Aviso de fin del soporte: el 30 de junio de 2027 AWS finalizará el soporte para AMS Advanced. Después del 30 de junio de 2027, ya no podrá acceder a la consola de AMS Advanced ni a los recursos de AMS Advanced. Para obtener más información, consulte el fin del soporte de AMS Advanced.
Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Cómo funciona la supervisión
Consulte los siguientes gráficos sobre la arquitectura de supervisión en AWS Managed Services (AMS).
El siguiente diagrama proporciona una descripción general de alto nivel del flujo de trabajo de monitoreo de zonas de aterrizaje con múltiples cuentas de AMS y zonas de aterrizaje con una sola cuenta de AMS.
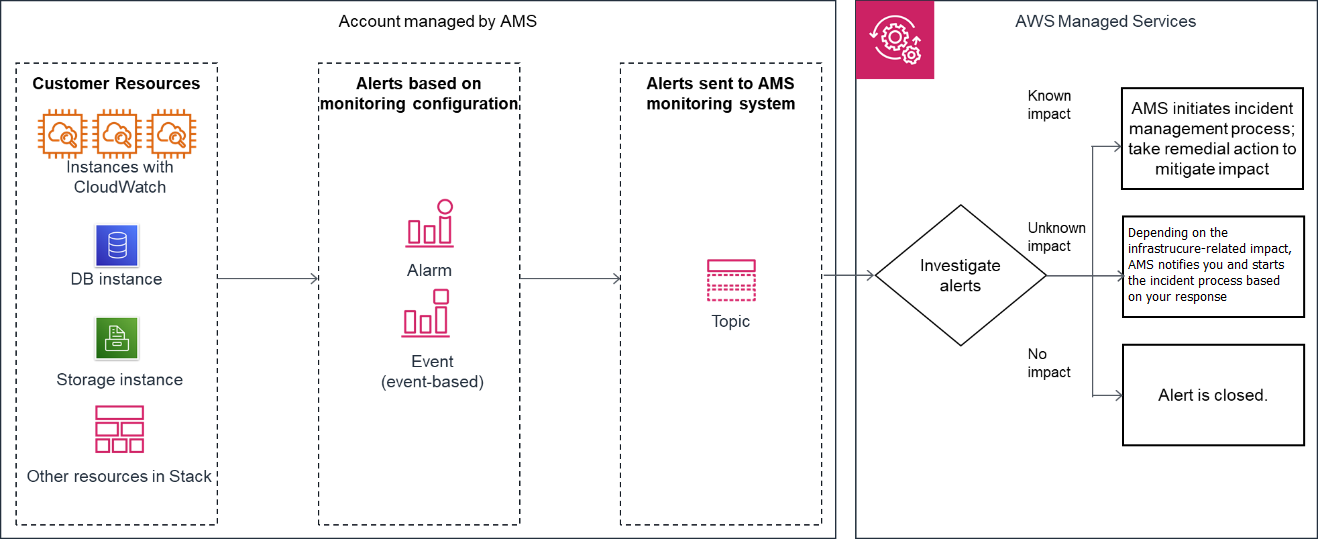
Generación: en el momento de la incorporación de la cuenta, AMS configura la supervisión de referencia (una combinación de alarmas CloudWatch (CW) y reglas de eventos de CW) para todos los recursos creados en una cuenta gestionada. La configuración de supervisión básica genera una alerta cuando se activa una alarma de CW o se genera un evento de CW.
Agregación:
Multi-Account Zona de destino: las alertas las generan sus recursos en las cuentas de la aplicación y de la unidad organizativa principal y las envían al sistema de monitoreo AMS dirigiéndolas a través de la cuenta de seguridad.
Single-Account Zona de aterrizaje: todas las alertas generadas por tus recursos se envían al sistema de monitoreo de AMS, dirigiéndolas a un tema de SNS de la cuenta.
