Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Multi-AZ-Beobachtbarkeit
Um eine Availability Zone während eines Ereignisses evakuieren zu können, das auf eine einzelne Availability Zone beschränkt ist, müssen Sie zunächst feststellen können, dass der Fehler tatsächlich auf eine einzelne Availability Zone beschränkt ist. Dies erfordert einen genauen Überblick darüber, wie sich das System in jeder Availability Zone verhält. Viele AWS Dienste bieten out-of-the-box Kennzahlen, die Ihnen betriebliche Einblicke in Ihre Ressourcen geben. Amazon EC2 bietet beispielsweise zahlreiche Metriken wie CPU Auslastung, Lese- und Schreibvorgänge auf der Festplatte sowie ein- und ausgehender Netzwerkverkehr.
Wenn Sie Workloads erstellen, die diese Services nutzen, benötigen Sie jedoch mehr Transparenz als nur diese Standardmetriken. Sie möchten Einblick in das Kundenerlebnis haben, das Ihr Workload bietet. Darüber hinaus müssen Ihre Kennzahlen auf die Availability Zones abgestimmt sein, in denen sie erstellt werden. Dies ist der Einblick, den Sie benötigen, um unterschiedlich beobachtbare Graufehler zu erkennen. Dieses Maß an Transparenz erfordert Instrumentierung.
Die Instrumentierung erfordert das Schreiben von explizitem Code. Dieser Code sollte beispielsweise aufzeichnen, wie lange Aufgaben dauern, zählen, wie viele Elemente erfolgreich waren oder nicht, Metadaten zu den Anfragen sammeln und so weiter. Außerdem müssen Sie im Voraus Schwellenwerte definieren, um zu definieren, was als normal angesehen wird und was nicht. Sie sollten Ziele und verschiedene Schweregrade für Latenz, Verfügbarkeit und Fehleranzahl in Ihrem Workload skizzieren. Der Artikel Instrumenting Distributed Systems for Operational Visibility
Metriken sollten sowohl serverseitig als auch clientseitig generiert werden. Eine bewährte Methode zur Generierung von kundenseitigen Kennzahlen und zum besseren Verständnis des Kundenerlebnisses ist die Verwendung von Canaries, einer Software, die Ihre Arbeitslast regelmäßig überprüft und Kennzahlen aufzeichnet.
Neben der Erstellung dieser Kennzahlen müssen Sie auch deren Kontext verstehen. Eine Möglichkeit, dies zu tun, ist die Verwendung von Dimensionen. Dimensionen geben einer Metrik eine eindeutige Identität und helfen zu erklären, was Ihnen die Metriken sagen. Für Metriken, die zur Identifizierung von Fehlern in Ihrem Workload verwendet werden (z. B. Latenz, Verfügbarkeit oder Fehleranzahl), müssen Sie Dimensionen verwenden, die Ihren Grenzen zur Fehlerisolierung entsprechen.
Wenn Sie beispielsweise einen Webservice in einer Region über mehrere Availability Zones hinweg mit einem M odel-view-controllerRegion,, Availability
Zone IDControllerAction, und InstanceId als Dimensionen für Ihre Dimensionssätze verwenden (wenn Sie Microservices verwenden, könnten Sie den Dienstnamen und die HTTP Methode anstelle der Controller- und Aktionsnamen verwenden). Dies liegt daran, dass Sie davon ausgehen, dass verschiedene Arten von Fehlern durch diese Grenzen isoliert werden. Sie würden nicht erwarten, dass ein Fehler im Code Ihres Webdienstes, der die Möglichkeit beeinträchtigt, Produkte aufzulisten, sich auch auf die Startseite auswirkt. Ebenso würden Sie nicht erwarten, dass ein voller EBS Volume auf einer einzelnen EC2 Instanz andere EC2 Instanzen davon abhält, Ihre Webinhalte bereitzustellen. Mithilfe der Dimension Availability Zone ID können Sie die Auswirkungen auf die Availability Zone überall einheitlich identifizieren. AWS-Konten Sie können die Availability Zone ID in Ihren Workloads auf verschiedene Arten finden. Einige Beispiele finden Sie unter. Anhang A — Abrufen der Availability Zone-ID
