Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Überwachen einer globalen Amazon-Aurora-Datenbank
Wenn Sie die Aurora-DB-Cluster erstellen, aus denen Ihre Aurora globale Datenbank besteht, können Sie viele Optionen auswählen, mit denen Sie die Leistung Ihres DB-Clusters überwachen können. Diese Optionen umfassen Folgendes:
Amazon RDS Performance Insights – Es ermöglicht Performance-Schema in der zugrunde liegenden Aurora-Datenbank-Engine. Weitere Informationen über Performance Insights und Aurora globale Datenbanken finden Sie unter Überwachung einer Amazon Aurora globalen Datenbank mit Amazon RDS Performance Insights.
„Enhanced Monitoring“ (Erweiterte Überwachung) – Es generiert Metriken für die Prozess- oder Thread-Nutzung auf der CPU. Weitere Informationen zur erweiterten Überwachung finden Sie unter Überwachen von Betriebssystem-Metriken mithilfe von „Enhanced Monitoring“·(Erweiterte·Überwachung).
Amazon CloudWatch Logs — Veröffentlicht bestimmte Protokolltypen in CloudWatch Logs. Fehlerprotokolle werden standardmäßig veröffentlicht. Sie können jedoch andere für Ihre Aurora-Datenbank-Engine spezifische Protokolle auswählen.
Für Aurora MySQL–basierte Aurora-DB-Cluster können Sie das Audit-Log, das allgemeine Protokoll und das langsame Abfrage-Log exportieren.
Für Aurora PostgreSQL–basierte Aurora-DB-Cluster können Sie das PostgreSQL-Protokoll exportieren.
Für Aurora-MySQL-basierte globale Datenbanken können Sie bestimmte
information_schema-Tabellen verwenden, um den Status Ihrer globalen Aurora-Datenbank und deren Instances zu überprüfen. Um zu erfahren wie dies geht, vgl. Überwachung der MySQL-based globalen Aurora-Datenbanken.Für Aurora-PostgreSQL-basierte globale Datenbanken können Sie bestimmte Funktionen verwenden, um den Status Ihrer Aurora globalen Datenbank und ihrer Instances zu überprüfen. Um zu erfahren wie, siehe Überwachung der PostgreSQL-based globalen Aurora-Datenbanken.
Der folgende Screenshot zeigt einige der Optionen, die auf der Registerkarte Überwachung eines primären Aurora-DB-Clusters in einer Aurora globalen Datenbank verfügbar sind.
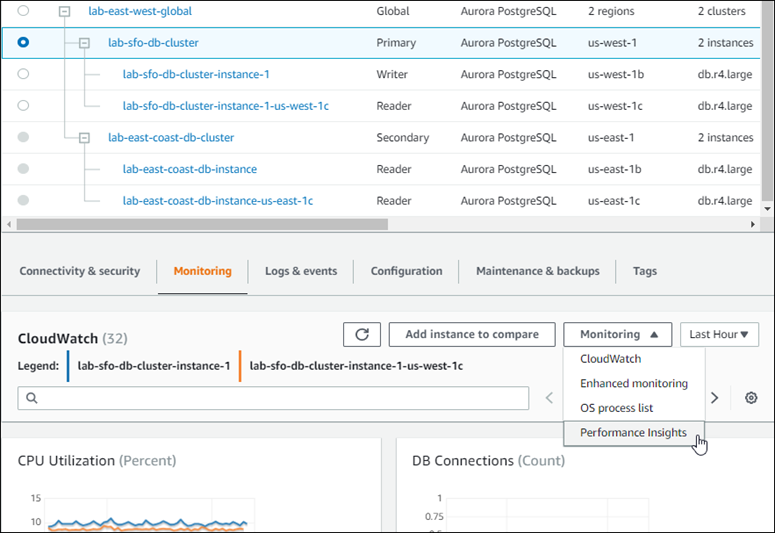
Weitere Informationen finden Sie unter Überwachung von Metriken in einem Amazon-Aurora-Cluster.
