本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
Amazon SageMaker HyperPod 中的 Spot 執行個體
Amazon SageMaker HyperPod 支援 Amazon EC2 Spot 執行個體,可大幅節省容錯和無狀態 AI/ML 工作負載的成本。使用案例包括批次推論和訓練任務、超參數調校和實驗性工作負載。您也可以使用 Spot 執行個體,在有此低成本容量可用時自動擴展運算容量,並在回收新增的 Spot 容量時縮減至隨需容量。
根據預設,HyperPod 上的 Spot 執行個體使用 HyperPod 的持續佈建功能,可讓 SageMaker HyperPod 自動在背景佈建剩餘容量,同時工作負載會立即在可用的執行個體上啟動。當節點佈建因為容量限制或其他問題而遇到失敗時,SageMaker HyperPod 會自動在背景重試,直到叢集達到所需的擴展,因此您的自動擴展操作會保持彈性和非封鎖。您也可以使用 Spot 執行個體搭配 Karpenter 型自動擴展。
要考慮的主要功能和概念
-
與隨需執行個體相比,節省高達 90% 的成本
-
將 Spot 執行個體用於可處理中斷以及任務開始和完成時間彈性的任務
-
使用 Karpenter 進行自動擴展時,您可以將 HyperPod 設定為在 Spot 容量中斷或無法使用時自動回復至隨需
-
存取 HyperPod 支援的多種 CPU、GPU 和加速器執行個體類型
-
容量可用性取決於 EC2 的供應,並因區域和執行個體類型而異
-
您可以使用 EC2 提供的各種工具執行各種動作,例如識別取得所需執行個體或中斷的可能性,例如 Spot Instance Advisor
開始使用
先決條件
開始前,請確保您具備以下條件:
AWS CLI 已安裝和設定
設定您的 AWS 登入資料和區域:
aws configure
如需詳細說明,請參閱AWS 登入資料文件。
SageMaker HyperPod 執行的 IAM 角色
若要更新叢集,您必須先為 Karpenter 建立 AWS Identity and Access Management
VPC 和 EKS 叢集設定
2.1 建立 VPC 和 EKS 叢集
遵循 HyperPod EKS 設定指南以:
-
在多個可用區域中建立具有子網路的 VPC
-
建立 EKS 叢集
-
使用 Helm Chart 安裝必要的相依性
2.2 設定環境變數
export EKS_CLUSTER_ARN="arn:aws:eks:REGION:ACCOUNT_ID:cluster/CLUSTER_NAME" export EXECUTION_ROLE="arn:aws:iam::ACCOUNT_ID:role/SageMakerExecutionRole" export BUCKET_NAME="your-s3-bucket-name" export SECURITY_GROUP="sg-xxxxx" export SUBNET="subnet-xxxxx" export SUBNET1="subnet-xxxxx" export SUBNET2="subnet-xxxxx" export SUBNET3="subnet-xxxxx"
Spot 執行個體的服務配額
確認您擁有要在 SageMaker HyperPod 叢集中建立之執行個體所需的配額。若要檢閱您的配額,請在 Service Quotas 主控台上,選擇導覽窗格中 AWS 的服務,然後選擇 SageMaker。例如,下列螢幕擷取畫面顯示 c5 執行個體的可用配額。

檢查 Spot 可用性
建立 Spot 執行個體群組之前,請檢查不同可用區域中的可用性:
aws ec2 get-spot-placement-scores \ --region us-west-2 \ --instance-types c5.2xlarge \ --target-capacity 10 \ --single-availability-zone \ --region-names us-west-2
秘訣:具有較高置放分數的目標可用區域,以獲得更好的可用性。您也可以檢查 Spot Instance Advisor 和 EC2 Spot 定價的可用性。選取具有較佳可用性分數的必要可用區域,並將執行個體群組與關聯的子網路設定為在該可用區域中啟動執行個體。
建立執行個體群組 (無自動擴展)
CreateCluster (Spot)
