Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Planungsdaten im Connect Customer Analytics-Datensee
In diesem Thema wird der Inhalt der Data Lake-Scheduling-Tabellen von Connect Customer detailliert beschrieben. In den Tabellen sind die Spalte, der Typ und die Beschreibung des Inhalts aufgeführt.
Es gibt zwei Möglichkeiten, auf den Analytics Data Lake zuzugreifen und Daten für die gemeinsame Nutzung zu konfigurieren:
Wenn Sie mit Option 1 nicht auf die Planungstabellen zugreifen können, versuchen Sie es mit Option 2.
Inhalt
Personalplanungsprofil
Tabellenname: staff_scheduling_profile
Zusammengesetzter Primärschlüssel: {instance_id, agent_arn,
staff_scheduling_profile_version}
| Spalte | Typ | Description |
|---|---|---|
| instance_id | Zeichenfolge | Die ID der Connect Customer-Instanz. |
| agent_arn | Zeichenfolge | Der ARN des Kundendienstmitarbeiters. |
| staff_scheduling_profile_version | bigint | Die Version des Personalplanungsprofils. |
| instance_arn | Zeichenfolge | Der ARN der Connect Customer-Instanz. |
| staffing_group_arn | Zeichenfolge | Der ARN der Personalgruppe, der der Kundendienstmitarbeiter zugewiesen ist. |
| start_timestamp | Zeitstempel | StartTimestamp für den in den Personalregeln konfigurierten Agenten (Zeitpläne werden erst nach diesem Zeitstempel generiert). |
| end_timestamp | Zeitstempel | EndTimestamp für den in den Personalregeln konfigurierten Agenten (Zeitpläne werden nach diesem Zeitstempel nicht generiert). |
| shift_profile_arn | Zeichenfolge | Der ARN des Schichtprofils, das dem Agenten in den Personalregeln zugewiesen wurde. Schließt sich mit dem Schichtwechselmuster gegenseitig aus. |
| shift_rotation_pattern_arn | Zeichenfolge | Der ARN des Schichtwechselmusters, das dem Agenten in den Personalregeln zugewiesen wurde. Schließt sich mit Shift Profile gegenseitig aus. |
| shift_rotation_start_step_id | bigint | Die Schritt-ID, mit der der Agent im zugewiesenen Schichtrotationsmuster beginnt. |
| timezone | Zeichenfolge | Für den Kundendienstmitarbeiter konfigurierte Zeitzone. |
| is_deleted | Boolesch | Lautet True, wenn der Kundendienstmitarbeiter gelöscht wurde. Andernfalls lautet der Wert False. |
| last_updated_timestamp | Zeitstempel | Zeitstempel, zu dem das Personaleinsatzprofil /gelöscht wurde created/updated. |
| data_lake_last_processed_timestamp | Zeitstempel | Zeitstempel, der anzeigt, wann der Data Lake sich das letzte Mal mit dem Datensatz beschäftigt hat. Dies kann Transformation und Backfill beinhalten. Dieses Feld kann nicht verwendet werden, um die Aktualität der Daten zuverlässig zu bestimmen. |
Verschiebungsaktivitäten
Tabellenname: shift_activities
Zusammengesetzter Primärschlüssel: {instance_id, shift_activity_arn,
shift_activity_version}
| Spalte | Typ | Description |
|---|---|---|
| instance_id | Zeichenfolge | Die ID der Connect Customer-Instanz. |
| shift_activity_arn | Zeichenfolge | Der ARN der Schichtaktivität. |
| shift_activity_version | bigint | Die Version der Schichtaktivität. |
| instance_arn | Zeichenfolge | Der ARN der Connect Customer-Instanz. |
| shift_activity_name | Zeichenfolge | Name der Schichtaktivität. |
| type | Zeichenfolge | Typ der Schichtaktivität. Die möglichen Werte sind: PRODUCTIVE, NON_PRODUCTIVE und LEAVE. |
| sub_type | Zeichenfolge | Der Untertyp der Schichtaktivität. Dies gilt nur für Aktivitäten vom Typ NON_PRODUCTIVE. Die möglichen Werte sind: BREAK_OR_MEAL und NONE. |
| is_adherence_tracked | Boolesch | Lautet True, wenn die Schichtaktivität für die Nachverfolgung der Einhaltung von Vorschriften konfiguriert ist. Andernfalls lautet der Wert False. |
| is_paid | Boolesch | Lautet True, wenn die Schichtaktivität als „Bezahlt“ konfiguriert ist. Andernfalls lautet der Wert False. |
| is_deleted | Boolesch | Lautet True, wenn die Schichtaktivität gelöscht wurde. Andernfalls lautet der Wert False. |
| last_updated_timestamp | Zeitstempel | Der Zeitstempel, zu dem die Schichtaktivität /gelöscht wurde created/updated. |
| data_lake_last_processed_timestamp | Zeitstempel | Der Zeitstempel, der anzeigt, wann der Data Lake sich das letzte Mal mit dem Datensatz beschäftigt hat. Dies kann Transformation und Backfill beinhalten. Dieses Feld kann nicht verwendet werden, um die Aktualität der Daten zuverlässig zu bestimmen. |
Schichtprofile
Tabellenname: shift_profiles
Zusammengesetzter Primärschlüssel: {instance_id, shift_profile_arn,
shift_profile_version}
| Spalte | Typ | Description |
|---|---|---|
| instance_id | Zeichenfolge | Die ID der Connect Customer-Instanz. |
| shift_profile_arn | Zeichenfolge | Der ARN des Schichtprofils. |
| shift_profile_version | bigint | Die Version des Schichtprofils. |
| instance_arn | Zeichenfolge | Der ARN der Connect Customer-Instanz. |
| shift_profile_name | Zeichenfolge | Der Name des Schichtprofils. |
| is_deleted | Boolesch | Lautet True, wenn das Schichtprofil gelöscht wurde. Andernfalls lautet der Wert False. |
| last_updated_timestamp | Zeitstempel | Der Zeitstempel, zu dem das Schichtprofil /gelöscht wurde created/updated. |
| data_lake_last_processed_timestamp | Zeitstempel | Der Zeitstempel, der anzeigt, wann der Data Lake sich das letzte Mal mit dem Datensatz beschäftigt hat. Dies kann Transformation und Backfill beinhalten. Dieses Feld kann nicht verwendet werden, um die Aktualität der Daten zuverlässig zu bestimmen. |