Überwachung einer Amazon Aurora globalen Datenbank mit Amazon RDS Performance Insights
Sie können Amazon RDS Performance Insights für Ihre globalen Aurora-Datenbanken verwenden. Sie aktivieren diese Funktion einzeln für jeden Aurora-DB-Cluster in Ihrer Aurora globalen Datenbank. Dazu wählen Sie Performance Insights aktivieren im Abschnitt Zusätzliche Konfiguration der Seite „Datenbank erstellen“. Oder Sie können Ihre Aurora-DB-Cluster ändern, um diese Funktion zu verwenden, nachdem sie in Betrieb sind. Sie können Performance Insights für jeden Cluster, der zur Aurora globalen Datenbank gehört, aktivieren bzw. deaktivieren.
Die von Performance Insights erstellten Berichte gelten für jeden Cluster in der globalen Datenbank. Wenn Sie einer globalen Aurora-Datenbank AWS-Region , die bereits Performance Insights verwendet, eine neue Sekundärdatenbank hinzufügen, stellen Sie sicher, dass Sie Performance Insights im neu hinzugefügten Cluster aktivieren. Die Performance-Insights-Einstellung wird nicht von der vorhandenen globalen Datenbank übernommen.
Sie können wechseln, AWS-Regionen während Sie die Performance Insights Insights-Seite für eine DB-Instance aufrufen, die an eine globale Datenbank angehängt ist. Möglicherweise werden Ihnen jedoch unmittelbar nach dem Wechsel keine Leistungsinformationen angezeigt AWS-Regionen. Obwohl die DB-Instances in jeder DB-Instance identische Namen haben können AWS-Region, ist die zugehörige Performance Insights Insights-URL für jede DB-Instance unterschiedlich. Wählen Sie nach dem Umschalten AWS-Regionen erneut den Namen der DB-Instance im Performance Insights Insights-Navigationsbereich aus.
Für DB-Instances, die einer globalen Datenbank zugeordnet sind, können sich in jeder AWS-Region andere Faktoren auf die Leistung auswirken. Beispielsweise AWS-Region können die DB-Instances in jeder Instanz unterschiedliche Kapazitäten haben.
Weitere Informationen zum Verwenden von Performance Insights finden Sie unter Überwachung der Datenbanklast mit eingeschaltetem Performance Insights Amazon Aurora.
Überwachung von globalen Aurora-Datenbanken mithilfe von Datenbank-Aktivitätsstreams
Durch die Verwendung von Datenbank-Aktivitätsstreams können Sie Alarme für die Prüfung von Aktivitäten in den DB-Clustern Ihrer globalen Datenbank überwachen und einstellen. Sie starten einen Datenbank-Aktivitätsstream separat auf jedem DB-Cluster. Jeder Cluster liefert Auditdaten innerhalb seiner eigenen AWS-Region an seinen eigenen Kinesis-Stream. Weitere Informationen finden Sie unter Überwachen Amazon Aurora mit Datenbank-Aktivitätsstreams.
Überwachung der MySQL-based globalen Aurora-Datenbanken
Um den Status einer MySQL-based globalen Aurora-Datenbank anzuzeigen, fragen Sie die information_schema.aurora_global_db_instance_status Tabellen information_schema.aurora_global_db_status und ab.
Anmerkung
Die information_schema.aurora_global_db_instance_status Tabellen information_schema.aurora_global_db_status und sind nur mit Aurora MySQL Version 3.04.0 und höher und Version 8.4 und höher, globalen Datenbanken, verfügbar.
Um eine MySQL-based globale Aurora-Datenbank zu überwachen
-
Stellen Sie mithilfe eines MySQL-Clients eine Verbindung zum primären Cluster-Endpunkt der globalen Datenbank her. Weitere Informationen zum Herstellen einer Verbindung finden Sie unter Verbinden mit Amazon Aurora Global Database.
