本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
視覺理解提示技巧
注意
本文件適用於 Amazon Nova 第 1 版。如需有關如何在 Amazon Nova 2 中提示多模態理解的資訊,請參閱提示多模態輸入。
下列視覺提示技巧可協助您為 Amazon Nova 建立更好的提示詞。
放置事項
建議您在新增任何文件之前放置媒體檔案 (例如影像或影片),接著是引導模型的指示文字或提示詞。雖然在文字之後放置影像或與文字交錯放置影像仍能有良好的表現,但如果使用案例允許,則 {media_file}-then-{text} 結構是慣用的方法。
以下範本可在執行視覺理解時用來將媒體檔案置於文字之前。
{ "role": "user", "content": [ { "image": "..." }, { "video": "..." }, { "document": "..." }, { "text": "..." } ] }
未遵循結構化 |
最佳化提示詞 |
|
|---|---|---|
使用者 |
說明影像中發生的情況 [Image1.png] |
[Image1.png] 說明影像中發生了什麼情況? |
具有視覺元件的多個媒體檔案
在跨回合提供多個媒體檔案的情況下,使用編號標籤引入每個影像。例如,如果使用兩個影像,則標記為 Image
1: 和 Image 2:。如果使用三個影片,則標記為 Video
1:、 Video 2: 和 Video 3:。影像之間或影像與提示詞之間不需要換行。
下列範本可用來放置多個媒體檔案:
messages = [ { "role": "user", "content": [ {"text":"Image 1:"}, {"image": {"format": "jpeg", "source": {"bytes": img_1_base64}}}, {"text":"Image 2:"}, {"image": {"format": "jpeg", "source": {"bytes": img_2_base64}}}, {"text":"Image 3:"}, {"image": {"format": "jpeg", "source": {"bytes": img_3_base64}}}, {"text":"Image 4:"}, {"image": {"format": "jpeg", "source": {"bytes": img_4_base64}}}, {"text":"Image 5:"}, {"image": {"format": "jpeg", "source": {"bytes": img_5_base64}}}, {"text":user_prompt}, ], } ]
非最佳化提示詞 |
最佳化提示詞 |
|---|---|
|
描述您在第二個影像中看到的內容。 [Image1.png] [Image2.png] |
[Image1.png] [Image2.png] 描述您在第二個影像中看到的內容。 |
|
隨附的文件中是否描述了第二個影像? [Image1.png] [Image2.png] [Document1.pdf] |
[Image1.png] [Image2.png] [Document1.pdf] 隨附的文件中是否描述了第二個影像? |
由於媒體檔案類型的長上下文詞元,在某些情況下可能不會遵守在提示詞開頭指出的系統提示詞。在此情況下,建議您將任何系統指示移至使用者回合,並遵循 {media_file}-then-{text} 的一般指引。這不會影響使用 RAG、代理程式或工具的系統提示。
使用使用者指示來改善視覺理解任務的指示遵循效果