Personalgruppen
Tabellenname: staffing_groups
Zusammengesetzter Primärschlüssel: {instance_id, staffing_group_arn,
staffing_group_version}
| Spalte | Typ | Description |
|---|---|---|
| instance_id | Zeichenfolge | Die ID der Connect Customer-Instanz. |
| staffing_group_arn | Zeichenfolge | Der ARN der Personalgruppe. |
| staffing_group_version | bigint | Die Version der Personalgruppe. |
| instance_arn | Zeichenfolge | Der ARN der Connect Customer-Instanz. |
| staffing_group_name | Zeichenfolge | Der Name der Personalgruppe. |
| is_deleted | Boolesch | Lautet True, wenn die Personalgruppe gelöscht wurde. Andernfalls lautet der Wert False. |
| last_updated_timestamp | Zeitstempel | Der Zeitstempel, zu dem die Personalgruppe /gelöscht wurde. created/updated |
| data_lake_last_processed_timestamp | Zeitstempel | Der Zeitstempel, der anzeigt, wann der Data Lake sich das letzte Mal mit dem Datensatz beschäftigt hat. Dies kann Transformation und Backfill beinhalten. Dieses Feld kann nicht verwendet werden, um die Aktualität der Daten zuverlässig zu bestimmen. |
Personalgruppen – Prognosegruppen
Tabellenname: staffing_group_forecast_groups
Zusammengesetzter Primärschlüssel: {instance_id, staffing_group_arn,
staffing_group_version, forecast_group_arn}
Diese Tabelle sollte abgefragt werden, indem sie mit der Tabelle staffing_groups zu staffing_group_arn und staffing_group_version verknüpft wird.
| Spalte | Typ | Description |
|---|---|---|
| instance_id | Zeichenfolge | Die ID der Connect Customer-Instanz. |
| staffing_group_arn | Zeichenfolge | Der ARN der Personalgruppe. |
| staffing_group_version | bigint | Die Version der Personalgruppe. |
| forecast_group_arn | Zeichenfolge | Der ARN der Prognosegruppe, die der Personalgruppe zugeordnet ist. |
| instance_arn | Zeichenfolge | Der ARN der Connect Customer-Instanz. |
| is_deleted | Boolesch | Wird auf False gesetzt, wenn die StaffingGroup-ForecastGroup Zuordnung gültig ist. |
| last_updated_timestamp | Zeitstempel | Der Zeitstempel, zu dem die Personalgruppe gegründet wurde. created/updated |
| data_lake_last_processed_timestamp | Zeitstempel | Der Zeitstempel, der anzeigt, wann der Data Lake sich das letzte Mal mit dem Datensatz beschäftigt hat. Dies kann Transformation und Backfill beinhalten. Dieses Feld kann nicht verwendet werden, um die Aktualität der Daten zuverlässig zu bestimmen. |
Personalgruppen – Supervisoren
Tabellenname: staffing_group_supervisors
Zusammengesetzter Primärschlüssel: {instance_id, staffing_group_arn,
staffing_group_version, supervisor_arn}
Diese Tabelle sollte abgefragt werden, indem sie mit der Tabelle staffing_groups zu staffing_group_arn und staffing_group_version verknüpft wird.
| Spalte | Typ | Description |
|---|---|---|
| instance_id | Zeichenfolge | Die ID der Connect Customer-Instanz. |
| staffing_group_arn | Zeichenfolge | Der ARN der Personalgruppe. |
| staffing_group_version | bigint | Die Version der Personalgruppe. |
| supervisor_arn | Zeichenfolge | Der Kundendienstmitarbeiter-ARN des Supervisoren, der der Personalgruppe zugeordnet ist. |
| instance_arn | Zeichenfolge | Der ARN der Connect Customer-Instanz. |
| is_deleted | Boolesch | Wird auf False gesetzt, wenn die StaffingGroup-ForecastGroup Zuordnung gültig ist. |
| last_updated_timestamp | Zeitstempel | Der Zeitstempel, zu dem die Personalgruppe gegründet wurde. created/updated |
| data_lake_last_processed_timestamp | Zeitstempel | Der Zeitstempel, der anzeigt, wann der Data Lake sich das letzte Mal mit dem Datensatz beschäftigt hat. Dies kann Transformation und Backfill beinhalten. Dieses Feld kann nicht verwendet werden, um die Aktualität der Daten zuverlässig zu bestimmen. |
Personalschichten
Tabellenname: staff_shifts
Zusammengesetzter Primärschlüssel: {instance_id, shift_id, shift_version}
| Spalte | Typ | Description |
|---|---|---|
| instance_id | Zeichenfolge | Die ID der Connect Customer-Instanz. |
| shift_id | Zeichenfolge | Die ID der Schicht. |
| shift_version | bigint | Die Version der Schicht. |
| instance_arn | Zeichenfolge | Der ARN der Connect Customer-Instanz. |
| agent_arn | Zeichenfolge | Der ARN des Kundendienstmitarbeiters. |
| shift_start_timestamp | Zeitstempel | Der Zeitpunkt, zu dem die Schicht beginnt. |
| shift_end_timestamp | Zeitstempel | Der Zeitpunkt, zu dem die Schicht endet. |
| created_timestamp | Zeitstempel | Der Zeitpunkt, zu dem die Schicht erstellt wurde. |
| is_deleted | Boolesch | Lautet True, wenn die Schicht gelöscht wurde. Andernfalls lautet der Wert False. |
| last_updated_timestamp | Zeitstempel | Der Zeitstempel, zu dem die Schicht /gelöscht wurde created/updated. |
| data_lake_last_processed_timestamp | Zeitstempel | Der Zeitstempel, der anzeigt, wann der Data Lake sich das letzte Mal mit dem Datensatz beschäftigt hat. Dies kann Transformation und Backfill beinhalten. Dieses Feld kann nicht verwendet werden, um die Aktualität der Daten zuverlässig zu bestimmen. |
Schichtaktivitäten des Personals
Tabellenname: staff_shift_activities
Zusammengesetzter Primärschlüssel: {instance_id, shift_id, shift_version,
activity_id}
Diese Tabelle sollte abgefragt werden, indem sie mit der Tabelle staff_shifts zu shift_id und shift_version verknüpft wird.
