Unterstützung für die Verbesserung dieser Seite beitragen
Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Um zu diesem Benutzerhandbuch beizutragen, wählen Sie den GitHub Link Diese Seite bearbeiten auf, der sich im rechten Bereich jeder Seite befindet.
Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Kubernetes-Konzepte
Amazon Elastic Kubernetes Service (Amazon EKS) ist ein AWS verwalteter Service, der auf dem Open-Source-Kubernetes-Projekt
Auf dieser Seite werden die Kubernetes-Konzepte in drei Abschnitte unterteilt: Warum Kubernetes?, Cluster und Workloads. Der erste Abschnitt beschreibt den Wert der Ausführung eines Kubernetes-Services, insbesondere als verwalteter Service wie Amazon EKS. Der Abschnitt „Workloads“ behandelt, wie Kubernetes-Anwendungen erstellt, gespeichert, ausgeführt und verwaltet werden. Im Abschnitt „Cluster“ werden die verschiedenen Komponenten erläutert, aus denen Kubernetes-Cluster bestehen, und welche Aufgaben Sie beim Erstellen und Verwalten von Kubernetes-Clustern haben.
Beim Durchgehen dieser Inhalte führen Sie Links zu weiteren Beschreibungen der Kubernetes-Konzepte in der Amazon-EKS- und Kubernetes-Dokumentation, falls Sie tiefer in die hier behandelten Themen eintauchen möchten. Weitere Informationen zur Implementierung der Kubernetes-Steuerebene und der Rechenfunktionen in Amazon EKS finden Sie unter Amazon-EKS-Architektur.
Warum Kubernetes?
Kubernetes wurde entwickelt, um die Verfügbarkeit und Skalierbarkeit beim Ausführen unternehmenskritischer containerisierter Anwendungen in Produktionsqualität zu verbessern. Anstatt Kubernetes nur auf einem einzelnen Rechner auszuführen (obwohl dies möglich ist), erreicht Kubernetes diese Ziele, indem es Ihnen ermöglicht, Anwendungen auf einer Reihe von Rechnern auszuführen, die je nach Bedarf erweitert oder reduziert werden können. Kubernetes enthält Funktionen, die Ihnen Folgendes vereinfachen:
-
Anwendungen auf mehreren Rechnern (mithilfe von in Pods bereitgestellten Containern) bereitstellen
-
Container-Zustand und Neustart ausgefallener Container überwachen
-
Container je nach Auslastung nach oben und unten zu skalieren
-
Container mit neuen Versionen aktualisieren
-
Ressourcen zwischen Containern zuzuweisen
-
Datenverkehr über mehrere Rechner hinweg ausgleichen
Durch die Automatisierung dieser komplexen Aufgaben durch Kubernetes kann sich ein Anwendungsentwickler auf die Erstellung und Verbesserung seiner Anwendungs-Workloads konzentrieren, anstatt sich um die Infrastruktur zu kümmern. Der Entwickler erstellt in der Regel Konfigurationsdateien im YAML-Format, die den gewünschten Zustand der Anwendung beschreiben. Dies kann beinhalten, welche Container ausgeführt werden sollen, Ressourcenlimits, Anzahl der Pod-Replikate, CPU/memory Zuweisung, Affinitätsregeln und mehr.
Eigenschaften von Kubernetes
Um seine Ziele zu erreichen, verfügt Kubernetes über die folgenden Eigenschaften:
-
Containerisiert – Kubernetes ist ein Container-Orchestrierungstool. Um Kubernetes verwenden zu können, müssen Sie zunächst Ihre Anwendungen containerisieren. Je nach Art der Anwendung kann dies als eine Reihe von Microservices, als Batch-Aufträge oder in anderen Formen erfolgen. Anschließend können Ihre Anwendungen die Vorteile eines Kubernetes-Workflows nutzen, der ein umfangreiches Ökosystem von Tools beinhaltet, in dem Container als Images in einer Container-Registry
gespeichert, in einem Kubernetes-Cluster bereitgestellt und in einem verfügbaren Knoten ausgeführt werden können. Sie können einzelne Container auf Ihrem lokalen Computer mit Docker oder einer anderen Container-Laufzeitumgebung erstellen und testen, bevor Sie sie in Ihrem Kubernetes-Cluster bereitstellen. -
Skalierbar – Wenn die Nachfrage nach Ihren Anwendungen die Kapazität der auszuführenden Instances dieser Anwendungen übersteigt, kann Kubernetes entsprechend hochskaliert werden. Bei Bedarf kann Kubernetes erkennen, ob Anwendungen mehr CPU oder Speicher benötigen, und darauf reagieren, indem es entweder automatisch die verfügbare Kapazität erweitert oder mehr der vorhandenen Kapazität nutzt. Die Skalierung kann auf Pod-Ebene erfolgen, wenn genügend Rechenleistung für die Ausführung mehrerer Anwendungs-Instances zur Verfügung steht (horizontale Pod-Autoskalierung
), oder auf Knotenebene, wenn mehr Knoten für die erhöhte Kapazität hochgefahren werden müssen (Cluster Autoscaler oder Karpenter ). Da keine Kapazität mehr benötigt wird, können diese Services unnötige Pods löschen und nicht mehr benötigte Knoten herunterfahren. -
Verfügbar – Wenn eine Anwendung oder ein Knoten fehlerhaft oder nicht mehr verfügbar ist, kann Kubernetes die ausgeführten Workloads auf einen anderen verfügbaren Knoten verschieben. Sie können das Problem beheben, indem Sie einfach eine ausgeführte Instance einer Workload oder einen Knoten löschen, auf dem Ihre Workload ausgeführt wird. Im Endeffekt können Workloads an anderen Standorten hochgefahren werden, wenn sie dort nicht mehr ausgeführt werden können.
