por una línea nueva (\n).
Ordenar etiquetas por clave: antes de escribir puntos de datos en InfluxDB, ordene las etiquetas por clave en orden lexicográfico.
measurement,tagC=therefore,tagE=am,tagA=i,tagD=i,tagB=think fieldKey=fieldValue 1562020262 # Optimized line protocol example with tags sorted by key measurement,tagA=i,tagB=think,tagC=therefore,tagD=i,tagE=am fieldKey=fieldValue 1562020262Utilizar la precisión de tiempo más aproximada posible: InfluxDB escribe los datos con una precisión de nanosegundos; sin embargo, si los datos no se recopilan en nanosegundos, no es necesario escribir con esa precisión. Para obtener un mejor rendimiento, utilice la mayor precisión posible para las marcas de tiempo. Puede especificar la precisión de escritura en las siguientes situaciones:
Cuando utilices el SDK, puedes especificar el WritePrecision atributo de tiempo de tu punto. Para obtener más información sobre las bibliotecas cliente de InfluxDB, consulte la documentación de InfluxDB
. Al utilizar Telegraf, se ajusta la precisión del tiempo en la configuración del agente de Telegraf. La precisión se especifica como un intervalo con un número entero + unidad (por ejemplo, 0 s, 10 ms, 2 us, 4 s). Las unidades de tiempo válidas son “ns”, “us”, “ms”, and “s”.
[agent] interval ="10s" metric_batch_size="5000" precision = "0s"
Utilizar la compresión gzip: utilice la compresión gzip para acelerar las escrituras en InfluxDB y reducir el ancho de banda de la red. Los puntos de referencia han demostrado una mejora de la velocidad de hasta 5 veces cuando se comprimen los datos.
Cuando utilice Telegraf, en la configuración del plugin de salida Influxdb_v2 de su telegraf.conf, establezca la opción content_encoding en gzip:
[[outputs.influxdb_v2]] urls = ["http://localhost:8086"] # ... content_encoding = "gzip"Al utilizar bibliotecas cliente, cada biblioteca cliente de InfluxDB
ofrece opciones para comprimir las solicitudes de escritura o aplica la compresión de forma predeterminada. El método para habilitar la compresión es diferente para cada biblioteca. Para obtener instrucciones específicas, consulte la documentación de InfluxDB . Cuando utilice el punto de conexión
/api/v2/writede la API de InfluxDB para escribir datos, comprima los datos con gzip y establezca el encabezado Content-Encoding en gzip.
Diseño en pos del rendimiento
Diseñe su esquema para que las consultas sean más sencillas y generen mayor rendimiento. Las siguientes pautas garantizarán que su esquema sea fácil de consultar y maximice el rendimiento de las consultas:
Diseñe en pos de la consulta: elija medidas
, claves de etiquetas y claves de campo que sean fáciles de consultar. Para lograr este objetivo, siga estos principios: Utilice medidas que tengan un nombre sencillo y que describan el esquema con precisión.
Evite usar el mismo nombre para una clave de etiqueta
y una clave de campo dentro del mismo esquema. Evite utilizar palabras clave de Flux
y caracteres especiales reservados en las claves de etiquetas y campos. Las etiquetas almacenan metadatos que describen los campos y son comunes en muchos puntos de datos.
Los campos almacenan datos únicos o muy variables, normalmente puntos de datos numéricos.
Las medidas y las claves no deben contener datos, sino que deben usarse para agregar o describir datos. Los datos se almacenarán en valores de etiquetas y campos.
Mantenga la cardinalidad de serie temporal bajo control La alta cardinalidad de las series es una de las principales causas de la disminución del rendimiento de escritura y lectura en InfluxDB. En el contexto de InfluxDB, la alta cardinalidad se refiere a la presencia de una gran cantidad de valores de etiquetas únicos. Los valores de las etiquetas están indexados en InfluxDB, lo que significa que una cantidad muy alta de valores únicos generará un índice mayor. Esto puede ralentizar la ingesta de datos y el rendimiento de las consultas.
