本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
在 AWS Glue 中串流 ETL 任務
您可以建立串流擷取、轉換和載入 (ETL) 任務,讓它連續執行並從 Amazon Kinesis Data Streams、Apache Kafka 和 Amazon Managed Streaming for Apache Kafka (Amazon MSK) 的串流來源使用資料。這些任務會清理並轉換資料,然後將結果載入 Amazon S3 資料湖或 JDBC 資料存放區。
此外,您可以為 Amazon Kinesis Data Streams 產生資料。此功能僅適用於撰寫 AWS Glue 指令碼時。如需詳細資訊,請參閱Kinesis 連線。
依預設,AWS Glue 以 100 秒的間隔處理和寫出資料。這樣可以有效處理資料,並且可在資料到達時間比預期晚時執行彙總。您可以修改此時段大小,以提高適時性或彙總正確性。AWS Glue 串流任務使用檢查點而不是任務書籤來追蹤已讀取的資料。
注意
AWS Glue 在串流 ETL 任務執行時按小時計費。
本影片討論串流 ETL 的成本挑戰,以及其中節省成本的功能 AWS Glue。
建立串流 ETL 任務包含下列步驟:
-
對於 Apache Kafka 串流來源,建立連接到 Kafka 來源或 Amazon MSK 叢集的 AWS Glue 連線。
-
為串流來源手動建立 Data Catalog 資料表。
-
為串流資料來源建立 ETL 任務。定義串流特定的任務屬性,並提供您自己的指令碼,或選擇修改產生的指令碼。
如需詳細資訊,請參閱在 中串流 ETL AWS Glue。
為 Amazon Kinesis Data Streams 建立串流 ETL 任務時,您不需要建立 AWS Glue 連線。但是,如果有連線連接到以 Kinesis Data Streams 做為來源的 AWS Glue 串流 ETL 任務,則需要連到 Kinesis 的 Virtual Private Cloud (VPC) 端點。如需詳細資訊,請參閱 Amazon VPC 使用者指南中的建立介面端點。在另一個帳戶中指定 Amazon Kinesis Data Streams 時,您必須設定角色和政策以允許跨帳戶存取。如需詳細資訊,請參閱範例:從不同帳戶中的 Kinesis 串流讀取。
AWS Glue 串流 ETL 作業可以自動偵測壓縮資料、透明地解壓縮串流資料、在輸入來源上執行例行轉換並載入輸出存放區。
AWS Glue 根據輸入格式,支援以下壓縮類型的自動解壓縮:
| 壓縮類型 | Avro 檔案 | Avro 資料 | JSON | CSV | Grok |
|---|---|---|---|---|---|
| BZIP2 | 是 | 是 | 是 | 是 | 是 |
| GZIP | 否 | 是 | 是 | 是 | 是 |
| SNAPPY | 是 (原始 Snappy) | 是 (框架式 Snappy) | 是 (框架式 Snappy) | 是 (框架式 Snappy) | 是 (框架式 Snappy) |
| XZ | 是 | 是 | 是 | 是 | 是 |
| ZSTD | 是 | 否 | 否 | 否 | 否 |
| DEFLATE | 是 | 是 | 是 | 是 | 是 |
主題
為 Apache Kafka 資料串流建立 AWS Glue 連線
若要讀取 Apache Kafka 串流,您必須建立 AWS Glue 連線。
為 Kafka 來源建立 AWS Glue 連線 (主控台)