| Spalte | Typ | Description |
|---|---|---|
| instance_id | Zeichenfolge | Die ID der Connect Customer-Instanz. |
| shift_id | Zeichenfolge | Die ID der Schicht. |
| shift_version | bigint | Die Version der Schicht. |
| activity_id | Zeichenfolge | Die ID der Aktivität. |
| instance_arn | Zeichenfolge | Der ARN der Connect Customer-Instanz. |
| activity_start_timestamp | Zeitstempel | Der Zeitpunkt, zu dem die Aktivität beginnt. |
| activity_end_timestamp | Zeitstempel | Der Zeitpunkt, zu dem die Aktivität endet. |
| shift_activity_arn | Zeichenfolge | Der ARN der Schichtaktivität. Wenn shift_activity_arn Null ist, bedeutet dies, dass die Aktivität „Work“ lautet. |
| activity_status | Zeichenfolge | Der Status der Aktivität. Dieser Wert lautet INACTIVE, wenn sich die Aktivität mit einem Urlaub überschneidet. |
| is_overtime | Boolesch | Lautet True, wenn die Aktivität Teil der Überstunden ist. Andernfalls lautet der Wert False. |
| is_deleted | Boolesch | Lautet False, wenn die Schichtaktivitäten gültig sind. |
| last_updated_timestamp | Zeitstempel | Der Zeitstempel, zu dem die Schicht stattfand created/updated. |
| data_lake_last_processed_timestamp | Zeitstempel | Der Zeitstempel, der anzeigt, wann der Data Lake sich das letzte Mal mit dem Datensatz beschäftigt hat. Dies kann Transformation und Backfill beinhalten. Dieses Feld kann nicht verwendet werden, um die Aktualität der Daten zuverlässig zu bestimmen. |
Änderungen am Urlaubsguthaben des Personals
Tabellenname: staff_timeoff_balance_changes
Zusammengesetzter Primärschlüssel: {instance_id, agent_arn, shift_activity_arn,
timeoff_balance_version}
| Spalte | Typ | Description |
|---|---|---|
| instance_arn | Zeichenfolge | Der ARN der Connect Customer-Instanz. |
| instance_id | Zeichenfolge | Die ID der Connect Customer-Instanz. |
| account_id | Zeichenfolge | Die ID des AWS Kontos. |
| agent_arn | Zeichenfolge | Der ARN des Kundendienstmitarbeiters. |
| shift_activity_arn | Zeichenfolge | Der ARN der Schichtaktivität, der dieses Guthaben zugewiesen ist. |
| timeoff_balance_version | bigint | Die Version des Urlaubsguthabens, eine fortlaufende Zahl, die die Reihenfolge der Änderungen angibt. |
| balance_update_source | Zeichenfolge | Quelle der Guthabenaktualisierung. Die möglichen Werte sind TIME_OFF_BALANCE_UPLOAD, CONNECT_TIME_OFF_REQUEST, SCHEDULE_PUBLISH, CSV_TIME_OFF_BALANCE_DELETION, TIME_OFF_BALANCE_BACKFILL, SYSTEM_UPDATE. |
| timeoff_id | Zeichenfolge | Die ID des Urlaubs, der diese Guthabenänderung verursacht hat, falls vorhanden. |
| last_updated_by | Zeichenfolge | Der ARN des Kundendienstmitarbeiter, der diese Guthabenänderung verursacht hat, falls vorhanden. |
| balance_change_in_hours | double | Um viele Stunden das Urlaubsguthaben durch diese Änderung aktualisiert wurde. Wenn dieser Wert positiv ist, erhöht sich das Urlaubsguthaben durch diese Änderung. Wenn dieser Wert negativ ist, verringert sich das Urlaubsguthaben durch diese Änderung. Dieser Wert ist für Guthaben-Upload- und -Löschereignisse nicht definiert. |
| remaining_balance_in_hours | double | Die verbleibenden Stunden Urlaubsguthaben nach diesem Änderungsereignis. Dieser Wert ist für Guthaben-Löschereignisse nicht definiert. |
| last_created_timestamp | Zeitstempel | Der Zeitpunkt, zu dem der Datensatz zur Änderung des Urlaubsguthabens erstellt wurde. |
| data_lake_last_processed_timestamp | Zeitstempel | Der Zeitstempel, der anzeigt, wann der Data Lake sich das letzte Mal mit dem Datensatz beschäftigt hat. Dies kann Transformation und Backfill beinhalten. Dieses Feld kann nicht verwendet werden, um die Aktualität der Daten zuverlässig zu bestimmen. |
Personalurlaube
Tabellenname: staff_timeoffs
Zusammengesetzter Primärschlüssel: {instance_id, timeoff_id, agent_arn,
timeoff_version}
| Spalte | Typ | Description |
|---|---|---|
| instance_id | Zeichenfolge | Die ID der Connect Customer-Instanz. |
| timeoff_id | Zeichenfolge | Die ID des Urlaubs. |
| agent_arn | Zeichenfolge | Der ARN des Kundendienstmitarbeiters. |
| timeoff_version | bigint | Die Version des Urlaubs. |
| instance_arn | Zeichenfolge | Der ARN der Connect Customer-Instanz. |
| timeoff_type | Zeichenfolge | Die Art des Urlaubs. Die möglichen Werte sind: TIME_OFF und VOLUNTARY_TIME_OFF. |