Dieses Dokument verwendet in den Beispielen hauptsächlich Amazon EC2 als Rechenressource, InstanceId könnte aber durch eine Container-ID für die Rechenressourcen Amazon Elastic Container Service
Ihre Kanaren können auchController,Action, und Region als Dimensionen in ihren Metriken verwendenAZ-ID, wenn Sie zonale Endpunkte für Ihren Workload haben. Richten Sie in diesem Fall Ihre Canaries so aus, dass sie in der Availability Zone laufen, die sie gerade testen. Dadurch wird sichergestellt, dass, wenn sich ein isoliertes Availability Zone-Ereignis auf die Availability Zone auswirkt, in der Ihr Canary läuft, keine Metriken aufgezeichnet werden, die eine andere Availability Zone, die getestet wird, als ungesund erscheinen lassen. Ihr Canary kann beispielsweise jeden zonalen Endpunkt anhand seiner zonalen Namen auf einen Dienst hinter einem Network Load Balancer (NLB) oder Application Load Balancer (ALB) testen. DNS
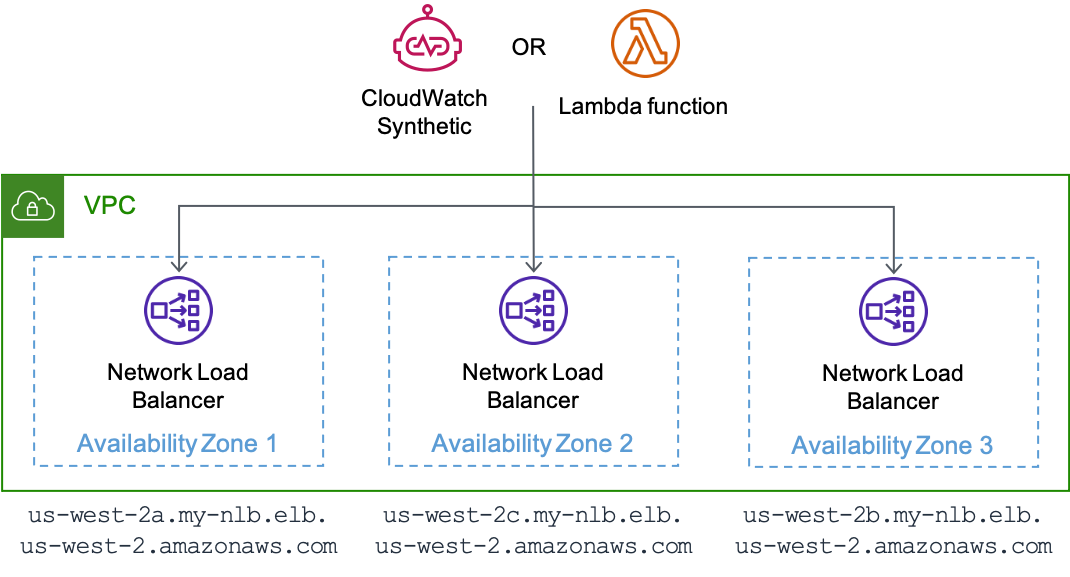
Ein Canary, der auf CloudWatch Synthetics läuft, oder eine AWS Lambda Funktion, die jeden zonalen Endpunkt eines testet NLB
Durch die Erstellung von Metriken mit diesen Dimensionen können Sie CloudWatch Amazon-Alarme einrichten, die Sie benachrichtigen, wenn innerhalb dieser Grenzen Änderungen der Verfügbarkeit oder Latenz auftreten. Sie können diese Daten auch schnell mithilfe von Dashboards analysieren. Um sowohl Metriken als auch Protokolle effizient zu nutzen, CloudWatch bietet Amazon das eingebettete Metrikformat (EMF), mit dem Sie benutzerdefinierte Metriken in Protokolldaten einbetten können. CloudWatchextrahiert automatisch die benutzerdefinierten Metriken, sodass Sie sie visualisieren und als Alarm auslösen können. AWS bietet mehrere Client-Bibliotheken für verschiedene Programmiersprachen, die den Einstieg erleichternEMF. Sie können mit AmazonEC2, Amazon ECS EKS AWS LambdaAZ-IDInstanceId, oder Controller sowie nach jedem anderen Feld im Protokoll wie SuccessLatency oder anzeigen. HttpResponseCode
{ "_aws": { "Timestamp": 1634319245221, "CloudWatchMetrics": [ { "Namespace": "workloadname/frontend", "Metrics": [ { "Name": "2xx", "Unit": "Count" }, { "Name": "3xx", "Unit": "Count" }, { "Name": "4xx", "Unit": "Count" }, { "Name": "5xx", "Unit": "Count" }, { "Name": "SuccessLatency", "Unit": "Milliseconds" } ], "Dimensions": [ [ "Controller", "Action", "Region", "AZ-ID", "InstanceId"], [ "Controller", "Action", "Region", "AZ-ID"], [ "Controller", "Action", "Region"] ] } ], "LogGroupName": "/loggroupname" }, "CacheRefresh": false, "Host": "use1-az2-name.example.com", "SourceIp": "34.230.82.196", "TraceId": "|e3628548-42e164ee4d1379bf.", "Path": "/home", "OneBox": false, "Controller": "Home", "Action": "Index", "Region": "us-east-1", "AZ-ID": "use1-az2", "InstanceId": "i-01ab0b7241214d494", "LogGroupName": "/loggroupname", "HttpResponseCode": 200, "2xx": 1, "3xx": 0, "4xx": 0, "5xx": 0, "SuccessLatency": 20 }