-
Fragen Sie die Tabelle
information_schema.aurora_global_db_statusin einem mysql-Befehl ab, um die primären und sekundären Volumes aufzulisten. Diese Abfrage gibt die Verzögerungszeiten der sekundären DB-Cluster der globalen Datenbank zurück, wie im folgenden Beispiel dargestellt.mysql> select * from information_schema.aurora_global_db_status;AWS_REGION | HIGHEST_LSN_WRITTEN | DURABILITY_LAG_IN_MILLISECONDS | RPO_LAG_IN_MILLISECONDS | LAST_LAG_CALCULATION_TIMESTAMP | OLDEST_READ_VIEW_TRX_ID -----------+---------------------+--------------------------------+------------------------+---------------------------------+------------------------ us-east-1 | 183537946 | 0 | 0 | 1970-01-01 00:00:00.000000 | 0 us-west-2 | 183537944 | 428 | 0 | 2023-02-18 01:26:41.925000 | 20806982 (2 rows)Die Ausgabe enthält eine Zeile für jeden DB-Cluster der globalen Datenbank, die die folgenden Spalten enthält:
-
AWS_REGION — Die AWS-Region , in der sich dieser DB-Cluster befindet. Eine nach Engine aufgelistete Tabellen finden Sie AWS-Regionen unter. Verfügbarkeit in Regionen
-
HIGHEST_LSN_WRITTEN – die höchste Log-Sequenznummer (LSN), die derzeit auf diesem DB-Cluster geschrieben wird.
Eine Log-Sequenznummer (LSN) ist eine eindeutige fortlaufende Nummer, die einen Datensatz im Datenbank-Transaktionsprotokoll identifiziert. LSNs werden so angeordnet, dass eine größere LSN eine spätere Transaktion darstellt.
-
DURABILITY_LAG_IN_MILLISECONDS – die Differenz der Zeitstempelwerte zwischen
HIGHEST_LSN_WRITTENin einem sekundären DB-Cluster undHIGHEST_LSN_WRITTENim primären DB-Cluster. Der Wert ist immer 0 im primären DB-Cluster der globalen Aurora-Datenbank. -
RPO_LAG_IN_MILLISECONDS – die Verzögerung des Zeitraums im Hinblick auf Recovery Point Objective (RPO). Die RPO-Verzögerung ist die Zeit, die benötigt wird, bis die letzte Benutzertransaktion COMMIT auf einem sekundären DB-Cluster gespeichert wird, nachdem sie auf dem primären DB-Cluster einer globalen Aurora-Datenbank abgelegt wurde. Der Wert ist immer 0 im primären DB-Cluster der globalen Aurora-Datenbank.
Einfach ausgedrückt berechnet diese Metrik das Recovery Point Objective für jeden DB-Cluster voon Aurora MySQL in der globalen Aurora-Datenbank, d. h., wie viele Daten bei einem Ausfall verloren gehen könnten. Wie die Verzögerung wird auch RPO zeitlich gemessen.
-
LAST_LAG_CALCULATION_TIMESTAMP – der Zeitstempel mit Angabe des Zeitpunkts, zu dem die Werte für
DURABILITY_LAG_IN_MILLISECONDSundRPO_LAG_IN_MILLISECONDSzuletzt berechnet wurden. Ein Zeitwert wie1970-01-01 00:00:00+00bedeutet, dass dies der primäre DB-Cluster ist. -
OLDEST_READ_VIEW_TRX_ID – die ID der ältesten Transaktion, bis zu der die Writer-DB-Instance Daten löschen kann.
