本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
現代資料湖
現代資料湖中的進階使用案例
資料儲存的演變已從資料庫進展到資料倉儲和資料湖,其中每項技術都處理獨特的業務和資料需求。傳統資料庫擅長處理結構化資料和交易工作負載,但隨著資料量的增加,他們面臨效能挑戰。資料倉儲出現來解決效能和可擴展性問題,但與資料庫一樣,它們依賴垂直整合系統中的專屬格式。
資料湖在成本、可擴展性和靈活性方面提供儲存資料的最佳選項之一。您可以使用資料湖以低成本保留大量結構化和非結構化資料,並將此資料用於不同類型的分析工作負載,從商業智慧報告到大數據處理、即時分析、機器學習和生成式人工智慧 (AI),以協助引導更好的決策。
儘管有這些優點,但資料湖最初並非使用類似資料庫的功能進行設計。資料湖不提供原子性、一致性、隔離性和耐久性 (ACID) 處理語意的支援,您可能需要這些語意,才能透過使用許多不同的技術,在數百或數千名使用者之間大規模地最佳化和管理資料。資料湖不提供下列功能的原生支援:
-
當業務中的資料變更時,執行有效的記錄層級更新和刪除
-
隨著資料表成長到數百萬個檔案和數十萬個分割區,管理查詢效能
-
確保多個並行寫入器和讀取器之間的資料一致性
-
當寫入操作透過 操作中途失敗時,防止資料損毀
-
隨著時間演進的資料表結構描述,而不需要 (部分) 重寫資料集
這些挑戰在處理變更資料擷取 (CDC) 等使用案例中變得特別普遍,或與隱私權、刪除資料和串流資料擷取相關的使用案例,這可能會導致次佳資料表。
使用傳統 Hive 格式資料表的資料湖僅支援整個檔案的寫入操作。這使得更新和刪除難以實作、耗時且成本高昂。此外,需要 ACID 相容系統中提供的並行控制和保證,以確保資料完整性和一致性。
這些挑戰讓使用者面臨兩難:選擇完全整合的專屬平台,或選擇廠商中立但資源密集的自建資料湖,這些湖需要持續維護和遷移才能實現其潛在價值。
為了協助克服這些挑戰,Iceberg 提供額外的類似資料庫的功能,可簡化資料湖的最佳化和管理負荷,同時仍然支援 Amazon S3
Apache Iceberg 簡介
Apache Iceberg 是一種開放原始碼資料表格式,可在資料湖資料表中提供過去只能在資料庫或資料倉儲中使用的功能。它專為擴展和效能而設計,非常適合用於管理超過數百 GB 的資料表。Iceberg 資料表的一些主要功能包括:
-
刪除、更新和合併。 Iceberg 支援資料倉儲的標準 SQL 命令,可與資料湖資料表搭配使用。
-
快速掃描規劃和進階篩選。Iceberg 會存放中繼資料,例如分割區和資料欄層級統計資料,可供引擎用來加速規劃和執行查詢。
-
完整的結構描述演變。Iceberg 支援新增、捨棄、更新或重新命名資料欄,而不會產生副作用。
-
分割區演變。您可以在資料磁碟區或查詢模式變更時更新資料表的分割區配置。Iceberg 支援變更資料表分割所在的資料欄,或將資料欄新增至複合分割區或從中移除資料欄。
-
隱藏分割。 此功能可防止自動讀取不必要的分割區。這可讓使用者不必了解資料表的分割詳細資訊,或將額外的篩選條件新增至其查詢。
-