-
Deklarativ – Kubernetes verwendet aktive Abstimmung, um ständig zu überprüfen, ob der von Ihnen für Ihren Cluster deklarierte Status mit dem tatsächlichen Status übereinstimmt. Indem Sie Kubernetes-Objekte
auf einen Cluster anwenden, in der Regel über YAML-formatted Konfigurationsdateien, können Sie beispielsweise darum bitten, die Workloads zu starten, die Sie auf Ihrem Cluster ausführen möchten. Sie können die Konfigurationen später ändern, um beispielsweise eine neuere Version eines Containers zu verwenden oder mehr Speicher zuzuweisen. Kubernetes wird die erforderlichen Maßnahmen ergreifen, um den gewünschten Zustand herzustellen. Dazu gehört unter anderem das Hoch- oder Herunterfahren von Knoten, das Beenden und Neustarten von Workloads oder das Abrufen aktualisierter Container. -
Zusammensetzbar – Da eine Anwendung in der Regel aus mehreren Komponenten besteht, ist es wünschenswert, eine Reihe dieser Komponenten (oft durch mehrere Container repräsentiert) gemeinsam verwalten zu können. Während Docker Compose eine Möglichkeit bietet, dies direkt mit Docker zu tun, kann Ihnen der Befehl Kubernetes Kompose
dabei helfen, dies mit Kubernetes zu erreichen. Ein Beispiel hierfür finden Sie unter Übersetzen einer Docker-Compose-Datei in Kubernetes-Ressourcen . -
Erweiterbar – Im Gegensatz zu proprietärer Software ist das Open-Source-Projekt Kubernetes so konzipiert, dass Sie Kubernetes beliebig erweitern können, um Ihren Anforderungen gerecht zu werden. APIs und Konfigurationsdateien können direkt geändert werden. Third-parties werden ermutigt, ihre eigenen Controller
zu schreiben, um sowohl die Infrastruktur als auch die Kubernetes-Funktionen für Endbenutzer zu erweitern. Mit Webhooks können Sie Cluster-Regeln einrichten, um Richtlinien durchzusetzen und sich an veränderte Bedingungen anzupassen. Weitere Informationen zur Erweiterung von Kubernetes-Clustern finden Sie unter Erweiterung von Kubernetes . -
Portabel – Viele Unternehmen haben ihre Abläufe in Kubernetes standardisiert, da sie damit alle ihre Anwendungsanforderungen auf einheitliche Weise verwalten können. Entwickler können dieselben Pipelines zum Entwickeln und Speichern von containerisierten Anwendungen verwenden. Diese Anwendungen können dann auf Kubernetes-Clustern bereitgestellt werden, die vor Ort, in Clouds, auf POS-Terminals in Restaurants oder auf IoT-Geräten laufen, die über die Remote-Standorte eines Unternehmens verteilt sind. Aufgrund seines Open-Source-Charakters können Benutzer diese speziellen Kubernetes-Distributionen zusammen mit den zu ihrer Verwaltung erforderlichen Tools entwickeln.
Verwaltung von Kubernetes
Der Quellcode von Kubernetes ist kostenlos verfügbar, sodass Sie Kubernetes mit Ihrer eigenen Ausrüstung selbst installieren und verwalten können. Die eigenständige Verwaltung von Kubernetes erfordert jedoch fundierte Fachkenntnisse und ist mit einem erheblichen Zeit- und Arbeitsaufwand verbunden. Aus diesen Gründen entscheiden sich die meisten Anwender, die Produktions-Workloads bereitstellen, für einen Cloud-Anbieter (z. B. Amazon EKS) oder einen On-Premises-Anbieter (z. B. Amazon EKS Anywhere) mit einer eigenen erprobten Kubernetes-Verteilung und Support durch Kubernetes-Experten. Dadurch können Sie einen Großteil der undifferenzierten, aufwändigen Aufgaben, die für die Wartung Ihrer Cluster erforderlich sind, auslagern, darunter:
-
Hardware — Wenn Sie keine Hardware zur Verfügung haben, um Kubernetes gemäß Ihren Anforderungen auszuführen, kann Ihnen ein Cloud-Anbieter wie AWS Amazon EKS Vorabkosten sparen. Mit Amazon EKS bedeutet dies, dass Sie die besten Cloud-Ressourcen nutzen können, die Ihnen zur Verfügung stehen AWS, darunter Recheninstanzen (Amazon Elastic Compute Cloud), Ihre eigene private Umgebung (Amazon VPC), zentrales Identitäts- und Berechtigungsmanagement (IAM) und Speicher (Amazon EBS). AWS verwaltet die Computer, Netzwerke, Rechenzentren und alle anderen physischen Komponenten, die für den Betrieb von Kubernetes erforderlich sind. Ebenso müssen Sie Ihr Rechenzentrum nicht für die maximale Kapazität an Tagen mit höchster Auslastung auslegen. Bei Amazon EKS Anywhere oder anderen lokalen Kubernetes-Clustern sind Sie für die Verwaltung der Infrastruktur verantwortlich, die in Ihren Kubernetes-Bereitstellungen verwendet wird, aber Sie können sich trotzdem darauf verlassen, dass wir Sie dabei unterstützen, Kubernetes auf dem AWS neuesten Stand zu halten.
-
Verwaltung der Kontrollebene — Amazon EKS verwaltet die Sicherheit und Verfügbarkeit der AWS gehosteten Kubernetes-Steuerebene, die für die Planung von Containern, die Verwaltung der Verfügbarkeit von Anwendungen und andere wichtige Aufgaben verantwortlich ist, sodass Sie sich auf Ihre Anwendungs-Workloads konzentrieren können. Sollte Ihr Cluster ausfallen, AWS sollten Sie über die Mittel verfügen, Ihren Cluster wieder in den Betriebszustand zu versetzen. Bei Amazon EKS Anywhere verwalten Sie die Steuerebene selbst.
-
Geprüfte Upgrades – Bei der Aktualisierung Ihrer Cluster können Sie sich darauf basieren, dass Amazon EKS oder Amazon EKS Anywhere geprüfte Versionen ihrer Kubernetes-Verteilungen bereitstellen.