aws sagemaker create-cluster \ --cluster-name clusterNameHere \ --orchestrator 'Eks={ClusterArn='$EKS_CLUSTER_ARN'}' \ --node-provisioning-mode "Continuous" \ --cluster-role 'arn:aws:iam::YOUR-ACCOUNT-ID:role/SageMakerHyperPodRole' \ --instance-groups '[{ "InstanceGroupName": "auto-spot-c5-2x-az1", "InstanceType": "ml.c5.2xlarge", "InstanceCount": 2, "CapacityRequirements: { "Spot": {} } "LifeCycleConfig": { "SourceS3Uri": "s3://'$BUCKET_NAME'", "OnCreate": "on_create_noop.sh" }, "ExecutionRole": "'$EXECUTION_ROLE'", "ThreadsPerCore": 1, "OverrideVpcConfig": { "SecurityGroupIds": ["'$SECURITY_GROUP'"], "Subnets": ["'$SUBNET1'"] } }]' --vpc-config '{ "SecurityGroupIds": ["'$SECURITY_GROUP'"], "Subnets": ["'$SUBNET'"] }'
更新叢集 (Spot + 隨需)
aws sagemaker update-cluster \ --cluster-name "my-cluster" \ --instance-groups '[{ "InstanceGroupName": "auto-spot-c5-x-az3", "InstanceType": "ml.c5.xlarge", "InstanceCount": 2, "CapacityRequirements: { "Spot": {} }, "LifeCycleConfig": { "SourceS3Uri": "s3://'$BUCKET_NAME'", "OnCreate": "on_create_noop.sh" }, "ExecutionRole": "'$EXECUTION_ROLE'", "ThreadsPerCore": 1, "OverrideVpcConfig": { "SecurityGroupIds": ["'$SECURITY_GROUP'"], "Subnets": ["'$SUBNET3'"] } }, { "InstanceGroupName": "auto-spot-c5-2x-az2", "InstanceType": "ml.c5.2xlarge", "InstanceCount": 2, "CapacityRequirements: { "Spot": {} } "LifeCycleConfig": { "SourceS3Uri": "s3://'$BUCKET_NAME'", "OnCreate": "on_create_noop.sh" }, "ExecutionRole": "'$EXECUTION_ROLE'", "ThreadsPerCore": 1, "OverrideVpcConfig": { "SecurityGroupIds": ["'$SECURITY_GROUP'"], "Subnets": ["'$SUBNET2'"] } }, { "InstanceGroupName": "auto-ondemand-c5-2x-az1", "InstanceType": "ml.c5.2xlarge", "InstanceCount": 2, "LifeCycleConfig": { "SourceS3Uri": "s3://'$BUCKET_NAME'", "OnCreate": "on_create_noop.sh" }, "ExecutionRole": "'$EXECUTION_ROLE'", "ThreadsPerCore": 1, "OverrideVpcConfig": { "SecurityGroupIds": ["'$SECURITY_GROUP'"], "Subnets": ["'$SUBNET1'"] } }]'
CapacityRequirements 執行個體群組建立後就無法修改。
描述叢集