對於影片理解,上下文中的詞元數量使得 放置事項 中的建議非常重要。使用系統提示詞來處理更一般的事項,例如語氣和風格。我們建議您在使用者提示詞中保留影片相關指示,以獲得更好的效能。
下列範本可用於改善指示:
{ "role": "user", "content": [ { "video": { "format": "mp4", "source": { ... } } }, { "text": "You are an expert in recipe videos. Describe this video in less than 200 words following these guidelines: ..." } ] }
如同文字一樣,我們建議對影像和影片套用思維鏈,以獲得改善的效能。我們也建議您將思維鏈指令置於系統提示詞中,同時保留使用者提示詞中的其他指示。
重要
Amazon Nova Premier 模型是 Amazon Nova 系列中更高智慧的模型,能夠處理更複雜的任務。如果您的任務需要進階思維鏈思考,我們建議您使用給予 Amazon Nova 時間思考 (思維鏈) 中提供的提示詞範本。這種方法有助於增強模型的分析和問題解決能力。
少樣本範例
如同文字模型一樣,我們建議您提供影像範例,以獲得改善的影像理解效能 (由於每個推論一個影片的限制,無法提供影片範例)。我們建議您將範例放在使用者提示詞的媒體檔案之後,而不是在系統提示詞中提供。
| 0-Shot | 2-Shot | |
|---|---|---|
| User | [Image 1] | |
| Assistant | The image 1 description | |
| User | [Image 2] | |
| Assistant | The image 2 description | |
| User | [影像 3] 說明影像中發生了什麼情況 |
[影像 3] 說明影像中發生了什麼情況 |
週框方塊偵測
如果您需要識別物件的週框方塊座標,您可以使用 Amazon Nova 模型,以 [0, 1000) 的尺度輸出週框方塊。取得這些座標之後,您就可以根據影像維度調整座標大小,作為後製處理步驟。如需如何完成此後製處理步驟的詳細資訊,請參閱 Amazon Nova Image Grounding 筆記本
以下是週框方塊偵測的範例提示詞:
Detect bounding box of objects in the image, only detect {item_name} category objects with high confidence, output in a list of bounding box format. Output example: [ {"{item_name}": [x1, y1, x2, y2]}, ... ] Result:
更豐富的輸出或樣式
影片理解輸出可能非常短。如果您想要較長的輸出,建議您為模型建立人物角色。您可以指示此人物角色以您想要的方式回應,類似於使用系統角色。
對回應的進一步修改可以透過單樣本和少樣本技術來實現。提供良好回應的範例,模型可以在產生答案時模擬其中的各個層面。
將文件內容擷取至 Markdown
Amazon Nova Premier 示範了理解文件中嵌入之圖表的增強功能,以及從科學論文等複雜領域讀取和理解內容的能力。此外,Amazon Nova Premier 還會在擷取文件內容時顯示改善的效能,並可將此資訊輸出為 Markdown 表格和 Latex 格式。
下列範例提供了影像格式的表格,以及供 Amazon Nova Premier 將影像內容轉換為 Markdown 表格的提示詞。建立 Markdown (或 Latex 表示) 之後,您可以使用工具將內容轉換為 JSON 或其他結構化輸出。