-
Add-ons— Es gibt Hunderte von Projekten, die für die Erweiterung und Nutzung von Kubernetes konzipiert wurden und die Sie zur Infrastruktur Ihres Clusters hinzufügen oder zur Unterstützung der Ausführung Ihrer Workloads verwenden können. Anstatt diese Add-Ons selbst zu erstellen und zu verwalten, können AWS Sie Amazon-EKS-Add-ons diese mit Ihren Clustern verwenden. Amazon EKS Anywhere bietet kuratierte Pakete
, die Entwicklungen vieler beliebter Open-Source-Projekte enthalten. Daher ist es nicht erforderlich, die Software selbst zu entwickeln oder wichtige Sicherheitspatches, Fehlerbehebungen oder Upgrades zu verwalten. Wenn die Standardeinstellungen Ihren Anforderungen entsprechen, ist in der Regel nur ein sehr geringer Konfigurationsaufwand für diese Add-Ons erforderlich. Weitere Informationen zur Erweiterung Ihres Clusters mit Add-Ons finden Sie unter Cluster erweitern.
Kubernetes in Aktion
Das folgende Diagramm zeigt die wichtigsten Aktivitäten, die Sie als Kubernetes-Administrator oder Anwendungsentwickler zum Erstellen und zur Nutzung eines Kubernetes-Clusters durchführen würden. Dabei wird veranschaulicht, wie Kubernetes-Komponenten miteinander interagieren, wobei die AWS Cloud als Beispiel für den zugrunde liegenden Cloud-Anbieter verwendet wird.
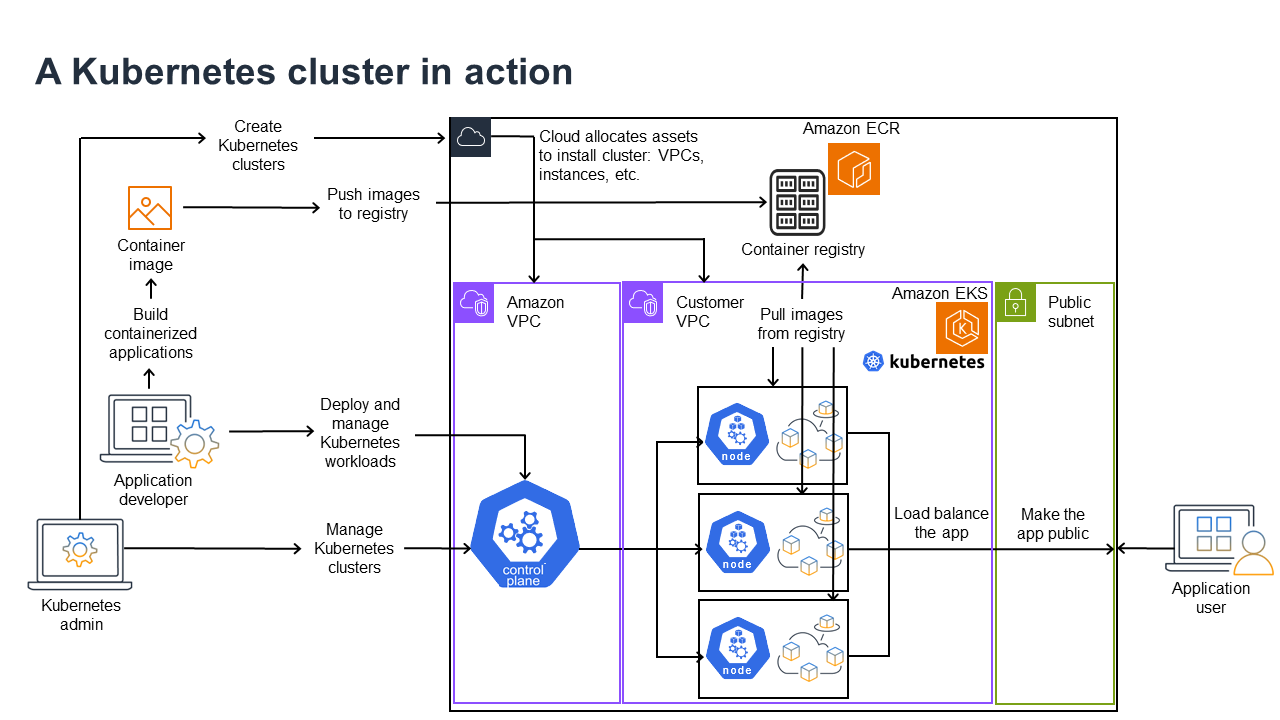
Ein Kubernetes-Administrator erstellt den Kubernetes-Cluster mit einem Tool, das speziell auf den Anbietertyp zugeschnitten ist, auf dem der Cluster entwickelt wird. In diesem Beispiel wird die AWS Cloud als Anbieter verwendet, der den verwalteten Kubernetes-Dienst namens Amazon EKS anbietet. Der verwaltete Service weist automatisch die zum Erstellen des Clusters erforderlichen Ressourcen zu. Dazu gehört das Erstellen von zwei neuen Virtual Private Clouds (Amazon VPCs) für den Cluster, die Einrichtung des Netzwerks und die Zuordnung von Kubernetes-Berechtigungen zu den neuen VPCs für die Verwaltung von Cloud-Ressourcen. Der verwaltete Service erkennt auch, dass die Dienste der Steuerungsebene über Ausführungsplätze verfügen, und weist null oder mehr Amazon EC2 EC2-Instances als Kubernetes-Knoten für die Ausführung von Workloads zu. AWS verwaltet eine Amazon-VPC selbst für die Kontrollebene, während die andere Amazon-VPC die Kundenknoten enthält, die Workloads ausführen.
Viele Aufgaben des Kubernetes-Administrators werden in Zukunft mithilfe von Kubernetes-Tools wie kubectl ausgeführt. Dieses Tool stellt Service-Anfragen direkt an die Steuerebene des Clusters. Die Vorgehensweise bei Abfragen und Änderungen am Cluster entspricht im Wesentlichen der Vorgehensweise, die Sie bei jedem Kubernetes-Cluster anwenden würden.
Ein Anwendungsentwickler, der Workloads in diesem Cluster bereitstellen möchte, kann mehrere Aufgaben ausführen. Der Entwickler muss die Anwendung in ein oder mehrere Container-Images integrieren und diese Images dann in eine Container-Registry übertragen, auf die der Kubernetes-Cluster zugreifen kann. AWS bietet zu diesem Zweck das Amazon Elastic Container Registry (Amazon ECR) an.
