Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Fehlererkennung mit CloudWatch kombinierten Alarmen
Bei CloudWatch Metriken ist jeder Dimensionssatz eine eindeutige Metrik, und Sie können für jede einzelne einen CloudWatch Alarm erstellen. Sie können dann CloudWatch zusammengesetzte Amazon-Alarme erstellen, um diese Metriken zu aggregieren.
Um Auswirkungen genau zu erkennen, werden in den Beispielen in diesem paper zwei verschiedene CloudWatch Alarmstrukturen für jede Dimension verwendet, auf die sie den Alarm einstellen. Jeder Alarm verwendet einen Zeitraum von einer Minute, was bedeutet, dass die Metrik einmal pro Minute ausgewertet wird. Beim ersten Ansatz werden drei aufeinanderfolgende Datenpunkte für Sicherheitsverletzungen verwendet, indem die Bewertungszeiträume und Datenpunkte auf „Alarm“ auf drei gesetzt werden, was einer Gesamtauswirkung von drei Minuten entspricht. Beim zweiten Ansatz wird ein „M aus N“ verwendet, wenn 3 beliebige Datenpunkte innerhalb eines Fünf-Minuten-Zeitfensters verletzt werden, indem die Bewertungszeiträume auf fünf und die Datenpunkte auf Alarm auf drei gesetzt werden. Auf diese Weise kann sowohl ein konstantes Signal als auch ein Signal erkannt werden, das über einen kurzen Zeitraum schwankt. Die hier angegebenen Zeitdauern und die Anzahl der Datenpunkte sind nur ein Vorschlag. Verwenden Sie Werte, die für Ihre Workloads sinnvoll sind.
Erkennen Sie Auswirkungen in einer einzelnen Availability Zone
Stellen Sie sich anhand dieses Konstrukts einen Workload vor ControllerAction, derInstanceId,AZ-ID, und Region als Dimensionen verwendet. Der Workload besteht aus zwei Controllern, Products und Home, und einer Aktion pro Controller, List und Index. Er ist in drei Availability Zones in der us-east-1 Region tätig. Sie würden in jeder Availability Zone zwei Alarme für die Verfügbarkeit Controller und Action eine