Make a table representation in Markdown of the image provided.
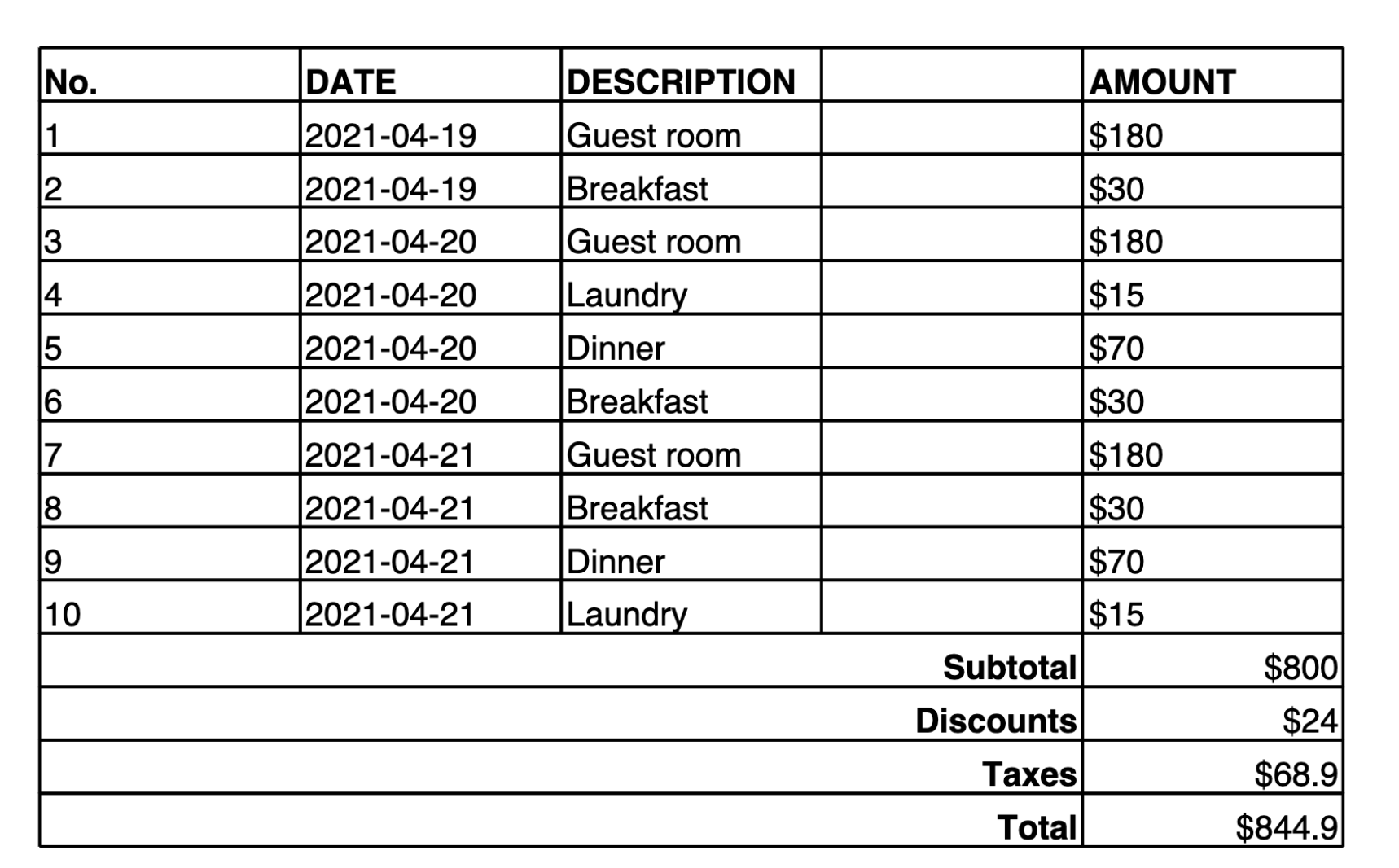
以下是該模型提供的輸出:
| No. | DATE | DESCRIPTION | AMOUNT | |-----|------------|-------------|--------| | 1 | 2021-04-19 | Guest room | $180 | | 2 | 2021-04-19 | Breakfast | $30 | | 3 | 2021-04-20 | Guest room | $180 | | 4 | 2021-04-20 | Laundry | $15 | | 5 | 2021-04-20 | Dinner | $70 | | 6 | 2021-04-20 | Breakfast | $30 | | 7 | 2021-04-21 | Guest room | $180 | | 8 | 2021-04-21 | Breakfast | $30 | | 9 | 2021-04-21 | Dinner | $70 | | 10 | 2021-04-21 | Laundry | $15 | | | | Subtotal | $800 | | | | Discounts | $24 | | | | Taxes | $68.9 | | | | Total | $844.9 |
此輸出使用自訂資料表表示法,其中 || 用作資料欄分隔符號,&& 用作資料列分隔符號。
用於視覺理解的推論參數設定
對於視覺理解使用案例,我們建議您從將推論參數 temperature 設定為 0,並將 topK 設定為 1 開始。觀察模型的輸出之後,您就可以根據使用案例調整推論參數。這些值通常取決於任務和所需的變異,請提高溫度設定,以引發答案的更多變化。
影片分類
若要有效將影片內容整理為適當的類別,請提供模型可用於分類的類別。考慮下列範例提示詞:
[Video] Which category would best fit this video? Choose an option from the list below: \Education\Film & Animation\Sports\Comedy\News & Politics\Travel & Events\Entertainment\Trailers\How-to & Style\Pets & Animals\Gaming\Nonprofits & Activism\People & Blogs\Music\Science & Technology\Autos & Vehicles
標記影片
Amazon Nova Premier 展示了建立影片標籤的改善功能。為了獲得最佳結果,請使用下列請求逗號分隔標籤的指示:「使用逗號分隔每個標籤」。以下為範例提示詞:
[video] "Can you list the relevant tags for this video? Use commas to separate each tag."
影片的密集字幕
Amazon Nova Premier 示範了提供密集字幕,即為影片中多個區段產生詳細文字描述的增強功能。以下為範例提示詞:
[Video] Generate a comprehensive caption that covers all major events and visual elements in the video.