aws sagemaker describe-cluster --cluster-name $HP_CLUSTER_NAME --region us-west-2
## Sample Response { "ClusterName": "my-cluster", "InstanceGroups": [ { "InstanceGroupName": "ml.c5.2xlarge", "InstanceType": "ml.c5.xlarge", "InstanceCount": 5, "CurrentCount": 3, "CapacityRequirements: { "Spot": {} }, "ExecutionRole": "arn:aws:iam::account:role/SageMakerExecutionRole", "InstanceStorageConfigs": [...], "OverrideVpcConfig": {...} } // Other IGs ] }
DescribeClusterNode
aws sagemaker describe-cluster-node --cluster-name $HP_CLUSTER_NAME --region us-west-2
## Sample Response { "NodeDetails": { "InstanceId": "i-1234567890abcdef1", "InstanceGroupName": "ml.c5.2xlarge", "CapacityType": "Spot", "InstanceStatus": {...} } }
使用主控台
建立和設定 SageMaker HyperPod 叢集
若要開始,請啟動和設定 SageMaker HyperPod EKS 叢集,並確認叢集建立時已啟用持續佈建模式。請完成下列步驟:
-
在 SageMaker AI 主控台上,選擇導覽窗格中的 HyperPod 叢集。
-
選擇建立 HyperPod 叢集並在 Amazon EKS 上協調。
-
針對設定選項,選取自訂設定。
-
針對名稱,輸入名稱。
-
針對執行個體復原,選取自動。
-
針對執行個體佈建模式,選取使用連續佈建。
-
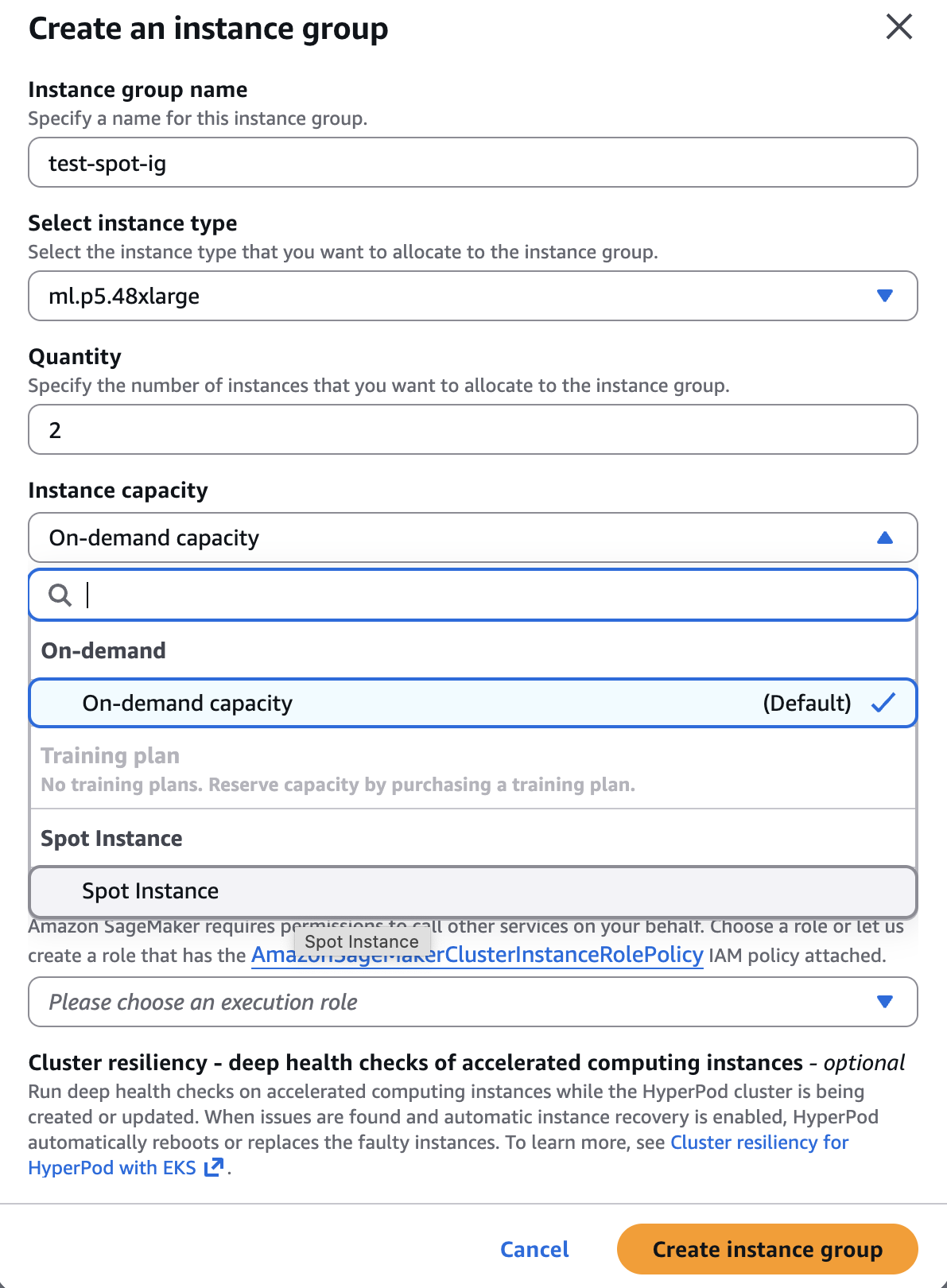
CapacityType:選取 Spot
-
選擇提交。
主控台的螢幕擷取畫面:

此設定會建立必要的組態,例如虛擬私有雲端 (VPC)、子網路、安全群組和 EKS 叢集,並在叢集中安裝運算子。如果您想要使用現有的叢集,而不是建立新的叢集,也可以提供現有的資源,例如 EKS 叢集。此設定大約需要 20 分鐘。
將新的 Spot 執行個體群組新增至相同的叢集
將 Spot IG 新增至現有的 HyperPod EKS 叢集。請完成下列步驟:
-
在 SageMaker AI 主控台上,選擇導覽窗格中的 HyperPod 叢集。
-
選取具有 Amazon EKS 協同運作的現有 HyperPod 叢集 (確保已啟用持續佈建)。
-
按一下 Edit (編輯)。
-
在編輯叢集頁面上,按一下建立執行個體群組。
-
選取容量類型:執行個體群組組態中的 Spot 執行個體。
-
按一下建立執行個體群組。
-
請按 Submit (提交)。
主控台的螢幕擷取畫面:
使用 CloudFormation
Resources: TestCluster: Type: AWS::SageMaker::Cluster Properties: ClusterName: "SampleCluster" InstanceGroups: - InstanceGroupName: group1 InstanceType: ml.c5.2xlarge InstanceCount: 1 LifeCycleConfig: SourceS3Uri: "s3://'$BUCKET_NAME'" OnCreate: "on_create_noop.sh" ExecutionRole: "'$EXECUTION_ROLE'", ThreadsPerCore: 1 CapacityRequirements: Spot: {} VpcConfig: Subnets: - "'$SUBNET1'" SecurityGroupIds: - "'$SECURITY_GROUP'" Orchestrator: Eks: ClusterArn: '$EKS_CLUSTER_ARN' NodeProvisioningMode: "Continuous" NodeRecovery: "Automatic"