-
-
Fragen Sie die Tabelle
information_schema.aurora_global_db_instance_statusab, um alle sekundären DB-Instances sowohl für den primären DB-Cluster als auch für sekundäre DB-Cluster aufzulisten.mysql> select * from information_schema.aurora_global_db_instance_status;SERVER_ID | SESSION_ID | AWS_REGION | DURABLE_LSN | HIGHEST_LSN_RECEIVED | OLDEST_READ_VIEW_TRX_ID | OLDEST_READ_VIEW_LSN | VISIBILITY_LAG_IN_MSEC ---------------------+--------------------------------------+------------+-------------+----------------------+-------------------------+----------------------+------------------------ ams-gdb-primary-i2 | MASTER_SESSION_ID | us-east-1 | 183537698 | 0 | 0 | 0 | 0 ams-gdb-secondary-i1 | cc43165b-bdc6-4651-abbf-4f74f08bf931 | us-west-2 | 183537689 | 183537692 | 20806928 | 183537682 | 0 ams-gdb-secondary-i2 | 53303ff0-70b5-411f-bc86-28d7a53f8c19 | us-west-2 | 183537689 | 183537692 | 20806928 | 183537682 | 677 ams-gdb-primary-i1 | 5af1e20f-43db-421f-9f0d-2b92774c7d02 | us-east-1 | 183537697 | 183537698 | 20806930 | 183537691 | 21 (4 rows)Die Ausgabe enthält eine Zeile für jede DB-Instance der globalen Datenbank, die die folgenden Spalten enthält:
-
SERVER_ID – die Server-ID für die DB-Instance.
-
SESSION_ID – eine eindeutige ID für die aktuelle Sitzung. Der Wert
MASTER_SESSION_IDbezeichnet die (primäre) Writer-DB-Instance. -
AWS_REGION — Die AWS-Region , in der sich diese DB-Instance befindet. Eine nach Engine aufgelistete Tabellen finden Sie AWS-Regionen unter. Verfügbarkeit in Regionen
-
DURABLE_LSN – die LSN, die im Speicher als dauerhaft definiert wurde.
-
HIGHEST_LSN_RECEIVED – die höchste LSN, die die DB-Instance von der DB-Writer-Instance empfangen hat.
-
OLDEST_READ_VIEW_TRX_ID – die ID der ältesten Transaktion, bis zu der die Writer-DB-Instance Daten löschen kann.
-
OLDEST_READ_VIEW_LSN – die älteste LSN, die von der DB-Instance zum Lesen aus dem Speicher verwendet wird.
-
VISIBILITY_LAG_IN_MSEC – für Reader im primären DB-Cluster, wie weit diese DB-Instance der Writer-DB-Instance in Millisekunden hinterherhinkt. Für Reader in einem sekundären DB-Cluster, wie weit diese DB-Instance dem sekundären Volume in Millisekunden hinterherhinkt.
-
Um zu sehen, wie sich diese Werte im Laufe der Zeit verändern, betrachten Sie den folgenden Transaktionsblock, in dem eine Tabelleneinfügung eine Stunde dauert.
mysql> BEGIN;
mysql> INSERT INTO table1 SELECT Large_Data_That_Takes_1_Hr_To_Insert;
mysql> COMMIT;
In einigen Fällen kann es nach der BEGIN-Anweisung zu einer Netzwerktrennung zwischen dem primären DB-Cluster und dem sekundären DB-Cluster kommen. In diesem Fall beginnt der Wert DURABILITY_LAG_IN_MILLISECONDS des sekundäre DB-Clusters zu steigen. Am Ende der INSERT-Anweisung beträgt der Wert DURABILITY_LAG_IN_MILLISECONDS 1 Stunde. Der Wert RPO_LAG_IN_MILLISECOND ist jedoch 0, da alle Benutzerdaten, die zwischen dem primären DB-Cluster und dem sekundären DB-Cluster übertragen werden, immer noch dieselben sind. Sobald die COMMIT-Anweisung abgeschlossen ist, steigt der Wert RPO_LAG_IN_MILLISECONDSWert steigt.
