本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
Amazon Athena SQL 中的 Iceberg 資料表入門
Amazon Athena 為 Iceberg 提供內建支援。您可以使用 Iceberg,無需任何其他步驟或組態,但設定 Athena 文件入門一節中詳述的服務先決條件除外。本節提供在 Athena 中建立資料表的簡介。如需詳細資訊,請參閱本指南稍後的使用 Athena SQL 來使用 Iceberg 資料表。
您可以使用不同的引擎 AWS 在 上建立 Iceberg 資料表。這些資料表可順暢運作 AWS 服務。若要使用 Athena SQL 建立第一個 Iceberg 資料表,您可以使用下列樣板程式碼。
CREATE TABLE <table_name> ( col_1 string, col_2 string, col_3 bigint, col_ts timestamp) PARTITIONED BY (col_1, <<<partition_transform>>>(col_ts)) LOCATION 's3://<bucket>/<folder>/<table_name>/' TBLPROPERTIES ( 'table_type' ='ICEBERG' )
下列各節提供在 Athena 中建立分割和未分割 Iceberg 資料表的範例。如需詳細資訊,請參閱 Athena 文件中詳述的 Iceberg 語法。
建立未分割的資料表
下列範例陳述式會自訂樣板 SQL 程式碼,以在 Athena 中建立未分割的 Iceberg 資料表。您可以將此陳述式新增至 Athena 主控台
CREATE TABLE athena_iceberg_table ( color string, date string, name string, price bigint, product string, ts timestamp) LOCATION 's3://DOC_EXAMPLE_BUCKET/ice_warehouse/iceberg_db/athena_iceberg_table/' TBLPROPERTIES ( 'table_type' ='ICEBERG' )
如需使用查詢編輯器的step-by-step說明,請參閱 Athena 文件中的入門。
建立分割的資料表
下列陳述式會使用 Iceberg 的隱藏分割概念,根據日期建立分割day()轉換,從時間戳記資料欄使用 dd-mm-yyyy 格式衍生每日分割區。Iceberg 不會將此值儲存為資料集中的新資料欄。相反地,當您寫入或查詢資料時, 值會即時衍生。
CREATE TABLE athena_iceberg_table_partitioned ( color string, date string, name string, price bigint, product string, ts timestamp) PARTITIONED BY (day(ts)) LOCATION 's3://DOC_EXAMPLE_BUCKET/ice_warehouse/iceberg_db/athena_iceberg_table/' TBLPROPERTIES ( 'table_type' ='ICEBERG' )
使用單一 CTAS 陳述式建立資料表並載入資料
在前幾節的分割和未分割範例中,Iceberg 資料表會建立為 空白資料表。您可以使用 INSERT 或 MERGE陳述式將資料載入資料表。或者,您可以使用 CREATE TABLE AS SELECT (CTAS)陳述式,在單一步驟中建立資料並將其載入 Iceberg 資料表。
CTAS 是 Athena 在單一陳述式中建立資料表和載入資料的最佳方式。下列範例說明如何使用 CTAS 從 Athena 中現有的 Hive/Parquet 資料表 (iceberg_ctas_table) 建立 Iceberg 資料表 (hive_table)。
CREATE TABLE iceberg_ctas_table WITH ( table_type = 'ICEBERG', is_external = false, location = 's3://DOC_EXAMPLE_BUCKET/ice_warehouse/iceberg_db/iceberg_ctas_table/' ) AS SELECT * FROM "iceberg_db"."hive_table" limit 20 --- SELECT * FROM "iceberg_db"."iceberg_ctas_table" limit 20
