本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
DR Orchestrator Framework 概觀
DR Orchestrator Framework 提供一鍵式解決方案,可協調和自動化 AWS 資料庫的跨區域 DR。它使用 AWS Step Functions和 AWS Lambda 在容錯移轉和容錯回復期間執行必要的步驟。Step Functions 狀態機器提供協調器設計中決策的基礎。用於執行容錯移轉或容錯回復動作的 API 操作會編碼為從狀態機器內呼叫的 Lambda 函數。Lambda 函數會執行 適用於 Python (Boto3) 的 AWS SDK
DR Orchestrator Framework 包含兩個主要狀態機器,對應至容錯移轉和容錯回復階段。
對於 Amazon RDS,容錯移轉階段會將跨區域 RDS 僅供讀取複本提升為獨立的資料庫執行個體。對於 Amazon Aurora,當主要區域在罕見且非預期的中斷期間關閉時,其寫入器節點無法使用。寫入器節點與次要叢集之間的複寫會停止。您必須從全域資料庫分離次要叢集,並將其提升為獨立叢集。應用程式可以連接並傳送寫入流量到獨立叢集。您可以使用這個相同的程序,將全域資料庫的主要資料庫叢集切換到次要區域。 將此方法用於受控案例,如下所示:
-
操作維護
-
規劃的操作程序
-
將 Amazon ElastiCache (Redis OSS) 次要叢集提升為新的主要叢集
容錯回復階段會在即時主要區域和新的次要區域之間建立資料的即時複寫。
請務必了解 DR Orchestrator 僅適用於資料庫。參考這些資料庫且位於相同區域的所有應用程式,可能需要個別的串聯容錯移轉解決方案。在資料庫容錯移轉至次要區域後,需要更新應用程式以連線至新的資料庫執行個體,該執行個體將做為資料來源。
容錯移轉程序
若要執行容錯移轉,請執行 DR Orchestrator FAILOVER 狀態機器。在此階段,次要資料庫已存在於次要區域中,可以是僅供讀取複本 (Amazon RDS) 或次要叢集 (Amazon Aurora)。當您執行 DR Orchestrator FAILOVER 狀態機器時, 它會提升次要資料庫成為主要資料庫。
DR Orchestrator FAILOVER 架構
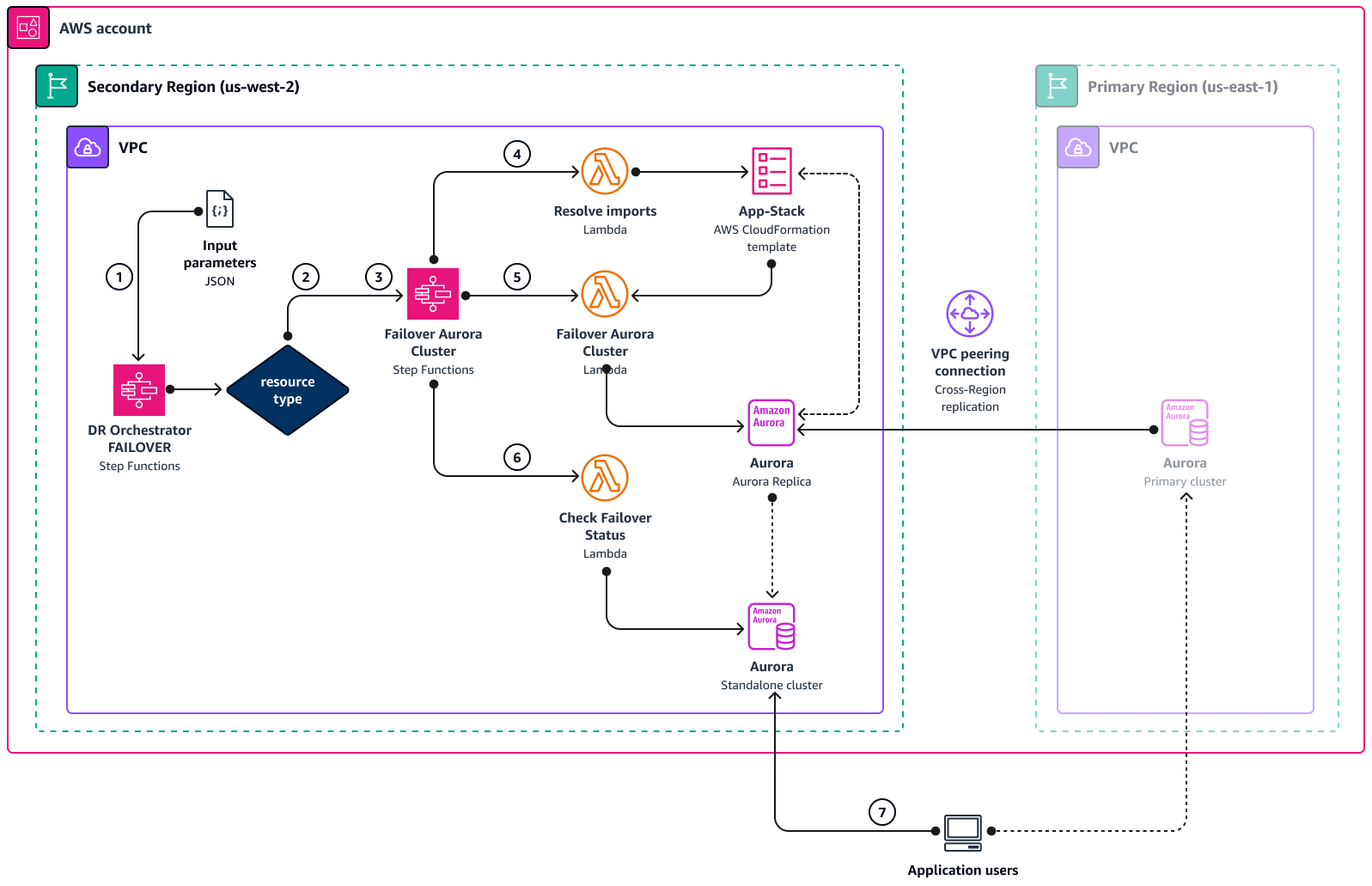
