本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
在資料庫分解期間解耦資料表關係
本節提供在單體資料庫分解期間分解複雜資料表關係和 JOIN 操作的指引。資料表聯結會根據資料表之間的相關資料欄,結合來自兩個或多個資料表的資料列。分隔這些關係的目標是減少資料表之間的高度耦合,同時維持微型服務之間的資料完整性。
非標準化策略
非標準化是一種資料庫設計策略,透過合併或複製跨資料表的資料,刻意引入備援。將大型資料庫分成小型資料庫時,跨服務複製一些資料可能很合理。例如,在行銷服務和訂單服務中存放基本客戶詳細資訊,例如姓名和電子郵件地址,無需持續進行跨服務查詢。行銷服務可能需要行銷活動目標的客戶偏好設定和聯絡資訊,而訂單服務則需要相同的資料以進行訂單處理和通知。雖然這會產生一些資料備援,但可以大幅提升服務效能和獨立性,讓行銷團隊在不依賴即時客戶服務查詢的情況下操作行銷活動。
實作非標準化時,請專注於透過仔細分析資料存取模式來識別的經常存取欄位。您可以使用工具,例如Oracle AWR報告或 pg_stat_statements,來了解通常一起擷取哪些資料。網域專家也可以提供對自然資料分組的寶貴洞見。請記住,去標準化不是all-or-nothing的方法,只是可明顯改善系統效能或降低複雜相依性的重複資料。
Reference-by-key策略
reference-by-key策略是一種資料庫設計模式,其中實體之間的關係是透過唯一的金鑰來維護,而不是儲存實際的相關資料。現代微服務通常只儲存相關資料的唯一識別符,而不是傳統的外部金鑰關係。例如,訂單服務不會將所有客戶詳細資訊保留在訂單資料表中,而是只會存放客戶 ID,並在需要時透過 API 呼叫擷取其他客戶資訊。此方法可維持服務獨立性,同時確保存取相關資料。
CQRS 模式
命令查詢責任隔離 (CQRS) 模式會區隔資料存放區的讀取和寫入操作。此模式在具有高效能需求的複雜系統中特別有用,尤其是具有非對稱讀取/寫入負載的系統。如果您的應用程式經常需要來自多個來源的資料組合,您可以建立專用 CQRS 模型,而不是複雜的聯結。例如,不是在每個請求上加入 Product、 Pricing和 Inventory資料表,而是維護包含必要資料的合併Product Catalog資料表。這種方法的好處可能會超過額外資料表的成本。
假設 Product、 PriceInventory和服務經常需要產品資訊的情況。建立專用服務,而不是將這些服務設定為直接存取共用資料表Product Catalog。此服務會維護自己的資料庫,其中包含合併的產品資訊。它可做為產品相關查詢的單一事實來源。當產品詳細資訊、價格或庫存層級變更時,個別服務可以發佈事件來更新Product Catalog服務。這可提供資料一致性,同時保持服務獨立性。下圖顯示此組態,其中 Amazon EventBridge
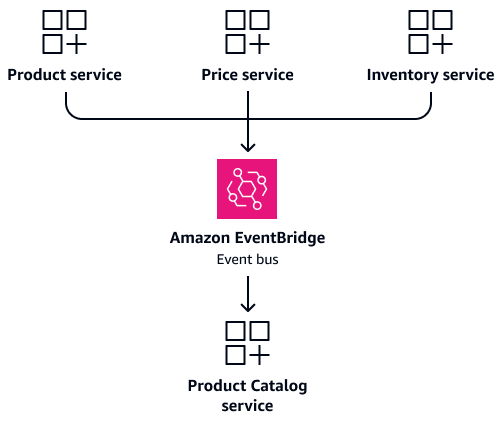
如下一節所述事件型資料同步,透過事件保持 CQRS 模型的更新狀態。當產品詳細資訊、價格或庫存層級變更時,個別的服務會發佈事件。Product Catalog 服務會訂閱這些事件並更新其合併檢視。這可在沒有複雜聯結的情況下提供快速讀取,並維持服務獨立性。
事件型資料同步
事件型資料同步是擷取資料變更並將其傳播為事件的模式,可讓不同的系統或元件維持同步資料狀態。當資料變更時,而不是立即更新所有相關資料庫,請發佈事件以通知訂閱的服務。例如,當客戶變更服務中的運送地址時Customer,CustomerUpdated事件會根據每個OrderDelivery服務的排程啟動服務和服務的更新。這種方法使用靈活、可擴展的事件驅動更新來取代剛性資料表聯結。有些服務可能會短暫有過時的資料,但權衡是改善系統可擴展性和服務獨立性。
實作資料表聯結的替代方案
使用讀取操作開始資料庫分解,因為它們通常更易於遷移和驗證。讀取路徑穩定後,請處理更複雜的寫入操作。對於關鍵的高效能需求,請考慮實作 CQRS 模式。針對讀取使用個別的最佳化資料庫,同時針對寫入維護另一個資料庫。
透過為跨服務呼叫新增重試邏輯並實作適當的快取層來建置彈性系統。密切監控服務互動,並設定資料一致性問題的提醒。最終目標是不是任何地方都完美的一致性,而是建立獨立服務,其效能良好,同時為您的業務需求維持可接受的資料準確性。