| timeoff_start_timestamp | Zeitstempel | Zeitpunkt, zu dem der Urlaub beginnt. |
| timeoff_end_timestamp | Zeitstempel | Zeitpunkt, zu dem der Urlaub endet. |
| timeoff_status | Zeichenfolge | Status des Urlaubs. Die möglichen Werte sind: PENDING_CREATE, PENDING_UPDATE, PENDING_CANCEL, PENDING_ACCEPT, PENDING_APPROVE, PENDING_DECLINE, APPROVED, ACCEPTED, REJECTED, CANCELLED, WAITING_ACCEPT und WAITING_APPROVE. Die Status WAITING geben an, dass „Timeoff“ auf eine Benutzeraktion wartet. Die Status PENDING geben an, dass „Timeoff“ auf die Verarbeitung einer Benutzeraktion durch das System wartet. |
| shift_activity_arn | Zeichenfolge | Der ARN der Schichtaktivität, die für die arbeitsfreie Zeit verwendet wurde. |
| effective_timeoff_hours | double | Gesamtzahl der effektiven Urlaubsstunden. Tatsächliche Urlaubsstunden werden auf Grundlage der Urlaubsabzugslogik berechnet. Dies ist nur für den Typ TIME_OFF festgelegt. |
| last_updated_timestamp | Zeitstempel | Zeitstempel, zu dem der Time Off /gelöscht wurde created/updated. |
| data_lake_last_processed_timestamp | Zeitstempel | Zeitstempel, der anzeigt, wann der Data Lake sich das letzte Mal mit dem Datensatz beschäftigt hat. Dies kann Transformation und Backfill beinhalten. Dieses Feld kann nicht verwendet werden, um die Aktualität der Daten zuverlässig zu bestimmen. |
Personal-Urlaubsintervalle
Tabellenname: staff_timeoff_intervals
Zusammengesetzter Primärschlüssel: {instance_id, timeoff_id, timeoff_version,
interval_id}
Diese Tabelle sollte abgefragt werden, indem sie mit der Tabelle staff_timeoffs zu timeoff_id und timeoff_version verknüpft wird.
| Spalte | Typ | Description |
|---|---|---|
| instance_id | Zeichenfolge | Die ID der Connect Customer-Instanz. |
| timeoff_id | Zeichenfolge | Die ID des Urlaubs. |
| timeoff_version | bigint | Die Version des Urlaubs. |
| interval_id | Zeichenfolge | Die ID des Urlaubs-Intervalls. |
| instance_arn | Zeichenfolge | Der ARN der Connect Customer-Instanz. |
| timeoff_interval_start_timestamp | Zeitstempel | Zeitpunkt, zu dem das spezifische Urlaubs-Intervall beginnt. |
| timeoff_interval_end_timestamp | Zeitstempel | Zeitpunkt, zu dem das spezifische Urlaubs-Intervall endet. |
| interval_effective_timeoff_hours | double | Tatsächliche Urlaubsstunden für dieses spezifische Urlaubs-Intervall. Tatsächliche Urlaubsstunden werden auf Grundlage der Urlaubsabzugslogik berechnet. |
| last_updated_timestamp | Zeitstempel | Zeitstempel, zu dem der Time Off /gelöscht wurde created/updated. |
| data_lake_last_processed_timestamp | Zeitstempel | Zeitstempel, der anzeigt, wann der Data Lake sich das letzte Mal mit dem Datensatz beschäftigt hat. Dies kann Transformation und Backfill beinhalten. Dieses Feld kann nicht verwendet werden, um die Aktualität der Daten zuverlässig zu bestimmen. |
Bedarfsgruppe für Mitarbeiter
Name der Tabelle: staff_demand_group
Zusammengesetzter Primärschlüssel: {instance_id, agent_arn, demand_group_arn, staff_demand_group_version}
| Spalte | Typ | Description |
|---|---|---|
| instance_id | Zeichenfolge | Die ID der Connect Customer-Instanz. |
| agent_arn | Zeichenfolge | Der ARN des Kundendienstmitarbeiters. |
| demand_group_arn | Zeichenfolge | Der ARN der Nachfragegruppe. |
| staff_demand_group_version | Long | Version für die Zuordnung zwischen diesem Agenten und der Bedarfsgruppe |
| priority | Zeichenfolge | Priorität der Bedarfsgruppe für diesen Agenten. Kann NIEDRIG, MITTEL oder HOCH sein |
| instance_arn | Zeichenfolge | Der ARN der Connect Customer-Instanz. |
| is_override | Boolesch | Ist auf 'true' gesetzt, wenn die Zuordnung zwischen Agent und Bedarfsgruppe auf Agentenebene überschrieben ist. |
| is_deleted | Boolesch | Wird auf „true“ gesetzt, wenn die Zuordnung zwischen Agent und Bedarfsgruppe gelöscht wird. |
| last_updated_timestamp | Zeitstempel | Der Zeitstempel, zu dem die Zuordnung zwischen Agent und Bedarfsgruppe erfolgte created/updated. |
| data_lake_last_processed_timestamp | Zeitstempel | Der Zeitstempel, der anzeigt, wann der Data Lake sich das letzte Mal mit dem Datensatz beschäftigt hat. Dies kann Transformation und Backfill beinhalten. Dieses Feld kann nicht verwendet werden, um die Aktualität der Daten zuverlässig zu bestimmen. |
