本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
Amazon Redshift 資料倉儲的架構元件
我們建議您對 Amazon Redshift 資料倉儲中的核心架構元件有基本的了解。這些知識可協助您進一步了解如何設計查詢和資料表,以獲得最佳效能。
Amazon Redshift 中的資料倉儲包含下列核心架構元件:
-
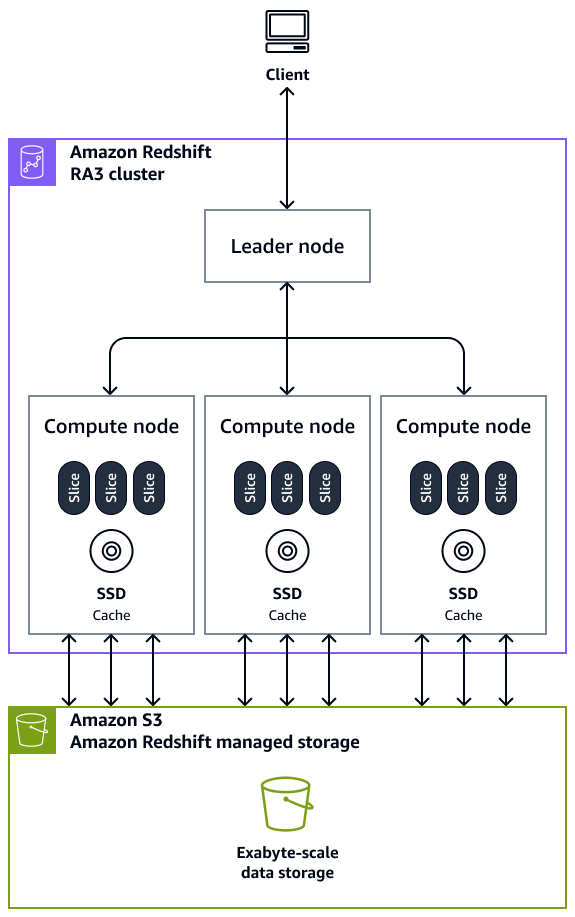
叢集 – 叢集由一或多個運算節點組成,是 Amazon Redshift 資料倉儲的核心基礎設施元件。運算節點對外部應用程式是透明的,但您的用戶端應用程式只會直接與領導節點互動。典型叢集有兩個或多個運算節點。運算節點會透過領導節點進行協調。
-
領導節點 – 領導節點會管理用戶端程式和所有運算節點的通訊。領導者節點也會準備每當查詢提交至叢集時執行查詢的計劃。當計劃準備就緒時,領導節點會編譯程式碼、將編譯的程式碼分發給運算節點,然後將資料配量指派給每個運算節點來處理查詢結果。
-
運算節點 – 運算節點會執行查詢。領導節點會針對計劃的個別元素編譯程式碼,以執行查詢並將程式碼指派給個別運算節點。運算節點會執行編譯過的程式碼,並將中間的結果傳回領導節點,以進行最終的彙總。每個運算節點都有自己的專用 CPU、記憶體和連接的磁碟儲存。隨著工作負載的增長,您可以藉由增加節點的數量、將節點的類型升級,或是同時實行這兩種做法,來增加叢集的運算容量和儲存容量。
-
節點配量 – 運算節點會分割成稱為配量的單位。運算節點中的每個配量都會配置一部分的節點記憶體和磁碟空間,用於處理指派給節點的部分工作負載。這些分割接著會平行運作,以完成操作。資料會根據特定資料表的分佈樣式和分佈索引鍵,在配量之間分佈。資料的均勻分佈可讓 Amazon Redshift 將工作負載平均指派給配量,並最大化平行處理的優勢。每個運算節點的配量數目取決於節點的類型。如需詳細資訊,請參閱 Amazon Redshift 文件中的 Amazon Redshift 中的叢集和節點 。
-
大規模平行處理 (MPP) – Amazon Redshift 使用 MPP 架構快速處理資料,甚至是複雜的查詢和大量的資料。多個運算節點會在部分資料上執行相同的查詢程式碼,以最大化平行處理。
-
用戶端應用程式 – Amazon Redshift 與各種資料載入、擷取、轉換和載入 (ETL)、商業智慧 (BI) 報告、資料探勘和分析工具整合。所有用戶端應用程式只會透過領導節點與叢集通訊。
下圖顯示 Amazon Redshift 資料倉儲的架構元件如何協同運作以加速查詢。
查詢生命週期有七個階段:
-
查詢接收和剖析:
-
領導者節點接收查詢並剖析 SQL。
-
剖析器會產生初始查詢樹狀結構,代表原始查詢的邏輯結構。
-
Amazon Redshift 將此查詢樹饋送至查詢最佳化工具。
-
-
查詢最佳化:
-
最佳化工具會評估查詢,並視需要將其重寫以最大化效率。
-
此最佳化程序可能涉及建立多個相關查詢來取代單一查詢。
-
-
查詢計畫產生:
-
最佳化工具會產生查詢計畫 (或多個計畫,如有需要) 以供執行。
-
查詢計畫會指定執行選項,例如聯結類型、聯結順序、彙總方法和資料分佈需求。
-
-
執行引擎翻譯:
-
執行引擎會將查詢計畫轉換為分散的步驟、區段和串流:
-
步驟 – 代表查詢執行期間所需的個別操作。您可以合併步驟,以允許運算節點執行查詢、聯結或其他資料庫操作。
-
客群 – 結合單一程序可執行的數個步驟。這是運算節點配量可執行的最小編譯單位。(配量是 Amazon Redshift 中平行處理的單位。)
-
串流 – 分散在可用運算節點配量的區段集合。
-
-
執行引擎會根據這些步驟、區段和串流產生編譯的程式碼。編譯的程式碼執行速度比解譯的程式碼更快,並消耗較少的運算容量。
-
領導節點會將編譯的程式碼廣播至運算節點。
-
-
平行執行:
-
每個串流都會執行此步驟一次。
-
運算節點配量會平行執行查詢區段。
-
在此過程中,Amazon Redshift 會最佳化網路通訊、記憶體用量和磁碟管理,將中繼結果從一個查詢計畫步驟傳遞到下一個步驟。
-
此最佳化有助於更快速的查詢執行。
-
-
串流處理:
-
每個串流都會執行此步驟一次。
-
引擎會為每個串流建立可執行區段,以有效率地平行處理。
-
-
最終排序和彙總:
-
領導節點會處理查詢所需的任何最終排序或彙總。
-
完成後,領導節點會將結果傳回給用戶端。
-
如需架構元件的資訊,請參閱 Amazon Redshift 文件中的資料倉儲系統架構。
