Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Fehlererkennung mithilfe der Ausreißererkennung
Eine Lücke zum vorherigen Ansatz könnte entstehen, wenn Sie erhöhte Fehlerraten in mehreren Availability Zones feststellen, die aus einem unkorrelierten Grund auftreten. Stellen Sie sich ein Szenario vor, in dem Sie EC2 Instances in drei Availability Zones bereitgestellt haben und Ihr Schwellenwert für den Verfügbarkeitsalarm bei 99% liegt. Dann kommt es zu einer Beeinträchtigung einer einzelnen Availability Zone, wodurch viele Instanzen isoliert werden und die Verfügbarkeit in dieser Zone auf 55% sinkt. Gleichzeitig, aber in einer anderen Availability Zone, verbraucht eine einzelne EC2 Instanz den gesamten Speicherplatz auf ihrem EBS Volume und kann keine Protokolldateien mehr schreiben. Dadurch gibt sie zwar Fehler zurück, besteht aber trotzdem die Integritätsprüfungen des Load Balancers, da diese das Schreiben einer Protokolldatei nicht auslösen. Dies führt dazu, dass die Verfügbarkeit in dieser Availability Zone auf 98% sinkt. In diesem Fall würde Ihr einzelner Availability Zone-Auswirkungsalarm nicht aktiviert werden, da Sie eine Beeinträchtigung der Verfügbarkeit in mehreren Availability Zones feststellen. Sie könnten jedoch trotzdem fast alle Auswirkungen abmildern, indem Sie die beeinträchtigte Availability Zone evakuieren.
Bei einigen Arten von Workloads können in allen Availability Zones konsistent Fehler auftreten, bei denen die vorherige Verfügbarkeitsmetrik möglicherweise nicht hilfreich ist. Nehmen wir AWS Lambda zum Beispiel. AWS ermöglicht es Kunden, ihren eigenen Code für die Ausführung in der Lambda-Funktion zu erstellen. Um den Dienst nutzen zu können, müssen Sie Ihren Code einschließlich Abhängigkeiten in eine ZIP Datei hochladen und den Einstiegspunkt für die Funktion definieren. Aber manchmal verstehen Kunden diesen Teil falsch, weil sie beispielsweise eine kritische Abhängigkeit in der ZIP Datei vergessen oder den Methodennamen in der Lambda-Funktionsdefinition falsch eingeben. Dies führt dazu, dass die Funktion nicht aufgerufen werden kann, was zu einem Fehler führt. AWS Lambda sieht ständig solche Fehler, aber sie deuten nicht darauf hin, dass etwas unbedingt ungesund ist. Eine Beeinträchtigung der Availability Zone kann jedoch auch dazu führen, dass diese Fehler auftreten.
Um ein Signal in dieser Art von Rauschen zu finden, können Sie mithilfe der Ausreißererkennung feststellen, ob die Anzahl der Fehler zwischen den Availability Zones statistisch signifikant schwankt. Wir sehen zwar Fehler in mehreren Availability Zones, aber wenn es wirklich in einer Availability Zone zu einem Ausfall kommen sollte, würden wir davon ausgehen, dass die Fehlerrate in dieser Availability Zone im Vergleich zu den anderen deutlich höher oder möglicherweise deutlich niedriger ist. Aber um wie viel höher oder niedriger?
Eine Möglichkeit, diese Analyse durchzuführen, besteht darin, einen Chi-Quadrat-Test
Ein Chi-Quadrat-Test bewertet die Wahrscheinlichkeit, dass eine Verteilung der Ergebnisse wahrscheinlich ist. In diesem Fall interessiert uns die Verteilung der Fehler auf eine bestimmte Gruppe von. AZs Betrachten Sie für dieses Beispiel vier Availability Zones, um die Mathematik zu vereinfachen.