Personengruppen, Bedarfsgruppe
Name der Tabelle: staffing_group_demand_group
Zusammengesetzter Primärschlüssel: {instance_id, staffing_group_arn, demand_group_arn,
staffing_group_demand_group_version}
| Spalte | Typ | Description |
|---|---|---|
| instance_id | Zeichenfolge | Die ID der Connect Customer-Instanz. |
| staffing_group_arn | Zeichenfolge | Der ARN der Personalgruppe. |
| demand_group_arn | Zeichenfolge | Der ARN der Nachfragegruppe. |
| staffing_group_demand_group_version | Long | Version für diese Zuordnung von Staffing Group zu Demand Group |
| priority | Zeichenfolge | Priorität der Bedarfsgruppe für diese Personalgruppe. Kann NIEDRIG, MITTEL oder HOCH sein |
| instance_arn | Zeichenfolge | Der ARN der Connect Customer-Instanz. |
| is_deleted | Boolesch | Wird auf „true“ gesetzt, wenn die Zuordnung zwischen Personalgruppe und Bedarfsgruppe gelöscht wird. |
| last_updated_timestamp | Zeitstempel | Zeitstempel, zu dem die Zuordnung zwischen Personalgruppe und Bedarfsgruppe /gelöscht wurde. created/updated |
| data_lake_last_processed_timestamp | Zeitstempel | Der Zeitstempel, der anzeigt, wann der Data Lake sich das letzte Mal mit dem Datensatz beschäftigt hat. Dies kann Transformation und Backfill beinhalten. Dieses Feld kann nicht verwendet werden, um die Aktualität der Daten zuverlässig zu bestimmen. |
Verteilung der Aktivitäten in der Personalschicht
Name der Tabelle: staff_shift_activity_allocations
Zusammengesetzter Primärschlüssel: {instance_id, shift_id, shift_version, activity_id, demand_group_arn}
| Spalte | Typ | Description |
|---|---|---|
| instance_id | Zeichenfolge | Die ID der Connect Customer-Instanz. |
| shift_id | Zeichenfolge | Die ID der Schicht. |
| shift_version | Long | Die Version der Schicht. |
| activity_id | Zeichenfolge | Die ID der Aktivität. |
| demand_group_arn | Zeichenfolge | Der ARN der Nachfragegruppe. |
| forecast_group_arn | Zeichenfolge | Der ARN der Prognosegruppe. |
| Zuweisungsprozentsatz | double | Prozentuale Zuordnung der Aktivität zur Bedarfsgruppe. |
| is_deleted | Boolesch | Wird auf False gesetzt, wenn der gültig StaffingGroup-ForecastGroupassociation ist. |
| last_updated_timestamp | Zeitstempel | Der Zeitstempel, zu dem die Personalgruppe gegründet wurde. created/updated |
| data_lake_last_processed_timestamp | Zeitstempel | Der Zeitstempel, der anzeigt, wann der Data Lake sich das letzte Mal mit dem Datensatz beschäftigt hat. Dies kann Transformation und Backfill beinhalten. Dieses Feld kann nicht verwendet werden, um die Aktualität der Daten zuverlässig zu bestimmen. |
Zeitplanmetriken
Tabellenname: schedule_metrics
Zusammengesetzter Primärschlüssel: {instance_id, metric_id, interval_start_timestamp}
| Spalte | Typ | Description |
|---|---|---|
| instance_id | Zeichenfolge | Der ARN der Amazon-Connect-Instance. |
| instance_arn | Zeichenfolge | Die ID der Amazon-Connect-Instance. |
| metric_id | Zeichenfolge | Eindeutiger Bezeichner für den Metrikwert |
| aws_account_id | Zeichenfolge | Die ID des AWS-Kontos. |
| entity_type | Zeichenfolge | Gibt an, ob sich die Metrik auf eine Prognosegruppe oder eine Bedarfsgruppe bezieht. |
| entity_arn | Zeichenfolge | Arn der Prognosegruppe oder Nachfragegruppe |
| channel | Zeichenfolge | Bezeichnet den Medienkanal wie Voice, Chat. Wenn die Zeile Messwerte enthält, die sich nicht auf Kanalebene beziehen, wird sie mit ALL gefüllt |
| interval_start_timestamp | Zeitstempel | Zeitstempel, der den Beginn des Intervalls angibt |
| required_agent_count | float | Bezeichnet die prognostizierte Anzahl der Agenten |
| scheduled_agent_count | float | Bezeichnet die Anzahl der Zeitplanagenten |
| scheduled_occupancy | float | Bezeichnet den Prozentsatz der Belegung |
| scheduled_service_level_percentage | float | Gibt den Prozentsatz der geplanten Servicelevel an |
| service_level_seconds | Ganzzahl | Bezeichnet die Service-Level-Sekunden |
| scheduled_average_speed_of_answer | float | Bezeichnet die durchschnittliche Antwortgeschwindigkeit |
| is_deleted | boolesch | Gibt an, ob die Metrik gelöscht wurde |
| last_updated_timestamp | Zeitstempel | Der Zeitstempel, zu dem der Metrikdatensatz erstellt wurde. |