如需詳細資訊,請參閱 https://docs.aws.amazon.com/sagemaker/latest/dg/smcluster-getting-started-eks-console-create-cluster-cfn.html://。
以 Karpenter 為基礎的 Autoscaling
建立叢集角色
步驟 1:導覽至 IAM 主控台
-
前往 AWS 管理主控台 → IAM 服務
-
按一下左側邊欄中的角色
-
按一下建立角色
步驟 2:設定信任政策
-
選取自訂信任政策 (而非 AWS 服務)
-
使用此信任政策取代預設 JSON:
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "Service": [ "hyperpod.sagemaker.amazonaws.com" ] }, "Action": "sts:AssumeRole" } ] }
按一下下一步
步驟 3:建立自訂許可政策
由於這些是特定的 SageMaker 許可,您將需要建立自訂政策:
-
按一下建立政策 (開啟新標籤)
-
按一下 JSON 索引標籤
-
輸入此政策:
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "sagemaker:BatchAddClusterNodes", "sagemaker:BatchDeleteClusterNodes" ], "Resource": "*" } ] } -
按一下下一步
-
為其命名,例如
SageMakerHyperPodRolePolicy -
按一下建立政策
步驟 4:將政策連接至角色
-
返回您的角色建立索引標籤
-
重新整理政策清單
-
搜尋並選取新建立的政策
-
按一下下一步
步驟 5:名稱和建立角色
-
輸入角色名稱 (例如
SageMakerHyperPodRole) -
視需要新增描述
-
檢閱信任政策和許可
-
按一下建立角色
驗證
建立之後,您可以透過以下方式驗證:
-
檢查信任關係索引標籤會顯示 HyperPod 服務
-
檢查許可索引標籤會顯示您的自訂政策
-
角色 ARN 將可與 HyperPod 搭配使用
角色 ARN 格式為:
arn:aws:iam::YOUR-ACCOUNT-ID:role/SageMakerHyperPodRole
使用 AutoScaling 建立叢集:
為了提高可用性,請透過設定子網路在多個 AZs 中建立 IGs。您也可以包含用於備用的onDemand IGs。
aws sagemaker create-cluster \ --cluster-name clusterNameHere \ --orchestrator 'Eks={ClusterArn='$EKS_CLUSTER_ARN'}' \ --node-provisioning-mode "Continuous" \ --cluster-role 'arn:aws:iam::YOUR-ACCOUNT-ID:role/SageMakerHyperPodRole' \ --instance-groups '[{ "InstanceGroupName": "auto-spot-c5-2x-az1", "InstanceType": "ml.c5.2xlarge", "InstanceCount": 0, // For Auto scaling keep instance count as 0 "CapacityRequirements: { "Spot": {} } "LifeCycleConfig": { "SourceS3Uri": "s3://'$BUCKET_NAME'", "OnCreate": "on_create_noop.sh" }, "ExecutionRole": "'$EXECUTION_ROLE'", "ThreadsPerCore": 1, "OverrideVpcConfig": { "SecurityGroupIds": ["'$SECURITY_GROUP'"], "Subnets": ["'$SUBNET1'"] } }]' --vpc-config '{ "SecurityGroupIds": ["'$SECURITY_GROUP'"], "Subnets": ["'$SUBNET'"] }' --auto-scaling ' { "Mode": "Enable", "AutoScalerType": "Karpenter" }'
更新叢集 (Spot + 隨需)