Um die Anwendung auszuführen, kann der Entwickler YAML-formatted Konfigurationsdateien erstellen, die dem Cluster mitteilen, wie die Anwendung ausgeführt werden soll, einschließlich der Container, die aus der Registrierung abgerufen werden sollen und wie diese Container in Pods verpackt werden sollen. Die Steuerebene (Scheduler) plant die Container für einen oder mehrere Knoten ein und die Container-Laufzeit auf jedem Knoten ruft die benötigten Container ab und führt sie aus. Der Entwickler kann auch einen Application Load Balancer einrichten, um den Datenverkehr auf die verfügbaren Container zu verteilen, die im jeweiligen Knoten ausgeführt werden, und die Anwendung so freizugeben, dass sie in einem öffentlichen Netzwerk für die Außenwelt verfügbar ist. Anschließend kann sich jeder, der die Anwendung nutzen möchte, mit dem Anwendungsendpunkt verbinden und darauf zugreifen.
In den folgenden Abschnitten werden die einzelnen Features aus der Perspektive von Kubernetes-Clustern und -Workloads detailliert beschrieben.
Cluster
Wenn Sie Kubernetes-Cluster starten und verwalten, sollten Sie wissen, wie Kubernetes-Cluster erstellt, erweitert, verwaltet und gelöscht werden. Sie sollten außerdem wissen, aus welchen Komponenten ein Cluster besteht und wie Sie diese Komponenten warten.
Tools zur Cluster-Verwaltung verwalten die Überschneidungen zwischen den Kubernetes-Services und dem zugrunde liegenden Hardware-Anbieter. Aus diesem Grund erfolgt die Automatisierung dieser Aufgaben in der Regel durch den Kubernetes-Anbieter (wie Amazon EKS oder Amazon EKS Anywhere) mithilfe von anbieterspezifischen Tools. Um beispielsweise einen Amazon-EKS-Cluster zu starten, können Sie eksctl create cluster verwenden, während Sie für Amazon EKS Anywhere eksctl anywhere create cluster verwenden können. Beachten Sie, dass diese Befehle zwar einen Kubernetes-Cluster erstellen, jedoch spezifisch für den Anbieter sind und nicht Teil des Kubernetes-Projekts selbst sind.
Tools zur Erstellung und Verwaltung von Clustern
Das Kubernetes-Projekt bietet Tools zur manuellen Erstellung eines Kubernetes-Clusters. Wenn Sie Kubernetes auf einem einzelnen Rechner installieren oder die Steuerebene auf einem Rechner ausführen und Knoten manuell hinzufügen möchten, können Sie CLI-Tools wie kind
In AWS Cloud können Sie Amazon EKS-Cluster mithilfe von CLI-Tools wie eksctl
-
Verwaltete Kontrollebene —AWS stellt sicher, dass der Amazon EKS-Cluster verfügbar und skalierbar ist, da er die Kontrollebene für Sie verwaltet und sie in allen AWS Availability Zones verfügbar macht.
-
Knotenverwaltung – Anstatt Knoten manuell hinzuzufügen, können Sie Amazon EKS Knoten bei Bedarf automatisch erstellen lassen, indem Sie verwaltete Knotengruppen (siehe Vereinfachung des Knotenlebenszyklus mit verwalteten Knotengruppen) oder Karpenter
verwenden. Verwaltete Knotengruppen verfügen über Integrationen mit Kubernetes Cluster Autoscaling . Mithilfe von Knotenverwaltungstools können Sie Kosteneinsparungen erzielen, beispielsweise durch Spot Instances und Knotenkonsolidierung, sowie die Verfügbarkeit verbessern, indem Sie Feature zur Planung verwenden, um festzulegen, wie Workloads bereitgestellt und Knoten ausgewählt werden. -
Cluster-Netzwerk — Richtet mithilfe von CloudFormation Vorlagen
eksctldie Vernetzung zwischen Komponenten der Steuerungsebene und der Datenebene (Knoten) im Kubernetes-Cluster ein. Außerdem werden Endpunkte für die interne und externe Kommunikation eingerichtet. Weitere Informationen finden Sie unter De-mystifying Cluster-Netzwerke für Amazon EKS-Worker-Knoten. Die Kommunikation zwischen Pods in Amazon EKS erfolgt über Amazon EKS Pod Identities (sieheErfahren Sie, wie EKS Pod Identity Pods Zugriff gewährt auf AWS service), wodurch Pods AWS Cloud-Methoden zur Verwaltung von Anmeldeinformationen und Berechtigungen nutzen können. -
Add-Ons— Amazon EKS erspart Ihnen das Erstellen und Hinzufügen von Softwarekomponenten, die üblicherweise zur Unterstützung von Kubernetes-Clustern verwendet werden. Wenn Sie beispielsweise einen Amazon EKS-Cluster aus dem erstellen AWS-Managementkonsole, werden automatisch die Amazon EKS kube-proxy (Kube-Proxy in Amazon EKS-Clustern verwalten), das Amazon VPC CNI-Plug-In für Kubernetes (Zuweisung von IPs zu Pods mit Amazon VPC CNI) und CoreDNS () hinzugefügt. Verwalten von CoreDNS für DNS in Amazon-EKS-Clustern Weitere Informationen zu diesen Add-Ons, einschließlich einer Liste der verfügbaren Add-Ons, finden Sie unter Amazon-EKS-Add-ons.
Um Ihre Cluster auf Ihren eigenen On-Premises-Computern und -Netzwerken auszuführen, bietet Amazon Amazon EKS Anywhere
Amazon EKS Anywhere basiert auf derselben Amazon EKS Distroetcd weiter unten in diesem Dokument).