Kombination davon sowie jeweils zwei Alarme für die Latenz einrichten. Anschließend können Sie optional für jede Controller Action Kombination einen zusammengesetzten Verfügbarkeitsalarm erstellen. Schließlich erstellen Sie einen zusammengesetzten Alarm, der alle Verfügbarkeitsalarme für die Availability Zone zusammenfasst. Dies wird in der folgenden Abbildung für eine einzelne Availability Zone dargestelltuse1-az1, wobei der optionale zusammengesetzte Alarm für jede Controller Action Kombination verwendet wird (ähnliche Alarme wären auch für die Availability Zones use1-az2 und use1-az3 Availability Zones vorhanden, werden aber der Einfachheit halber nicht dargestellt).
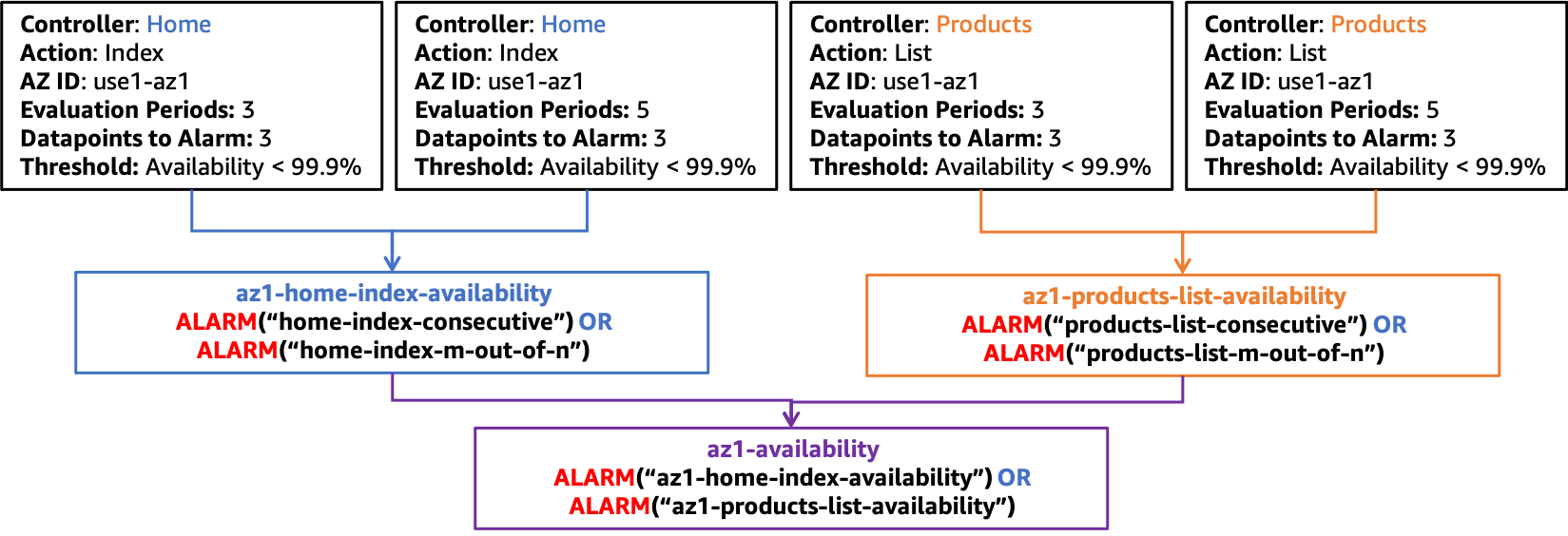
Verbundalarmstruktur für die Verfügbarkeit in use1-az1
Sie würden auch eine ähnliche Alarmstruktur für die Latenz erstellen, wie in der nächsten Abbildung dargestellt.
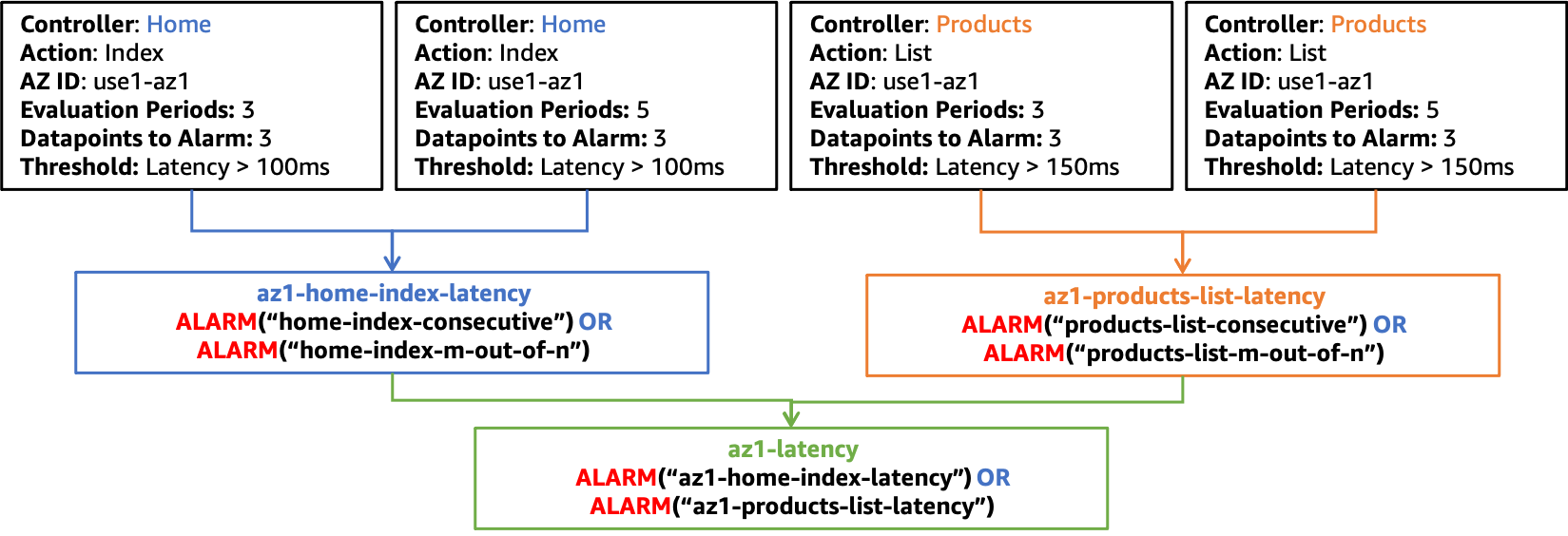
Verbundalarmstruktur für Latenz in use1-az1
Bei den restlichen Zahlen in diesem Abschnitt werden nur die Alarme az1-availability und die az1-latency zusammengesetzten Alarme auf der obersten Ebene angezeigt. Diese zusammengesetzten Alarme az1-availability und informieren Sie darüberaz1-latency, ob in einer bestimmten Availability Zone für einen Teil Ihrer Workload entweder die Verfügbarkeit unter oder die Latenz über definierte Schwellenwerte steigt. Möglicherweise sollten Sie auch erwägen, den Durchsatz zu messen, um Auswirkungen zu erkennen, die verhindern, dass Ihre Arbeitslast in einer einzelnen Availability Zone bearbeitet wird. Sie können auch Alarme, die auf den von Ihren Kanaren ausgegebenen Messdaten basieren, in diese zusammengesetzten Alarme integrieren. Auf diese Weise wird durch den Alarm eine Warnung ausgelöst, wenn entweder auf der Server- oder der Clientseite Auswirkungen auf die Verfügbarkeit oder Latenz festgestellt werden.