在 https://https://console.aws.amazon.com/glue/
開啟 AWS Glue 主控台。 -
在導覽窗格中,於 Data catalog ( Data Catalog ) 下選擇 Connections (連線)。
-
選擇 Add connection (新增連線),然後在 Set up your connection’s properties (設定連線的屬性) 頁面上輸入連線名稱。
注意
如需指定連線屬性的詳細資訊,請參見《AWS Glue 連線屬性。》。
-
對於連線類型,請選擇 Kafka。
-
對於 Kafka bootstrap servers URLs (Kafka 引導伺服器 URL),請為您的 Amazon MSK 叢集或 Apache Kafka 叢集輸入引導代理程式的主機和連接埠號碼。僅使用 Transport Layer Security (TLS) 端點來建立與 Kafka 叢集的初始連線。不支援純文字端點。
以下是 Amazon MSK 叢集的主機名稱和連接埠號碼對的範例清單。
myserver1.kafka.us-east-1.amazonaws.com:9094,myserver2.kafka.us-east-1.amazonaws.com:9094, myserver3.kafka.us-east-1.amazonaws.com:9094如需取得引導代理程式資訊的詳細資訊,請參閱 Amazon Managed Streaming for Apache Kafka 開發人員指南中的取得 Amazon MSK 叢集的引導代理程式。
-
如果您想要與 Kafka 資料來源的安全連線,請選取 Require SSL connection (需要 SSL 連線),以及對於 Kafka private CA certificate location (Kafka 私有 CA 憑證位置),輸入自訂 SSL 憑證的有效 Amazon S3 路徑。
對於自我管理的 Kafka 的 SSL 連線,自訂憑證是強制性的。這對於 Amazon MSK 是選用的。
如需指定 Kafka 之自訂憑證的詳細資訊,請參閱 AWS Glue SSL 連線屬性。
-
使用 AWS Glue Studio 或 AWS CLI 指定 Kafka 用戶端身分驗證方法。若要存取,AWS Glue請從左側導覽窗格中的 ETL 選單 AWS Glue Studio 中選取 。
如需 Kafka 用戶端身分驗證方法的詳細資訊,請參閱 用於用戶端身分驗證的 AWS Glue Kafka 連連線屬性。
-
選用地輸入描述,然後選擇 Next (下一頁)。
-
對於 Amazon MSK 叢集,請指定其 Virtual Private Cloud (VPC)、子網路和安全群組。VPC 資訊對於自我管理 Kafka 是選用的。
-
選擇 Next (下一頁) 檢閱所有連線屬性,然後選擇 Finish (完成)。
如需 AWS Glue 連線的詳細資訊,請參閱 連線至資料。
用於用戶端身分驗證的 AWS Glue Kafka 連連線屬性
- SASL/GSSAPI (Kerberos) 身分驗證
-
選擇此身分驗證方法將允許您指定 Kerberos 屬性。
- Kerberos Keytab
-
選擇 Keytab 檔案的位置。Keytab 存放了一個或多個主體的長期金鑰。如需詳細資訊,請參閱 MIT Kerberos 文件:Keytab
。 - Kerberos krb5.conf 檔案
-
選擇 krb5.conf 檔案。這包含預設範圍 (類似網域的邏輯網路,可定義相同 KDC 下的一組系統) 和 KDC 伺服器的位置。如需詳細資訊,請參閱 MIT Kerberos 文件:krb5.conf
