本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
使用 Apache Spark 處理 Iceberg 資料表
本節提供使用 Apache Spark 與 Iceberg 資料表互動的概觀。這些範例是可在 Amazon EMR 或 上執行的樣板程式碼 AWS Glue。
注意:與 Iceberg 資料表互動的主要界面是 SQL,因此大多數範例會將 Spark SQL 與 DataFrames API 結合。
建立和寫入 Iceberg 資料表
您可以使用 Spark SQL 和 Spark DataFrames 來建立資料,並將資料新增至 Iceberg 資料表。
使用 Spark SQL
若要寫入 Iceberg 資料集,請使用標準 Spark SQL 陳述式,例如 CREATE TABLE和 INSERT INTO。
未分割的資料表
以下是使用 Spark SQL 建立未分割 Iceberg 資料表的範例:
spark.sql(f""" CREATE TABLE IF NOT EXISTS {CATALOG_NAME}.{DB_NAME}.{TABLE_NAME}_nopartitions ( c_customer_sk int, c_customer_id string, c_first_name string, c_last_name string, c_birth_country string, c_email_address string) USING iceberg OPTIONS ('format-version'='2') """)
若要將資料插入至未分割的資料表,請使用標準INSERT INTO陳述式:
spark.sql(f""" INSERT INTO {CATALOG_NAME}.{DB_NAME}.{TABLE_NAME}_nopartitions SELECT c_customer_sk, c_customer_id, c_first_name, c_last_name, c_birth_country, c_email_address FROM another_table """)
分割的資料表
以下是使用 Spark SQL 建立分割 Iceberg 資料表的範例:
spark.sql(f""" CREATE TABLE IF NOT EXISTS {CATALOG_NAME}.{DB_NAME}.{TABLE_NAME}_withpartitions ( c_customer_sk int, c_customer_id string, c_first_name string, c_last_name string, c_birth_country string, c_email_address string) USING iceberg PARTITIONED BY (c_birth_country) OPTIONS ('format-version'='2') """)
若要使用 Spark SQL 將資料插入分割的 Iceberg 資料表,請使用標準INSERT INTO陳述式:
spark.sql(f""" INSERT INTO {CATALOG_NAME}.{DB_NAME}.{TABLE_NAME}_withpartitions SELECT c_customer_sk, c_customer_id, c_first_name, c_last_name, c_birth_country, c_email_address FROM another_table """)
注意
從 Iceberg 1.5.0 開始,當您將資料插入分割資料表時,hash寫入分佈模式為預設值。如需詳細資訊,請參閱 Iceberg 文件中的撰寫分佈模式
使用 DataFrames API
若要寫入 Iceberg 資料集,您可以使用 DataFrameWriterV2 API。
若要建立 Iceberg 資料表並將資料寫入其中,請使用 df.writeTo(t) 函數。如果資料表存在,請使用 .append()函數。如果沒有,請使用.create().下列範例使用 .createOrReplace(),這是.create()相當於 的變體CREATE OR REPLACE TABLE AS SELECT。
未分割的資料表
若要使用 DataFrameWriterV2 API 建立和填入未分割的 Iceberg 資料表:
input_data.writeTo(f"{CATALOG_NAME}.{DB_NAME}.{TABLE_NAME}_nopartitions") \ .tableProperty("format-version", "2") \ .createOrReplace()
若要使用 DataFrameWriterV2 API 將資料插入 現有的未分割 Iceberg 資料表:
input_data.writeTo(f"{CATALOG_NAME}.{DB_NAME}.{TABLE_NAME}_nopartitions") \ .append()
分割的資料表
若要使用 DataFrameWriterV2 API 建立和填入分割的 Iceberg 資料表:
input_data.writeTo(f"{CATALOG_NAME}.{DB_NAME}.{TABLE_NAME}_withpartitions") \ .tableProperty("format-version", "2") \ .partitionedBy("c_birth_country") \ .createOrReplace()
若要使用 DataFrameWriterV2 API 將資料插入分割的 Iceberg 資料表:
input_data.writeTo(f"{CATALOG_NAME}.{DB_NAME}.{TABLE_NAME}_withpartitions") \ .append()
更新 Iceberg 資料表中的資料
下列範例顯示如何更新 Iceberg 資料表中的資料。此範例會修改c_customer_sk資料欄中具有偶數的所有資料列。
spark.sql(f""" UPDATE {CATALOG_NAME}.{db.name}.{table.name} SET c_email_address = 'even_row' WHERE c_customer_sk % 2 == 0 """)
此操作使用預設copy-on-write策略,因此會重寫所有受影響的資料檔案。
在 Iceberg 資料表中備份資料
支援資料是指在單一交易中插入新的資料記錄和更新現有的資料記錄。若要將資料升級到 Iceberg 資料表,請使用 SQL MERGE INTO陳述式。