| data_lake_last_processed_timestamp | Zeitstempel | Zeitstempel, der anzeigt, wann der Data Lake den Datensatz zuletzt verarbeitet hat. Dies kann Transformation und Backfill beinhalten. Dieses Feld kann nicht verwendet werden, um die Aktualität der Daten zuverlässig zu bestimmen. |
Ziele planen
Tabellenname: schedule_goals
Zusammengesetzter Primärschlüssel: {instance_id, goal_id}
| Spalte | Typ | Description |
|---|---|---|
| instance_id | Zeichenfolge | Der ARN der Amazon-Connect-Instance. |
| instance_arn | Zeichenfolge | Die ID der Amazon-Connect-Instance. |
| goal_id | Zeichenfolge | Eindeutiger Bezeichner für den Zielwert |
| aws_account_id | Zeichenfolge | Die ID des AWS-Kontos. |
| entity_type | Zeichenfolge | Gibt an, ob das Ziel für eine Prognosegruppe oder eine Bedarfsgruppe bestimmt ist. |
| entity_arn | Zeichenfolge | Arn der Prognosegruppe oder Nachfragegruppe |
| channel | Zeichenfolge | Bezeichnet den Medienkanal wie Voice, Chat. |
| start_date_timestamp | Zeitstempel | Zeitstempel, der den Beginn des Ziels angibt |
| end_date_timestamp | Zeitstempel | Zeitstempel, der das Ende des Ziels angibt |
| goal_service_level_percentage | float | Bezeichnet den angestrebten Prozentsatz des Servicelevels |
| goal_service_level_seconds | Ganzzahl | Bezeichnet die Service-Level-Sekunden |
| goal_average_speed_of_answer | float | Bezeichnet die durchschnittliche Antwortgeschwindigkeit |
| is_deleted | boolesch | Gibt an, ob das Ziel gelöscht wurde |
| last_updated_timestamp | Zeitstempel | Der Zeitstempel, zu dem der Zieldatensatz erstellt wurde. |
| data_lake_last_processed_timestamp | Zeitstempel | Zeitstempel, der anzeigt, wann der Data Lake den Datensatz zuletzt verarbeitet hat. Dies kann Transformation und Backfill beinhalten. Dieses Feld kann nicht verwendet werden, um die Aktualität der Daten zuverlässig zu bestimmen. |
Rotationsmuster verschieben
Tabellenname: shift_rotation_patterns
Zusammengesetzter Primärschlüssel: {instance_id, shift_rotation_pattern_arn,
shift_rotation_pattern_version}
| Spalte | Typ | Description |
|---|---|---|
| instance_id | Zeichenfolge | Die ID der Connect Customer-Instanz. |
| shift_rotation_pattern_arn | Zeichenfolge | Der ARN des Schichtrotationsmusters. |
| shift_rotation_pattern_version | bigint | Die Version des Shift-Rotationsmusters. |
| instance_arn | Zeichenfolge | Der ARN der Connect Customer-Instanz. |
| shift_rotation_pattern_name | Zeichenfolge | Der Name des Schaltrotationsmusters. |
| start_date | Zeichenfolge | Das Startdatum des Schichtrotationsmusters im yyyy-mm-dd Format. |
| is_deleted | Boolesch | Auf True setzen, wenn das Schichtrotationsmuster gelöscht wird. Andernfalls lautet der Wert False. |
| last_updated_by | Zeichenfolge | Der ARN des Benutzers, der das Shift Rotation Pattern created/updated /gelöscht hat. |
| last_updated_timestamp | Zeitstempel | Der Zeitstempel, zu dem das Schichtrotationsmuster /gelöscht wurde. created/updated |
| data_lake_last_processed_timestamp | Zeitstempel | Der Zeitstempel, der anzeigt, wann der Data Lake sich das letzte Mal mit dem Datensatz beschäftigt hat. Dies kann Transformation und Backfill beinhalten. Dieses Feld kann nicht verwendet werden, um die Aktualität der Daten zuverlässig zu bestimmen. |
Schritte für die Umschaltrotation
Tabellenname: shift_rotation_steps
Zusammengesetzter Primärschlüssel: {instance_id, shift_rotation_pattern_arn,
shift_rotation_pattern_version, step_id}
Diese Tabelle sollte abgefragt werden, indem sie mit der Tabelle shift_rotation_patterns zu shift_rotation_pattern_arn und shift_rotation_pattern_version verknüpft wird.
| Spalte | Typ | Description |
|---|---|---|
| instance_id | Zeichenfolge | Die ID der Connect Customer-Instanz. |
| shift_rotation_pattern_arn | Zeichenfolge | Der ARN des Schichtrotationsmusters. |
| shift_rotation_pattern_version | bigint | Die Version des Shift-Rotationsmusters. |
| step_id | bigint | Die ID des Schritts innerhalb des Schichtrotationsmusters. Die Schritte werden fortlaufend nummeriert (1, 2, 3,... bis zu 52). |
| instance_arn | Zeichenfolge | Der ARN der Connect Customer-Instanz. |
| shift_profile_arn | Zeichenfolge | Der ARN des Schichtprofils, das dem Rotationsschritt zugeordnet ist. |
| duration | bigint | Die Dauer des Rotationsschritts in Wochen. |
| is_deleted | Boolesch | Wird auf False gesetzt, wenn der Shift Rotation Step gültig ist. |
