本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
使用 CloudWatch 複合式警報偵測故障
在 CloudWatch 量度中,每個維度集都是唯一的量度,您可以在每個維度集上建立 CloudWatch 警示。然後,您可以建立 Amazon CloudWatch 複合警示來彙總這些指標。
為了準確偵測撞擊,本 paper 中的範例將針對其 CloudWatch 警示的每個尺寸集使用兩種不同的警報結構。每個警報都會使用一分鐘的期間,表示每分鐘評估一次量度。第一種方法是通過將「評估期」和「數據點」設置為「警報」設置為三個來使用連續三個違規數據點,這意味著總共三分鐘的影響。第二種方法將使用「M out N」,當五分鐘視窗中的任何 3 個資料點違反時,方法是將「評估期間」設定為 5,將「資料點設定為警示」設定為 3。這提供了檢測恆定信號以及在短時間內波動的信號的能力。此處包含的時間持續時間和數據點數量是一個建議,請使用對您的工作負載有意義的值。
偵測單一可用區域中的影響
使用此建構,考慮使用Controller、ActionInstanceIdAZ-ID、和作Region為維度的工作負載。工作負載有兩個控制器:產品和首頁,以及每個控制器一個動作、清單和索引分別。它在區域中的三個可用區us-east-1域中運作。您可以針對每個可用區域的可用性Controller和Action組合建立兩個警示,以及每個可用區域的兩個延遲警示。然後,您可以選擇為每個警報和組合建立可用性的複ControllerAction合警示。最後,您會建立複合警示,彙總可用區域的所有可用性警示。對於單一可用區域use1-az1,使用每個Controller和Action組合的選用複合警示 (與可用區use1-az3域也會存在類似的警示use1-az2,但不會顯示為簡單起見),如下圖所示。
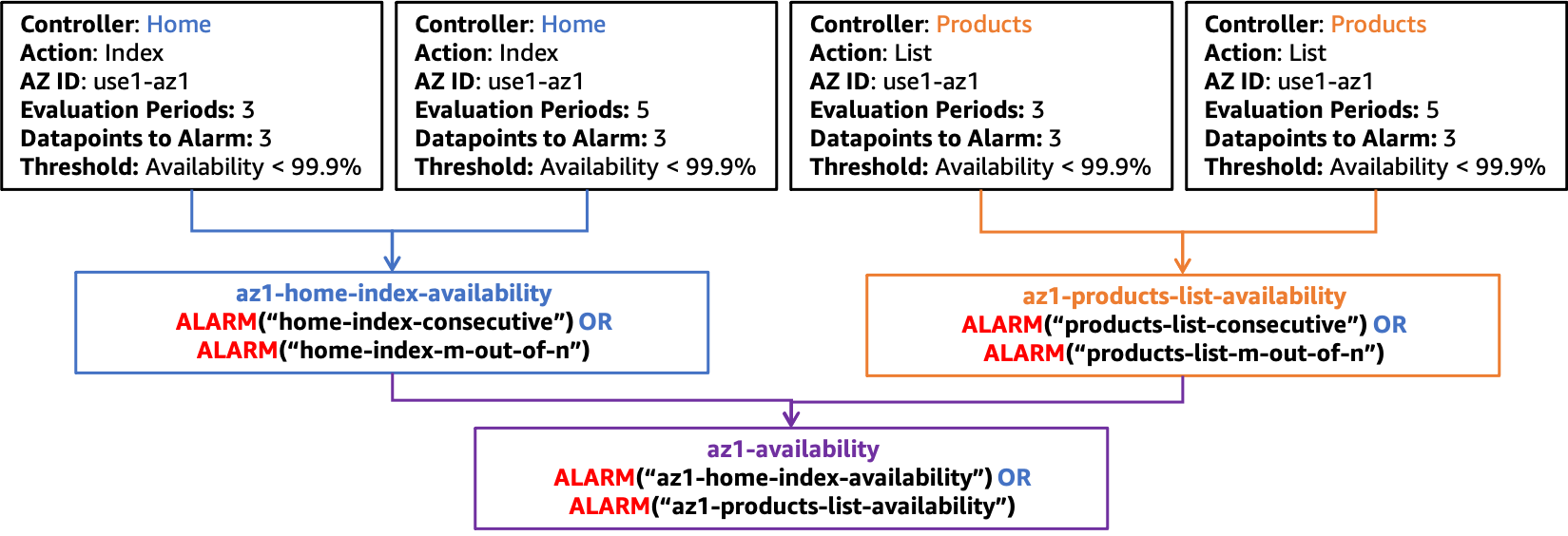
複合報警結構,可用於 use1-az1
您也可以針對延遲建立類似的警示結構,如下圖所示。
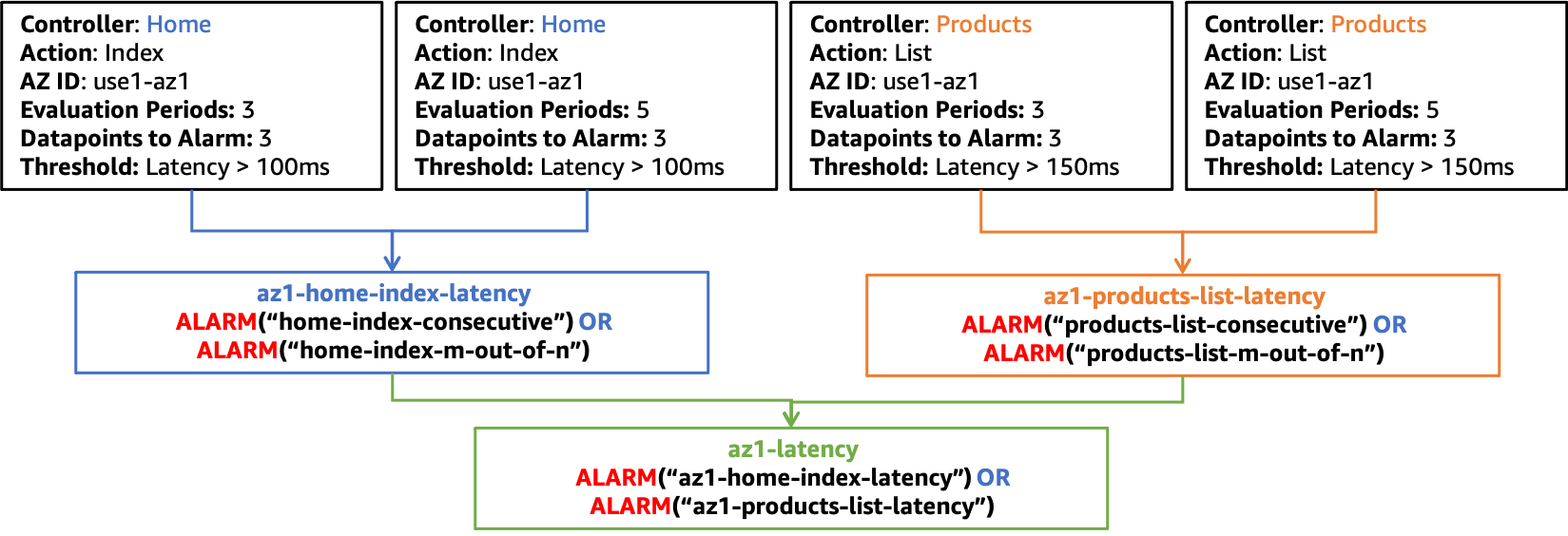
用於延遲的複合警報結構 use1-az1
對於本節的其餘數字,只有az1-availability和az1-latency複合警報會顯示在頂層。對於工作負載的任何部分az1-latency,這些複合警示az1-availability和,將告訴您是否可用性低於或延遲超過特定可用區域中定義的閾值。您也可以考慮測量輸送量,以偵測可防止單一可用區域中的工作負載接收工作的影響。您也可以將金絲雀發出的指標產生的警報集成到這些複合警報中。如此一來,如果伺服器端或用戶端看到可用性或延遲的影響,警示就會建立警示。