若要進一步了解 CTAS,請參閱 Athena CTAS 文件。
插入、更新和刪除資料
Athena 支援使用 INSERT INTO、MERGE INTO、 和 DELETE FROM 陳述式將資料寫入 Iceberg UPDATE資料表的不同方式。
注意
Athena SQL 目前不支援copy-on-write方法。UPDATE、 MERGE INTO和 DELETE FROM操作一律使用具有位置刪除的merge-on-read方法,無論指定的資料表屬性為何。如果您設定 write.update.mode、 write.merge.mode和 等資料表屬性write.delete.mode來使用copy-on-write,您的查詢將不會失敗,但 Athena 會忽略它們並繼續使用merge-on-read。
下列陳述式使用 INSERT INTO將資料新增至 Iceberg 資料表:
INSERT INTO "iceberg_db"."ice_table" VALUES ( 'red', '222022-07-19T03:47:29', 'PersonNew', 178, 'Tuna', now() ) SELECT * FROM "iceberg_db"."ice_table" where color = 'red' limit 10;
輸出範例:

如需詳細資訊,請參閱 Athena 文件。
查詢 Iceberg 資料表
您可以使用 Athena SQL 對 Iceberg 資料表執行定期 SQL 查詢,如先前範例所示。
除了一般查詢之外,Athena 還支援 Iceberg 資料表的時間歷程查詢。如前所述,您可以透過 Iceberg 資料表中的更新或刪除來變更現有記錄,因此根據時間戳記或快照 ID,使用時間歷程查詢來查看資料表的較舊版本相當方便。
例如,下列陳述式會更新 的顏色值Person5,然後顯示 2023 年 1 月 4 日起的舊值:
UPDATE ice_table SET color='new_color' WHERE name='Person5' SELECT * FROM "iceberg_db"."ice_table" FOR TIMESTAMP AS OF TIMESTAMP '2023-01-04 12:00:00 UTC'
輸出範例:
如需時間歷程查詢的語法和其他範例,請參閱 Athena 文件。
Iceberg 資料表結構
現在我們已經介紹了使用 Iceberg 資料表的基本步驟,讓我們深入了解 Iceberg 資料表的複雜細節和設計。
為了啟用本指南先前所述的功能,Iceberg 的設計採用階層式資料層和中繼資料檔案。這些層以智慧方式管理中繼資料,以最佳化查詢規劃和執行。
下圖透過兩個角度描繪 Iceberg 資料表的組織: AWS 服務 用於在 Amazon S3 中存放資料表和檔案放置的 。
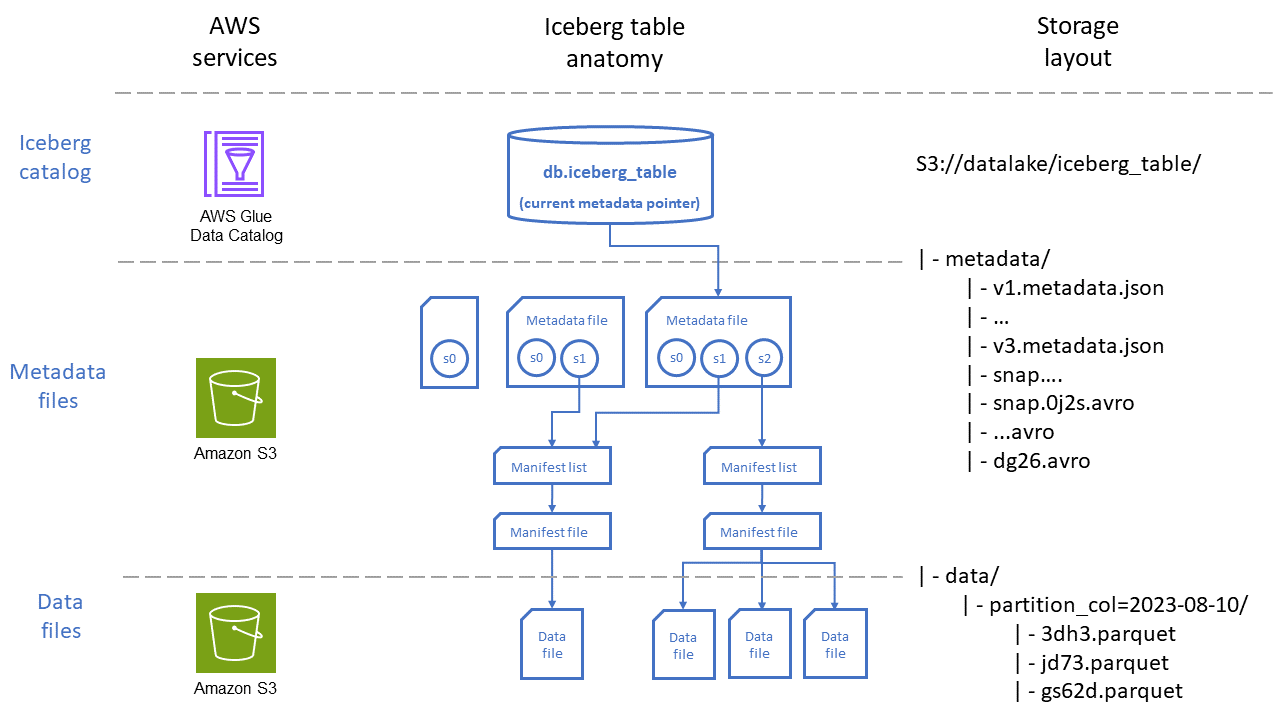
如圖所示,Iceberg 資料表由三個主要層組成:
-
Iceberg 目錄:與 Iceberg 原生 AWS Glue Data Catalog 整合,對於大多數使用案例而言, 是執行 之工作負載的最佳選項 AWS。與 Iceberg 資料表 (例如 Athena) 互動的服務會使用 目錄來尋找資料表的目前快照版本,以讀取或寫入資料。
-
中繼資料層:中繼資料檔案,即資訊清單檔案和資訊清單檔案,追蹤資訊,例如資料表的結構描述、分割區策略和資料檔案的位置,以及資料欄層級統計資料,例如儲存在每個資料檔案中記錄的最小和最大範圍。這些中繼資料檔案存放在資料表路徑中的 Amazon S3 中。
-
資訊清單檔案包含每個資料檔案的記錄,包括其位置、格式、大小、檢查總和和其他相關資訊。
-
資訊清單清單提供資訊清單檔案的索引。隨著資訊清單檔案的數量在資料表中成長,將該資訊分成較小的子區段有助於減少查詢需要掃描的資訊清單檔案數量。
-
中繼資料檔案包含整個 Iceberg 資料表的相關資訊,包括資訊清單清單、結構描述、分割區中繼資料、快照檔案,以及用於管理資料表中繼資料的其他檔案。
-
-
資料層:此層包含具有將執行查詢之資料記錄的檔案。這些檔案可以以不同的格式儲存,包括 Apache Parquet
、Apache Avro 和 Apache ORC 。 -
資料檔案包含資料表的資料記錄。
-
刪除在 Iceberg 資料表中編碼資料列層級刪除和更新操作的檔案。Iceberg 有兩種類型的刪除檔案,如 Iceberg 文件
所述。這些檔案是由 操作使用merge-on-read模式建立。
-