Cluster-Komponenten
Die Komponenten eines Kubernetes-Clusters lassen sich in zwei Hauptbereiche unterteilen: die Steuerebene und die Worker-Knoten. Komponente der Steuerebene
Steuerebene
Die Steuerebene besteht aus einer Reihe von Services, die den Cluster verwalten. Diese Services können alle auf einem einzigen Computer ausgeführt werden oder auf mehrere Computer verteilt sein. Intern werden diese als Instances der Steuerebene (CPIs) bezeichnet. Die Ausführung von CPIs hängt von der Größe des Clusters und den Anforderungen an die Hochverfügbarkeit ab. Wenn die Nachfrage im Cluster steigt, kann ein Service auf der Kontrollebene skaliert werden, um mehr Instanzen dieses Dienstes bereitzustellen, wobei die Anforderungen zwischen den Instanzen ausbalanciert werden.
Zu den Aufgaben, die Komponenten der Kubernetes-Steuerebene ausführen, gehören:
-
Kommunikation mit Cluster-Komponenten (API-Server) – Der API-Server (kube-apiserver
) stellt die Kubernetes-API bereit, sodass Anfragen an den Cluster sowohl innerhalb als auch außerhalb des Clusters gestellt werden können. Mit anderen Worten: Anforderungen zum Hinzufügen oder Ändern von Objekten eines Clusters (Pods, Services, Knoten usw.) können von externen Befehlen stammen, beispielsweise Anforderungen von kubectlzum Ausführen eines Pods. Ebenso können vom API-Server Anfragen an Komponenten innerhalb des Clusters gestellt werden, beispielsweise eine Abfrage an denkubelet-Service zum Status eines Pods. -
Speichern von Daten über den Cluster (
etcd-Schlüsselwertspeicher) – Deretcd-Service übernimmt die wichtige Aufgabe, den aktuellen Status des Clusters zu verfolgen. Wenn deretcd-Service nicht mehr erreichbar ist, können Sie den Status des Clusters nicht mehr aktualisieren oder abfragen, obwohl die Workloads noch eine Weile ausgeführt werden. Aus diesem Grund werden in kritischen Clustern in der Regel mehrere Instances desetcd-Services mit Lastausgleich gleichzeitig ausgeführt und regelmäßige Backups desetcd-Schlüsselwertspeichers für den Fall eines Datenverlusts oder einer Datenbeschädigung durchgeführt. Denken Sie daran, dass dies alles in Amazon EKS standardmäßig automatisch für Sie erledigt wird. Amazon EKS Anywhere bietet Anweisungen für die Sicherung und Wiederherstellung von etcd. Informationen darüber, wie etcdDaten verwaltet, finden Sie im etcd-Datenmodell. -
Pods für Knoten planen (Scheduler) – Anfragen zum Starten oder Stoppen eines Pods in Kubernetes werden an den Kubernetes Scheduler
(kube-scheduler ) weitergeleitet. Da ein Cluster über mehrere Knoten verfügen kann, auf denen der Pod ausgeführt werden kann, muss Scheduler auswählen, in welchem Knoten (oder auf welchen Knoten im Falle von Replikaten) der Pod ausgeführt werden soll. Wenn nicht genügend Kapazität verfügbar ist, um den angeforderten Pod in einem vorhandenen Knoten auszuführen, schlägt die Anforderung fehl, sofern Sie keine anderen Vorkehrungen getroffen haben. Zu diesen Vorkehrungen könnte die Aktivierung von Services wie verwaltete Knotengruppen (Vereinfachung des Knotenlebenszyklus mit verwalteten Knotengruppen) oder Karpenter gehören, die automatisch neue Knoten starten können, um die Workloads zu bewältigen. -
Komponenten im gewünschten Zustand halten (Controller Manager) – Der Kubernetes Controller Manager wird als Daemon-Prozess (kube-controller-manager
) ausgeführt, um den Zustand des Clusters zu überwachen und Änderungen am Cluster vorzunehmen, um die erwarteten Zustände wiederherzustellen. Insbesondere gibt es mehrere Controller, die verschiedene Kubernetes-Objekte überwachen, darunter statefulset-controller,endpoint-controller,cronjob-controller,node-controllerund andere. -
Verwalten von Cloud-Ressourcen (Cloud Controller Manager) – Die Interaktionen zwischen Kubernetes und dem Cloud-Anbieter, der die Anfragen für die zugrunde liegenden Rechenzentrumsressourcen ausführt, werden vom Cloud Controller Manager
(cloud-controller-manager ) verwaltet Zu den vom Cloud Controller Manager verwalteten Controllern können ein Route Controller (für die Einrichtung von Cloud-Netzwerkweiterleitungen), ein Service Controller (für die Nutzung von Cloud-Lastausgleichsservices) und ein Knoten-Lebenszyklus-Controller (um Knoten während ihres Lebenszyklus mit Kubernetes synchron zu halten) gehören.
Worker-Knoten (Datenebene)
Bei einem Kubernetes-Cluster mit einem Knoten werden Workloads auf demselben Rechner wie die Steuerebene ausgeführt. Eine gängigere Konfiguration ist jedoch ein oder mehrere separate Computersysteme (Knoten
Wenn Sie zum ersten Mal einen Kubernetes-Cluster erstellen, können Sie mit einigen Tools zur Cluster-Erstellung eine bestimmte Anzahl von Knoten konfigurieren, die dem Cluster hinzugefügt werden sollen (entweder durch die Identifizierung vorhandener Computersysteme oder durch die Erstellung neuer Systeme durch den Anbieter). Bevor Workloads zu diesen Systemen hinzugefügt werden, werden jedem Knoten Services hinzugefügt, um diese Features zu implementieren:
-
Knoten einzeln verwalten (
kubelet) – Der API-Server kommuniziert mit dem Kubelet-Service, der in jedem Knoten ausgeführt wird, um sicherzustellen, dass der Knoten ordnungsgemäß registriert ist und die vom Scheduler angeforderten Pods ausgeführt werden. Das Kubelet kann die Pod-Manifeste lesen und Speicher-Volumes oder andere von den Pods benötigte Feature auf dem lokalen System einrichten. Es kann auch den Zustand der lokal ausgeführten Container überprüfen. -
Container in einem Knoten ausführen (Container-Laufzeit) – Die Container-Laufzeit
in jedem Knoten verwaltet die Container, die für jeden dem Knoten zugewiesenen Pod angefordert werden. Das bedeutet, dass sie Container-Images aus der entsprechenden Registrierung abrufen, den Container ausführen, stoppen und auf Anfragen zum Container antworten kann. Die Standard-Container-Laufzeit ist containerd . Ab Kubernetes 1.24 wurde die spezielle Integration von Docker ( dockershim), die als Container-Laufzeit verwendet werden konnte, aus Kubernetes entfernt. Sie können Docker zwar weiterhin zum Testen und Ausführen von Containern auf Ihrem lokalen System verwenden, aber um Docker mit Kubernetes zu verwenden, müssen Sie jetzt Docker Engine auf jedem Knoten installieren, um es mit Kubernetes zu verwenden. -
Netzwerk zwischen Containern verwalten (
kube-proxy) – Um die Kommunikation zwischen Pods zu unterstützen, verwendet Kubernetes eine als Servicebezeichnetes Feature zum Einrichten von Pod-Netzwerken, welche die mit diesen Pods verknüpften IP-Adressen und Ports verfolgen. Der Service kube-proxy wird in jedem Knoten ausgeführt, damit die Kommunikation zwischen Pods stattfinden kann.
