Para obtener capacidades similares a las de Amazon Timestream, considere Amazon Timestream LiveAnalytics para InfluxDB. Ofrece una ingesta de datos simplificada y tiempos de respuesta a las consultas en milisegundos de un solo dígito para realizar análisis en tiempo real. Obtenga más información aquí.
Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Uso de clústeres de réplica de lectura Multi-AZ para Amazon Timestream para InfluxDB
La implementación de un clúster de réplica de lectura es un modo de implementación asíncrono de Amazon Timestream para InfluxDB que le permite configurar réplicas de lectura asociadas a una instancia de base de datos principal. Un clúster de réplica de lectura tiene una instancia de base de datos del escritor y una instancia de base de datos del lector en zonas de disponibilidad diferentes en la misma Región de AWS. Los clústeres de réplica de lectura proporcionan alta disponibilidad y mayor capacidad para cargas de trabajo de lectura en comparación con las implementaciones de instancias de base de datos Multi-AZ.
Disponibilidad de clases de instancia para los clústeres de réplica de lectura
Las implementaciones de clústeres de réplica de lectura son compatibles con los mismos tipos de instancias que las instancias normales de Timestream para InfluxDB.
| Clase de instancia | vCPU | Memoria (GiB) | Tipo de almacenamiento | Ancho de banda de la red (Gbps) |
|---|---|---|---|---|
| db.influx.medium | 1 | 8 | IOPS de Influx incluidas | 10 |
| db.influx.large | 2 | 16 | IOPS de Influx incluidas | 10 |
| db.influx.xlarge | 4 | 32 | IOPS de Influx incluidas | 10 |
| db.influx.2xlarge | 8 | 64 | IOPS de Influx incluidas | 10 |
| db.influx.4xlarge | 16 | 128 | IOPS de Influx incluidas | 10 |
| db.influx.8xlarge | 32 | 256 | IOPS de Influx incluidas | 12 |
| db.influx.12xlarge | 48 | 384 | IOPS de Influx incluidas | 20 |
| db.influx.16xlarge | 64 | 512 | IOPS de Influx incluidas | 25 |
| db.influx.24xlarge | 96 | 768 | IOPS de Influx incluidas | 40 |
Arquitectura del clúster de réplica de lectura
Con un clúster de réplicas de lectura, Amazon Timestream for InfluxDB replica automáticamente todas las escrituras realizadas en la instancia de base de datos del escritor en todas las instancias InfluxData de bases de datos del lector mediante el complemento de réplica de lectura con licencia. Esta replicación es asíncrona y todas las escrituras se reconocen en cuanto el nodo de escritura las confirma. Las escrituras no requieren el reconocimiento de todos los nodos lectores para que se considere una escritura correcta. Una vez que la instancia de base de datos del escritor confirma los datos, estos se replican en la instancia de réplica de lectura casi de forma instantánea. En caso de que se produzca un error irrecuperable en el lector, se perderán todos los datos que no se hayan replicado en al menos uno de los lectores.
Una instancia de réplica de lectura es una copia de solo lectura de una instancia de base de datos de escritor. Puede reducir la carga de la instancia de base de datos de escritor enrutando algunas o todas las consultas de sus aplicaciones a la réplica de lectura. De este modo, puede ajustar la escala horizontalmente y de manera elástica por encima de las restricciones de capacidad de una instancia de base de datos para las cargas de trabajo de las bases de datos con operaciones intensivas de lectura.
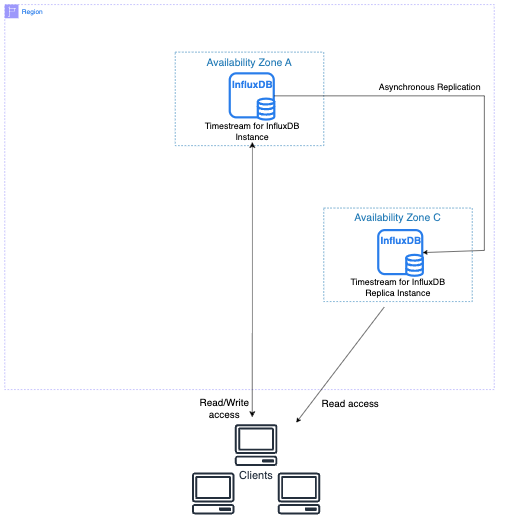
En el siguiente diagrama se muestra una instancia de base de datos principal que se replica en una réplica de lectura en una zona de disponibilidad diferente. Los clientes tienen read/write acceso a la instancia de base de datos principal y acceso de solo lectura a la réplica.
