本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
使用壓縮來維護資料表
Iceberg 包含的功能可讓您在將資料寫入資料表後執行資料表維護操作
Iceberg 壓縮
在 Iceberg 中,您可以使用壓縮來執行四個任務:
-
將小型檔案合併成大小通常超過 100 MB 的大型檔案。此技術稱為 bin packing。
-
將刪除檔案與資料檔案合併。使用merge-on-read方法的更新或刪除會產生刪除檔案。
-
(重新)根據查詢模式排序資料。您可以不使用任何排序順序或適合寫入和更新的排序順序來寫入資料。
-
使用空間填入曲線來叢集資料,以最佳化不同的查詢模式,特別是 z 順序排序。
在 上 AWS,您可以透過 Amazon Athena 或在 Amazon EMR 或 中使用 Spark,為 Iceberg 執行資料表壓縮和維護操作 AWS Glue。
當您使用 rewrite_data_files
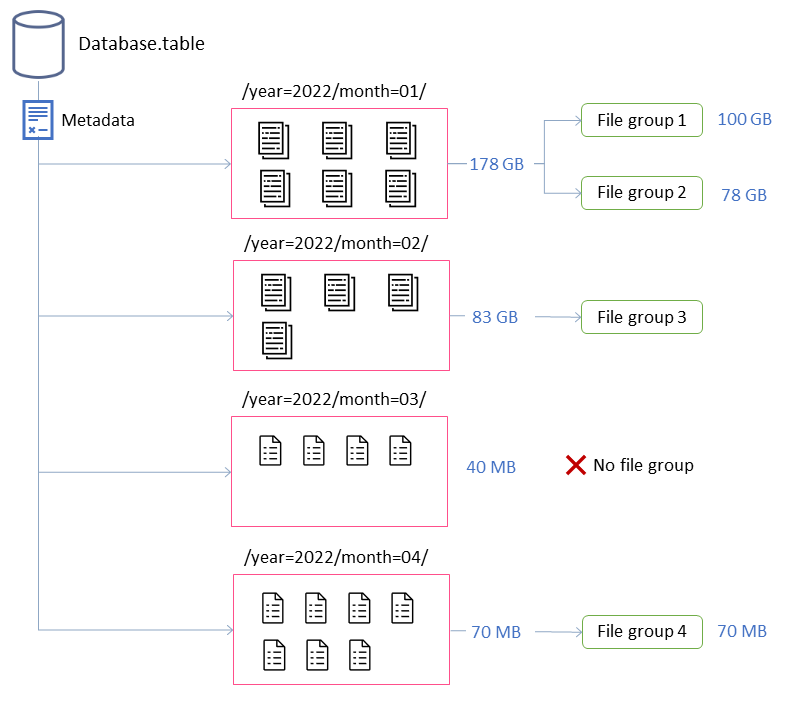
在此範例中,Iceberg 資料表包含四個分割區。每個分割區都有不同的大小和不同的檔案數量。如果您啟動 Spark 應用程式來執行壓縮,應用程式會建立總共四個要處理的檔案群組。檔案群組是 Iceberg 抽象,代表將由單一 Spark 任務處理的檔案集合。也就是說,執行壓縮的 Spark 應用程式將建立四個 Spark 任務來處理資料。
調校壓縮行為
下列金鑰屬性會控制如何選取資料檔案進行壓縮:
-
MAX_FILE_GROUP_SIZE_BYTES
預設會將單一檔案群組 (Spark 任務) 的資料限制設為 100 GB。此屬性對於沒有分割區的資料表或具有跨數百 GB 分割區的資料表特別重要。透過設定此限制,您可以細分操作來規劃工作並取得進展,同時防止叢集上的資源耗盡。 注意:每個檔案群組都會分別排序。因此,如果您想要執行分割區層級排序,您必須調整此限制以符合分割區大小。
-
MIN_FILE_SIZE_BYTES
或 MIN_FILE_SIZE_DEFAULT_RATIO 預設為資料表層級設定之目標檔案大小的 75%。例如,如果資料表的目標大小為 512 MB,則任何小於 384 MB 的檔案都會包含在將壓縮的一組檔案中。 -
MAX_FILE_SIZE_BYTES
或 MAX_FILE_SIZE_DEFAULT_RATIO 預設為目標檔案大小的 180%。與設定最小檔案大小的兩個屬性一樣,這些屬性用於識別壓縮任務的候選檔案。 -
如果資料表分割區大小小於目標檔案大小,MIN_INPUT_FILES
會指定要壓縮的檔案數目下限。此屬性的值用於判斷根據檔案數量壓縮檔案是否值得 (預設為 5)。 -
DELETE_FILE_THRESHOLD
會指定檔案在壓縮前的刪除操作數目下限。除非您另有指定,否則壓縮不會將刪除檔案與資料檔案合併。若要啟用此功能,您必須使用此屬性來設定閾值。此閾值專屬於個別資料檔案,因此如果您將其設定為 3,只有在有三個或多個參考該檔案的刪除檔案時,才會重新寫入資料檔案。
這些屬性可讓您深入了解上圖中檔案群組的形成。
例如,標記為 的分割區month=01包含兩個檔案群組,因為它超過 100 GB 的大小限制上限。相反地,month=02分割區包含單一檔案群組,因為它小於 100 GB。month=03 分割區不符合五個檔案的預設最低輸入檔案需求。因此,它不會壓縮。最後,雖然month=04分割區不包含足夠的資料來形成所需大小的單一檔案,但檔案將會壓縮,因為分割區包含五個以上的小型檔案。