下列範例會在資料表 內 upsert 資料表 {UPSERT_TABLE_NAME} 的內容{TABLE_NAME}:
spark.sql(f""" MERGE INTO {CATALOG_NAME}.{DB_NAME}.{TABLE_NAME} t USING {UPSERT_TABLE_NAME} s ON t.c_customer_id = s.c_customer_id WHEN MATCHED THEN UPDATE SET t.c_email_address = s.c_email_address WHEN NOT MATCHED THEN INSERT * """)
-
如果 中
{UPSERT_TABLE_NAME}已存在{TABLE_NAME}具有相同 的客戶記錄c_customer_id,則{UPSERT_TABLE_NAME}記錄c_email_address值會覆寫現有的值 (更新操作)。 -
如果 中的客戶記錄
{UPSERT_TABLE_NAME}不存在於 中{TABLE_NAME},則{UPSERT_TABLE_NAME}記錄會新增至{TABLE_NAME}(插入操作)。
刪除 Iceberg 資料表中的資料
若要從 Iceberg 資料表刪除資料,請使用 DELETE FROM運算式,並指定符合要刪除資料列的篩選條件。
spark.sql(f""" DELETE FROM {CATALOG_NAME}.{db.name}.{table.name} WHERE c_customer_sk % 2 != 0 """)
如果篩選條件符合整個分割區,Iceberg 會執行僅限中繼資料的刪除,並保留資料檔案。否則,它只會重寫受影響的資料檔案。
刪除方法會取得受 WHERE子句影響的資料檔案,並建立不含已刪除記錄的複本。然後,它會建立新的資料表快照,指向新的資料檔案。因此,已刪除的記錄仍然存在於資料表的較舊快照中。例如,如果您擷取資料表的上一個快照,您會看到您剛刪除的資料。如需有關使用相關資料檔案移除不需要的舊快照以進行清除的資訊,請參閱本指南稍後使用壓縮來維護檔案一節。
讀取資料
您可以使用 Spark SQL 和 DataFrames 在 Spark 中讀取 Iceberg 資料表的最新狀態。
使用 Spark SQL 的範例:
spark.sql(f""" SELECT * FROM {CATALOG_NAME}.{db.name}.{table.name} LIMIT 5 """)
使用 DataFrames API 的範例:
df = spark.table(f"{CATALOG_NAME}.{DB_NAME}.{TABLE_NAME}").limit(5)
使用時間歷程
Iceberg 資料表中的每個寫入操作 (插入、更新、upsert、刪除) 都會建立新的快照。然後,您可以將這些快照用於時間歷程,以返回時間並檢查過去資料表的狀態。
如需如何使用 snapshot-id和計時值擷取資料表快照歷史記錄的資訊,請參閱本指南稍後的存取中繼資料一節。
下列時間歷程查詢會根據特定 顯示資料表的狀態 snapshot-id。
使用 Spark SQL:
spark.sql(f""" SELECT * FROM {CATALOG_NAME}.{DB_NAME}.{TABLE_NAME} VERSION AS OF {snapshot_id} """)
使用 DataFrames API:
df_1st_snapshot_id = spark.read.option("snapshot-id", snapshot_id) \ .format("iceberg") \ .load(f"{CATALOG_NAME}.{DB_NAME}.{TABLE_NAME}") \ .limit(5)
下列時間歷程查詢會根據在特定時間戳記之前建立的最後一個快照顯示資料表的狀態,以毫秒為單位 (as-of-timestamp)。
使用 Spark SQL:
spark.sql(f""" SELECT * FROM dev.{db.name}.{table.name} TIMESTAMP AS OF '{snapshot_ts}' """)
使用 DataFrames API:
df_1st_snapshot_ts = spark.read.option("as-of-timestamp", snapshot_ts) \ .format("iceberg") \ .load(f"dev.{DB_NAME}.{TABLE_NAME}") \ .limit(5)
使用增量查詢
您也可以使用 Iceberg 快照逐步讀取附加的資料。
注意: 目前,此操作支援從append快照讀取資料。它不支援從 replace、 overwrite或 等操作擷取資料delete。 此外,Spark SQL 語法不支援增量讀取操作。
下列範例會擷取附加至快照 start-snapshot-id(獨佔) 和 end-snapshot-id(包含) 之間 Iceberg 資料表的所有記錄。
df_incremental = (spark.read.format("iceberg") .option("start-snapshot-id", snapshot_id_start) .option("end-snapshot-id", snapshot_id_end) .load(f"glue_catalog.{DB_NAME}.{TABLE_NAME}") )
存取中繼資料
Iceberg 可透過 SQL 存取其中繼資料。您可以查詢命名空間 來存取任何指定資料表 (<table_name>) 的中繼資料<table_name>.<metadata_table>。 如需中繼資料資料表的完整清單,請參閱 Iceberg 文件中的檢查資料表
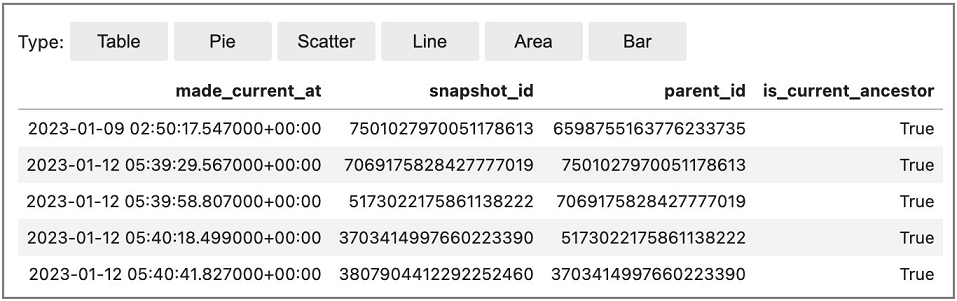
下列範例顯示如何存取 Iceberg 歷史記錄中繼資料表,其中顯示 Iceberg 資料表的遞交 (變更) 歷史記錄。
從 Amazon EMR Studio 筆記本使用 Spark SQL (搭配 %%sql魔術):
Spark.sql(f""" SELECT * FROM {CATALOG_NAME}.{DB_NAME}.{TABLE_NAME}.history LIMIT 5 """)
使用 DataFrames API:
spark.read.format("iceberg").load("{CATALOG_NAME}.{DB_NAME}.{TABLE_NAME}.history").show(5,False)
輸出範例: