本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
微調模型
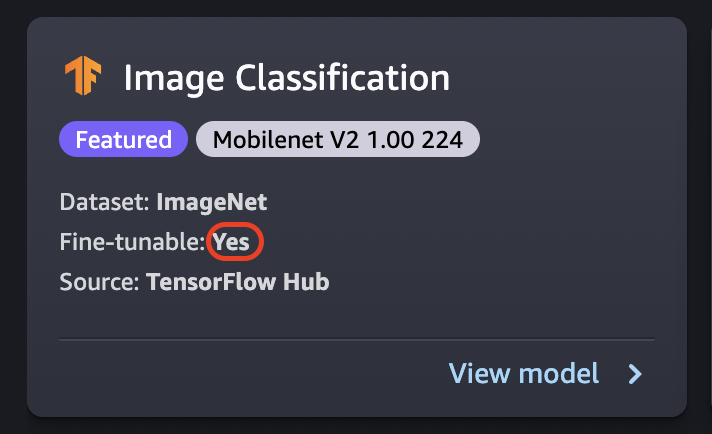
微調會在新資料集上訓練預先訓練的模型,而不需要從頭開始訓練。這個程序也稱為移轉學習,可以利用較小的資料集和較短的訓練時間來產生精確的模型。如果模型的卡顯示 可微調屬性設定為是,您就可以微調該模型。
重要
自 2023 年 11 月 30 日起,先前的 Amazon SageMaker Studio 體驗現在名為 Amazon SageMaker Studio Classic。下節專門介紹如何使用 Studio Classic 應用程式。如需使用已更新 Studio 體驗的資訊,請參閱 Amazon SageMaker Studio。
Studio Classic 仍會針對現有工作負載進行維護,但無法再用於加入。您只能停止或刪除現有的 Studio Classic 應用程式,而且無法建立新的應用程式。建議您將工作負載遷移至新的 Studio 體驗。
注意
如需在 Studio 中微調 JumpStart 模型的詳細資訊,請參閱在 Studio 中微調模型
微調資料來源
微調模型時,您可以使用預設資料集或選擇自己位於 Amazon S3 儲存貯體中的資料。
若要瀏覽可用的儲存貯體,請選擇尋找 S3 儲存貯體。這些儲存貯體受到用於設定 Studio Classic 帳戶的權限所限制。您也可以選擇輸入 Amazon S3 儲存貯體位置來指定 Amazon S3 URI。
提示
若要瞭解如何格式化儲存貯體中的資料,請選擇瞭解更多。模型的描述部分包含有關輸入和輸出的詳細資訊。
針對文字模型:
-
儲存貯體必須具有 data.csv 檔案。
-
第一欄必須是用於類別標籤的唯一整數。例如:
1、2、3、4、n -
第二欄必須為字串。
-
第二欄應具有符合模型類型和語言的對應文字。
針對視覺模型:
-
儲存貯體必須具有與類別數目一樣多的子目錄。
-
各個子目錄應包含屬於該類的 .jpg 格式圖像。
注意
Amazon S3 儲存貯體必須與您執行 SageMaker Studio Classic AWS 區域 所在的儲存貯體相同,因為 SageMaker AI 不允許跨區域請求。
微調部署組態
p3 系列是我們建議速度最快的深度學習訓練系列,建議您使用此系列來微調模型。下方圖表顯示每個執行個體類型中的 GPU 數目。您還可以選擇其他可用選項,包括 p2 和 g4 執行個體類型。
| 執行個體類型 | GPU |
|---|---|
| p3.2xlarge | 1 |
| p3.8xlarge | 4 |
| p3.16xlarge | 8 |
| p3dn.24xlarge | 8 |
超參數
您可以自訂用於微調模型的訓練工作的超參數。每個可微調模型的可用超參數視模型而有所不同。如需有關每個可用超參數的資訊,請參閱Amazon SageMaker 中的內建演算法和預先訓練模型中關於所選模型的超參數文件。例如,如需可微調圖像分類 - TensorFlow 超參數的詳細資訊,請參閱影像分類 - TensorFlow 參數。
如果您在未變更超參數的情況下使用文字模型的預設資料集,則會得到幾乎相同的模型。針對視覺模型,預設資料集與用於訓練預先訓練模型的資料集不同,因此您的模型因此會有所不同。
以下超參數在模型中很常見:
-
時期 - 一個時期是整個資料集的一個循環。一個批次包括多個間隔,多個批次最終組成一個時期。執行多個週期,直到模型的精準度達到可接受的程度,或者當誤差率降至可接受的程度以下為止。
-
學習速率 - 值應該在時期之間改變的量。在改良模型時,會推動其內部權重,並檢查錯誤率以查看模型是否有所改善。典型的學習速率是 0.1 或 0.01,其中 0.01 是較小的調整,可能會導致訓練需要很長時間才能收斂,而 0.1 則大得多,可能導致訓練過衝。它是您可以調整以訓練模型的主要超參數之一。請注意,針對文字模型,較小的學習速率要 (BERT 為 5e-5) 可能會帶來更準確的模型。
-
Batch 大小 - 每個間隔從資料集中選擇要傳送到 GPU 進行訓練的記錄數。
在圖像範例中,您可能針對每個 GPU 發送 32 張圖像,因此您的批次大小是 32。如果您選擇具有多個 GPU 的執行個體類型,則該批次會除以 GPU 數目。建議的批次大小會因您使用的資料和模型而有所不同。例如,最佳化圖像資料的方式與處理語言資料的方式就有所不同。
在部署組態段落的執行個體類型圖表中,您可以看到每個執行個體類型的 GPU 數目。從標準建議批次大小開始 (例如視覺模型為 32)。然後,將其乘以您選取的執行個體類型中的 GPU 數目。例如如果您使用的是
p3.8xlarge,則為 32 (批次大小) 乘以 4 (GPU),總計 128,因為您的批次大小會根據 GPU 數量調整。針對像 BERT 這樣的文字模型,請嘗試從批次大小 64 開始,然後根據需要縮小。
訓練輸出
微調程序完成後,JumpStart 會提供模型的相關資訊:父模型、訓練工作名稱、訓練工作 ARN、訓練時間和輸出路徑。輸出路徑是新模型在 Amazon S3 儲存貯體中的位置。資料夾結構使用您提供的模型名稱,且模型檔案位於 /output子資料夾中,而且永遠命名為 model.tar.gz。
範例:s3://bucket/model-name/output/model.tar.gz
設定模型訓練的預設值
您可以為 IAM 角色、VPC 和 KMS 金鑰等參數設定預設值,以預先填入 JumpStart 模型部署和訓練。如需詳細資訊,請參閱設定 JumpStart 模型的預設值。