Stellen Sie zunächst die Nullhypothese auf, die definiert, was Ihrer Meinung nach das Standardergebnis ist. In diesem Test geht die Nullhypothese davon aus, dass Sie erwarten, dass Fehler gleichmäßig auf jede Availability Zone verteilt werden. Generieren Sie dann die alternative Hypothese, dass die Fehler nicht gleichmäßig verteilt sind, was auf eine Beeinträchtigung der Availability Zone hindeutet. Jetzt können Sie diese Hypothesen anhand von Daten aus Ihren Metriken testen. Zu diesem Zweck testen Sie Ihre Metriken in einem Fünf-Minuten-Fenster. Angenommen, Sie erhalten 1000 veröffentlichte Datenpunkte in diesem Fenster, in dem Sie insgesamt 100 Fehler sehen. Sie gehen davon aus, dass bei einer gleichmäßigen Verteilung die Fehler in jeder der vier Availability Zones in 25% der Fälle auftreten würden. Nehmen wir an, die folgende Tabelle zeigt, was Sie erwartet haben, verglichen mit dem, was Sie tatsächlich gesehen haben.
Tabelle 1: Erwartete und tatsächlich festgestellte Fehler im Vergleich
| AZ | Expected | Tatsächliche |
|---|---|---|
use1-az1 |
25 | 20 |
use1-az2 |
25 | 20 |
use1-az3 |
25 | 25 |
use1-az4 |
25 | 35 |
Sie sehen also, dass die Verteilung in Wirklichkeit nicht gleichmäßig ist. Sie könnten jedoch glauben, dass dies auf einen gewissen Grad an Zufälligkeit der von Ihnen untersuchten Datenpunkte zurückzuführen ist. Es besteht eine gewisse Wahrscheinlichkeit, dass ein solcher Verteilungstyp im Stichprobensatz vorkommt, und trotzdem wird davon ausgegangen, dass die Nullhypothese wahr ist. Dies führt zu der folgenden Frage: Wie hoch ist die Wahrscheinlichkeit, ein mindestens so extremes Ergebnis zu erzielen? Wenn diese Wahrscheinlichkeit unter einem definierten Schwellenwert liegt, lehnen Sie die Nullhypothese ab. Um statistisch signifikant
1 Craparo, Robert M. (2007). „Signifikanzniveau“. In Salkind, Neil J. Enzyklopädie für Messung und Statistik 3. Thousand Oaks, CA: SAGE Veröffentlichungen. S. 889—891. ISBN1-412-91611-9.
Wie berechnet man die Wahrscheinlichkeit dieses Ergebnisses? Sie verwenden die x/2-Statistik, die sehr gut untersuchte Verteilungen liefert und anhand dieser Formel die Wahrscheinlichkeit bestimmt werden kann, dass ein so extremes oder extremeres Ergebnis erzielt wird.
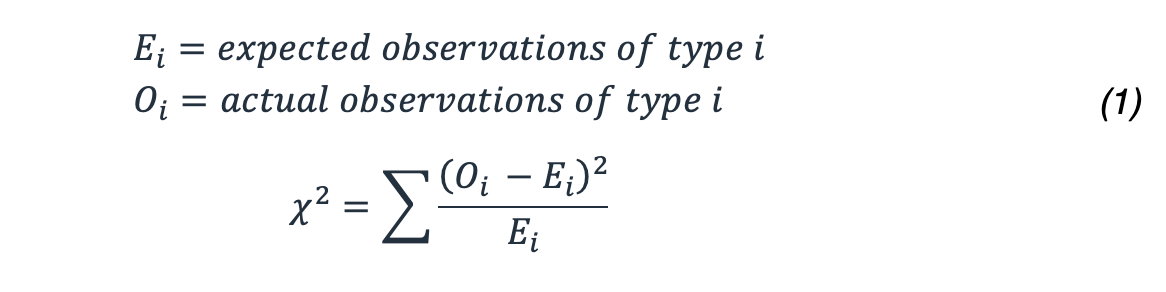
In unserem Beispiel ergibt das:
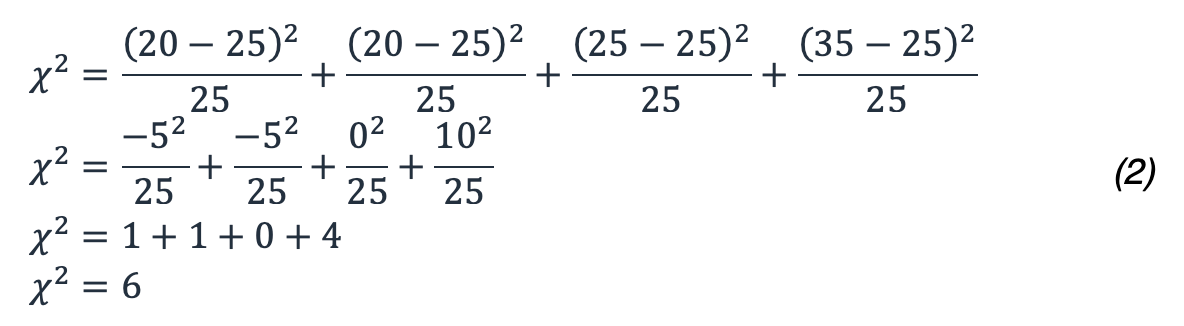
Also, was 6 bedeutet das in Bezug auf unsere Wahrscheinlichkeit? Sie müssen sich eine Chi-Quadrat-Verteilung mit dem entsprechenden Freiheitsgrad ansehen. Die folgende Abbildung zeigt mehrere Chi-Quadrat-Verteilungen für unterschiedliche Freiheitsgrade.