您可以為在 Amazon EMR 或 上執行的 Spark 設定這些參數 AWS Glue。對於 Amazon Athena,您可以使用字首為 的資料表屬性來管理類似的屬性optimize_)。
在 Amazon EMR 或 上使用 Spark 執行壓縮 AWS Glue
本節說明如何正確調整 Spark 叢集的大小,以執行 Iceberg 的壓縮公用程式。下列範例使用 Amazon EMR Serverless,但您可以在 Amazon EMR on EC2 或 EKS 或 中使用相同的方法 AWS Glue。
您可以利用檔案群組與 Spark 任務之間的相互關聯來規劃叢集資源。若要循序處理檔案群組,請考慮每個檔案群組的大小上限為 100 GB,您可以設定下列 Spark 屬性:
-
spark.dynamicAllocation.enabled=FALSE -
spark.executor.memory=20 GB -
spark.executor.instances=5
如果您想要加速壓縮,您可以透過增加平行壓縮的檔案群組數量來水平擴展。您也可以使用手動或動態擴展來擴展 Amazon EMR。
-
手動擴展 (例如,因數為 4)
-
MAX_CONCURRENT_FILE_GROUP_REWRITES=4(我們的因素) -
spark.executor.instances=5(範例中使用的值) x4(我們的因素) =20 -
spark.dynamicAllocation.enabled=FALSE
-
-
動態擴展
-
spark.dynamicAllocation.enabled=TRUE(預設,無需採取任何動作) -
MAX_CONCURRENT_FILE_GROUP_REWRITES
= N(將此值與 對齊spark.dynamicAllocation.maxExecutors,預設為 100;根據範例中的執行器組態,您可以將N設定為 20)
這些是協助調整叢集大小的指導方針。不過,您也應該監控 Spark 任務的效能,以尋找工作負載的最佳設定。
-
使用 Amazon Athena 執行壓縮
Athena 透過 OPTIMIZE 陳述式,將 Iceberg 的壓縮公用程式實作為受管功能。您可以使用此陳述式來執行壓縮,而不必評估基礎設施。
此陳述式使用 bin 封裝演算法將小型檔案分組為較大的檔案,並將刪除檔案與現有的資料檔案合併。若要使用階層排序或 z 順序排序來叢集資料,請在 Amazon EMR 或 上使用 Spark AWS Glue。
您可以在建立資料表時,透過在 OPTIMIZE 陳述式中傳遞資料表屬性,或使用 陳述式在建立資料表之後,變更 CREATE TABLE ALTER TABLE陳述式的預設行為。如需預設值,請參閱 Athena 文件。
執行壓縮的建議
使用案例 |
建議 |
|---|---|
根據排程執行 bin 封裝壓縮 |
|
根據事件執行 bin 封裝壓縮 |
|
執行壓縮以排序資料 |
|
執行壓縮以使用 z 順序排序來叢集資料 |
|
在可能因延遲抵達資料而由其他應用程式更新的分割區上執行壓縮 |
|
在冷分割區上執行壓縮 (不再接收作用中寫入的資料分割區) |
|