。 - Kerberos 主體和 Kerberos 服務名稱
-
輸入 Kerberos 主體和服務名稱。如需詳細資訊,請參閱 MIT Kerberos 文件:Kerberos 主體
。 - SASL/SCRAM-SHA-512 身分驗證
-
選擇此身分驗證方法將允許您指定身分驗證憑證。
- AWS Secrets Manager
-
在搜尋方塊中鍵入名稱或 ARN 來搜尋字符。
- 直接提供使用者名稱和密碼
-
請在搜尋方塊中鍵入名稱或 ARN 來搜尋字符。
- SSL 用戶端身分驗證
-
選擇此身分驗證方法將允許您透過瀏覽 Amazon S3 來選取 Kafka 用戶端金鑰存放區的位置。或者,您可以輸入 Kafka 用戶端金鑰存放區密碼和 Kafka 用戶端金鑰密碼。
- IAM 身分驗證
-
此身分驗證方法不需要任何額外的規格,且只有當串流來源是 MSK Kafka 時才適用。
- SASL/PLAIN 身分驗證
-
選擇此身分驗證方法可讓您指定身分驗證憑證。
為串流來源建立資料目錄資料表
可針對串流來源手動建立的資料目錄表,此資料目錄表可指定來源資料串流屬性,包含資料結構描述。此資料表做為串流 ETL 任務的資料來源。
如果您不知道來源資料串流中資料的結構描述,您可以建立沒有結構描述的資料表。然後,當您建立串流 ETL 任務時,您可以開啟 AWS Glue 結構描述偵測功能。AWS Glue 會從串流資料判斷結構描述。
使用 AWS Glue 主控台
注意
您無法使用 AWS Lake Formation 主控台建立資料表;您必須使用 AWS Glue主控台。
另外,請考慮以下 Avro 格式的串流來源或您可以套用 Grok 模式之日誌資料的資訊。
Kinesis 資料來源
建立資料表時,請設定下列串流 ETL 屬性 (主控台)。
- 來源類型
-
Kinesis
- 針對相同帳戶中的 Kinesis 來源:
-
- 區域
-
Amazon Kinesis Data Streams 服務所在的 AWS 區域。區域和 Kinesis 串流名稱會一起翻譯成串流 ARN。
範例:https://kinesis.us-east-1.amazonaws.com
- Kinesis 串流名稱
-
串流名稱,如 Amazon Kinesis Data Streams 開發人員指南中的建立串流所述。
- 如需其他帳戶中的 Kinesis 來源,請參閱此範例,將角色和政策設定為允許跨帳戶存取。設定下列設定:
-
- 串流 ARN
-
消費者註冊的 Kinesis 資料串流的 ARN。如需詳細資訊,請參閱 中的 Amazon Resource Name (ARNs) AWS 和服務命名空間AWS 一般參考。
- 擔任的角色 ARN
-
要擔任之角色的 Amazon Resource Name (ARN)。
- 工作階段名稱 (選用)
-
擔任角色工作階段的識別碼。
當同一個角色由不同委託人或出於不同原因而承擔時,使用角色工作階段名稱來唯一識別工作階段。在跨帳戶案例中,角色工作階段名稱對擁有該角色的帳戶是可見的,而且可以由擁有該角色的帳戶記錄。角色工作階段名稱也用於擔任角色委託人的 ARN。這表示使用臨時安全登入資料的後續跨帳戶 API 請求,會在其 AWS CloudTrail 日誌中向外部帳戶公開角色工作階段名稱。
為 Amazon Kinesis Data Streams 設定串流 ETL 屬性 (AWS Glue API 或 AWS CLI)
-
若要為相同帳戶中的 Kinesis 來源設定串流 ETL 屬性,請在