aws sagemaker update-cluster \ --cluster-name "my-cluster" \ --instance-groups '[{ "InstanceGroupName": "auto-spot-c5-x-az3", "InstanceType": "ml.c5.xlarge", "InstanceCount": 2, "CapacityRequirements: { "Spot": {} }, "LifeCycleConfig": { "SourceS3Uri": "s3://'$BUCKET_NAME'", "OnCreate": "on_create_noop.sh" }, "ExecutionRole": "'$EXECUTION_ROLE'", "ThreadsPerCore": 1, "OverrideVpcConfig": { "SecurityGroupIds": ["'$SECURITY_GROUP'"], "Subnets": ["'$SUBNET3'"] } }, { "InstanceGroupName": "auto-spot-c5-2x-az2", "InstanceType": "ml.c5.2xlarge", "InstanceCount": 2, "CapacityRequirements: { "Spot": {} } "LifeCycleConfig": { "SourceS3Uri": "s3://'$BUCKET_NAME'", "OnCreate": "on_create_noop.sh" }, "ExecutionRole": "'$EXECUTION_ROLE'", "ThreadsPerCore": 1, "OverrideVpcConfig": { "SecurityGroupIds": ["'$SECURITY_GROUP'"], "Subnets": ["'$SUBNET2'"] } }, { "InstanceGroupName": "auto-ondemand-c5-2x-az1", "InstanceType": "ml.c5.2xlarge", "InstanceCount": 2, "LifeCycleConfig": { "SourceS3Uri": "s3://'$BUCKET_NAME'", "OnCreate": "on_create_noop.sh" }, "ExecutionRole": "'$EXECUTION_ROLE'", "ThreadsPerCore": 1, "OverrideVpcConfig": { "SecurityGroupIds": ["'$SECURITY_GROUP'"], "Subnets": ["'$SUBNET1'"] } }]'
建立 HyperpodNodeClass
HyperpodNodeClass 是一種自訂資源,映射到 SageMaker HyperPod 中預先建立的執行個體群組,定義 Karpenter 自動擴展決策支援哪些執行個體類型和可用區域的限制。若要使用 HyperpodNodeClass,只需指定您要用作 AWS 運算資源來源InstanceGroups的 SageMaker HyperPod 叢集名稱,以擴展 NodePools 中的 Pod。您在此處使用HyperpodNodeClass的名稱會轉移到您參考它的下一節中的 NodePool。這會告知 NodePool HyperpodNodeClass 從中提取資源。若要建立 HyperpodNodeClass,請完成下列步驟:
-
建立類似下列程式碼的 YAML 檔案 (例如 nodeclass.yaml)。新增您在建立 SageMaker HyperPod 叢集時所使用的
InstanceGroup名稱。您也可以將新的執行個體群組新增至現有的 SageMaker HyperPod EKS 叢集。 -
參考 NodePool 組態中的
HyperPodNodeClass名稱。
以下是範例 HyperpodNodeClass :
apiVersion: karpenter.sagemaker.amazonaws.com/v1 kind: HyperpodNodeClass metadata: name: multiazg6 spec: instanceGroups: # name of InstanceGroup in HyperPod cluster. InstanceGroup needs to pre-created # before this step can be completed. # MaxItems: 10 - auto-spot-c5-2x-az1 - auto-spot-c5-2x-az2 - auto-spot-c5-x-az3 - auto-ondemand-c5-2x-az1
