Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Verbinden mit Amazon Aurora Global Database
Jede globale Aurora-Datenbank verfügt über einen Writer-Endpunkt, der automatisch von Aurora aktualisiert wird, um Anfragen an die aktuelle Writer-Instance des primären DB-Clusters weiterzuleiten. Mit dem Writer-Endpunkt müssen Sie Ihre Verbindungszeichenfolge nicht ändern, nachdem Sie den Standort der primären Region mithilfe der verwalteten Umstellungs- und Failover-Funktionen von Aurora Global Database geändert haben. Weitere Informationen zur Verwendung des Writer-Endpunkts zusammen mit den Umstellungs- und Failover-Funktionen von Aurora Global Database finden Sie unter Verwenden von Umstellung oder Failover in Amazon Aurora Global Database. Informationen zum Verbinden mit einer globalen Aurora-Datenbank über RDS-Proxy finden Sie unter Verwenden von RDS-Proxy mit globalen Aurora-Datenbanken.
Themen
Auswählen des Endpunkts, der Ihren Anwendungsanforderungen entspricht
Die Verbindung zu einer globalen Aurora-Datenbank hängt davon ab, ob Sie aus der Datenbank lesen oder in diese schreiben müssen sowie von der AWS -Region, an die Sie Ihre Anfragen weiterleiten möchten. Nachfolgend ein paar typische Anwendungsfälle:
-
Weiterleiten von Anfragen an die Writer-Instance: Stellen Sie eine Verbindung zum Writer-Endpunkt von Aurora Global Database her, wenn Sie Data Manipulation Language (DML)- und Data Definition Language (DDL)-Anweisungen ausführen müssen oder wenn Sie eine hohe Konsistenz zwischen Lese- und Schreibvorgängen benötigen. Dieser Endpunkt leitet Anfragen an die Writer-Instance im primären Cluster Ihrer globalen Datenbank weiter. Dieser Endpunkt wird automatisch aktualisiert, um Anfragen an die Writer-Instance weiterzuleiten, sodass Sie Ihre Anwendung nicht jedes Mal aktualisieren müssen, wenn Sie den Writer-Standort in Ihrem globalen Cluster ändern. Sie können den globalen Endpunkt auch verwenden, um regionsübergreifende read/write Anfragen an Ihren Autor zu senden.
Anmerkung
Wenn Sie Ihre globale Datenbank eingerichtet haben, bevor der Writer-Endpunkt von Aurora Global Database verfügbar war, stellt Ihre Anwendung möglicherweise eine Verbindung zum Cluster-Endpunkt des primären Clusters her. In diesem Fall empfehlen wir, Ihre Verbindungseinstellungen so zu ändern, dass stattdessen der globale Writer-Endpunkt verwendet wird. Dadurch müssen Sie Ihre Verbindungseinstellungen nicht nach jeder Umstellung oder jedem Failover von Aurora Global Database ändern.
Der erste Teil des Namens des Writer-Endpunkts ist der Name Ihrer globalen Aurora-Datenbank. Wenn Sie also Ihre globale Aurora-Datenbank umbenennen, ändert sich der Name des Writer-Endpunkts, und jeder Code, der ihn verwendet, muss mit dem neuen Namen aktualisiert werden.
-
Skalierung von Lesevorgängen näher an der Region Ihrer Anwendung: Um Nur-Lese-Anfragen in derselben oder einer nahegelegenen AWS Region wie Ihre Anwendung zu skalieren, stellen Sie eine Verbindung zum Reader-Endpunkt des primären oder sekundären Aurora-Clusters her.
-
Skalieren von Lesevorgängen mit gelegentlichen regionsübergreifenden Schreibvorgängen: Stellen Sie für gelegentliche DML-Anweisungen, z. B. zur Wartung und Datenbereinigung, eine Verbindung zum Reader-Endpunkt eines sekundären Clusters her, für den die Schreibweiterleitung aktiviert ist. Mit der Schreibweiterleitung leitet Aurora die Schreibanweisungen automatisch an den Writer in der primären Region Ihrer globalen Aurora-Datenbank weiter. Die Schreibweiterleitung bietet die folgenden Vorteile:
-
Sie müssen sich nicht die Mühe machen, eine Konnektivität zwischen dem sekundären und dem primären Cluster herzustellen, um regionsübergreifende Schreibvorgänge zu senden.
-
Sie müssen Lese- und Schreibanforderungen in der Anwendung nicht aufteilen.