CreateTableAPI 操作或create_tableCLI 命令的StorageDescriptor結構中指定streamName和endpointUrl參數。"StorageDescriptor": { "Parameters": { "typeOfData": "kinesis", "streamName": "sample-stream", "endpointUrl": "https://kinesis.us-east-1.amazonaws.com" } ... }或者,指定
streamARN。範例
"StorageDescriptor": { "Parameters": { "typeOfData": "kinesis", "streamARN": "arn:aws:kinesis:us-east-1:123456789:stream/sample-stream" } ... } -
若要為另一個帳戶中的 Kinesis 來源設定串流 ETL 屬性,請在
CreateTableAPI 操作或create_tableCLI 命令的StorageDescriptor結構中指定streamARN、awsSTSRoleARN和awsSTSSessionName(選用) 參數。"StorageDescriptor": { "Parameters": { "typeOfData": "kinesis", "streamARN": "arn:aws:kinesis:us-east-1:123456789:stream/sample-stream", "awsSTSRoleARN": "arn:aws:iam::123456789:role/sample-assume-role-arn", "awsSTSSessionName": "optional-session" } ... }
Kafka 資料來源
建立資料表時,請設定下列串流 ETL 屬性 (主控台)。
- 來源類型
-
Kafka
- 針對 Kafka 來源:
-
- 主題名稱
-
主題名稱依 Kafka 中所指定。
- 連線
-
參考 Kafka 來源的 AWS Glue 連線,如 為 Apache Kafka 資料串流建立 AWS Glue 連線 中所述。
AWS Glue 結構描述登錄檔資料表來源
若要使用使用 AWS Glue 結構描述登錄檔串流任務,請依照 使用案例: AWS Glue Data Catalog 中的說明建立或更新結構描述登錄檔資料表。
目前,AWS Glue 串流僅支援 Glue 結構描述登錄檔 Avro 格式,其中結構描述推斷設定為 false。
Avro 串流來源的注意事項與限制
下列注意事項和限制適用於 Avro 格式的串流來源:
-
開啟結構描述偵測時,Avro 結構描述必須包含在裝載中。關閉時,裝載應該只包含資料。
-
動態框架不支援某些 Avro 資料類型。在 AWS Glue 主控台的建立資料表精靈 Define a schema (定義結構描述) 頁面中定義結構描述時,您無法指定這些資料類型。在結構描述偵測期間,Avro 結構描述中不支援的類型會轉換成支援的類型,如下所示:
-
EnumType => StringType -
FixedType => BinaryType -
UnionType => StructType
-
-
如果您使用主控台中 Define a schema (定義結構描述) 頁面來定義資料表結構描述,則結構描述的隱含根元素類型為
record。如果您想要record以外的根元素類型,例如array或map,則無法使用 Define a schema (定義結構描述) 頁面指定結構描述。相反,您必須略過該頁面,並將結構描述指定為資料表屬性或在 ETL 指令碼內指定。-
