本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
GitHub 儲存庫
若要啟動訓練任務,您可以使用來自兩個不同 GitHub 儲存庫的檔案:
這些儲存庫包含啟動、管理和自訂大型語言模型 (LLM) 訓練程序的必要元件。您可以使用儲存庫中的指令碼,來設定和執行 LLM 的訓練任務。
HyperPod 配方儲存庫
使用 SageMaker HyperPod 配方
-
main.py:此檔案會做為主要進入點,用於啟動將訓練任務提交至叢集或 SageMaker 訓練任務的程序的。 -
launcher_scripts:此目錄包含常用指令碼的集合,旨在協助各種大型語言模型 (LLM) 的訓練程序。 -
recipes_collection:此資料夾包含由開發人員提供的預先定義 LLM 配方的編譯。使用者可以將這些配方與其自訂資料結合使用,來訓練根據其特定要求量身打造的 LLM 模型。
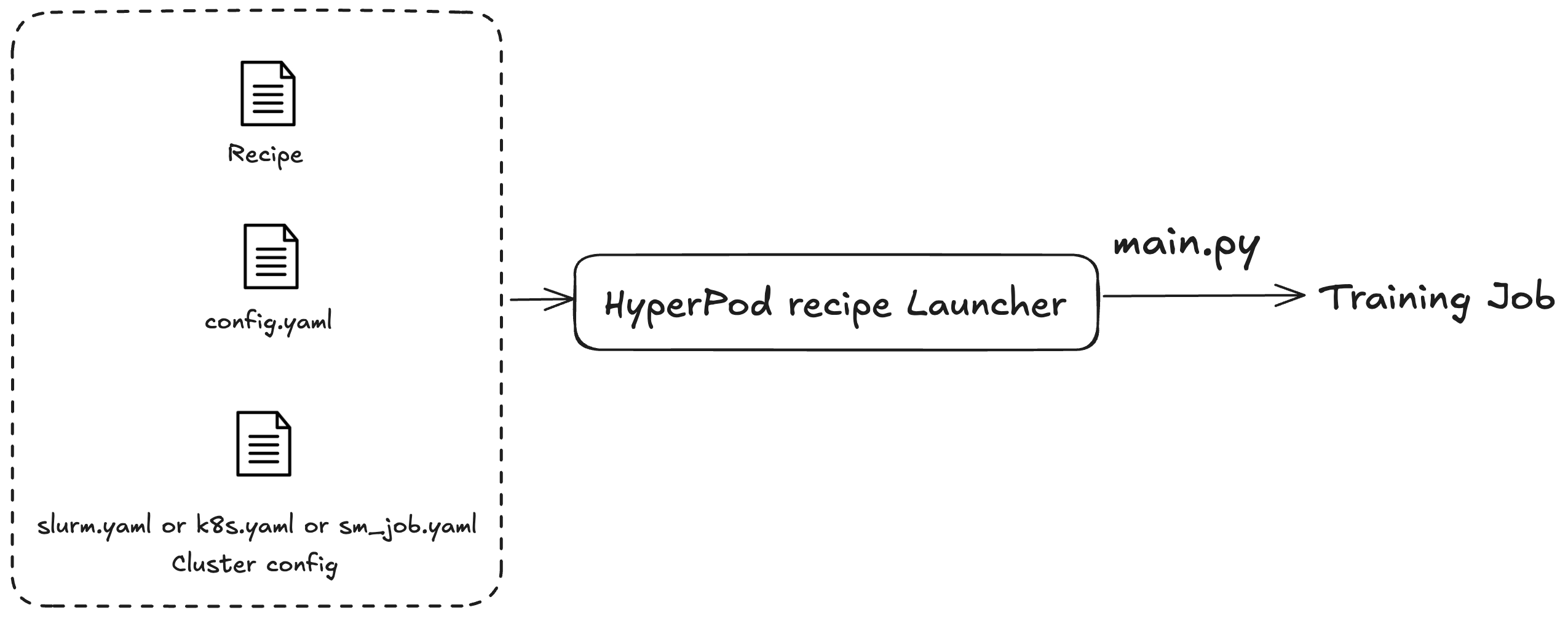
您可以使用 SageMaker HyperPod 配方來啟動訓練或微調任務。無論您使用的叢集為何,提交任務的程序都相同。例如,您可以使用相同的指令碼,將任務提交至 Slurm 或 Kubernetes 叢集。啟動器會根據三個組態檔案來分派訓練任務:
-
一般組態 (
config.yaml):包括常見設定,例如訓練任務中使用的預設參數或環境變數。 -
叢集組態 (叢集):僅限使用叢集的訓練任務。如果您要將訓練任務提交至 Kubernetes 叢集,則可能需要指定磁碟區、標籤等資訊或重新啟動政策。對於 Slurm 叢集,您可能需要指定 Slurm 任務名稱。所有參數都與您正在使用的特定叢集相關。
-
配方 (配方):配方包含訓練任務的設定,例如模型類型、碎片程度或資料集路徑。例如,您可以將 Llama 指定為訓練模型,並使用模型或資料平行處理技術對其進行訓練,例如跨八個機器的全碎片分散式平行 (FSDP)。您也可以針對訓練任務指定不同的檢查點頻率或路徑。
指定了配方後,您可以執行啟動器指令碼,透過 main.py 進入點根據組態在叢集上指定端對端訓練任務。對於您使用的每個配方,都有隨附的 Shell 指令碼位於 launch_scripts 資料夾中。這些範例會逐步引導您提交和啟動訓練任務。下圖說明 SageMaker HyperPod 配方啟動器如何根據上述內容將訓練任務提交至叢集。目前,SageMaker HyperPod 配方啟動器建置在 Nvidia NeMo Framework 啟動器之上。如需詳細資訊,請參閱 NeMo 啟動器指南
HyperPod 配方轉接器儲存庫
SageMaker HyperPod 訓練轉接器是一種訓練架構。您可以使用它來管理訓練任務的整個生命週期。使用轉接器將您模型的預先訓練或微調分散到多部電腦。轉接器使用不同的平行化技術來分散訓練。它也會處理儲存檢查點的實作和管理。如需詳細資訊,請參閱進階設定。
使用 SageMaker HyperPod 配方轉接器儲存庫
-
src:此目錄包含大規模語言模型 (LLM) 訓練的實作,涵蓋模型平行化、混合精準度訓練和檢查點管理等各種功能。 -
examples:此資料夾提供範例集合,示範如何建立用於訓練 LLM 模型的進入點,做為使用者的實際指南。