Cluster erweitern
Es gibt einige Services, die Sie zu Kubernetes hinzufügen können, um den Cluster zu unterstützen, die aber nicht in der Steuerebene ausgeführt werden. Diese Services werden oft direkt in Knoten im kube-system-Namespace oder in einem eigenen Namespace ausgeführt (wie dies bei Drittanbietern oft der Fall ist). Ein gängiges Beispiel ist der CoreDNS-Service, der DNS-Services für den Cluster bereitstellt. Informationen dazu, wie Sie feststellen können, welche Cluster-Services in Ihrem Cluster im Kube-System ausgeführt werden, finden Sie unter Integrierte Services ermitteln
Es gibt verschiedene Arten von Add-Ons, die Sie Ihren Clustern hinzufügen können. Um die Funktionsfähigkeit Ihrer Cluster zu gewährleisten, können Sie Beobachtbarkeitsfunktionen hinzufügen (siehe Überwachung der Cluster-Leistung und Anzeige von Protokollen), mit denen Sie beispielsweise Protokollierung, Überwachung und Metriken durchführen können. Mit diesen Informationen können Sie auftretende Probleme beheben, oft über dieselben Beobachtbarkeitsschnittstellen. Beispiele für diese Arten von Diensten sind Amazon CloudWatch (sieheÜberwachen Sie Clusterdaten mit Amazon CloudWatch) GuardDuty, AWS Distro for OpenTelemetry
Eine umfassendere Liste der verfügbaren Amazon-EKS-Add-Ons finden Sie unter Amazon-EKS-Add-ons.
Workloads
Kubernetes definiert einen Workload
Container
Das grundlegendste Element eines Anwendungs-Workloads, den Sie in Kubernetes bereitstellen und verwalten, ist ein Pod
Da der Pod die kleinste bereitstellbare Einheit ist, enthält er in der Regel einen einzigen Container. In Fällen, in denen Container eng miteinander verbunden sind, können sich jedoch mehrere Container in einem Pod befinden. Ein Webserver-Container kann beispielsweise in einem Pod mit einem Sidecar
Die Pod-Spezifikationen (PodSpec
Während ein Pod die kleinste Einheit ist, die Sie bereitstellen, ist ein Container die kleinste Einheit, die Sie entwickeln und verwalten.
Entwicklung von Containern
Der Pod ist eigentlich nur eine Struktur um einen oder mehrere Container, wobei jeder Container selbst das Dateisystem, ausführbare Dateien, Konfigurationsdateien, Bibliotheken und andere Komponenten enthält, um die Anwendung tatsächlich auszuführen. Da Container erstmals von einem Unternehmen namens Docker Inc. eingeführt wurden, werden sie manchmal als Docker-Container bezeichnet. Inzwischen hat die Open Container Initiative
Wenn Sie einen Container entwickeln, beginnen Sie in der Regel mit einer Docker-Datei (die wörtlich so heißt). Innerhalb dieser Docker-Datei identifizieren Sie:
-
Ein Basis-Image – Ein Basis-Container-Image ist ein Container, der normalerweise entweder aus einer Minimalversion des Dateisystems eines Betriebssystems (wie Red Hat Enterprise Linux
oder Ubuntu ) oder einem Minimalsystem erstellt wird, das erweitert wurde, um Software zum Ausführen bestimmter Arten von Anwendungen bereitzustellen (wie Node.js - oder Python -Apps). -
Anwendungssoftware – Sie können Ihre Anwendungssoftware Ihrem Container auf die gleiche Weise hinzufügen, wie Sie sie einem Linux-System hinzufügen würden. Beispielsweise können Sie in Ihrer Docker-Datei
npmundyarnausführen, um eine Java-Anwendung zu installieren, oderyumunddnf, um RPM-Pakete zu installieren. Anders ausgedrückt: Mit einem RUN-Befehl in einer Dockerdatei können Sie jeden Befehl ausführen, der im Dateisystem Ihres Basis-Images verfügbar ist, um Software zu installieren oder innerhalb des resultierenden Container-Images zu konfigurieren. -
Anweisungen – Die Dockerfile-Referenz
beschreibt die Anweisungen, die Sie einer Docker-Datei hinzufügen können, wenn Sie es konfigurieren. Dazu gehören Anweisungen zum Erstellen des Inhalts des Containers selbst ( ADDoderCOPY-Dateien aus dem lokalen System), zum Identifizieren von Befehlen, die beim Ausführen des Containers ausgeführt werden sollen (CMDoderENTRYPOINT), und zum Verbinden des Containers mit dem System, in dem er ausgeführt wird (durch Identifizieren des auszuführendenUSER, eines einzubindenden lokalenVOLUMEoder der Ports zuEXPOSE).