若要在資料表屬性中指定結構描述,請完成建立資料表精靈、編輯資料表詳細資訊,並在 Table properties (資料表屬性) 下新增鍵值對。使用鍵
avroSchema,然後輸入值的結構描述 JSON 物件,如下列螢幕擷取畫面所示。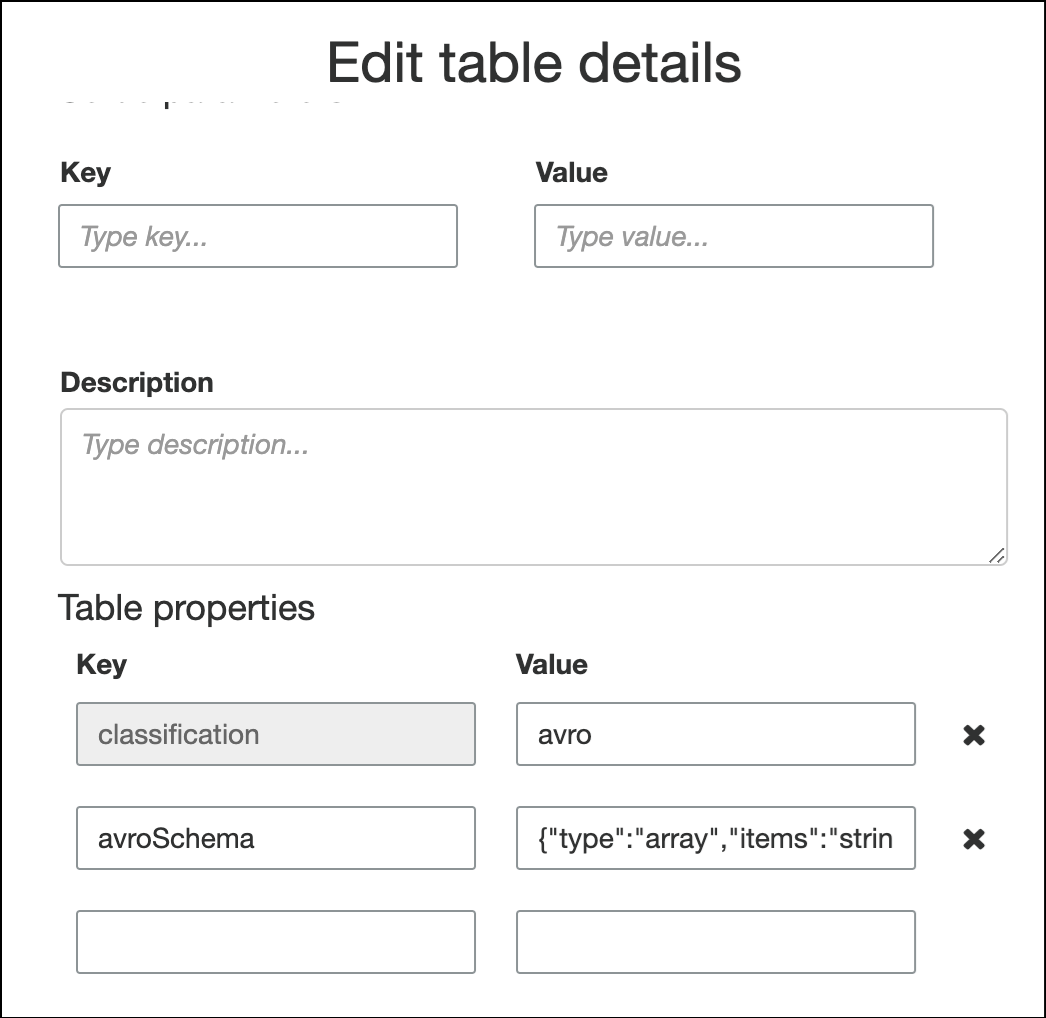
-
若要在 ETL 指令碼中指定結構描述,請修改
datasource0指派陳述式,並新增avroSchema鍵至additional_options參數,如下列 Python 和 Scala 範例所示。
-
將 grok 模式套用至串流來源
您可以為日誌資料來源建立串流 ETL 任務,並使用 Grok 模式將日誌轉換為結構化資料。ETL 任務接著會將資料當成結構化資料來源處理。您可以指定當您為串流來源建立 Data Catalog 資料表時要套用的 Grok 模式。
如需 Grok 模式和自訂模式字串值的相關資訊,請參閱 撰寫 grok 自訂分類器。
將 grok 模式新增至資料目錄資料表 (主控台)
-
使用建立資料表精靈,並使用 為串流來源建立資料目錄資料表 中指定的參數建立資料表。指定資料格式為 Grok,填寫 Grok pattern (Grok 模式) 欄位,並選擇性地在 Custom patterns (optional) (自訂模式 (選用)) 下方新增自訂模式。
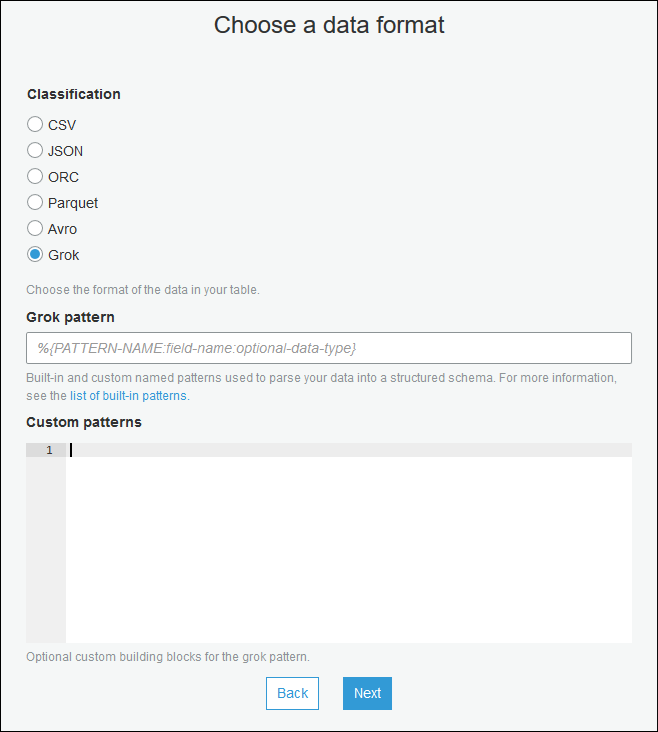
在每個自訂模式之後按 Enter。
將 grok 模式新增至 Data Catalog 資料表 (AWS Glue API 或 AWS CLI)
-
新增
GrokPattern參數,並選擇性地將CustomPatterns參數新增至CreateTableAPI 操作或create_tableCLI 命令。"Parameters": { ... "grokPattern": "string", "grokCustomPatterns": "string", ... },將
grokCustomPatterns表示為字串,並使用 "\n" 作為模式之間的分隔符。下列是指定這些參數的範例。
範例
"parameters": { ... "grokPattern": "%{USERNAME:username} %{DIGIT:digit:int}", "grokCustomPatterns": "digit \d", ... }
定義串流 ETL 任務的任務屬性
在 AWS Glue 主控台上定義串流 ETL 任務時,請提供下列串流特定的屬性。如需其他任務屬性的說明,請參閱 定義 Spark 任務的任務屬性。
- IAM 角色
-
指定用於授權執行任務、存取串流來源和存取目標資料存放區之資源的 AWS Identity and Access Management (IAM) 角色。
若要存取 Amazon Kinesis Data Streams,請將
AmazonKinesisFullAccessAWS 受管政策連接至角色,或連接類似的 IAM 政策,以允許更精細的存取。如需政策範例,請參閱使用 IAM 控制對 Amazon Kinesis Data Streams 資源的存取。如需在 AWS Glue 執行任務之許可的詳細資訊,請參閱 Glue AWS 的身分和存取管理。
- Type
-
選擇 Spark streaming (Spark 串流)。
- AWS Glue 版本
-