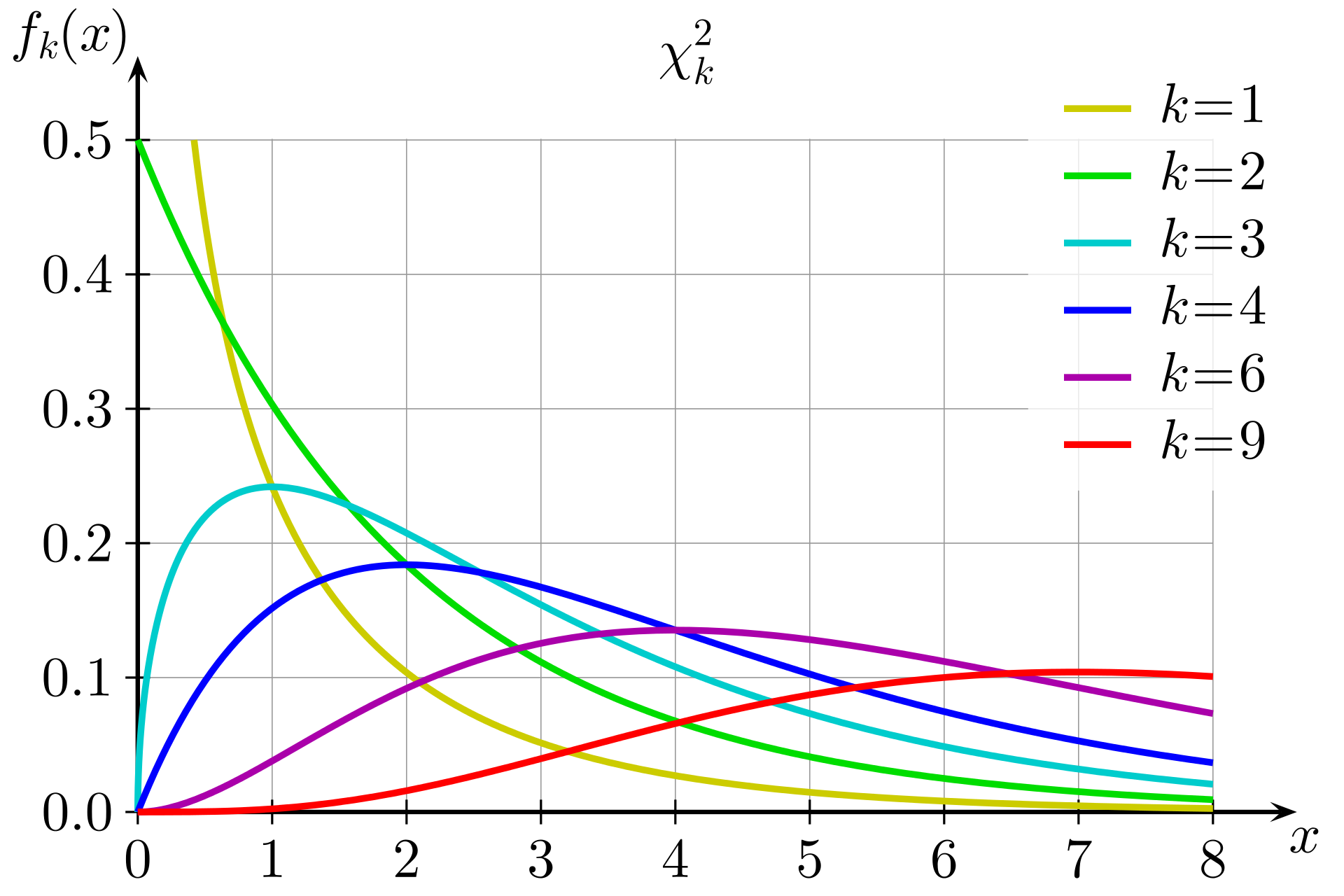
Chi-Quadrat-Verteilungen für verschiedene Freiheitsgrade
Der Freiheitsgrad wird berechnet, wenn er um eins kleiner ist als die Anzahl der Auswahlmöglichkeiten im Test. In diesem Fall beträgt der Freiheitsgrad drei, da es vier Availability Zones gibt. Dann möchten Sie die Fläche unter der Kurve (das Integral) für x ≥ 6 im Diagramm k = 3 ermitteln. Sie können diesen Wert auch anhand einer vorberechneten Tabelle mit häufig verwendeten Werten approximieren.
Tabelle 2: Kritische Werte im Chi-Quadrat
| Freiheitsgrade | Wahrscheinlichkeit geringer als der kritische Wert | ||||
|---|---|---|---|---|---|
| 0,75 | 0,90 | 0,95 | 0,99 | 0,999 | |
| 1 | 1,323 | 2,706 | 3,841 | 6,635 | 10,828 |
| 2 | 2,773 | 4,605 | 5,991 | 9,210 | 13,816 |
| 3 | 4,108 | 6,251 | 7,815 | 11,345 | 16,266 |
| 4 | 5,385 | 7,779 | 9,488 | 13,277 | 18,467 |
Bei drei Freiheitsgraden liegt der Chi-Quadrat-Wert von sechs zwischen den Wahrscheinlichkeitsspalten 0,75 und 0,9. Das bedeutet, dass die Wahrscheinlichkeit, dass diese Verteilung eintritt, bei über 10% liegt, was nicht weniger als der Schwellenwert von 5% ist. Daher akzeptieren Sie die Nullhypothese und stellen fest, dass es keinen statistisch signifikanten Unterschied bei den Fehlerraten zwischen den Availability Zones gibt.
Die Durchführung eines Chi-Quadrat-Statistiktests wird in der CloudWatch metrischen Mathematik nicht nativ unterstützt. Daher müssen Sie die entsprechenden Fehlermetriken in einer Rechenumgebung wie Lambda sammeln CloudWatch und den Test in einer Rechenumgebung ausführen. Sie können sich dafür entscheiden, diesen Test auf MVC Controller-/Aktionsebene oder individueller Microservice-Ebene oder auf Availability Zone-Ebene durchzuführen. Sie müssen abwägen, ob sich eine Beeinträchtigung der Availability Zone auf jeden Controller/jede Aktion oder jeden Microservice gleichermaßen auswirken würde, oder ob ein DNS Ausfall Auswirkungen auf einen Dienst mit geringem Durchsatz haben könnte und nicht auf einen Dienst mit hohem Durchsatz, der die Auswirkungen in aggregierter Form maskieren könnte. Wählen Sie in beiden Fällen die entsprechenden Dimensionen aus, um die Abfrage zu erstellen. Der Grad der Granularität wirkt sich auch auf die resultierenden CloudWatch Alarme aus, die Sie erstellen.