Grupos de parámetros para clústeres de réplica de lectura
En un clúster de réplica de lectura, un grupo de parámetros de base de datos funciona como un contenedor para los valores de configuración del motor que se aplican a cada instancia de base de datos en el clúster de réplica de lectura. Se establece un grupo de parámetros de base de datos predeterminado en función del motor de base de datos y de la versión del motor. La configuración del grupo de parámetros de base de datos se utiliza para todas las instancias de base de datos del clúster.
Al transferir un grupo de parámetros de base de datos específico mediante una réplica UpdateDbClusterde lectura de bases de datos Multi-AZ CreateDbClustero Multi-AZ, asegúrese de que tenga una duración mínima de 1 hora. storage-wal-max-write-delay Si no se especifica ningún grupo de parámetros de base de datos, el valor predeterminado de storage-wal-max-write-delay será de 1 hora.
Retraso de réplica en los clústeres de réplica de lectura
Aunque los clústeres de réplica de lectura de Timestream para InfluxDB permiten un alto rendimiento de escritura, puede producirse un retraso de réplica debido a la naturaleza de la replicación asíncrona basada en motor. Este retraso puede provocar una posible pérdida de datos en el caso de una conmutación por error, por lo que es fundamental supervisarlo.
Puede realizar un seguimiento del retraso de la réplica CloudWatch seleccionando Todas las métricas en el panel de Consola de administración de AWS navegación. Seleccione Timestream/InfluxDB y, a continuación, Por. DbCluster Seleccione su y, a continuación, su. DbClusterNameDbReaderInstanceName Aquí, además del conjunto normal de métricas rastreadas para todas las instancias de Timestream for InfluxDB (consulte la lista a continuación), también verá ReplicaLag las métricas expresadas en milisegundos.
CPUUtilization
MemoryUtilization
DiskUtilization
ReplicaLag (solo para instancias de base de datos en modo de instancia de réplica)
Causas comunes del retraso de réplica
En general, el retraso de réplica se produce cuando las cargas de trabajo de escritura y lectura son demasiado altas para que las instancias de base de datos del lector apliquen las transacciones de manera eficiente. Varias cargas de trabajo pueden provocar un retraso de réplica temporal o continuo. Ejemplos de causas comunes:
Alta simultaneidad de escritura o actualización por lotes pesados en la instancia de base de datos del escritor, lo que hace que el proceso de aplicación en las instancias de base de datos del lector se demore.
Carga de trabajo de lectura pesada que utiliza recursos en una o más instancias de base de datos del lector. La ejecución de consultas lentas o grandes puede afectar al proceso de aplicación y provocar un retraso de réplica.
Las transacciones que modifican grandes cantidades de datos o instrucciones DDL a veces pueden provocar un aumento temporal del retraso de réplica porque la base de datos debe conservar el orden de confirmación.
Para ver un tutorial que muestra cómo crear una CloudWatch alarma cuando el retraso de la réplica supera un período de tiempo establecido, consulteTutorial: Cree una CloudWatch alarma de Amazon para el retraso de réplica de un clúster Multi-AZ para Amazon Timestream para InfluxDB.
Mitigación del retraso de réplica
En el caso de los clústeres de réplica de lectura de Timestream para InfluxDB, puede reducir la carga de la instancia de base de datos del escritor para mitigar el retraso de réplica.
Disponibilidad y durabilidad
Los clústeres de réplica de lectura se pueden configurar para conmutar automáticamente por error a una de las instancias de lector en caso de que el escritor no priorice la disponibilidad de escritura o para evitar la conmutación por error y minimizar la pérdida de los datos más recientes. Los datos más recientes se refieren a la brecha de replicación de los datos que aún no se han replicado en al menos uno de los nodos lectores (consulte Retraso de réplica en los clústeres de réplica de lectura). El comportamiento predeterminado y recomendado para los clústeres de réplica de lectura es realizar automáticamente la conmutación por error en caso de que se produzca un error en el escritor. Sin embargo, si la pérdida de los datos más recientes es más importante para sus casos de uso que la disponibilidad de escritura, puede anular la opción predeterminada actualizando el clúster.
Los clústeres de réplica de lectura garantizan que todas las instancias de base de datos del clúster estén distribuidas en al menos dos zonas de disponibilidad para garantizar una mayor disponibilidad de escritura y durabilidad de los datos en caso de que se produzca una interrupción en la zona de disponibilidad.
Temas
Descripción general de los clústeres de réplica de lectura de Amazon Timestream para InfluxDB
Creación de un clúster de réplica de lectura de Timestream para InfluxDB
Conexión un clúster de base de datos de réplica de lectura de Timestream para InfluxDB
Modificación de un clúster de réplica de lectura de Amazon Timestream para InfluxDB
Reiniciar un clúster de réplicas de lectura en Amazon Timestream para InfluxDB
Creación de CloudWatch alarmas para monitorear Amazon Timestream para InfluxDB