Stellen Sie sicher, dass die Auswirkungen nicht regional sind
Ein weiterer Satz zusammengesetzter Alarme kann verwendet werden, um sicherzustellen, dass nur ein isoliertes Availability Zone-Ereignis zur Aktivierung des Alarms führt. Dies wird erreicht, indem sichergestellt wird, dass sich ein zusammengesetzter Availability Zone-Alarm im ALARM Status befindet, während sich die zusammengesetzten Alarme für die anderen Availability Zones im OK Status befinden. Dies führt zu einem zusammengesetzten Alarm pro Availability Zone, die Sie verwenden. Ein Beispiel ist in der folgenden Abbildung dargestellt (denken Sie daran, dass es Alarme für Latenz und Verfügbarkeit in use1-az2 unduse1-az3,az2-latency,az2-availability, undaz3-latency, gibtaz3-availability, die der Einfachheit halber nicht abgebildet sind).
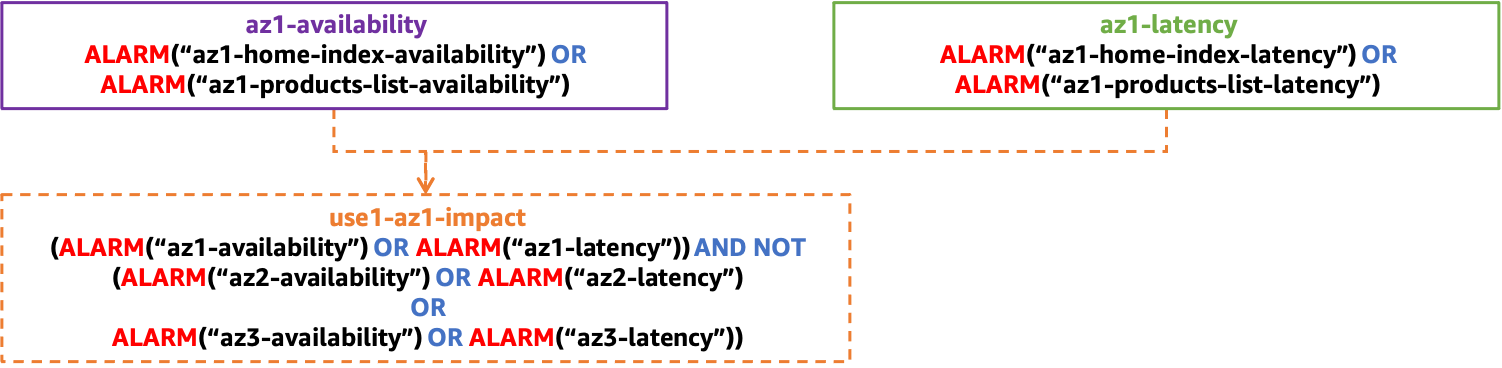
Verbundalarmstruktur zur Erkennung von Stößen, isoliert auf eine einzelne AZ
Stellen Sie sicher, dass die Auswirkungen nicht durch eine einzelne Instanz verursacht werden
Eine einzelne Instanz (oder ein kleiner Prozentsatz Ihrer gesamten Flotte) kann unverhältnismäßige Auswirkungen auf die Verfügbarkeits- und Latenzkennzahlen haben, sodass die gesamte Availability Zone als betroffen erscheinen könnte, obwohl dies in Wirklichkeit nicht der Fall ist. Es ist schneller und genauso effektiv, eine einzelne problematische Instanz zu entfernen, als eine Availability Zone zu evakuieren.