Erfassen Sie die Metrik zur Fehleranzahl für jede AZ und jeden Controller/jede Aktion in einem bestimmten Zeitfenster. Berechnen Sie zunächst, ob das Ergebnis des Chi-Quadrat-Tests entweder wahr (es gab eine statistisch signifikante Verzerrung) oder falsch (es gab keinen, das heißt, die Nullhypothese gilt). Wenn das Ergebnis falsch ist, veröffentlichen Sie einen Datenpunkt von 0 in Ihrem Metrik-Stream für Chi-Quadrat-Ergebnisse für jede Availability Zone. Wenn das Ergebnis wahr ist, veröffentlichen Sie einen 1-Datenpunkt für die Availability Zone mit den Fehlern, die am weitesten vom erwarteten Wert entfernt sind, und eine 0 für die anderen (Beispielcode, der in einer Lambda-Funktion verwendet werden kann, finden Sie unter). Anhang B — Beispiel für eine Chi-Quadrat-Berechnung Sie können den gleichen Ansatz wie bei den vorherigen Verfügbarkeitsalarmen verfolgen, indem Sie einen CloudWatch metrischen Alarm 3 in einer Reihe und einen CloudWatch metrischen Alarm 3 von 5 basierend auf den Datenpunkten erstellen, die von der Lambda-Funktion erzeugt werden. Wie in den vorherigen Beispielen kann dieser Ansatz so geändert werden, dass mehr oder weniger Datenpunkte in einem kürzeren oder längeren Fenster verwendet werden.
Fügen Sie diese Alarme dann zu Ihrem bestehenden Availability Zone-Verfügbarkeitsalarm für die Kombination aus Controller und Aktion hinzu, wie in der folgenden Abbildung dargestellt.
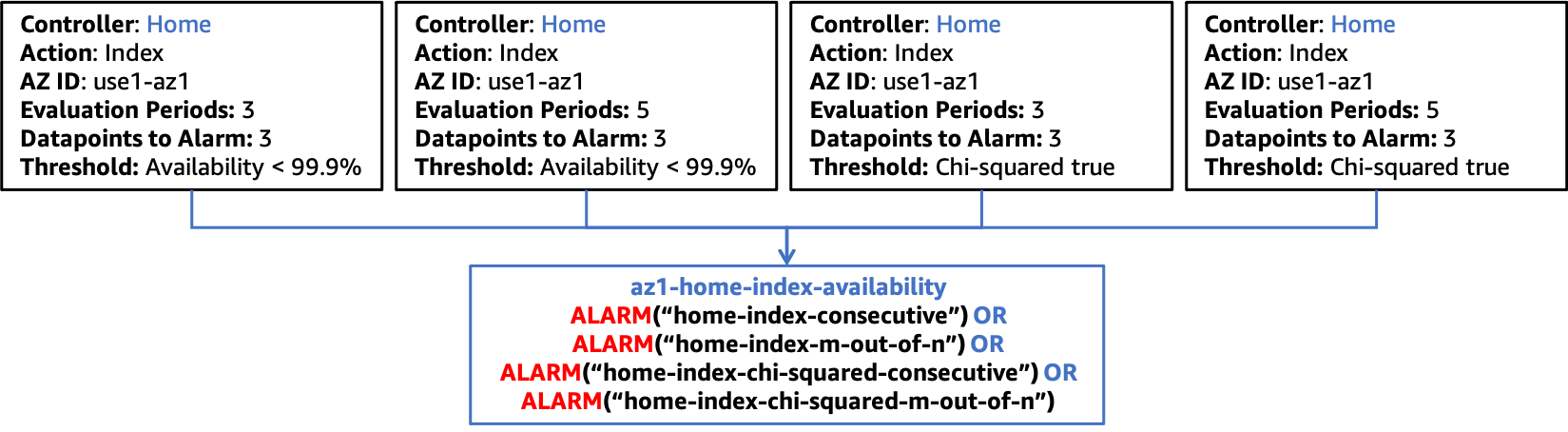
Integration des Chi-Quadrat-Statistiktests mit zusammengesetzten Alarmen
Wie bereits erwähnt, müssen Sie, wenn Sie neue Funktionen in Ihren Workload integrieren, nur die entsprechenden CloudWatch metrischen Alarme erstellen, die für diese neue Funktion spezifisch sind, und die nächste Stufe in der zusammengesetzten Alarm-Hierarchie aktualisieren, um diese Alarme einzubeziehen. Der Rest der Alarmstruktur bleibt statisch.