Dieses Protokoll hat drei Gruppen von Dimensionen. Sie werden in der Reihenfolge ihrer Granularität von Instanz zu Availability Zone zu Region weitergeleitet (Controllerund Action sind in diesem Beispiel immer enthalten). Sie unterstützen die Erstellung von Alarmen für Ihren gesamten Workload, die darauf hinweisen, wenn eine bestimmte Controller-Aktion in einer einzelnen Instanz, in einer einzelnen Availability Zone oder innerhalb eines Ganzen AWS-Region Auswirkungen hat. Diese Dimensionen werden für die Anzahl der HTTP Antwortmetriken 2xx, 3xx, 4xx und 5xx sowie für die Latenz erfolgreicher Anforderungsmetriken verwendet (wenn die Anfrage fehlschlägt, wird auch eine Metrik für die Latenz fehlgeschlagener Anfragen aufgezeichnet). Das Protokoll zeichnet auch andere Informationen auf, z. B. den HTTP Pfad, die Quell-IP des Anforderers und ob für diese Anfrage der lokale Cache aktualisiert werden musste. Diese Datenpunkte können dann verwendet werden, um die Verfügbarkeit und Latenz der einzelnen Datenpunkte zu berechnen, die der Workload API bereitstellt.
Ein Hinweis zur Verwendung von HTTP Antwortcodes für Verfügbarkeitsmetriken
In der Regel können Sie 2xx- und 3xx-Antworten als erfolgreich und 5xx als Fehlschläge betrachten. 4xx-Antwortcodes liegen irgendwo dazwischen. In der Regel werden sie aufgrund eines Client-Fehlers generiert. Vielleicht liegt ein Parameter außerhalb des zulässigen Bereichs, was zu einer 400-Antwort
Wenn Sie beispielsweise eine strengere Eingabeüberprüfung eingeführt haben, die eine Anfrage ablehnt, die zuvor erfolgreich gewesen wäre, könnte die Antwort von 400 als Rückgang der Verfügbarkeit gewertet werden. Oder vielleicht drosseln Sie den Kunden und geben eine Antwort von 429 zurück. Die Drosselung eines Kunden schützt zwar Ihren Service, um seine Verfügbarkeit aufrechtzuerhalten, aus Sicht des Kunden ist der Service jedoch nicht verfügbar, um seine Anfrage zu bearbeiten. Sie müssen entscheiden, ob 4xx-Antwortcodes Teil Ihrer Verfügbarkeitsberechnung sind oder nicht.
In diesem Abschnitt wurde zwar die Verwendung CloudWatch als Methode zur Erfassung und Analyse von Metriken beschrieben, dies ist jedoch nicht die einzige Lösung, die Sie verwenden können. Sie können sich dafür entscheiden, Metriken auch an Amazon Managed Service for Prometheus und Amazon Managed Grafana, eine Amazon DynamoDB-Tabelle, zu senden oder eine Überwachungslösung eines Drittanbieters zu verwenden. Entscheidend ist, dass die von Ihrem Workload generierten Metriken einen Kontext zu den Grenzen der Fehlerisolierung Ihres Workloads enthalten müssen.
Mit Workloads, die Metriken erzeugen, deren Dimensionen auf die Grenzen der Fehlerisolierung ausgerichtet sind, können Sie eine Beobachtbarkeit einrichten, die isolierte Ausfälle in der Availability Zone erkennt. In den folgenden Abschnitten werden drei sich ergänzende Ansätze zur Erkennung von Ausfällen beschrieben, die auf die Beeinträchtigung einer einzelnen Availability Zone zurückzuführen sind.
Themen