Instances und Container werden in der Regel als kurzlebige Ressourcen behandelt und häufig durch Dienste wie ersetzt. AWS Auto Scaling
Beispielsweise können Sie für eine HTTP Webanwendung eine Regel erstellen, um die wichtigsten Mitwirkenden für HTTP 5xx-Antworten in jeder Availability Zone zu ermitteln. Dadurch wird ermittelt, welche Instances zu einem Rückgang der Verfügbarkeit beitragen (unsere oben definierte Verfügbarkeitsmetrik basiert auf dem Vorhandensein von 5xx-Fehlern). Erstellen Sie anhand des EMF Protokollbeispiels eine Regel mit dem Schlüssel vonInstanceId. Filtern Sie dann das Protokoll nach dem HttpResponseCode Feld. Dieses Beispiel ist eine Regel für die use1-az1 Availability Zone.
{ "AggregateOn": "Count", "Contribution": { "Filters": [ { "Match": "$.InstanceId", "IsPresent": true }, { "Match": "$.HttpStatusCode", "IsPresent": true }, { "Match": "$.HttpStatusCode", "GreaterThan": 499 }, { "Match": "$.HttpStatusCode", "LessThan": 600 }, { "Match": "$.AZ-ID", "In": ["use1-az1"] }, ], "Keys": [ "$.InstanceId" ] }, "LogFormat": "JSON", "LogGroupNames": [ "/loggroupname" ], "Schema": { "Name": "CloudWatchLogRule", "Version": 1 } }
CloudWatch Alarme können ebenfalls auf der Grundlage dieser Regeln erstellt werden. Sie können Alarme auf der Grundlage von Contributor Insights-Regeln mithilfe von metrischer Mathematik und der INSIGHT_RULE_METRIC Funktion mit der UniqueContributors Metrik erstellen. Sie können auch zusätzliche Contributor Insights-Regeln mit CloudWatch Alarmen für Messwerte wie Latenz oder Fehlerzahlen sowie Alarme für die Verfügbarkeit erstellen. Diese Alarme können zusammen mit den kombinierten Alarmen der isolierten Availability Zone verwendet werden, um sicherzustellen, dass einzelne Instanzen den Alarm nicht auslösen. Die Metrik für die Insights-Regel für use1-az1 könnte wie folgt aussehen:
INSIGHT_RULE_METRIC("5xx-errors-use1-az1", "UniqueContributors")
Sie können einen Alarm definieren, wenn diese Metrik einen Schwellenwert überschreitet, in diesem Beispiel zwei. Er wird aktiviert, wenn der einzelne Mitwirkende an 5xx-Antworten diesen Schwellenwert überschreitet, was darauf hindeutet, dass die Auswirkungen auf mehr als zwei Instanzen zurückzuführen sind. Dieser Alarm verwendet den Vergleich „Größer als“ statt „Weniger als“, um sicherzustellen, dass ein Nullwert für einzelne Mitwirkende den Alarm nicht auslöst. Dies zeigt Ihnen, dass die Auswirkung nicht auf eine einzelne Instanz zurückzuführen ist. Passen Sie diesen Schwellenwert an Ihre individuelle Arbeitslast an. Als allgemeine Richtlinie gilt, dass dieser Wert mindestens 5% der gesamten Ressourcen in der Availability Zone ausmachen sollte. Mehr als 5% Ihrer Ressourcen, die betroffen sind, weisen bei ausreichender Stichprobengröße eine statistische Signifikanz auf.