Para comprender y resolver mejor los posibles problemas relacionados con la alta cardinalidad, puede seguir estos pasos:
Comprenda las causas de la alta cardinalidad
Mida la cardinalidad de los buckets
Tome medidas para resolver la alta cardinalidad
Causas de la alta cardinalidad de serie InfluxDB indexa los datos en función de las mediciones y las etiquetas para acelerar la lectura de los datos. Cada conjunto de elementos de datos indexados forma una clave de serie
. Las etiquetas que contienen información muy variable, como cadenas únicas IDs, códigos hash y cadenas aleatorias, conducen a un gran número de series , lo que también se conoce como cardinalidad alta de series . La alta cardinalidad de serie es el principal impulsor del uso elevado de memoria en InfluxDB. Medición de la cardinalidad de serie Si experimenta una ralentización del rendimiento u observa un uso de memoria cada vez mayor en su instancia de Timestream para InfluxDB, le recomendamos que mida la cardinalidad de serie de sus segmentos.
InfluxDB proporciona funciones que le permiten medir la cardinalidad de serie tanto en Flux como en InfluxQL.
En Flux, use la función
influxdb.cardinality().En FluxQL, use el comando
SHOW SERIES CARDINALITY.
En ambos casos, el motor devolverá la cantidad de claves de serie únicas de sus datos. Tenga en cuenta que no se recomienda tener más de 10 millones de claves de serie en ninguna de sus instancias de Timestream para InfluxDB.
Causas de la alta cardinalidad de serie Si descubre que alguno de los buckets tiene una cardinalidad alta, puede tomar algunas medidas correctivas para solucionarlo:
Revise las etiquetas: asegúrese de que las cargas de trabajo no generen casos en los que las etiquetas tengan valores únicos para la mayoría de las entradas. Esto puede suceder en los casos en que el número de valores de etiquetas únicos siempre aumente con el tiempo, o si los mensajes de tipo registro se escriben en la base de datos, donde cada mensaje tendría una combinación única de marcas de tiempo, etiquetas, etc. Puede usar el siguiente código de Flux para determinar qué etiquetas son las que más contribuyen a los problemas de alta cardinalidad:
// Count unique values for each tag in a bucketimport "influxdata/influxdb/schema" cardinalityByTag = (bucket) => schema.tagKeys(bucket: bucket) |> map( fn: (r) => ({ tag: r._value, _value: if contains(set: ["_stop", "_start"], value: r._value) then 0 else (schema.tagValues(bucket: bucket, tag: r._value) |> count() |> findRecord(fn: (key) => true, idx: 0))._value, }), ) |> group(columns: ["tag"]) |> sum() cardinalityByTag(bucket: "amzn-s3-demo-bucket")Si tiene una cardinalidad muy alta, es posible que se agote el tiempo de espera de la consulta anterior. Si se agota el tiempo de espera, ejecute las siguientes consultas una por vez.
Genere una lista de etiquetas:
// Generate a list of tagsimport "influxdata/influxdb/schema" schema.tagKeys(bucket: "amzn-s3-demo-bucket")Cuente los valores de etiqueta únicos para cada etiqueta:
// Run the following for each tag to count the number of unique tag valuesimport "influxdata/influxdb/schema" tag = "example-tag-key" schema.tagValues(bucket: "amzn-s3-demo-bucket1", tag: tag) |> count()Le recomendamos que las ejecute en diferentes momentos para identificar qué etiqueta está creciendo más rápido.
Mejore su esquema: siga las recomendaciones de modelado que se describen en nuestras Prácticas recomendadas de seguridad de Timestream para InfluxDB.
Elimine o agregue datos antiguos para reducir la cardinalidad: considere si sus casos de uso necesitan o no todos los datos que están causando los problemas de alta cardinalidad. Si estos datos ya no son necesarios o no se accede a ellos con frecuencia, puede agregarlos, eliminarlos o exportarlos a otro motor, como Timestream para LiveAnalytics, para almacenarlos y analizarlos a largo plazo.
