本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
建立自訂工作者任務範本
若要建立自訂標籤工作,您需要更新工作者任務範本、將資訊清單檔案中的輸入資料對應至範本使用的變數,並將輸出資料對應至 Amazon S3。若要進一步了解使用 Liquid 自動化的進階功能,請參閱 新增包含 Liquid 的自動化。
下列各節描述每個必要步驟。
工作者任務範本
工作任務範本是 Ground Truth 的檔案,用於自訂工作者使用者介面 (UI)。您可利用 HTML、CSS、JavaScript、Liquid 範本語言
您可利用下列主題來了解如何建立工作者任務範本。您可於 GitHub
在 SageMaker AI 主控台使用基礎工作者任務範本
您可利用 Ground Truth 主控台的範本編輯器開始建立範本。此編輯器包含許多預先設計的基礎範本。此編輯器支援自動填入 HTML 和 Crowd HTML 元素程式碼。
若要存取 Ground Truth 自訂範本編輯器:
-
請遵循 建立標籤工作 (主控台) 中的說明。
-
然後針對標籤工作的任務類型選取自訂。
-
選擇下一步,然後您就能夠在自訂標籤任務設定區段存取範本編輯器與基礎範本。
-
(選用) 從 Templates (範本) 的下拉式功能表選取基礎範本。如您偏好從頭開始建立範本,請從下拉式功能表選擇 Custom (自訂),即可取得最簡單的範本骨架。
透過下一節了解如何在本機視覺化從主控台開發的範本。
在本機視覺化您的工作者任務範本
您必須透過主控台測試範本如何處理傳入資料。若要測試範本 HTML 和自訂元素的外觀和風格,您可以使用瀏覽器。
注意
變數不會經剖析。在本機檢視內容時,您可能需要將其取代為範例內容。
下列程式碼片段範例會載入必要的程式碼,以轉譯自訂 HTML 元素。如果您想要以您偏好的編輯器 (而不是主控台) 來開發範本外觀和風格,請使用此操作。
範例
<script src="https://assets.crowd.aws/crowd-html-elements.js"></script>
建立簡單的 HTML 任務範例
現在,您已有基礎工作者任務範本,您可以透過此主題來建立簡單的 HTML 型任務範本。
以下是輸入資訊清單檔案的範例項目。
{ "source": "This train is really late.", "labels": [ "angry" , "sad", "happy" , "inconclusive" ], "header": "What emotion is the speaker feeling?" }
在 HTML 任務範本中,我們需要將輸入資訊清單檔案的變數對應到範本。輸入資訊清單範例的變數將使用下列語法 task.input.source、task.input.labels 和 task.input.header 進行對應。
以下是推文分析的 HTML 工作者任務範本範例。所有任務都以 <crowd-form> </crowd-form> 元素開始和結束。如同標準 HTML <form> 元素,所有表單程式碼都應該放置於其中間。Ground Truth 會直接從範本中指定的內容產生工作者的任務,除非您實作註釋前 Lambda。Ground Truth 傳回的 taskInput 物件或 註釋前 Lambda 是範本中的 task.input 物件。
針對簡單的推文分析任務,請使用 <crowd-classifier> 元素。需要下列屬性:
名稱 - 輸出變數的名稱。工作者註釋會儲存至輸出資訊清單中的此變數名稱。
類別– 多種可能解答的 JSON 格式陣列。
標題 - 註釋工具的標題
<crowd-classifier> 元素至少需要下列三個子元素。
<classification-target> – 工作者將根據上述
categories屬性中指定之選項來分類的文字。<full-instructions> – 工具中「檢視完整說明」連結提供的說明。您可以將這項保留空白,但建議您提供完善說明以獲得更佳結果。
<short-instructions> – 任務的更簡要描敘,會顯示在工具的側邊欄。您可以將這項保留空白,但建議您提供完善說明以獲得更佳結果。
此工具的簡易版本看起來如下所示。變數 {{ task.input.source }} 會指定輸入資訊清單檔案中的來源資料。{{ task.input.labels | to_json }} 是將陣列變成 JSON 表示法的變數篩選條件範例。categories 屬性必須是 JSON。
