本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
智慧快閃記憶體快取
Exadata Smart Flash 快取功能會在快閃記憶體中快取資料庫物件,以加快存取資料庫物件的速度。智慧快閃記憶體快取可以判斷需要快取哪些類型的資料區段和操作。它可識別不同類型的 I/O 請求,以便不可重複的資料存取 (例如 RMAN 備份 I/O) 不會從快取排清資料庫區塊。您可以使用 ALTER命令將熱資料表和索引移至 Smart Flash 快取。當您使用回寫快閃記憶體快取功能時,智慧型快閃記憶體也可以快取資料庫區塊寫入操作。
Exadata 儲存伺服器軟體也提供智慧快閃記憶體記錄,以加速重做日誌寫入操作,並減少日誌檔案同步事件的服務時間。此功能會同時對快閃記憶體和磁碟控制器快取執行重做寫入操作,並在兩者中的第一個完成時完成寫入操作。
下列兩個統計資料提供 Exadata Smart Flash 快取效能的快速洞見。這些可用於動態效能檢視,例如 V$SYSSTAT和 AWR 報告的全域活動統計資料或執行個體活動統計資料區段。
-
Cell Flash Cache read hits– 記錄在 Smart Flash 快取中找到相符項目的讀取請求數量。 -
Physical read requests optimized– 記錄透過 Smart Flash 快取或儲存索引最佳化的讀取請求數目。
從儲存單元收集的 Exadata 指標也有助於了解工作負載如何使用 Smart Flash 快取。下列 CellCLI
CellCLI> LIST METRICDEFINITION ATTRIBUTES NAME,DESCRIPTION WHERE OBJECTTYPE = FLASHCACHE FC_BYKEEP_DIRTY "Number of megabytes unflushed for keep objects on FlashCache" FC_BYKEEP_OLTP "Number of megabytes for OLTP keep objects in flash cache" FC_BYKEEP_OVERWR "Number of megabytes pushed out of the FlashCache because of space limit for keep objects" FC_BYKEEP_OVERWR_SEC "Number of megabytes per second pushed out of the FlashCache because of space limit for keep objects" ...
遷移至 AWS
智慧快閃記憶體快取不存在於 上 AWS。在將 Exadata 工作負載遷移至 時,有幾個選項可以緩解此挑戰,並避免效能降低 AWS,包括以下章節所討論的內容:
-
使用擴充記憶體執行個體
-
將執行個體與 NVMe 型執行個體存放區搭配使用
-
使用低延遲和高輸送量的 AWS 儲存選項
不過,這些選項無法重現 Smart Flash 快取行為,因此您需要評估工作負載的效能,以確保其持續符合您的效能 SLAs。
擴充記憶體執行個體
Amazon EC2 提供許多高記憶體執行個體,包括具有 12 TiB 和 24 TiB 記憶體的執行個體
具有 NVMe 型執行個體存放區的執行個體
執行個體存放區提供執行個體的臨時區塊層級儲存。這個儲存空間位於實際連接到主機電腦的磁碟上。執行個體存放區可將資料儲存在 NVMe 磁碟上,讓工作負載達到低延遲和更高的輸送量。執行個體存放區中的資料只會在執行個體的生命週期內持續存在,因此執行個體存放區非常適合暫時資料表空間和快取。根據執行個體的類型和 I/O 大小,執行個體存放區可以在微秒的延遲下支援數百萬 IOPS 和超過 10 Gbps 的輸送量。如需執行個體存放區讀取/寫入 IOPS 和不同執行個體類別輸送量支援的詳細資訊,請參閱 Amazon EC2 文件中的一般用途、運算最佳化、記憶體最佳化和儲存最佳化執行個體。