También puede configurar la forma en que AMS agrupa las alertas de EC2. AMS agrupa todas las alertas relacionadas con la misma instancia de EC2 en un solo incidente o crea un incidente por alerta, según sus preferencias. Puede cambiar esta configuración en cualquier momento trabajando con su administrador de prestación de servicios en la nube o con un arquitecto de nube. Esto funciona de la misma manera tanto si utiliza Multi-Account Landing Zone como Single-Account Landing Zone.
Procesamiento: AMS analiza las alertas y las procesa en función de su potencial de impacto. Las alertas se procesan como se describe a continuación.
Alertas con un impacto conocido en los clientes: conducen a la creación de un nuevo informe de incidentes y AMS sigue el proceso de gestión de incidentes; para obtener información sobre la gestión de incidentes, consulteRespuesta a incidentes de AMS.
Ejemplo de alerta: una instancia de Amazon EC2 no supera una comprobación de estado del sistema, AMS intenta recuperar la instancia deteniéndola y reiniciándola.
Alertas con un impacto incierto en los clientes: en el caso de este tipo de alertas, AMS envía un informe del incidente y, en muchos casos, le pide que verifique el impacto antes de que AMS tome medidas. Sin embargo, si se aprueban las comprobaciones relacionadas con la infraestructura, AMS no le enviará ningún informe del incidente.
Por ejemplo: una alerta de un uso superior al 85% de la CPU durante más de 10 minutos en una instancia de Amazon EC2 no se puede clasificar inmediatamente como incidente, ya que este comportamiento podría esperarse en función del uso. En este ejemplo, AMS Automation realiza comprobaciones relacionadas con la infraestructura del recurso. Si se aprueban esas comprobaciones, AMS no envía ninguna notificación de alerta, incluso si el uso de la CPU supera el 99%. Si Automation detecta que las comprobaciones relacionadas con la infraestructura están fallando en el recurso, AMS envía una notificación de alerta y comprueba si es necesaria una mitigación. Las notificaciones de alerta se analizan en detalle en esta sección. AMS ofrece opciones de mitigación en la notificación. Cuando respondes a la notificación confirmando que la alerta es un incidente, AMS crea un nuevo informe de incidente y comienza el proceso de gestión de incidentes de AMS. Las notificaciones de servicio que reciben una respuesta que indica que «no afecta al cliente» o que no reciben respuesta alguna durante tres días se marcan como resueltas y la alerta correspondiente se marca como resuelta.
Alertas que no afectan a los clientes: si, tras una evaluación, AMS determina que la alerta no afecta a los clientes, se cierra.
Por ejemplo, AWS Health notifica que una instancia EC2 necesita ser reemplazada, pero esa instancia ha sido cancelada desde entonces.
Notificaciones agrupadas de instancias EC2
Puede configurar la supervisión de AMS para agrupar las alertas de la misma instancia de EC2 en un solo incidente. Su administrador de prestación de servicios en la nube o su arquitecto de nube pueden configurarlo por usted. Hay cuatro parámetros que puede configurar para cada AMS-managed cuenta.
Alcance: elija entre toda la cuenta o basado en etiquetas.
Para especificar una configuración que se aplique a todas las instancias de EC2 de esa cuenta, elija scope = account-wide.
Para especificar una configuración que se aplique únicamente a las instancias EC2 de esa cuenta con una etiqueta específica, elija scope = tag-based.
Regla de agrupación: elija una clásica o una instancia.
Para configurar la agrupación a nivel de instancia para todos los recursos de tu cuenta, elige ámbito = toda la cuenta y regla de agrupación = instancia.
Para configurar recursos específicos de tu cuenta para que usen la agrupación a nivel de instancia, etiqueta esas instancias y, a continuación, elige ámbito = basado en etiquetas y regla de agrupación = nivel de instancia.
Para no usar la agrupación de instancias para las alertas de tu cuenta, elige la regla de agrupación = clásica.
Opción de participación: elige entre ninguna, solo informar o predeterminada.
Para que AMS no cree incidentes ni ejecute automatizaciones para las alarmas desde esos recursos mientras la configuración esté activa, no elija ninguna.