確保影響不是區域
另一組複合警報可用於確保只有隔離的可用區域事件才會啟動警示。這是透過確保可用區域複合警示處於ALARM狀態,而其他可用區域的複合警示處於OK狀態來執行。這將導致您使用的每個可用區域產生一個複合警報。下圖顯示了一個範例 (請記住,和、、、和中use1-az2有延遲和可用性的警示 use1-az3 az2-latency az2-availability az3-latencyaz3-availability,這些警示並未顯示為簡單起見)。
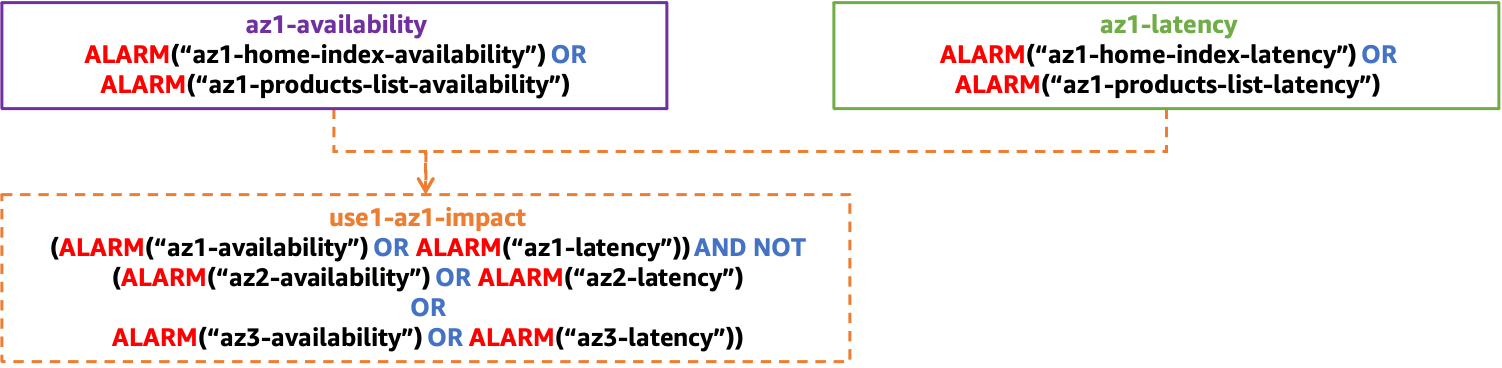
複合式警報結構,可偵測隔離至單一 AZ 的衝擊
確保影響不是由單一執行個體造成
單一執行個體 (或整體叢集的一小部分) 可能會對可用性和延遲指標造成不成比例的影響,這些指標可能會使整個可用區域看起來受到影響,但事實上並非如此。與撤除可用區域相比,移除單一有問題的執行個體更快速且有效。
執行個體和容器通常會被視為暫時資源,通常會被等服務取代。AWS Auto Scaling
例如,對於 HTTP Web 應用程式,您可以建立規則,以識別每個可用區域中 5xx HTTP 回應的主要貢獻者。這將識別哪些執行個體導致可用性下降 (上面定義的可用性指標是由存在 5xx 錯誤驅動)。使用記EMF錄範例,使用的索引鍵建立規則InstanceId。然後,按HttpResponseCode字段過濾日誌。此範例是use1-az1可用區域的規則。
{ "AggregateOn": "Count", "Contribution": { "Filters": [ { "Match": "$.InstanceId", "IsPresent": true }, { "Match": "$.HttpStatusCode", "IsPresent": true }, { "Match": "$.HttpStatusCode", "GreaterThan": 499 }, { "Match": "$.HttpStatusCode", "LessThan": 600 }, { "Match": "$.AZ-ID", "In": ["use1-az1"] }, ], "Keys": [ "$.InstanceId" ] }, "LogFormat": "JSON", "LogGroupNames": [ "/loggroupname" ], "Schema": { "Name": "CloudWatchLogRule", "Version": 1 } }