在組態中指定時,Karpenter 會將 Spot 執行個體群組優先於隨需執行個體,使用隨需做為備用執行個體。執行個體選擇會依與每個子網路可用區域相關聯的 EC2 Spot 置放分數進行排序。
使用 將組態套用至您的 EKS 叢集kubectl:
kubectl apply -f nodeclass.yaml
HyperPod 叢集必須啟用 AutoScaling,且 AutoScaling 狀態必須變更為 HyperpodNodeClass InService,才能套用 。它也會將執行個體群組容量顯示為 Spot 或 OnDemand。如需詳細資訊和重要考量事項,請參閱在 SageMaker HyperPod EKS 上自動擴展。
例如,
apiVersion: karpenter.sagemaker.amazonaws.com/v1 kind: HyperpodNodeClass metadata: creationTimestamp: "2025-11-30T03:25:04Z" name: multiazc6 uid: ef5609be-15dd-4700-89ea-a3370e023690 spec: instanceGroups: -spot1 status: conditions: // true when all IGs in the spec are present in SageMaker cluster, false otherwise - lastTransitionTime: "2025-11-20T03:25:04Z" message: "" observedGeneration: 3 reason: InstanceGroupReady status: "True" type: InstanceGroupReady // true if subnets of IGs are discoverable, false otherwise - lastTransitionTime: "2025-11-20T03:25:04Z" message: "" observedGeneration: 3 reason: SubnetsReady status: "True" type: SubnetsReady // true when all dependent resources are Ready [InstanceGroup, Subnets] - lastTransitionTime: "2025-11-30T05:47:55Z" message: "" observedGeneration: 3 reason: Ready status: "True" type: Ready instanceGroups: - instanceTypes: - ml.c5.2xlarge name:auto-spot-c5-2x-az2 subnets: - id: subnet-03ecc649db2ff20d2 zone: us-west-2a zoneId: usw2-az2 - capacities: {"Spot": {}}
建立 NodePool
NodePool 會對 Karpenter 可建立的節點和可在這些節點上執行的 Pod 設定限制。NodePool 可以設定為執行各種動作,例如:
-
定義標籤和污點,以限制可在 Karpenter 建立的節點上執行的 Pod
-
將節點建立限制在特定區域、執行個體類型和電腦架構等
如需 NodePool 的詳細資訊,請參閱 NodePools
若要建立 NodePool,請完成下列步驟:
使用所需的 NodePool 組態建立名為 nodepool.yaml的 YAML 檔案。下列程式碼是建立範例 NodePool 的範例組態。我們指定 NodePool 來包含 ml.g6.xlarge SageMaker 執行個體類型,並另外指定一個區域。如需更多自訂項目,請參閱 NodePools