微服務解耦的性質在資料管理中引入了以下新的複雜性:
-
資料已分發。資料現在位於由獨立 服務管理的個別資料庫中。
-
跨服務進行即時同步通常不切實際,需要最終一致性模型。
-
先前在單一資料庫交易中發生的操作現在橫跨多個 服務。
若要解決這些挑戰,請執行下列動作:
-
實作事件驅動架構 – 使用訊息佇列和事件發佈,在 服務之間傳播資料變更。如需詳細資訊,請參閱在無伺服器土地上建置事件驅動架構
。 -
採用 saga 協同運作模式 – 此模式可協助您管理分散式交易,並維護跨服務的資料完整性。如需詳細資訊,請參閱 AWS 部落格上的使用saga 協同運作模式建置無伺服器分散式應用程式
。 -
故障設計 – 整合重試機制、斷路器和補償交易,以處理網路問題或服務故障。
-
使用版本戳記 – 追蹤資料版本以管理衝突,並確保套用最新的更新。
-
定期對帳 – 實作定期資料同步程序,以擷取和修正任何不一致。
以案例為基礎的範例
下列結構描述範例有兩個資料表:Customer資料表和Order資料表:
-- Customer table CREATE TABLE customer ( customer_id INT PRIMARY KEY, first_name VARCHAR(100), last_name VARCHAR(100), email VARCHAR(255), phone VARCHAR(20), address TEXT, created_at TIMESTAMP ); -- Order table CREATE TABLE order ( order_id INT PRIMARY KEY, customer_id INT, order_date TIMESTAMP, total_amount DECIMAL(10,2), status VARCHAR(50), FOREIGN KEY (customer_id) REFERENCES customers(id) );
以下是如何使用非標準化方法的範例:
CREATE TABLE order ( order_id INT PRIMARY KEY, customer_id INT, -- Reference only customer_first_name VARCHAR(100), -- Denormalized customer_last_name VARCHAR(100), -- Denormalized customer_email VARCHAR(255), -- Denormalized order_date TIMESTAMP, total_amount DECIMAL(10,2), status VARCHAR(50) );
新Order資料表具有非標準化的客戶名稱和電子郵件地址。customer_id 會參考 ,而且Customer資料表沒有外部金鑰限制。以下是此非標準化方法的優點:
-
Order服務可以顯示具有客戶詳細資訊的訂單歷史記錄,而且不需要對Customer微服務進行 API 呼叫。 -
如果
Customer服務關閉,Order服務仍可正常運作。 -
訂單處理和報告的查詢執行速度更快。
下圖顯示使用 getOrder(customer_id)、getOrder(order_id)getCustomerOders(customer_id)、 和 createOrder(Order order) API 呼叫微Order服務擷取訂單資料的單體應用程式。
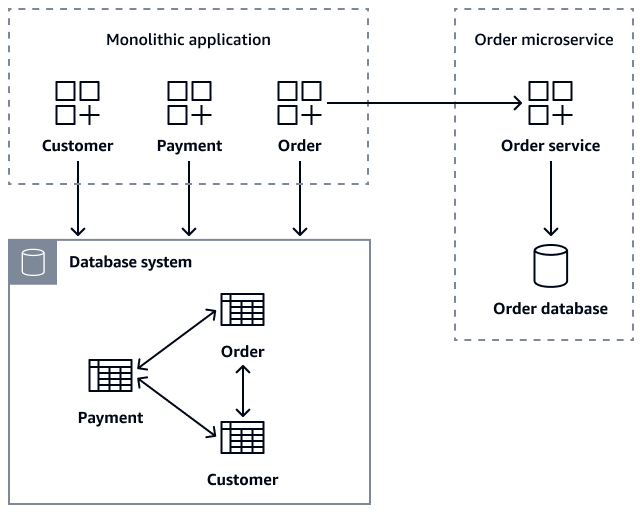
在微服務遷移期間,您可以維護單體資料庫中的Order資料表作為轉換安全措施,以確保舊版應用程式保持正常運作。不過,所有與訂單相關的新操作都必須透過Order微服務 API 路由,此 API 會維護自己的資料庫,同時寫入舊版資料庫做為備份。此雙寫入模式提供安全網路。它允許漸進遷移,同時保持系統穩定性。在所有客戶成功遷移到新的微服務後,您可以棄用單體資料庫中的舊版Order資料表。將單體應用程式及其資料庫分解為不同的CustomerOrder微服務之後,維護資料一致性會成為主要挑戰。