版本轉返。使用者可以還原至交易前狀態,快速修正問題。
-
時間歷程。使用者可以查詢資料表的特定先前版本。
-
可序列化隔離。資料表變更是原子的,因此讀者永遠不會看到部分或未遞交的變更。
-
並行寫入器。Iceberg 使用樂觀並行來允許多個交易成功。如果發生衝突,其中一個寫入器必須重試交易。
-
開啟檔案格式。Iceberg 支援多種開放原始碼檔案格式,包括 Apache Parquet
、Apache Avro 和 Apache ORC 。
總之,使用 Iceberg 格式的資料湖受益於交易一致性、速度、擴展和結構描述演變。如需這些和其他 Iceberg 功能的詳細資訊,請參閱 Apache Iceberg 文件
AWS 支援 Apache Iceberg
Amazon EMR
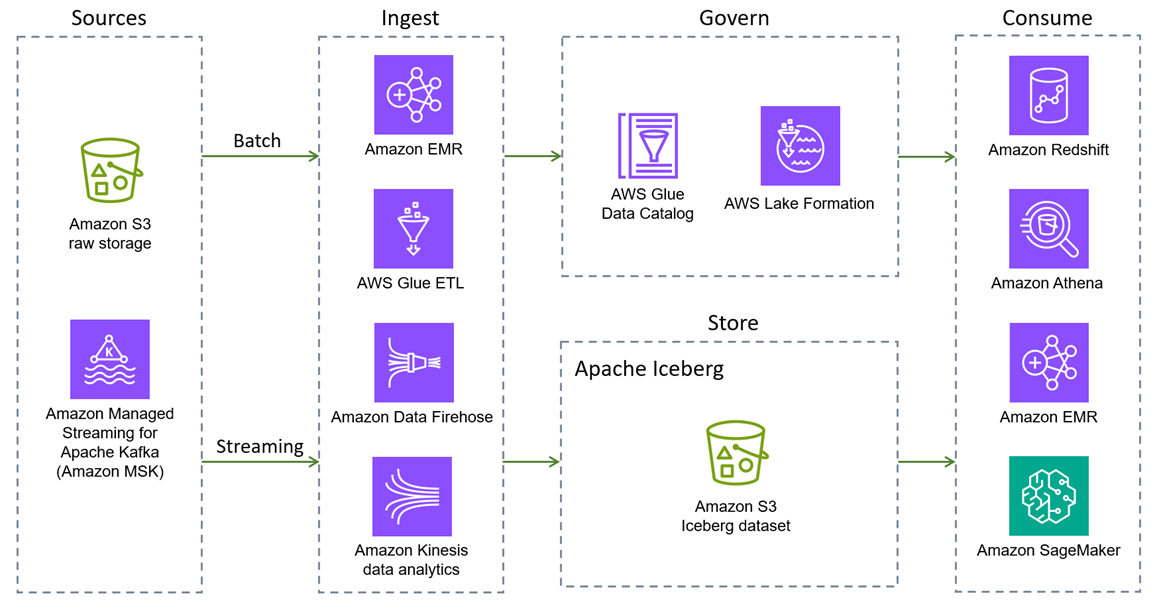
以下 AWS 服務 提供原生 Iceberg 整合。還有其他 AWS 服務 可以間接或透過封裝 Iceberg 程式庫來與 Iceberg 互動。
-
由於其耐用性、可用性、可擴展性、安全性、合規性和稽核功能,Amazon S3 是建置資料湖的最佳位置。Iceberg 的設計和建置旨在與 Amazon S3 無縫互動,並支援 Iceberg 文件中
列出的許多 Amazon S3 功能。此外,Amazon S3 Tables 提供第一個具有內建 Iceberg 支援的雲端物件存放區,並簡化大規模儲存表格式資料。透過支援 Iceberg 的 S3 Tables,您可以使用熱門 AWS 和第三方查詢引擎輕鬆查詢表格式資料。 -
新一代 SageMaker
建置在開放式湖群架構上,可統一跨 Amazon S3 資料湖、Amazon Redshift 資料倉儲以及第三方和聯合資料來源的資料存取。這些功能可協助您在單一資料複本上建置強大的分析和 AI/ML 應用程式。湖房與 Iceberg 完全相容,因此您可以使用 Iceberg REST API 靈活地存取和查詢資料。 -
Amazon EMR 是一種大數據解決方案,適用於使用 Apache Spark、Flink、Trino 和 Hive 等開放原始碼架構的 PB 級資料處理、互動式分析和機器學習。Amazon EMR 可以在自訂的 Amazon Elastic Compute Cloud (Amazon EC2) 叢集、Amazon Elastic Kubernetes Service (Amazon EKS) AWS Outposts、 或 Amazon EMR Serverless 上執行。
-
Amazon Athena 是一種以開放原始碼架構為基礎的無伺服器互動式分析服務。它支援開放資料表和檔案格式,並提供簡化、靈活的方式來分析其所在位置的 PB 資料。Athena 為 Iceberg 的讀取、時間歷程、寫入和 DDL 查詢提供原生支援,並使用 AWS Glue Data Catalog Iceberg 中繼存放區的 。
-