apiVersion: karpenter.sh/v1 kind: NodePool metadata: name: gpunodepool spec: template: spec: nodeClassRef: group: karpenter.sagemaker.amazonaws.com kind: HyperpodNodeClass name: multiazg6 expireAfter: Never requirements: - key: node.kubernetes.io/instance-type operator: Exists - key: "node.kubernetes.io/instance-type" // Optional otherwise Karpenter will decide based on Job config resource requirements operator: In values: ["ml.c5.2xlarge"] - key: "topology.kubernetes.io/zone" operator: In values: ["us-west-2a"]
提示:在 EC2 Spot 中斷時,Hyperpod 會污染節點以觸發 Pod 移出。Karpenter 的合併程序遵守 Pod 中斷預算,並執行正常的 Kubernetes 移出,但如果您設定 consolidateAfter: 0,則整合可以立即發生,幾乎沒有時間進行正常的 Pod 移出。將其設定為非零最多 2 分鐘,以允許對任何檢查點需求進行正常的 Pod 移出。
將 NodePool 套用至您的叢集:
kubectl apply -f nodepool.yaml
監控 NodePool 狀態,以確保 狀態的就緒條件設定為 True:
kubectl get nodepool gpunodepool -oyaml
此範例顯示如何使用 NodePool 來指定 Pod 的硬體 (執行個體類型) 和置放 (可用區域)。
啟動簡單的工作負載
下列工作負載會執行 Kubernetes 部署,其中部署中的 Pod 要求每個 Pod 每個複本 1 個 CPU 和 256 MB 記憶體。Pod 尚未旋轉。
kubectl apply -f https://raw.githubusercontent.com/aws/karpenter-provider-aws/refs/heads/main/examples/workloads/inflate.yaml
套用此功能時,我們可以看到叢集中的部署和單一節點啟動,如下列螢幕擷取畫面所示。
若要擴展此元件,請使用下列命令:
kubectl scale deployment inflate --replicas 10
如需詳細資訊,請參閱 https://docs.aws.amazon.com/sagemaker/latest/dg/sagemaker-hyperpod-eks-autoscaling.html://。
管理節點中斷
您可以隨時回收 Spot 執行個體。在大多數情況下,EC2 會盡最大努力提供 2 分鐘的中斷通知,但不保證此通知。在某些情況下,EC2 可能會立即終止 Spot 執行個體,而不會有任何預先警告。HyperPod 會自動處理這兩種情況:
-
使用 2 分鐘通知:Spot 容量可用時, 會自動重新嘗試正常的 Pod 移出和受控容量替換。
-
無通知 (立即終止):自動重新嘗試節點替換 (當 Spot 容量可用時),無需正常移出
運作方式
當 EC2 傳送 Spot 中斷通知時,HyperPod 會自動:
-
偵測中斷訊號
-
標記節點:防止在中斷的執行個體上排程新的 Pod
-
優雅地移出 Pod:讓執行中的 Pod 有時間完成或檢查點其工作 (遵守 Kubernetes
terminationGracePeriodSeconds) -
取代容量:自動嘗試佈建取代執行個體 (Spot 或隨需,視可用性而定)。
容量替換的運作方式是自動佈建替換執行個體。當容量無法立即使用時,系統會繼續檢查,直到可以存取資源為止。在非自動擴展執行個體群組的情況下,HyperPod 會嘗試在相同的執行個體群組內向上擴展,直到所需的容量可用為止。對於 Karpenter 型執行個體群組,當主要群組無法滿足需求時,Karpenter 會對節點類別中設定的其他執行個體群組實作備用機制。此外,您可以將隨需設定為備用選項,允許 Karpenter 在無法成功擴展 Spot 執行個體群組時自動切換到隨需執行個體。
-
重新排程工作負載:Kubernetes 會自動在運作狀態良好的節點上重新排程移出的 Pod
尋找您的用量和帳單
若要在 HyperPod 上檢查 Spot 執行個體的用量和帳單,您可以使用 Cost Explorer AWS 主控台。前往帳單與成本管理 > 帳單

若要在主控台上探索用量和帳單,請前往 Billing and Cost Management > Cost Explorer