Zusammenführung
Die folgende Abbildung zeigt die vollständige zusammengesetzte Alarmstruktur für eine einzelne Availability Zone:
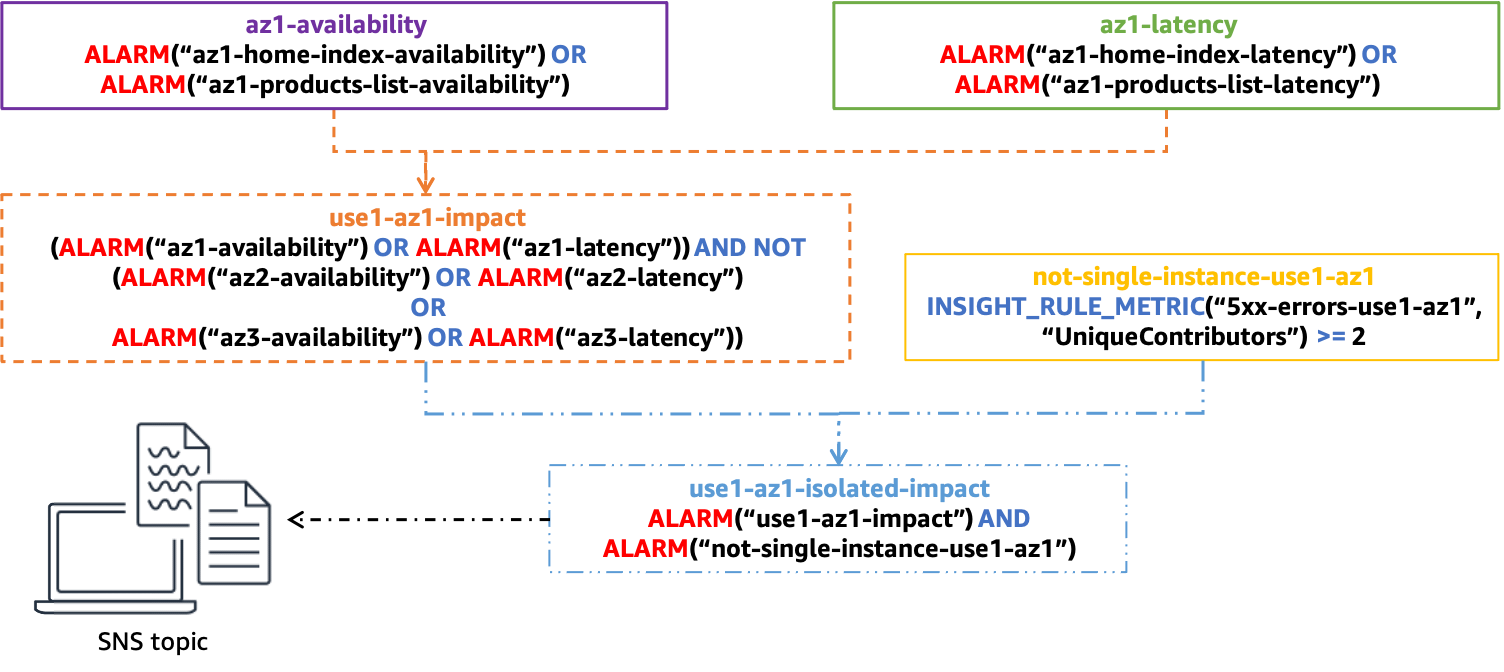
Vollständige Verbundalarmstruktur zur Bestimmung der Einzel-AZ-Auswirkung
Der letzte zusammengesetzte Alarm,, wird aktiviertuse1-az1-isolated-impact, wenn der zusammengesetzte Alarm, der auf die Auswirkungen der isolierten Availability Zone aufgrund von Latenz oder Verfügbarkeit hinweistuse1-az1-aggregate-alarm, sich im ALARM Status befindet und wenn der Alarm, der auf der Contributor Insights-Regel für dieselbe Availability Zone basiertnot-single-instance-use1-az1, ebenfalls im ALARM Status ist (was bedeutet, dass es sich bei der Auswirkung um mehr als eine einzelne Instanz handelt). Sie würden diesen Alarm-Stapel für jede Availability Zone erstellen, die Ihr Workload verwendet.
Sie können diesem letzten Alarm eine Amazon Simple Notification ServiceOK Wenn es in einer anderen Availability Zone zu Auswirkungen kommt, ist es möglich, dass durch die Automatisierung eine zweite oder dritte Availability Zone evakuiert wird, wodurch möglicherweise die gesamte verfügbare Kapazität des Workloads entfernt wird. Die Automatisierung sollte überprüfen, ob bereits eine Evakuierung durchgeführt wurde, bevor Maßnahmen ergriffen werden. Möglicherweise müssen Sie auch Ressourcen in anderen Availability Zones skalieren, bevor eine Evakuierung erfolgreich ist.
Wenn Sie Ihrer MVC Web-App neue Controller oder Aktionen oder einen neuen Microservice oder generell zusätzliche Funktionen hinzufügen, die Sie separat überwachen möchten, müssen Sie in diesem Setup nur einige Alarme ändern. Sie erstellen neue Verfügbarkeits- und Latenzalarme für diese neue Funktionalität und fügen diese dann den entsprechenden zusammengesetzten Verfügbarkeits- und Latenzalarmen hinzu, az1-latency wie az1-availability in dem Beispiel, das wir hier verwendet haben. Die übrigen zusammengesetzten Alarme bleiben statisch, nachdem sie konfiguriert wurden. Dies macht die Einführung neuer Funktionen mit diesem Ansatz zu einem einfacheren Prozess.