下圖顯示使用 DR Orchestrator 時 Amazon Aurora 容錯移轉程序的概念。Amazon Aurora 和 Amazon ElastiCache 使用相同的工作流程,但使用不同的狀態機器和 Lambda 函數。
-
DR Orchestrator FAILOVER狀態機器會讀取輸入 JSON 參數。 -
根據
resourceType參數,狀態機器會呼叫其他 狀態機器:Failover Aurora Cluster、Promote RDS Read Replica或Failover ElastiCache。如果輸入中傳遞多個資源,這些狀態機器會平行執行。 -
Failover Aurora Cluster狀態機器會在下列三個步驟中呼叫 Lambda 函數。 -
Resolve importsLambda 函數"! import <export-variable-name>"會以App-StackAWS CloudFormation 範本中的實際值解析。 -
Lambda
Failover Aurora Cluster函數會將僅供讀取複本 提升為獨立資料庫執行個體。 -
Lambda
Check Failover Status函數會檢查提升資料庫執行個體的狀態。狀態為可用後,Lambda 函數會將成功字符傳回給呼叫狀態機器並完成。 -
您可以將應用程式重新導向至 DR 區域 (
us-west-2) 中的獨立資料庫,該區域現在是主要資料庫。
容錯回復程序
在您的前一個主要區域 (us-east-1) 再次啟動後,您可以容錯移轉回該區域,讓 中的資料庫再次us-east-1成為主要區域。若要啟動容錯回復,請執行 DR Orchestrator FAILBACK 狀態機器。如名稱所示,此狀態機器會開始將新主要區域 (us-west-2) 中的變更複寫回先前的主要區域 (us-east-1),該區域做為目前的次要區域。
在兩個區域之間建立複寫之後,您可以啟動容錯回復。若要容錯回復並返回原始主要區域 (us-east-1),請在目前的次要區域 (us-east-1) 中執行 DR Orchestrator FAILOVER 狀態機器,將其提升為主要區域。
DR Orchestrator FAILBACK 架構
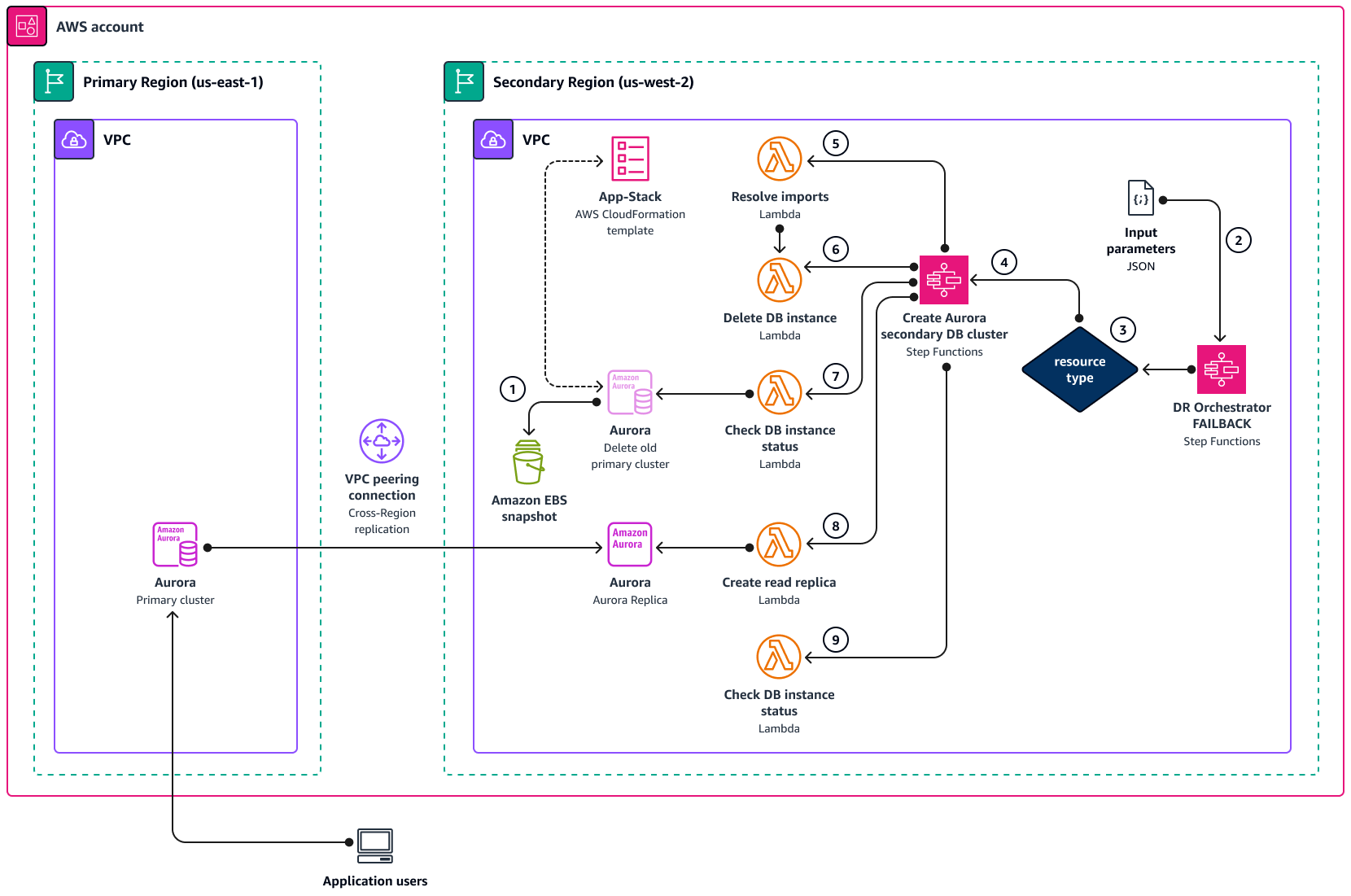
下圖顯示使用 DR Orchestrator 時 Amazon Aurora 的容錯回復程序概念。
-
開始容錯回復之前,請手動建立資料庫快照,以便在執行根本原因分析 (RCA) 時使用。
