本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
使用案例
以下是向量搜尋的使用案例。
檢索增強生成 (RAG)
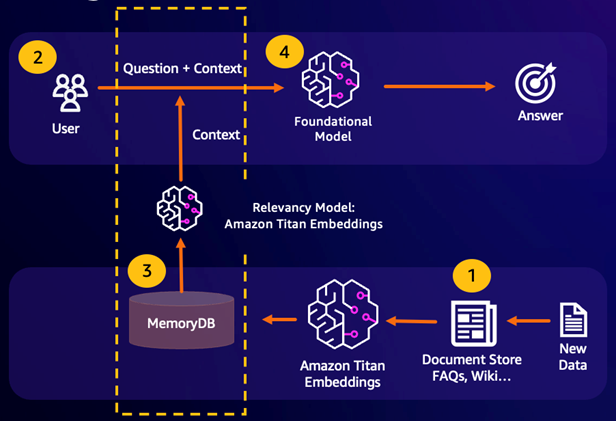
擷取增強生成 (RAG) 利用向量搜尋,從大型資料組合擷取相關段落,以增強大型語言模型 (LLM)。具體而言,編碼器會將輸入內容和搜尋查詢嵌入向量,然後使用近似接近的鄰近搜尋來尋找類似語義的段落。這些擷取的段落會與原始內容串連,以提供其他相關資訊給 LLM,以傳回更準確的回應給使用者。
持久的語意快取
語意快取是一種程序,可透過儲存來自 FM 的先前結果來降低運算成本。透過重複使用先前推論的先前結果,而不是重新運算,語意快取可減少透過 FMs 推論期間所需的運算量。MemoryDB 可啟用持久的語意快取,避免過去推論的資料遺失。這可讓您的生成式 AI 應用程式在單一位數毫秒內回應先前語意相似問題的答案,同時避免不必要的 LLM 推論來降低成本。
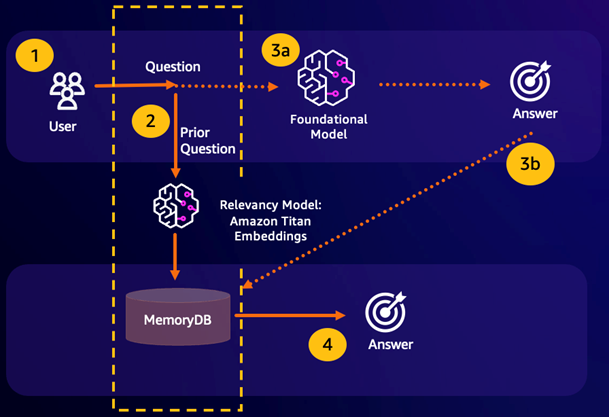
語意搜尋命中 – 如果客戶的查詢根據與先前問題所定義的相似性分數在語義上類似,FM 緩衝區記憶體 (MemoryDB) 會傳回步驟 4 中先前問題的答案,而不會透過步驟 3 呼叫 FM。這將避免基礎模型 (FM) 延遲和產生的成本,為客戶提供更快的體驗。
語意搜尋遺漏 – 如果客戶的查詢根據與先前查詢的定義相似度分數在語義上不相似,則客戶會在步驟 3a 中呼叫 FM 以向客戶傳遞回應。然後,從 FM 產生的回應將作為向量儲存到 MemoryDB 以供未來查詢 (步驟 3b),以將語意相似問題的 FM 成本降至最低。在此流程中,不會叫用步驟 4,因為原始查詢沒有類似語義的問題。
詐騙偵測
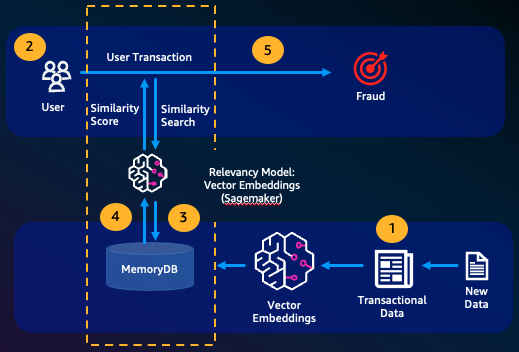
詐騙偵測是一種異常偵測形式,代表有效的交易做為向量,同時比較新交易淨額的向量表示法。當這些新交易與代表有效交易資料的向量具有低相似性時,就會偵測到詐騙。這可透過建模正常行為來偵測詐騙,而不是嘗試預測每個可能的詐騙執行個體。MemoryDB 可讓組織在高輸送量期間執行此操作,並將誤報和單位數毫秒延遲降至最低。
其他使用案例
建議引擎可以透過將項目表示為向量來尋找類似的產品或內容。透過分析屬性和模式來建立向量。根據使用者模式和屬性,可以透過尋找已與使用者正面對齊的最類似向量,向使用者建議新的看不見項目。
文件搜尋引擎將文字文件表示為數字的密集向量,擷取語意意義。在搜尋時間,引擎會將搜尋查詢轉換為向量,並使用近似最接近的鄰近搜尋來尋找具有最相似向量的文件。此向量相似性方法允許根據意義比對文件,而不只是比對關鍵字。