Überwachung der PostgreSQL-based globalen Aurora-Datenbanken
Verwenden Sie die aurora_global_db_instance_status Funktionen aurora_global_db_status und, um den Status einer PostgreSQL-based globalen Aurora-Datenbank anzuzeigen.
Anmerkung
Die Funktionen aurora_global_db_status und aurora_global_db_instance_status werden nur von Aurora PostgreSQL unterstützt.
Um eine PostgreSQL-based globale Aurora-Datenbank zu überwachen
-
Stellen Sie mithilfe eines PostgreSQL-Dienstprogramms wie psql eine Verbindung zum primären Cluster-Endpunkt der globalen Datenbank her. Weitere Informationen zum Herstellen einer Verbindung finden Sie unter Verbinden mit Amazon Aurora Global Database.
-
Sie verwenden die Funktion
aurora_global_db_statusin einem psql-Befehl, um die primären und sekundären Volumes aufzulisten. Dadurch werden die Verzögerungszeiten der sekundären DB-Cluster der globalen Datenbank angezeigt.postgres=> select * from aurora_global_db_status();aws_region | highest_lsn_written | durability_lag_in_msec | rpo_lag_in_msec | last_lag_calculation_time | feedback_epoch | feedback_xmin ------------+---------------------+------------------------+-----------------+----------------------------+----------------+--------------- us-east-1 | 93763984222 | -1 | -1 | 1970-01-01 00:00:00+00 | 0 | 0 us-west-2 | 93763984222 | 900 | 1090 | 2020-05-12 22:49:14.328+00 | 2 | 3315479243 (2 rows)Die Ausgabe enthält eine Zeile für jeden DB-Cluster der globalen Datenbank, die die folgenden Spalten enthält:
-
aws_region — Die AWS-Region , in der sich dieser DB-Cluster befindet. Eine nach Engine aufgelistete Tabellen finden Sie AWS-Regionen unter. Verfügbarkeit in Regionen
-
highest_lsn_written – Die höchste Log-Sequenznummer (LSN), die derzeit auf diesem DB-Cluster geschrieben wird.
Eine Log-Sequenznummer (LSN) ist eine eindeutige fortlaufende Nummer, die einen Datensatz im Datenbank-Transaktionsprotokoll identifiziert. LSNs werden so angeordnet, dass eine größere LSN eine spätere Transaktion darstellt.
-
durability_lag_in_msec – Die Zeitstempeldifferenz zwischen der höchsten Log-Sequenznummer, die auf einem sekundären DB-Cluster (
highest_lsn_written) geschrieben wurde, und derhighest_lsn_writtenauf dem primären DB-Cluster. -
rpo_lag_in_msec – Die Verzögerung des Zeitraums zwischen zwei Datensicherungen (RPO). Diese Verzögerung ist die Zeitdifferenz zwischen dem letzten Benutzertransaktions-Commit, der auf einem sekundären DB-Cluster gespeichert ist, und dem letzten Benutzertransaktions-Commit, der auf dem primären DB-Cluster gespeichert ist.
-
last_lag_calculation_time – Der Zeitstempel mit Angabe des Zeitpunkts, zu dem die Werte für
durability_lag_in_msecundrpo_lag_in_mseczuletzt berechnet wurden. -
feedback_epoch – Die Epoche, die ein sekundärer DB-Cluster beim Erzeugen von Hot-Standby-Informationen verwendet.
Hot-Standby bedeutet, dass ein DB-Cluster eine Verbindung herstellen und Abfragen durchführen kann, während sich der Server im Wiederherstellungs- oder Standby-Modus befindet. Hot-Standby-Feedbacks sind Informationen über den DB-Cluster, wenn dieser sich im Hot-Standby-Modus befindet. Weitere Informationen finden Sie in der PostgreSQL-Dokumentation zu Hot Standby
. -
feedback_xmin – Die minimale (älteste) aktive Transaktions-ID, die von einem sekundären DB-Cluster verwendet wird.