Während der docker-Befehl und der Service üblicherweise zur Erstellung von Containern verwendet werden (docker build), gibt es auch andere Tools wie podman
Aufbewahrungscontainer
Sobald Sie Ihr Container-Image entwickelt haben, können Sie es in einer Registry für die Container-Verteilung
Um Container-Images auf eine öffentlichere Art und Weise zu speichern, können Sie sie in eine öffentliche Container-Registry verschieben. Öffentliche Container-Registries bieten einen zentralen Ort zum Speichern und Verteilen von Container-Images. Beispiele für öffentliche Container-Registrys sind die Amazon Elastic Container Registry
Bei Ausführung von containerisierten Workloads in Amazon Elastic Kubernetes Service (Amazon EKS) empfehlen wir, Kopien der offiziellen Docker-Images abzurufen, die in der Amazon Elastic Container Registry gespeichert sind. Amazon ECR speichert diese Images seit 2021. Sie können in der Amazon ECR Public Gallery
Ausführung von Containern
Da Container in einem Standardformat entwickelt werden, kann ein Container auf jedem Rechner ausgeführt werden, auf dem eine Container-Laufzeitumgebung (wie Docker) ausgeführt werden kann und dessen Inhalt der Architektur des lokalen Rechners entspricht (z. B. x86_64 oder arm). Um einen Container zu testen oder ihn einfach auf Ihrem lokalen Desktop auszuführen, können Sie die Befehle docker run oder podman run verwenden, um einen Container auf dem lokalen Host zu starten. Bei Kubernetes hingegen ist auf jedem Worker-Knoten eine Container-Laufzeitumgebung bereitgestellt und es liegt an Kubernetes, einen Knoten aufzufordern, einen Container auszuführen.
Sobald ein Container zur Ausführung auf einem Knoten zugewiesen wurde, prüft der Knoten, ob die angeforderte Version des Container-Images bereits auf dem Knoten vorhanden ist. Ist dies nicht der Fall, weist Kubernetes die Container-Laufzeitumgebung an, den Container aus der entsprechenden Container-Registry abzurufen und ihn dann lokal auszuführen. Beachten Sie, dass sich ein Container-Image auf das Softwarepaket bezieht, das zwischen Ihrem Laptop, der Container-Registry und den Kubernetes-Knoten verschoben wird. Ein Container bezieht sich auf eine ausgeführte Instance dieses Images.
Pods
Sobald Ihre Container bereit sind, umfasst die Arbeit mit Pods das Konfigurieren, Bereitstellen und Zugänglichmachen der Pods.
Konfigurierung von Pods
Wenn Sie einen Pod definieren, weisen Sie ihm eine Reihe von Attributen zu. Diese Attribute müssen mindestens den Pod-Namen und das auszuführende Container-Image enthalten. Es gibt jedoch noch viele andere Dinge, die Sie mit Ihren Pod-Definitionen konfigurieren möchten (Einzelheiten darüber, was in einen Pod aufgenommen werden kann, finden Sie auf der PodSpec
-
Speicher – Wenn ein ausgeführter Container angehalten und gelöscht wird, verschwindet der Datenspeicher in diesem Container, sofern Sie keinen dauerhafteren Speicher einrichten. Kubernetes unterstützt viele verschiedene Speicher und fasst diese unter dem Begriff Volumes
zusammen. Zu den Speichertypen gehören CephFS , NFS , iSCSI und andere. Sie können sogar ein lokales Blockgerät vom lokalen Computer aus verwenden. Mit einem dieser in Ihrem Cluster verfügbaren Speichertypen können Sie das Speichervolume an einem ausgewählten Einbindepunkt im Dateisystem Ihres Containers einbinden. Ein persistentes Volume ist ein Volume, das nach dem Löschen des Pods weiterhin vorhanden ist, während ein flüchtiges Volume gelöscht wird, wenn der Pod gelöscht wird. Wenn Ihr Cluster-Administrator verschiedene Speicherklassen für Ihren Cluster erstellt hat, haben Sie möglicherweise die Möglichkeit, die Attribute des von Ihnen verwendeten Speichers auszuwählen, z. B. ob das Volume nach der Verwendung gelöscht oder wiederhergestellt wird, ob es erweitert wird, wenn mehr Speicherplatz benötigt wird, und sogar, ob es bestimmte Leistungsanforderungen erfüllt -
Secrets — Indem Sie Secrets
in Pod-Spezifikationen Containern zur Verfügung stellen, können Sie die Berechtigungen bereitstellen, die diese Container für den Zugriff auf Dateisysteme, Datenbanken oder andere geschützte Ressourcen benötigen. Schlüssel, Passwörter und Token gehören zu den Elementen, die als Geheimnisse gespeichert werden können. Durch die Verwendung von Geheimnissen müssen Sie diese Informationen nicht in Container-Images speichern, sondern müssen sie nur ausgeführten Containern zur Verfügung stellen. Ähnlich wie Secrets sind ConfigMaps . Ein ConfigMapenthält in der Regel weniger kritische Informationen, wie beispielsweise Schlüssel-Wert-Paare zur Konfiguration eines Service. -
Container-Ressourcen – Objekte zur weiteren Konfiguration von Containern können in Form von Ressourcenkonfigurationen vorliegen. Sie können für jeden Container die Speicher- und CPU-Menge anfordern, die er verwenden kann, und auch Beschränkungen für die Gesamtmenge dieser Ressourcen festlegen, die der Container verwenden kann. Beispiele finden Sie unter Ressource-Verwaltung für Pods und Container
. -
Störungen – Pods können unfreiwillig (wenn ein Knoten ausfällt) oder freiwillig (wenn ein Upgrade gewünscht wird) unterbrochen werden. Durch die Konfiguration eines Budgets für Pod-Unterbrechungen
können Sie eine gewisse Kontrolle darüber ausüben, wie verfügbar Ihre Anwendung bleibt, wenn Störungen auftreten. Beispiele finden Sie unter Festlegen eines Budgets für Unterbrechung für Ihre Anwendung. -
Namespaces – Kubernetes bietet verschiedene Möglichkeiten, Kubernetes-Komponenten und -Workloads voneinander zu isolieren. Das Ausführen aller Pods für eine bestimmte Anwendung im selben Namespace
ist eine gängige Methode, um diese Pods gemeinsam zu sichern und zu verwalten. Sie können Ihre eigenen Namespaces erstellen oder keinen Namespace angeben (was dazu führt, dass Kubernetes den default-Namespace verwendet). Die Komponenten der Kubernetes-Steuerebene werden in der Regel im Namespace kube-systemausgeführt.