Para que AMS no cree incidentes ni ejecute automatizaciones para las alarmas a partir de esos recursos mientras la configuración esté activa, ni ejecute la reparación automática de los documentos de Systems Manager, sino que incluya registros de estos eventos en los informes, elija solo informar. Esto puede resultar útil si desea reducir el volumen de casos de asistencia ante incidentes con los que interactúa y si algunos incidentes procedentes de algunos recursos no requieren atención inmediata, por ejemplo, los que se producen en una cuenta ajena a la producción.
Para que AMS procese sus alertas, ejecute automatizaciones y cree casos de incidentes cuando sea necesario, elija la opción predeterminada.
Resolver después: elija entre 24 horas, 48 horas o 72 horas. Por último, configure cuándo se cierran automáticamente los casos de incidentes. Si el tiempo transcurrido desde la correspondencia del último caso alcanza el valor de resolución posterior configurado, el incidente se cierra.
Notificación de alerta
Como parte del procesamiento de alertas, en función del análisis de impacto, AWS Managed Services (AMS) crea un incidente e inicia el proceso de administración de incidentes para su corrección, cuando se puede determinar el impacto. Si no se puede determinar el impacto, AMS envía una notificación de alerta a la dirección de correo electrónico asociada a su cuenta mediante una notificación de servicio. En algunos casos, esta notificación de alerta no se envía. Por ejemplo, si las comprobaciones relacionadas con la infraestructura superan una alerta de uso elevado de la CPU, no se te enviará ninguna notificación de alerta. Para obtener más información, consulte el diagrama sobre la arquitectura de supervisión de AMS para ver el proceso de gestión de alertas en. Cómo funciona la supervisión
Tag-based notificación de alerta
Usa etiquetas para enviar notificaciones de alerta para tus recursos a diferentes direcciones de correo electrónico. Se recomienda utilizar notificaciones de alerta basadas en etiquetas, ya que las notificaciones que se envían a una sola dirección de correo electrónico pueden causar confusión cuando varios equipos de desarrolladores utilizan la misma cuenta. Tag-based las notificaciones de alerta no se ven afectadas por la Notificaciones agrupadas de instancias EC2 configuración que elijas.
Con las notificaciones de alerta basadas en etiquetas, puedes:
Enviar alertas a una dirección de correo electrónico específica: etiquete los recursos que tengan alertas que deban enviarse a una dirección de correo electrónico específica con la
key = OwnerTeamEmail,value =.EMAIL_ADDRESSEnviar alertas a varias direcciones de correo electrónico: para usar varias direcciones de correo electrónico, especifique una lista de valores separados por comas. Por ejemplo,
key =,OwnerTeamEmailvalue =. El número total de caracteres del campo de valor no puede superar los 260.EMAIL_ADDRESS_1,EMAIL_ADDRESS_2,EMAIL_ADDRESS_3, ...Use una clave de etiqueta personalizada: para usar una clave de etiqueta personalizada, proporcione el nombre de la clave de etiqueta personalizada a su CSDM en un correo electrónico en el que dé su consentimiento explícito para activar las notificaciones automáticas para la comunicación basada en etiquetas. Se recomienda utilizar la misma estrategia de etiquetado para las etiquetas de contacto en todas las instancias y recursos.
nota
El valor clave OwnerTeamEmail no tiene por qué estar en camel Case. Sin embargo, las etiquetas distinguen entre mayúsculas y minúsculas y se recomienda utilizar el formato recomendado.
La dirección de correo electrónico debe especificarse en su totalidad, con el signo «at» (@) para separar la parte local del dominio. Ejemplos de direcciones de correo electrónico no válidas: Team.AppATabc.xyz ojohn.doe. Para obtener información general sobre tu estrategia de etiquetado, consulta los recursos de etiquetado AWS. No añadas información de identificación personal (PII) en tus etiquetas. Usa listas de distribución o alias siempre que sea posible.
Tag-based la notificación de alertas es compatible con los recursos de los siguientes servicios de Amazon: EC2, Elastic Block Store (EBS), Elastic Load Balancing (ELB), Application Load Balancer (ALB), Network Load Balancer, Relational Database Service (RDS), Elastic File System (EFS), FSx, y VPN. OpenSearch Site-to-Site