範例使用 crowd-classifier 搭配輸入資訊清單 JSON 範例
<script src="https://assets.crowd.aws/crowd-html-elements.js"></script> <crowd-form> <crowd-classifier name="tweetFeeling"categories="='{{ task.input.labels | to_json }}'" header="{{ task.input.header }}'" > <classification-target>{{ task.input.source }}</classification-target> <full-instructions header="Sentiment Analysis Instructions"> Try to determine the sentiment the author of the tweet is trying to express. If none seem to match, choose "cannot determine." </full-instructions> <short-instructions> Pick the term that best describes the sentiment of the tweet. </short-instructions> </crowd-classifier> </crowd-form>
在 Ground Truth 標籤工作建立工作流程,您可將程式碼複製並貼到編輯器以便預覽工具,或試用 CodePen 上此程式碼的示範。
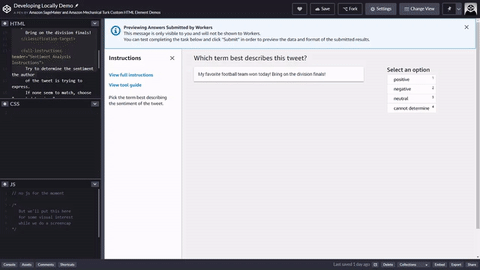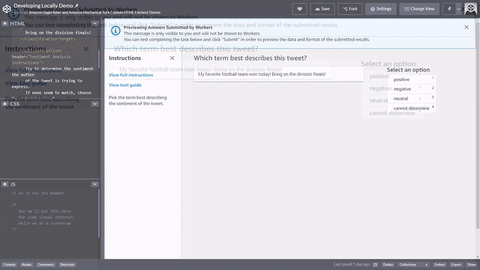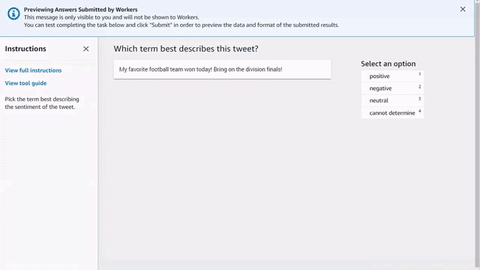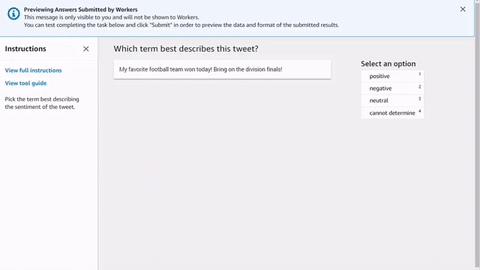
輸入資料、外部資產和您的任務範本
以下章節說明外部資產之使用、輸入資料格式要求,以及何時該考慮使用註釋前 Lambda 函式。
輸入資料格式要求
當您建立要在自訂 Ground Truth 標籤工作中使用的輸入資訊清單檔案時,您必須將資料儲存在 Amazon S3 中。輸入資訊清單檔案也必須儲存在執行自訂 Ground Truth 標籤任務 AWS 區域 的相同 中。除此之外,其可儲存在任何 Amazon S3 儲存貯體,前提是您用來在 Ground Truth 執行自訂標籤工作的 IAM 服務角色可以存取該 Amazon S3 儲存貯體。
輸入資訊清單檔案必須使用新行分隔 JSON 或 JSON 行格式。每一行都由標準分行符號 (\n 或 \r\n) 分隔。每一行也都必須為有效的 JSON 物件。
除此之外,資訊清單檔案中的每個 JSON 物件必須包含下列其中一個索引鍵:source-ref 或 source。鍵的值會解譯為如下:
-
source-ref– 物件來源是數值所指定的 Amazon S3 物件。當物件是二進位物件 (例如映像) 時,請使用此值。 -
source– 物件的來源即為數值。當物件為文字值時,請使用此值。
若要進一步了解如何格式化輸入資訊清單檔案,請參閱 輸入資訊清單檔案。
註釋前 Lambda 函式
您可以選擇指定註釋前 Lambda 函式,以管理在標記前如何處理輸入資訊清單檔案的資料。如果您已指定 isHumanAnnotationRequired 鍵/值對,則必須使用註釋前 Lambda 函式。Ground Truth 向註釋前 Lambda 函式傳送 JSON 格式的請求時,會使用下列結構描述。
範例透過 source-ref 鍵/值對識別的資料物件
{ "version": "2018-10-16", "labelingJobArn":arn:aws:lambda:us-west-2:555555555555:function:my-function"dataObject" : { "source-ref":s3://input-data-bucket/data-object-file-name} }
範例透過 source 鍵/值對識別的資料物件
{ "version": "2018-10-16", "labelingJobArn" :arn:aws:lambda:us-west-2:555555555555:function:my-function"dataObject" : { "source":Sue purchased 10 shares of the stock on April 10th, 2020} }