| last_updated_by | Zeichenfolge | Der ARN des Benutzers, der created/updated das Shift Rotation Pattern hat. |
| last_updated_timestamp | Zeitstempel | Der Zeitstempel, zu dem das Schichtrotationsmuster verwendet wurde created/updated. |
| data_lake_last_processed_timestamp | Zeitstempel | Der Zeitstempel, der anzeigt, wann der Data Lake sich das letzte Mal mit dem Datensatz beschäftigt hat. Dies kann Transformation und Backfill beinhalten. Dieses Feld kann nicht verwendet werden, um die Aktualität der Daten zuverlässig zu bestimmen. |
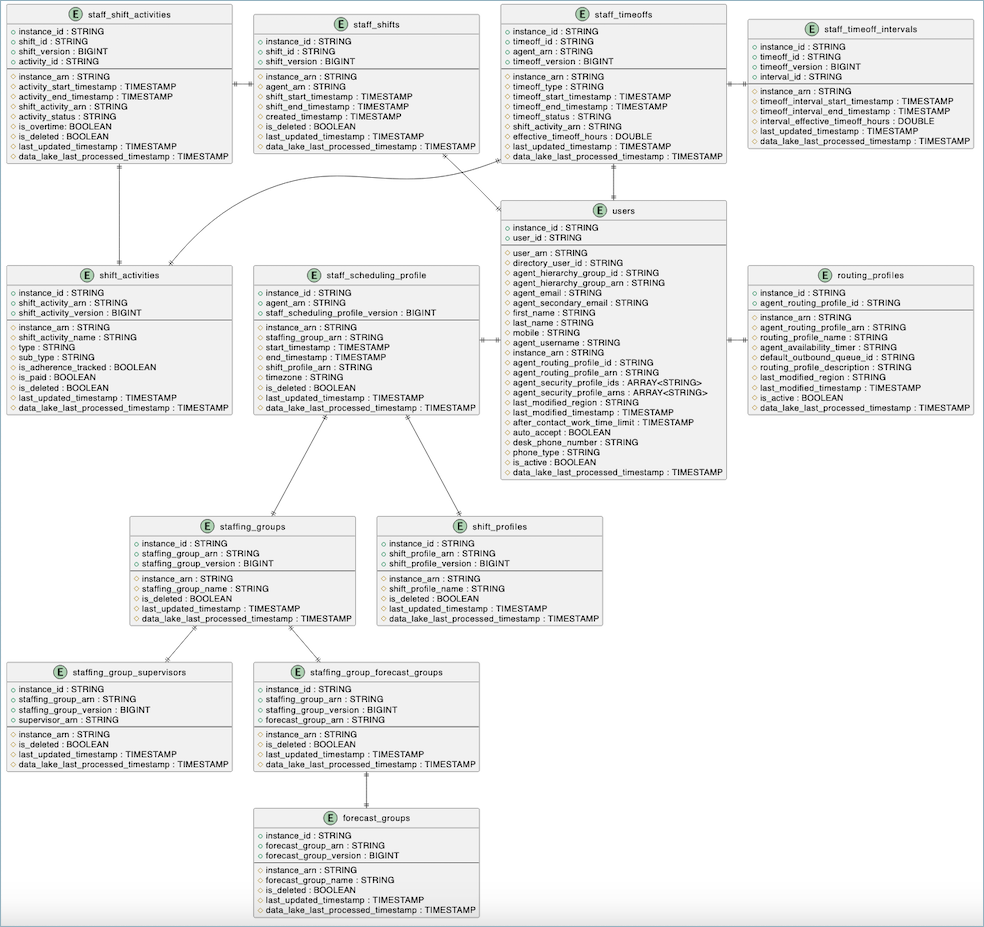
Datenschema
Im Folgenden finden Sie ein Entitätsbeziehungsdiagramm, das die Struktur und die Beziehungen zwischen Planungstabellen im Connect Customer-Datensee zeigt.
In jeder Tabelle werden ihre Primärschlüssel und Attribute mit ihren Datentypen angezeigt. Das Diagramm veranschaulicht, wie diese Tabellen durch Fremdschlüsselbeziehungen zueinander in Beziehung stehen, und bietet so einen umfassenden Überblick über das Planungsdatenmodell.
Beispielabfragen
1. Abfrage, um alle geplanten Schichtaktivitäten von Kundendienstmitarbeitern abzurufen, die an einer bestimmten Prognosegruppe arbeiten
SELECT * FROM agent_scheduled_shift_activities_view
where forecast_group_name = 'AnyDepartmentForecastGroup'
Führen Sie die folgenden Schritte aus, um die oben genannte agent_scheduled_shift_activities_view zu erstellen.
Schritt 1: Erstellen Sie eine Ansicht, um die Namen der Supervisoren abzurufen.
CREATE OR REPLACE VIEW "latest_supervisor_names_view" AS SELECT staffing_group_arn , array_agg(supervisor_name ORDER BY supervisor_name ASC) supervisor_names FROM ( SELECT s.staffing_group_arn , CONCAT(u.first_name, ' ', u.last_name) supervisor_name FROM (( SELECT staffing_group_arn , supervisor_arn FROM ( SELECT * , RANK() OVER (PARTITION BY staffing_group_arn ORDER BY staffing_group_version DESC) recency FROM staffing_group_supervisors WHERE (instance_id = 'YourAmazonConnectInstanceId') ) t WHERE (recency = 1) ) s INNER JOIN USERS u ON (s.supervisor_arn = u.user_arn)) ) GROUP BY staffing_group_arn
Schritt 2: Erstellen Sie eine Ansicht, um die Personalgruppe und die Prognosegruppe abzurufen, die einem Kundendienstmitarbeiter zugeordnet sind.
CREATE OR REPLACE VIEW "latest_agent_staffing_group_forecast_group_view" AS WITH latest_staff_scheduling_profile AS ( SELECT agent_arn , staffing_group_arn , last_updated_timestamp FROM ( SELECT * , RANK() OVER (PARTITION BY agent_arn ORDER BY staff_scheduling_profile_version DESC) recency FROM staff_scheduling_profile WHERE ((instance_id = 'YourAmazonConnectInstanceId') AND (is_deleted = false)) ) t WHERE (recency = 1) ) , latest_staffing_groups AS ( SELECT staffing_group_name , staffing_group_arn FROM ( SELECT * , RANK() OVER (PARTITION BY staffing_group_arn ORDER BY staffing_group_version DESC) recency FROM staffing_groups WHERE (instance_id = 'YourAmazonConnectInstanceId') ) t WHERE (recency = 1) ) , latest_forecast_groups AS ( SELECT forecast_group_arn , forecast_group_name FROM ( SELECT * , RANK() OVER (PARTITION BY forecast_group_arn ORDER BY forecast_group_version DESC) recency FROM forecast_groups WHERE (instance_id = 'YourAmazonConnectInstanceId') ) t WHERE (recency = 1) ) , latest_staffing_group_forecast_groups AS ( SELECT staffing_group_arn , forecast_group_arn FROM ( SELECT * , RANK() OVER (PARTITION BY staffing_group_arn ORDER BY staffing_group_version DESC) recency FROM staffing_group_forecast_groups WHERE (instance_id = 'YourAmazonConnectInstanceId') ) t WHERE (recency = 1) ) SELECT ssp.agent_arn , U.agent_username AS username , U.agent_routing_profile_id AS routing_profile_id , CONCAT(u.first_name, ' ', u.last_name) agent_name , fg.forecast_group_arn , fg.forecast_group_name , sg.staffing_group_arn , sg.staffing_group_name FROM latest_staff_scheduling_profile ssp INNER JOIN latest_staffing_groups sg ON ssp.staffing_group_arn = sg.staffing_group_arn INNER JOIN latest_staffing_group_forecast_groups sgfg ON ssp.staffing_group_arn = sgfg.staffing_group_arn INNER JOIN latest_forecast_groups fg ON fg.forecast_group_arn = sgfg.forecast_group_arn INNER JOIN USERS u ON ssp.agent_arn = u.user_arn
Schritt 3: Rufen Sie die neuesten Schichtaktivitäten ab.