CloudWatch 也可以根據這些規則來創建警報。您可以使用度量數學和具有量度的INSIGHT_RULE_METRIC函數,根據參與者見解規則建立警示。UniqueContributors除了可用性,您還可以使用延遲或錯誤計數等指標的 CloudWatch 警示來建立其他「參與者見解」規則。這些警示可與隔離的可用區域影響複合警示搭配使用,以確保單一執行個體不會啟動警示。見解規則的量度use1-az1可能如下所示:
INSIGHT_RULE_METRIC("5xx-errors-use1-az1", "UniqueContributors")
當此量度大於臨界值時,您可以定義警示;例如,本範例為 2。當 5xx 回應的獨特貢獻者超過該閾值時,就會啟動此功能,表示影響來自兩個以上的執行個體。此警報使用大於比較而不是小於的原因是為了確保唯一貢獻者的零值不會引發警報。這告訴您,影響不是來自單一執行個體。針對您的個別工作負載調整此閾值。一般指南是將此數字設定為可用區域中總資源的 5% 或更多。在足夠的樣本數量下,超過 5% 的資源受到影響顯著表現出統計顯著性。
整合練習
下圖顯示單一可用區域的完整複合警示結構:

完整的複合報警結構,用於確定單一可用區
當指示隔離可用區域對延遲或可用性造成的影響的複合警示處於ALARM狀態,use1-az1-aggregate-alarm以及根據該可用區域的 Contributor Insights 規則的警示也處於ALARM狀態 (表示影響超過單一執行個體) 時,會啟動最終複合警示。use1-az1-isolated-impact not-single-instance-use1-az1您可以為工作負載使用的每個可用區域建立此警示堆疊。
您可以在此最終警報上附加 Amazon 簡單通知服務OK狀態。如果其他可用區域發生影響,則自動化可能會撤除第二個或第三個可用區域,進而可能會移除工作負載的所有可用容量。在採取任何行動之前,自動化應檢查是否已執行疏散。在疏散成功之前,您可能還需要擴展其他可用區域中的資源。
當您將新的控制器或動作添加到 MVC Web 應用程序,或新的微服務或一般情況下,要單獨監視的任何其他功能時,只需要在此設置中修改一些警報即可。您將為該新功能建立新的可用性和延遲警示,然後將這些警示新增至適當的可用性區域對齊可用性和延遲複合警示,以az1-latency及我們az1-availability在此處使用的範例中。其餘的複合警報在配置完成後仍保持靜態。這使得使用此方法的新功能成為更簡單的過程。