-
Sie müssen keine komplexe Logik entwickeln, um die Konsistenz von Read-After-Write-Anfragen zu gewährleisten.
Bei der Schreibweiterleitung müssen Sie jedoch Ihren Anwendungscode oder Ihre Konfiguration aktualisieren, um nach einem regionsübergreifenden Failover oder einer solchen Umstellung eine Verbindung zum Reader-Endpunkt der neu hochgestuften primären Region herzustellen. Es wird empfohlen, die Latenz von Vorgängen, die über die Schreibweiterleitung ausgeführt werden, zu überwachen, um den Overhead bei der Verarbeitung der Schreibanforderungen zu überprüfen. Schließlich unterstützt die Schreibweiterleitung bestimmte MySQL- oder PostgreSQL-Operationen nicht, wie beispielsweise DDL-Änderungen oder
SELECT FOR UPDATE-Anweisungen.Weitere Informationen zur Verwendung der AWS regionsübergreifenden Schreibweiterleitung finden Sie unter. Verwenden der Schreibweiterleitung in einer Amazon Aurora globalen Datenbank
-
Einzelheiten zu den verschiedenen Arten von Aurora-Endpunkten finden Sie unter Herstellen einer Verbindung mit einem Amazon Aurora-DB-Cluster.
Anzeigen der Endpunkte einer globalen Amazon-Aurora-Datenbank
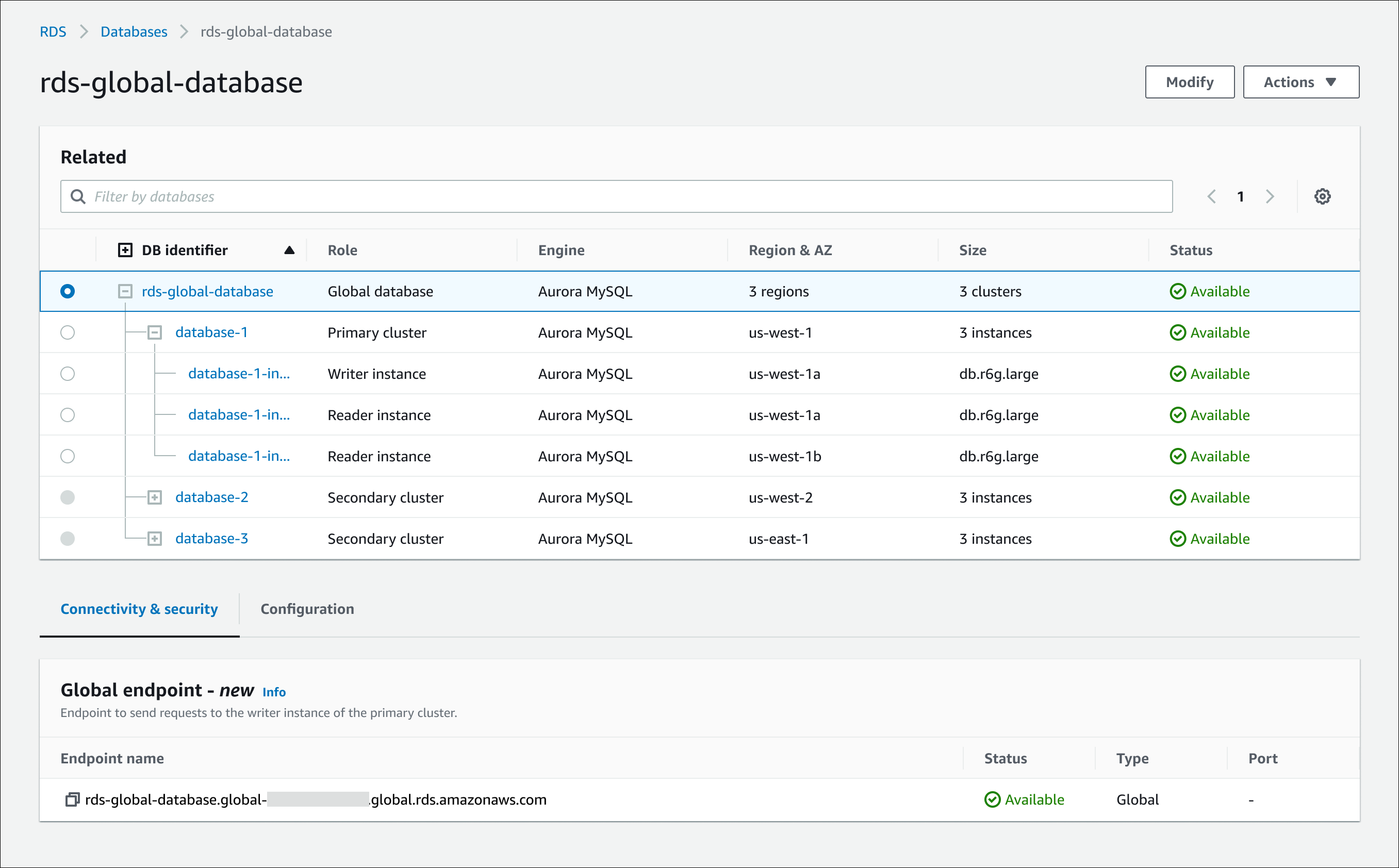
Wenn Sie eine globale Aurora-Datenbank in der Konsole anzeigen, können Sie alle Endpunkte sehen, die mit allen ihren Clustern verknüpft sind. Die folgende Abbildung zeigt ein Beispiel für die Arten von Endpunkten, die Sie sehen, wenn Sie sich die Details für Ihren primären DB-Cluster ansehen:
-
Globaler Writer — Der einzelne read/write Endpunkt, der immer auf die aktuelle Writer-DB-Instance für den globalen Datenbankcluster verweist.
-
Writer — Der Verbindungsendpunkt für read/write Anfragen an den primären DB-Cluster im globalen Datenbankcluster.
-
Reader – Dies ist der Verbindungsendpunkt für schreibgeschützte Anfragen an einen primären oder sekundären DB-Cluster im globalen Datenbank-Cluster. Um die Latenz zu minimieren, wählen Sie den Reader-Endpunkt aus, der sich in Ihrem AWS-Region oder dem Ihnen AWS-Region am nächsten befindet.