以下是使用 isHumanAnnotationRequired 時 Lambda 函式的預期回應。
{ "taskInput":{ "source": "This train is really late.", "labels": [ "angry" , "sad" , "happy" , "inconclusive" ], "header": "What emotion is the speaker feeling?" }, "isHumanAnnotationRequired":False}
使用外部資產
Amazon SageMaker Ground Truth 自訂範本允許嵌入外部指令碼與樣式表。例如,下列程式碼區塊示範如何將位於 https://www.example.com/my-enhancement-styles.css 的樣式表新增至範本。
範例
<script src="https://www.example.com/my-enhancment-script.js"></script> <link rel="stylesheet" type="text/css" href="https://www.example.com/my-enhancement-styles.css">
如果發生錯誤,請確保您的原始伺服器傳送資產的正確 MIME 類型和編碼標題。
例如,遠端指令碼的 MIME 和編碼類型為:application/javascript;CHARSET=UTF-8。
遠端樣式表的 MIME 和編碼類型為:text/css;CHARSET=UTF-8。
輸出資料和您的任務範本
下列章節說明自訂標籤工作的輸出資料,以及何時該考慮使用註釋後 Lambda 函式。
輸出資料
當您的自訂標籤工作完成時,資料會儲存在建立標籤工作時指定的 Amazon S3 儲存貯體中。資料會儲存在 output.manifest 檔案中。
注意
labelAttributeName 是預留位置變數。在您的輸出中,有標籤工作的名稱,或在建立標籤工作時指定的標籤屬性名稱。
-
source或source-ref– 要求字串或 S3 URI 工作者進行標記。 -
labelAttributeName– 包含來自註釋後 Lambda 函式的合併標籤內容的字典。如果未指定註釋後 Lambda 函式,則此字典為空白。 -
labelAttributeName-metadata– Ground Truth 所新增的自訂標籤工作的中繼資料。 -
worker-response-ref– 儲存資料的儲存貯體的 S3 URI。如果有指定註釋後 Lambda 函式,則不會出現此鍵/值對。
在此範例中,JSON 物件經過格式化以便於閱讀;在實際輸出檔案中,JSON 物件位於單一行上。
{ "source" : "This train is really late.", "labelAttributeName" : {}, "labelAttributeName-metadata": { # These key values pairs are added by Ground Truth "job_name": "test-labeling-job", "type": "groundTruth/custom", "human-annotated": "yes", "creation_date": "2021-03-08T23:06:49.111000", "worker-response-ref": "s3://amzn-s3-demo-bucket/test-labeling-job/annotations/worker-response/iteration-1/0/2021-03-08_23:06:49.json" } }
使用註釋後 Lambda 來合併工作者的結果
根據預設,Ground Truth 會在 Amazon S3 中儲存未處理的工作者回應。若要更精準地控制處理回應的方式,您可以指定註釋後 Lambda 函式。例如,如果多個工作者已標記相同的資料物件,則可以使用註釋後 Lambda 函式來合併註釋。若要進一步了解如何建立註釋後 Lambda 函式,請參閱 註釋後 Lambda。
如果您要使用註釋後 Lambda 函式,則必須在 CreateLabelingJob 請求中,將其指定為 AnnotationConsolidationConfig 的一部分。
若要進一步了解註釋合併的運作方式,請參閱 註釋整合。