此外,請停用上一個主要區域 () 中 Aurora 叢集
DeletionProtection的us-east-1。 -
DR Orchestrator FAILBACK狀態機器會讀取輸入 JSON 參數。 -
根據
resourceType,DR Orchestrator FAILBACK狀態機器會呼叫Create Aurora Secondary DB Cluster狀態機器。 -
Create Aurora Secondary DB Cluster狀態機器會在下列五個步驟中呼叫 Lambda 函數。 -
Resolve importLambda 函數"! import <export-variable-name>"會以App-StackCloudFormation 範本中的實際值解析。 -
Delete DB InstanceLambda 函數會刪除先前的主要執行個體。 -
Check DB instance statusLambda 函數會檢查 ,Delete DB Instance status直到刪除資料庫為止。 -
Create Read ReplicaLambda 函數會從位於新主要區域的資料庫執行個體,在次要區域中建立僅供讀取複本。 -
Check DB instance statusLambda 函數會檢查僅供讀取複本資料庫執行個體狀態。當狀態為可用時,Lambda 函數會將成功字符傳回至呼叫狀態機器,該機器已完成。
DR 協調器失敗
在主要區域 (us-east-1) 關閉時或在營運維護等計劃事件期間,在 DR 事件中使用 DR Orchestrator FAILOVER 狀態機器。
您可以呼叫 函數,透過單一或多個資料庫平行失敗。
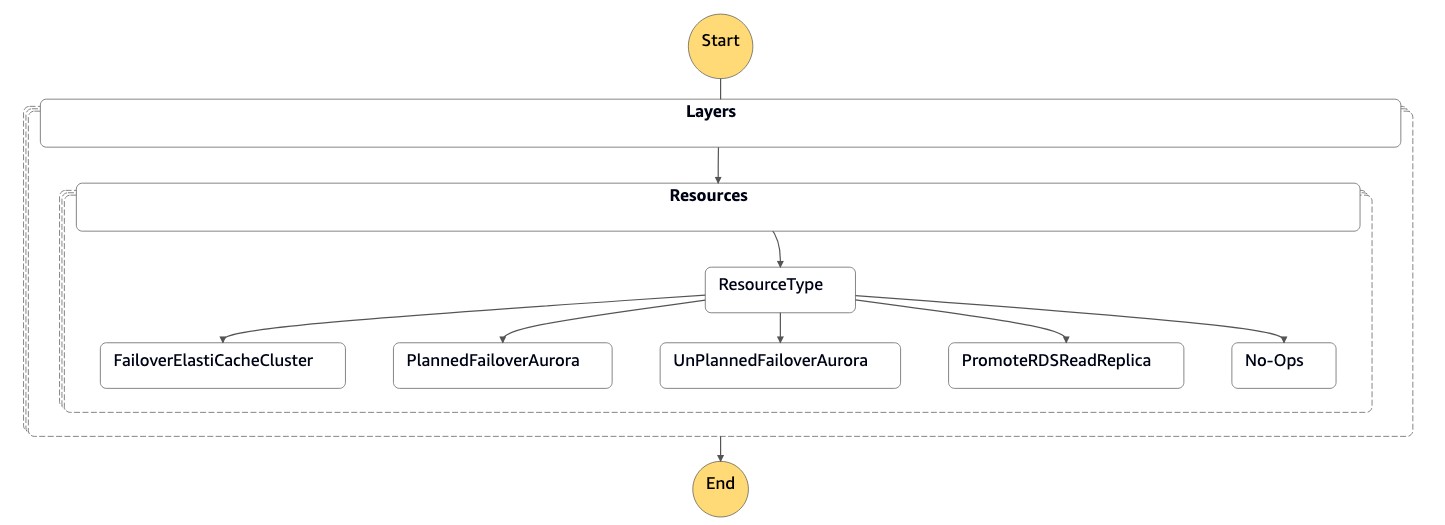
狀態機器接受 JSON 格式的參數,如下列程式碼所示:
{ "StatePayload": [ { "layer": 1, "resources": [ { "resourceType": "PromoteRDSReadReplica", "resourceName": "Promote RDS MySQL Read Replica", "parameters": { "RDSInstanceIdentifier": "!Import rds-mysql-instance-identifier", "TargetClusterIdentifier": "!Import