-
-
Verwenden Sie die Funktion
aurora_global_db_instance_status, um alle sekundären DB-Instances sowohl für den primären DB-Cluster als auch für sekundäre DB-Cluster aufzulisten.postgres=> select * from aurora_global_db_instance_status();server_id | session_id | aws_region | durable_lsn | highest_lsn_rcvd | feedback_epoch | feedback_xmin | oldest_read_view_lsn | visibility_lag_in_msec --------------------------------------------+--------------------------------------+------------+-------------+------------------+----------------+---------------+----------------------+------------------------ apg-global-db-rpo-mammothrw-elephantro-1-n1 | MASTER_SESSION_ID | us-east-1 | 93763985102 | | | | | apg-global-db-rpo-mammothrw-elephantro-1-n2 | f38430cf-6576-479a-b296-dc06b1b1964a | us-east-1 | 93763985099 | 93763985102 | 2 | 3315479243 | 93763985095 | 10 apg-global-db-rpo-elephantro-mammothrw-n1 | 0d9f1d98-04ad-4aa4-8fdd-e08674cbbbfe | us-west-2 | 93763985095 | 93763985099 | 2 | 3315479243 | 93763985089 | 1017 (3 rows)Die Ausgabe enthält eine Zeile für jede DB-Instance der globalen Datenbank, die die folgenden Spalten enthält:
-
server_id – Die Server-ID für die DB-Instance.
-
session_id – Eine eindeutige ID für die aktuelle Sitzung.
-
aws_region — Die AWS-Region , in der sich diese DB-Instance befindet. Eine nach Engine aufgelistete Tabellen finden Sie AWS-Regionen unter. Verfügbarkeit in Regionen
-
durable_lsn – Der LSN wurde im Speicher dauerhaft gemacht.
-
highest_lsn_rcvd – Die höchste LSN, die die DB-Instance von der DB-Writer-Instance empfangen hat.
-
feedback_epoch – Die Epoche, die die DB-Instance beim Erzeugen der Hot-Standby-Informationen verwendet.
Hot standby bedeutet, dass eine DB-Instance eine Verbindung herstellen und Abfragen durchführen kann, während sich der Server im Wiederherstellungs- oder Standby-Modus befindet. Hot-Standby-Feedbacks sind Informationen über die DB-Instance, wenn diese sich im Hot-Standby-Modus befindet. Weitere Informationen finden Sie in der PostgreSQL-Dokumentation zu Hot Standby
. -
feedback_xmin – Die minimale (älteste) aktive Transaktions-ID, die von der DB-Instance verwendet wird.
-
oldest_read_view_lsn – Die älteste LSN, die von der DB-Instance zum Lesen aus dem Speicher verwendet wird.
-
visibility_lag_in_msec – Wie stark diese DB-Instance gegenüber der DB-Schreiber-Instance zeitlich verzögert ist.
-
Um zu sehen, wie sich diese Werte im Laufe der Zeit verändern, betrachten Sie den folgenden Transaktionsblock, in dem eine Tabelleneinfügung eine Stunde dauert.
psql> BEGIN;
psql> INSERT INTO table1 SELECT Large_Data_That_Takes_1_Hr_To_Insert;
psql> COMMIT;In einigen Fällen kann es nach der BEGIN-Anweisung zu einer Netzwerktrennung zwischen dem primären DB-Cluster und dem sekundären DB-Cluster kommen. Wenn dies der Fall ist, beginnt sich der durability_lag_in_msec-Wert des sekundären DB-Clusters zu erhöhen. Am Ende der INSERT-Anweisung beträgt der durability_lag_in_msec-Wert 1 Stunde. Der Wert rpo_lag_in_msec ist jedoch 0, da alle Benutzerdaten, die zwischen dem primären DB-Cluster und dem sekundären DB-Cluster übertragen werden, immer noch dieselben sind. Sobald die COMMIT-Anweisung abgeschlossen ist, erhöht sich der rpo_lag_in_msec-Wert.