CREATE OR REPLACE VIEW "latest_shift_activities_view" AS SELECT shift_activity_arn , shift_activity_name , shift_activity_version , type , sub_type , is_adherence_tracked , is_paid , last_updated_timestamp FROM ( SELECT * , RANK() OVER (PARTITION BY shift_activity_arn ORDER BY shift_activity_version DESC) recency FROM shift_activities WHERE (instance_id = 'YourAmazonConnectInstanceId') ) t WHERE (recency = 1)
Schritt 4: Erstellen Sie eine Ansicht, um die für den Kundendienstmitarbeiter geplanten Schichtaktivitäten abzurufen.
CREATE OR REPLACE VIEW "agent_scheduled_shift_activities_view" AS WITH latest_staff_shifts AS ( SELECT agent_arn , shift_id , shift_version , shift_start_timestamp , shift_end_timestamp , created_timestamp , last_updated_timestamp , data_lake_last_processed_timestamp , recency FROM ( SELECT RANK() OVER (PARTITION BY shift_id ORDER BY shift_version DESC) recency , * FROM staff_shifts sa WHERE (instance_id = 'YourAmazonConnectInstanceId') ) t WHERE ((recency = 1) AND (is_deleted = false)) ) SELECT asgfg.forecast_group_name , array_join(sn.supervisor_names, ',') supervisor_names , s.agent_arn , u.first_name , u.last_name , asgfg.staffing_group_name , ssa.activity_id , (CASE WHEN (ssa.shift_activity_arn IS NULL) THEN COALESCE(sa.shift_activity_name, 'Work') ELSE sa.shift_activity_name END) shift_activity_name , s.shift_start_timestamp , s.shift_end_timestamp , (CASE WHEN (ssa.shift_activity_arn IS NULL) THEN COALESCE(sa.type, 'PRODUCTIVE') ELSE sa.type END) type , (CASE WHEN (ssa.shift_activity_arn IS NULL) THEN COALESCE(sa.is_paid, true) ELSE sa.is_paid END) is_paid , ssa.activity_start_timestamp , ssa.activity_end_timestamp , ssa.last_updated_timestamp , ssa.data_lake_last_processed_timestamp , u.agent_username as username , u.agent_routing_profile_id as routing_profile_id FROM staff_shift_activities ssa INNER JOIN latest_staff_shifts s ON s.shift_id = ssa.shift_id AND s.shift_version = ssa.shift_version INNER JOIN USERS u ON s.agent_arn = u.user_arn INNER JOIN latest_agent_staffing_group_forecast_group_view asgfg ON s.agent_arn = asgfg.agent_arn LEFT JOIN latest_shift_activities_view sa ON sa.shift_activity_arn = ssa.shift_activity_arn INNER JOIN latest_supervisor_names_view sn ON sn.staffing_group_arn = asgfg.staffing_group_arn WHERE (ssa.is_deleted = false) AND (COALESCE(ssa.activity_status, ' ') <> 'INACTIVE') AND (ssa.instance_id = 'YourAmazonConnectInstanceId')
2. Abfrage, um alle Urlaubsanträge der Kundendienstmitarbeiter in einer bestimmten Prognosegruppe abzurufen
SELECT * FROM agent_timeoff_report_view where forecast_group_name =
'AnyDepartmentForecastGroup'
Verwenden Sie die folgende Abfrage, um die oben genannte agent_timeoff_report_view zu erstellen.
CREATE OR REPLACE VIEW "agent_timeoff_report_view" AS WITH latest_staff_timeoffs AS ( SELECT t1.*, CAST((t1.effective_timeoff_hours * 60) AS INT) total_effective_timeoff_minutes FROM ( SELECT RANK() OVER ( PARTITION BY timeoff_id ORDER BY timeoff_version DESC ) recency, agent_arn, timeoff_id, shift_activity_arn, timeoff_status, timeoff_version, effective_timeoff_hours, timeoff_start_timestamp, timeoff_end_timestamp, last_updated_timestamp, data_lake_last_processed_timestamp FROM staff_timeoffs WHERE ( instance_id = 'YourAmazonConnectInstanceId' ) ) t1 WHERE (recency = 1) ) SELECT asgfg.forecast_group_name, to.agent_arn, asgfg.agent_name, asgfg.staffing_group_name, asgfg.username, sa.shift_activity_name, to.timeoff_start_timestamp, to.timeoff_end_timestamp, to.timeoff_status, array_join(sn.supervisor_names, ',') AS supervisor_names, sa.is_paid, to.last_updated_timestamp, to.data_lake_last_processed_timestamp, u.agent_routing_profile_id AS routing_profile_id, to.timeoff_id, to.shift_activity_arn, to.total_effective_timeoff_minutes FROM latest_staff_timeoffs to INNER JOIN latest_agent_staffing_group_forecast_group_view asgfg ON asgfg.agent_arn = to.agent_arn INNER JOIN latest_shift_activities_view sa ON sa.shift_activity_arn = to.shift_activity_arn INNER JOIN latest_supervisor_names_view sn ON sn.staffing_group_arn = asgfg.staffing_group_arn INNER JOIN users u ON u.user_arn = to.agent_arn