rds-mysql-instance-global-arn" } }, { "resourceType": "FailoverElastiCacheCluster", "resourceName": "Failover ElastiCache Cluster", "parameters": { "GlobalReplicationGroupId": "!Import demo-redis-cluster-global-replication-group-id", "TargetRegion": "!Import demo-redis-cluster-target-region", "TargetReplicationGroupId": "!Import demo-redis-cluster-target-replication-group-id" } } ] } ] }
參數詳細資訊
下表顯示DR Orchestrator FAILOVER狀態機器使用的參數。
| 參數名稱 | 說明 | 預期值 |
|---|---|---|
layer (必要:數字) |
處理序列。在執行第 2 層資源之前,必須先執行第 1 層中定義的所有資源。 | 1 或 2,以此類推 |
| 資源 (必要:字典陣列) | 單一 layer 內的所有資源都會平行執行。 |
|
resourceType (必要:字串) |
用於識別資源的資源類型 | PromoteRDSReadReplica 或 FailoverElastiCacheCluster |
resourceName (選用:字串) |
識別這些資源所屬的應用程式產品組合 | Promote RDS for MySQL Read Replica |
| 參數 (必要:字典陣列) | 容錯移轉或容錯回復 AWS 資料庫所需的參數清單 |
|
DR Orchestrator 失敗
當前一個主要區域 (us-east-1) 啟動時,在 DR 事件之後使用 DR Orchestrator FAILBACK 狀態機器。您可以從新的主要區域 (us-west-2) 在先前的主要區域中建立 Amazon RDS 的僅供讀取複本,以符合您的 DR 策略。由於這是計劃的事件,因此您可以在週末或離峰上班時間排程此活動,並估計停機時間。
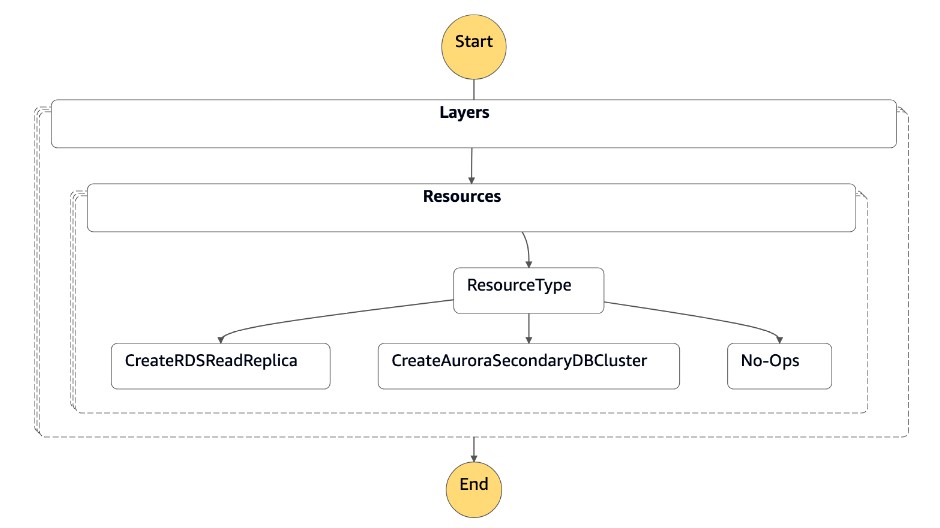
狀態機器接受 JSON 格式的參數,如下列程式碼所示:
{ "StatePayload": [ { "layer": 1, "resources": [ { "resourceType": "CreateRDSReadReplica", "resourceName": "Create RDS for MySQL Read Replica", "parameters": { "RDSInstanceIdentifier": "!Import rds-mysql-instance-identifier", "TargetClusterIdentifier": "!Import rds-mysql-instance-global-arn", "SourceRDSInstanceIdentifier": "!Import rds-mysql-instance-source-identifier", "SourceRegion": "!Import rds-mysql-instance-SourceRegion", "MultiAZ": "!Import rds-mysql-instance-MultiAZ", "DBInstanceClass": "!Import rds-mysql-instance-DBInstanceClass", "DBSubnetGroup": "!Import rds-mysql-instance-DBSubnetGroup", "DBSecurityGroup": "!Import rds-mysql-instance-DBSecurityGroup", "KmsKeyId": "!Import rds-mysql-instance-KmsKeyId", "BackupRetentionPeriod": "7", "MonitoringInterval": "60", "StorageEncrypted": "True", "EnableIAMDatabaseAuthentication": "True", "DeletionProtection": "True", "CopyTagsToSnapshot": "True", "AutoMinorVersionUpgrade": "True", "Port": "!Import rds-mysql-instance-DBPortNumber", "MonitoringRoleArn": "!Import rds-mysql-instance-RDSMonitoringRole" } } ] } ] }