Amazon Redshift 是 PB 級雲端資料倉儲,支援叢集型和無伺服器部署選項。Amazon Redshift Spectrum 可以查詢向 註冊 AWS Glue Data Catalog 並存放在 Amazon S3 上的外部資料表。Redshift Spectrum 也支援 Iceberg 儲存格式。
-
AWS Glue 是一種無伺服器資料整合服務,可讓您更輕鬆地探索、準備、移動和整合來自多個來源的資料,以進行分析、機器學習 (ML) 和應用程式開發。它與 Iceberg 完全整合。具體而言,您可以使用 AWS Glue 任務對 Iceberg 資料表執行讀取和寫入操作、透過 管理資料表 AWS Glue Data Catalog(Hive 中繼存放區相容)、使用 AWS Glue 爬蟲程式自動探索和註冊資料表,以及透過 Data Quality 功能評估 Iceberg 資料表中的 AWS Glue 資料品質。 AWS Glue Data Catalog 也支援收集資料欄統計資料、計算和更新 Iceberg 資料表中每個資料欄的不同值 (NDVs) 數量,以及自動資料表最佳化 (壓縮、快照保留和孤立檔案刪除)。 AWS Glue 也支援從 AWS 服務 和第三方應用程式清單將零 ETL 整合到 Iceberg 資料表。
-
Amazon Data Firehose 是一項全受管服務,可將即時串流資料交付至目的地,例如 Amazon S3、Amazon Redshift、Amazon OpenSearch Service、Amazon OpenSearch Serverless、Splunk、Apache Iceberg 資料表,以及支援的第三方服務提供者擁有的任何自訂 HTTP 或 HTTP 端點,包括 Datadog、Dynatrace、LogicMonitor、MongoDB、New Relic、Coralogix 和 Elastic。使用 Firehose,您不需要撰寫應用程式或管理資源。將您的資料產生來源設定為把資料傳送至 Firehose,它就會將資料自動交付至您指定的目的地。您也可以將 Firehose 設定為在交付資料前轉換您的資料。
-
Amazon Managed Service for Apache Flink 是一種全受管的 Amazon 服務,可讓您使用 Apache Flink 應用程式來處理串流資料。它支援從 Iceberg 資料表讀取和寫入,並啟用即時資料處理和分析。
-
Amazon SageMaker AI 支援使用 Iceberg 格式在 Amazon SageMaker AI Feature Store 中儲存功能集。
-
AWS Lake Formation 提供存取資料的粗略和精細存取控制許可,包括 Athena 或 Amazon Redshift 耗用的 Iceberg 資料表。若要進一步了解 Iceberg 資料表的許可支援,請參閱 Lake Formation 文件。
AWS 有各種支援 Iceberg 的服務,但涵蓋所有這些服務超出本指南的範圍。下列各節涵蓋 Amazon EMR 和 AWS Glue Athena SQL 上的 Spark (批次和結構化串流)。下一節提供 Athena SQL 中 Iceberg 支援的快速說明。