Die soeben beschriebene Konfiguration wird in der Regel in einer YAML-Datei zusammengefasst, die auf den Kubernetes-Cluster angewendet wird. Für persönliche Kubernetes-Cluster können Sie diese YAML-Dateien einfach auf Ihrem lokalen System speichern. Bei kritischeren Clustern und Workloads GitOps
Die zum Erfassen und Bereitstellen von Pod-Informationen verwendeten Objekte werden durch eine der folgenden Bereitstellungsmethoden definiert.
Bereitstellen von Pods
Die Methode, die Sie zum Bereitstellen von Pods wählen, hängt von der Art der Anwendung ab, die Sie mit diesen Pods ausführen möchten. Hier finden Sie einige Optionen:
-
Zustandslose Anwendungen – Eine zustandslose Anwendung speichert die Sitzungsdaten eines Clients nicht, sodass eine andere Sitzung nicht auf die Vorgänge einer vorherigen Sitzung zurückgreifen muss. Dies vereinfacht das Ersetzen von Pods durch neue, wenn sie fehlerhaft werden, oder das Verschieben ohne Speicherung des Zustands. Wenn Sie eine statuslose Anwendung (z. B. einen Webserver) ausführen, können Sie ein Deployment
verwenden, um Pods und bereitzustellen. ReplicaSets A ReplicaSet definiert, wie viele Instanzen eines Pods gleichzeitig ausgeführt werden sollen. Obwohl Sie einen ReplicaSet direkt ausführen können, ist es üblich, Replikate direkt in einem Deployment auszuführen, um zu definieren, wie viele Replikate eines Pods gleichzeitig ausgeführt werden sollen. -
Zustandsbehaftete Anwendungen – Bei einer zustandsbehafteten Anwendung sind die Identität des Pods und die Reihenfolge, in der die Pods gestartet werden, wichtig. Diese Anwendungen benötigen einen stabilen persistenten Speicher und müssen auf konsistente Weise bereitgestellt und skaliert werden. Um eine statusbehaftete Anwendung in Kubernetes bereitzustellen, können Sie verwenden. StatefulSets
Ein Beispiel für eine Anwendung, die normalerweise als ausgeführt wird, StatefulSet ist eine Datenbank. In einer StatefulSet könnten Sie Replikate, den Pod und seine Container, zu mountende Speichervolumes und Speicherorte im Container, an denen Daten gespeichert werden, definieren. Ein Beispiel für eine Datenbank, die als bereitgestellt wird, finden Sie unter Ausführen einer replizierten Stateful-Anwendung . ReplicaSet -
Per-node Anwendungen — Manchmal möchten Sie eine Anwendung auf jedem Knoten in Ihrem Kubernetes-Cluster ausführen. Beispielsweise könnte Ihr Rechenzentrum die Ausführung einer Überwachungsanwendung oder eines bestimmten Fernzugriffs auf jedem Computer verlangen. Für Kubernetes können Sie a verwenden, DaemonSet
um sicherzustellen, dass die ausgewählte Anwendung auf jedem Knoten in Ihrem Cluster ausgeführt wird. -
Anwendungen werden vollständig ausgeführt – Es gibt einige Anwendungen, die Sie ausführen möchten, um eine bestimmte Aufgabe abzuschließen. Dazu könnten beispielsweise Anwendungen gehören, die monatliche Statusberichte erstellen oder alte Daten bereinigen. Mit einem Objekt vom Typ Job
kann eine Anwendung so eingerichtet werden, dass sie gestartet und ausgeführt wird und nach Abschluss der Aufgabe beendet wird. Mit einem CronJob Objekt können Sie eine Anwendung so einrichten, dass sie zu einer bestimmten Stunde, Minute, an einem bestimmten Tag des Monats, Monats oder Wochentags ausgeführt wird. Dabei wird eine Struktur verwendet, die durch das Linux-Crontab-Format definiert ist.
Anwendungen über das Netzwerk zugänglich machen
Da Anwendungen oft als eine Reihe von Microservices bereitgestellt werden, die sich an verschiedene Orte bewegen, benötigte Kubernetes eine Möglichkeit, mit der sich diese Microservices gegenseitig finden konnten. Damit andere auf eine Anwendung außerhalb des Kubernetes-Clusters zugreifen können, benötigte Kubernetes außerdem eine Möglichkeit, diese Anwendung über externe Adressen und Ports verfügbar zu machen. Diese netzwerkbezogenen Features werden mit Service- und Ingress-Objekten durchgeführt:
-
Services – Da sich ein Pod zu verschiedenen Knoten und Adressen bewegen kann, kann es für einen anderen Pod, der mit dem ersten Pod kommunizieren muss, schwierig sein, dessen Standort zu ermitteln. Um dieses Problem zu lösen, ermöglicht Kubernetes die Darstellung einer Anwendung als Service
. Mit einem Service können Sie einen Pod oder eine Gruppe von Pods mit einem bestimmten Namen identifizieren und dann angeben, welcher Port den Service dieser Anwendung vom Pod aus verfügbar macht und welche Ports eine andere Anwendung verwenden könnte, um diesen Service zu kontaktieren. Ein anderer Pod innerhalb eines Clusters kann einfach einen Service nach Namen anfordern und Kubernetes leitet diese Anforderung an den richtigen Port für eine Instance des Pods weiter, auf dem dieser Service ausgeführt wird. -
Ingress – Ingress
ermöglicht es, Anwendungen, die durch Kubernetes-Services dargestellt werden, für Clients außerhalb des Clusters verfügbar zu machen. Zu den grundlegenden Features von Ingress gehören ein Load Balancer (verwaltet von Ingress), der Ingress-Controller und Regeln für die Weiterleitung von Anfragen vom Controller an den Service. Es gibt mehrere Ingress-Controller , aus denen Sie mit Kubernetes auswählen können.
Nächste Schritte
Das Verständnis der grundlegenden Kubernetes-Konzepte und ihrer Beziehung zu Amazon EKS wird Ihnen dabei helfen, sowohl die Amazon-EKS-Dokumentation als auch die Kubernetes-Dokumentation