AWS Glue 版本決定了可用於任務的 Apache Spark 和 Python 或 Scala 版本。選擇一個選項,指定可用於任務的 Python 或 Scala 版本。AWS Glue具有 Python 3 支援的 2.0 版本是串流 ETL 任務的預設值。
- Maintenance window (維護時段)
-
指定可以在其中重新啟動串流任務的時段。請參閱 AWS Glue 串流的維護時段。
- 任務逾時
-
選擇性地輸入持續時間 (以分鐘為單位)。預設值為空白。
串流任務的逾時值必須少於 7 天或 10,080 分鐘。
當您將值保留空白時,如果尚未設定維護時段,系統會在 7 天後重新啟動任務。如果您已設定維護時段,系統會在 7 天後的維護時段期間重新啟動任務。
- 資料來源
-
指定您在 為串流來源建立資料目錄資料表 中建立的資料表。
- 資料目標
-
執行以下任意一項:
-
選擇 Create tables in your data target (在您的資料目標中建立資料表),然後指定下列資料目標屬性。
- 資料存放區
-
選擇 Amazon S3 或 JDBC。
- 格式
-
選擇任何格式。全部支援串流。
-
選擇 Use tables in the data catalog and update your data target (使用 Data Catalog 中的資料表並更新您的資料目標),然後選擇 JDBC 資料存放區的資料表。
-
- 輸出結構描述定義
-
執行以下任意一項:
-
選擇 Automatically detect schema of each record (自動偵測每筆記錄的結構描述) 以開啟結構描述偵測。AWS Glue 會從串流資料判斷結構描述。
-
選擇 Specify output schema for all records (指定所有記錄的輸出結構描述),以使用「套用映射」轉換來定義輸出結構描述。
-
- 指令碼
-
選擇性地提供您自己的指令碼或修改產生的指令碼,以執行 Apache Spark 結構化串流引擎支援的操作。如需可用操作的詳細資訊,請參閱串流 DataFrames/資料集上的操作
。
串流 ETL 注意事項和限制
請記住下列注意事項和限制:
-
自動解壓縮 AWS Glue 串流 ETL 作業僅適用於支援的壓縮類型。同時請注意以下各項:
框架式 Snappy 指的是官方 Snappy 框架格式
。 Glue 3.0 版支援 Deflate,而 Glue 2.0 版不支援。
-
使用結構描述偵測時,您無法執行串流資料的聯結。
-
AWS Glue 串流 ETL 任務不支援 Avro 格式 AWS Glue 結構描述登錄檔的 Union 資料類型。
-
您的 ETL 指令碼可以使用 Apache Spark 結構化串流原生的 AWS Glue 內建轉換。如需詳細資訊,請參閱 Apache Spark 網站上的串流 DataFrames/資料集上的操作
或 AWS Glue PySpark 轉換參考。 -
AWS Glue 串流 ETL 任務使用檢查點來追蹤已讀取的資料。因此,已停止再重新啟動的任務會從原先在串流中停止的位置接續下去。如果想要重新處理資料,您可以刪除指令碼中參考的檢查點資料夾。
-
不支援任務書籤。
-
若要在任務中使用 Kinesis Data Streams 的強化廣發功能,請參閱 在 Kinesis 串流任務中使用強化廣發功能。
-
如果使用從 AWS Glue 結構描述登錄檔建立的 Data Catalog 資料表,則當新的結構描述版本可用時,為了反映新的結構描述,您需要執行以下操作:
-
停止與資料表相關聯的任務。
-
更新「 Data Catalog 」資料表的結構描述。
-
重新啟動與資料表相關聯的任務。
-