在 Exadata 中,資料庫快閃記憶體快取允許使用者在平均 I/O 延遲為 100 微秒的執行個體存放磁碟區上定義第二個緩衝區快取層,以改善讀取工作負載的效能。您可以設定兩個資料庫初始化參數來啟用此快取:
-
db_flash_cache_file = /<device_name> -
db_flash_cache_size = <size>G
您也可以在執行個體存放區放置資料庫檔案,並使用 Oracle Automatic Storage Management (ASM) 和 Data Guard 提供的備援,在執行個體存放區遺失資料時,為託管在 Amazon EC2 上的 Oracle 資料庫設計高效能架構。這些架構模式非常適合在低延遲時需要極端 I/O 輸送量的應用程式,並可在特定故障情況下提供較高的 RTO 來復原系統。下列各節簡短討論兩個架構,其中包括 NVMe 執行個體存放區上託管的資料庫檔案。
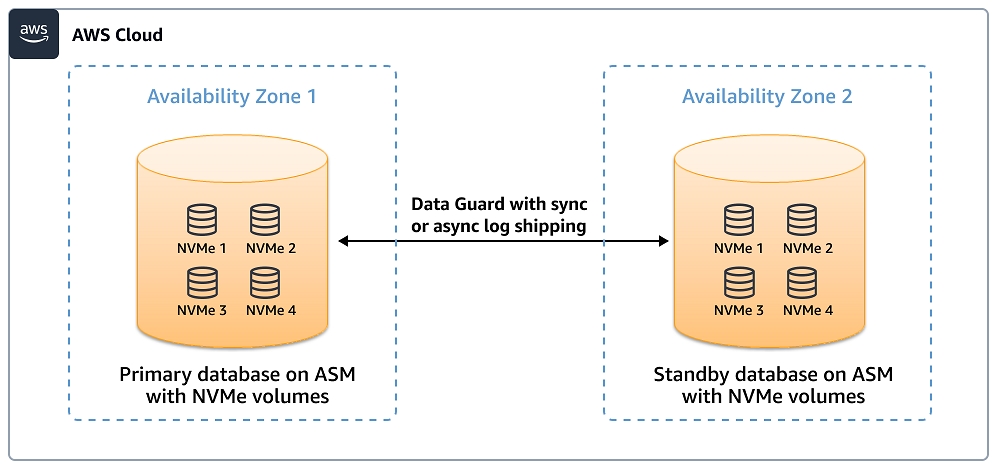
架構 1。資料庫託管在主要執行個體和待命執行個體上的執行個體存放區上,並搭配 Data Guard 進行資料保護
在此架構中,資料庫託管在 Oracle ASM 磁碟群組上,以跨多個執行個體存放區磁碟區分配 I/O,以實現高輸送量、低延遲的 I/O。 Data Guard 待命會放置在相同或另一個可用區域中,以防止執行個體存放區中的資料遺失。磁碟群組組態取決於 RPO 和遞交延遲。如果執行個體存放區因任何原因在主要執行個體上遺失,資料庫可能會容錯移轉為待命,且資料遺失為零或最小。您可以設定 Data Guard 觀察程式程序來自動化容錯移轉。讀取和寫入操作都受益於執行個體存放區提供的高輸送量和低延遲。
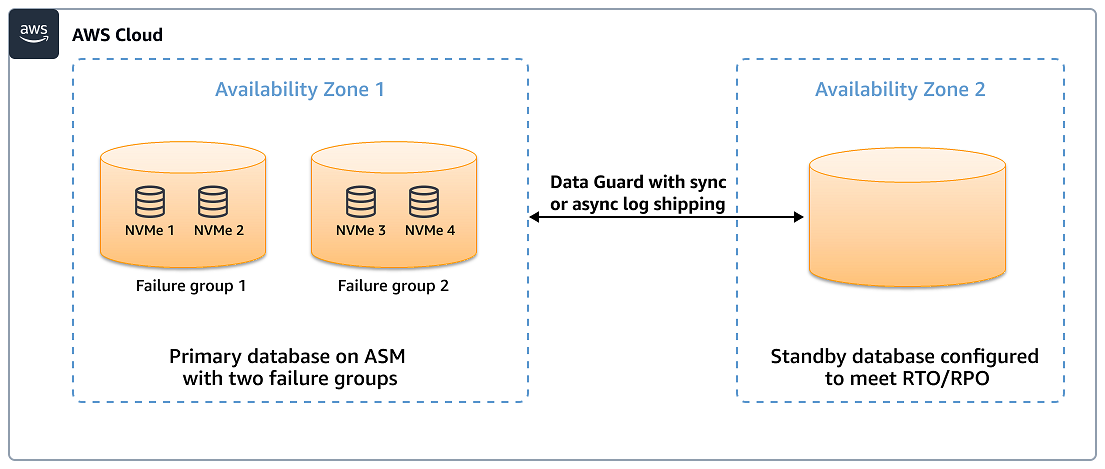
架構 2。資料庫託管在 ASM 磁碟群組上,其中有兩個失敗群組,結合 EBS 磁碟區和執行個體存放區
在此架構中,所有讀取操作都是使用 ASM_PREFERRED_READ_FAILURE_GROUP 參數從本機執行個體存放區執行。寫入操作同時適用於執行個體存放區磁碟區和 Amazon Elastic Block Store (Amazon EBS) 磁碟區。不過,Amazon EBS 頻寬專用於寫入操作,因為讀取操作會卸載至執行個體儲存體磁碟區。如果執行個體存放區遺失資料,您可以根據 EBS 磁碟區或待命資料庫從 ASM 故障群組復原資料。如需詳細資訊,請參閱 Oracle 白皮書使用 ASM 鏡像和故障群組
Amazon RDS for Oracle 支援執行個體存放區上的資料庫智慧快閃記憶體快取和暫存資料表空間。Oracle 資料庫工作負載可以使用此功能來實現讀取操作的較低延遲、更高的輸送量,以及其他資料庫 I/O 操作的 Amazon EBS 頻寬有效利用率。db.m5d、db.r5d、db.x2idn 和 db.x2iedn 執行個體類別目前支援此功能。如需最新資訊,請參閱 Amazon RDS 文件中的 RDS for Oracle 執行個體存放區的支援執行個體類別。
適用於需要低延遲和高輸送量之工作負載的 AWS 儲存選項
Amazon RDS for Oracle 目前支援的 EBS 磁碟區類型,gp2、gp3 和 io1
對於 Amazon EC2 上的自我管理 Oracle 資料庫部署,Amazon EBS io2 和 io2 Block Express EBS 磁碟區
在 Amazon EC2 上部署為自我管理 Oracle 資料庫時,需要更高輸送量或微秒延遲的工作負載可以使用不是以 Amazon EBS 為基礎的儲存磁碟區。例如,Amazon FSx for OpenZFS