So zeigen Sie die Endpunkte einer globalen Datenbank an
-
Melden Sie sich bei der an AWS-Managementkonsole und öffnen Sie die Amazon RDS-Konsole unter https://console.aws.amazon.com/rds/
. -
Wählen Sie im Navigationsbereich Datenbanken aus.
-
Wählen Sie in der Liste die globale Datenbank oder den primären oder sekundären DB-Cluster aus, dessen Endpunkte Sie anzeigen möchten.
-
Wählen Sie die Registerkarte Konnektivität und Sicherheit aus, um die Endpunktdetails zu sehen. Die angezeigten Endpunkte hängen vom Typ des Clusters ab, den Sie ausgewählt haben:
-
Globale Datenbank – der globale Writer-Endpunkt
-
Primärer DB-Cluster – der globale Writer-Endpunkt sowie der Cluster-Endpunkt und der Reader-Endpunkt für den primären Cluster
-
Sekundärer DB-Cluster – der Cluster-Endpunkt und der Reader-Endpunkt für den sekundären Cluster Auf einem sekundären Cluster zeigt der Cluster-Endpunkt den Status inaktiv an, da er keine Schreibanforderungen bearbeitet. Sie können weiterhin eine Verbindung zum Cluster-Endpunkt herstellen, jedoch nur für Leseabfragen.
-
Um den Writer-Endpunkt des globalen Clusters anzuzeigen, verwenden Sie den AWS CLI -Befehl describe-global-clusters wie im folgenden Beispiel gezeigt.
aws rds describe-global-clusters --regionaws_region{ "GlobalClusters": [ { "GlobalClusterIdentifier": "global_cluster_id", "GlobalClusterResourceId": "cluster-unique_string", "GlobalClusterArn": "arn:aws:rds::123456789012:global-cluster:global_cluster_id", "Status": "available", "Engine": "aurora-mysql", "EngineVersion": "5.7.mysql_aurora.2.11.2", "GlobalClusterMembers": [ ... ], "Endpoint": "global_cluster_id.global-unique_string.global.rds.amazonaws.com" } ] }
Um die Cluster- und Reader-Endpunkte für Mitglieds-DB-Cluster des globalen Clusters anzuzeigen, verwenden Sie den AWS CLI
-Befehl describe-db-clusters wie im folgenden Beispiel gezeigt. Bei den für Endpoint und ReaderEndpoint zurückgegebenen Werten handelt es sich um die Endpunkte für den Cluster bzw. Reader.
aws rds describe-db-clusters --regionprimary_region--db-cluster-identifierdb_cluster_id{ "DBClusters": [ { "AllocatedStorage": 1, "AvailabilityZones": [ "az_1", "az_2", "az_3" ], "BackupRetentionPeriod": 1, "DBClusterIdentifier": "db_cluster_id", "DBClusterParameterGroup": "default.aurora-mysql5.7", "DBSubnetGroup": "default", "Status": "available", "EarliestRestorableTime": "2023-08-01T18:21:11.301Z", "Endpoint": "db_cluster_id.cluster-unique_string.primary_region.rds.amazonaws.com", "ReaderEndpoint": "db_cluster_id.cluster-ro-unique_string.primary_region.rds.amazonaws.com", "MultiAZ": false, "Engine": "aurora-mysql", "EngineVersion": "5.7.mysql_aurora.2.11.2", "ReadReplicaIdentifiers": [ "arn:aws:rds:secondary_region:123456789012:cluster:db_cluster_id" ], "DBClusterMembers": [ { "DBInstanceIdentifier": "db_instance_id", "IsClusterWriter": true, "DBClusterParameterGroupStatus": "in-sync", "PromotionTier": 1 } ], ... "TagList": [], "GlobalWriteForwardingRequested": false } ] }
Verwenden Sie den DescribeGlobalClustersRDS-API-Vorgang, um den Writer-Endpunkt des globalen Clusters anzuzeigen. Verwenden Sie die RDS-API-Operation DescribeDBClusters, um die Cluster- und Reader-Endpunkte für Mitglieds-DB-Cluster des globalen Clusters anzuzeigen.
Überlegungen zur Verwendung globaler Writer-Endpunkte
Sie können Writer-Endpunkte von Aurora Global Database effektiv nutzen, indem Sie sich an die folgenden Richtlinien und bewährten Methoden halten:
-
Um Unterbrechungen nach einem regionsübergreifenden Failover oder Switchover zu minimieren, können Sie VPC-Konnektivität zwischen Ihrem Anwendungscomputer und Ihren primären und sekundären Regionen einrichten. AWS Angenommen, Sie haben Anwendungen oder Clientsysteme, die in derselben VPC wie der primäre Cluster ausgeführt werden. Wenn der sekundäre Cluster hochgestuft wird, ändert sich der globale Writer-Endpunkt automatisch so, dass er auf diesen Cluster verweist. Mit dem globalen Writer-Endpunkt können Sie zwar vermeiden, die Verbindungseinstellungen für Ihre Anwendung zu ändern, Ihre Anwendungen können jedoch erst dann auf die IP-Adressen in der VPC der neu beworbenen primären AWS Region zugreifen, wenn Sie ein Netzwerk zwischen den beiden VPCs eingerichtet haben. Unter Amazon VPC-to-Amazon VPC-Konnektivitätsoptionen finden Sie Informationen zu den verschiedenen Optionen für die Einrichtung dieser Konnektivität.
-
Die Aktualisierung des globalen Writer-Endpunkts nach einem globalen Datenbank-Failover oder einer solchen Umstellung kann je nach Dauer der Zwischenspeicherung Ihres Domain Name Service (DNS) lange dauern. Weitere Informationen finden Sie im Administratorhandbuch zu Amazon Aurora-MySQL-Datenbanken. Aurora Global Database gibt ein RDS-Ereignis aus, wenn es eine DNS-Änderung auf dem globalen Writer-Endpunkt feststellt. Sie können das Ereignis verwenden, um Strategien zu entwickeln, die dafür sorgen, dass die Dauer der DNS-Zwischenspeicherung nicht über die Zeit nach der Generierung des Ereignisses hinausgeht. Weitere Informationen finden Sie unter DB-Cluster-Ereignisse.
-
Aurora Global Database repliziert Daten asynchron. Die regionsübergreifenden Failover-Methoden können dazu führen, dass einige Schreibtransaktionsdaten vor dem Eintreten des Failovers nicht zur gewählten sekundären Region repliziert wurden. Obwohl Aurora nach besten Kräften versucht, Schreibvorgänge in der ursprünglichen primären AWS Region zu blockieren, kann ein Failover anfällig für Split-Brain-Probleme sein. Die Überlegungen zur Minimierung von Datenverlusten und Split-Brain-Risiken gelten auch für Writer-Endpunkte von Aurora Global Database. Weitere Informationen finden Sie unter Ausführen von verwalteten geplanten Failovers für globale Aurora-Datenbanken.
